
 Technology peripherals
AI
Spread everything? 3DifFusionDet: Diffusion model enters LV fusion 3D target detection!
Technology peripherals
AI
Spread everything? 3DifFusionDet: Diffusion model enters LV fusion 3D target detection!
Spread everything? 3DifFusionDet: Diffusion model enters LV fusion 3D target detection!

The author’s personal understanding
In recent years, the diffusion model has been very successful in generation tasks, and has naturally been extended to target detection tasks. It models target detection as starting from a noise box. (noisy boxes) to the object boxes (object boxes) denoising diffusion process. During the training phase, target boxes are diffused from ground-truth boxes to random distributions, and the model learns how to reverse this process of adding noise to ground-truth boxes. During the inference phase, the model refines a set of randomly generated target boxes into output results in a progressive manner. Compared with traditional object detection methods, which rely on a fixed set of learnable queries, 3DifFusionDet does not require learnable queries for object detection.
The main idea of 3DifFusionDet
The 3DifFusionDet framework represents 3D target detection as a denoising diffusion process from a noisy 3D box to a target box. In this framework, ground truth boxes are trained with random distribution diffusion and the model learns the inverse noise process. During inference, the model gradually refines a set of randomly generated boxes. Under the feature alignment strategy, the progressive refinement method can make an important contribution to lidar-camera fusion. The iterative refinement process also shows great adaptability by applying the framework to various detection environments requiring different levels of accuracy and speed. KITTI is a benchmark for real traffic target recognition. A large number of experiments have been conducted on KITTI, which shows that compared with early detectors, KITTI can achieve good performance
The main contributions of 3DifFusionDet are as follows:
- Represents 3D target detection as a generative denoising process and proposes 3DifFusionDet, which is the first research to apply the diffusion model to 3D target detection.
- The optimal Camera-LiDAR fusion alignment strategy under the framework of the generative denoising process was studied, and 2 branch fusion alignment strategies were proposed to utilize the complementary information provided by the two modalities.
- Extensive experiments were conducted on the KITTI benchmark. Compared with existing well-designed methods, 3DifFusionDet achieves competitive results, demonstrating the promise of diffusion models in 3D object detection tasks.
Using LiDAR-Camera fusion for 3D target detection
For 3D target detection, Camera and LiDAR are two complementary sensor types. LiDAR sensors focus on 3D localization and provide rich information about 3D structures, while Camera provides color information from which rich semantic features can be derived. Many efforts have been made to accurately detect 3D objects by fusing data from cameras and LiDAR. State-of-the-art methods are mainly based on LiDAR-based 3D object detectors and strive to incorporate image information into various stages of the LiDAR detection process, as the performance of LiDAR-based detection methods is significantly better than that of Camera-based methods. Due to the complexity of lidar-based and camera-based detection systems, combining the two modes will inevitably increase computational costs and inference time delays. Therefore, the problem of effectively fusing multimodal information remains.
Diffusion model
The diffusion model is a generative model that gradually deconstructs the observed data by introducing noise and restores the original data by reversing the process . Diffusion models and denoising score matching are connected through the denoising diffusion probabilistic model (Ho, Jain, and Abbeel 2020a), which has recently sparked interest in computer vision applications. It has been applied in many fields, such as graph generation, language understanding, robust learning and temporal data modeling.
Diffusion models have achieved great success in image generation and synthesis. Some pioneer works adopt diffusion models for image segmentation tasks. Compared to these fields, their potential for object detection has not yet been fully exploited. Previous approaches to object detection using diffusion models have been limited to 2D bounding boxes. Compared with 2D detection, 3D detection provides richer target space information and can achieve accurate depth perception and volume understanding, which is crucial for applications such as autonomous driving, where it is necessary to identify the precise distance of surrounding vehicles. and direction are important aspects for applications such as autonomous driving.
Network design of 3DifFusionDet
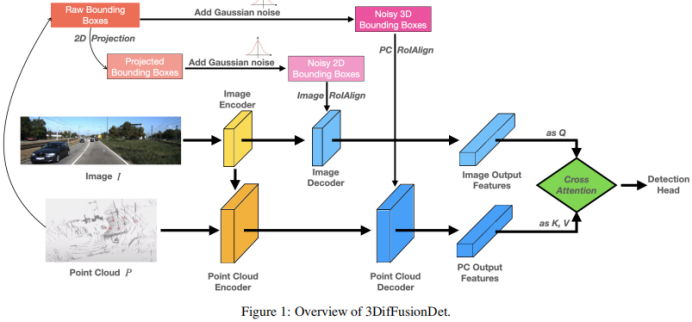
Figure 1 shows the overall architecture of 3DifFusionDet. It accepts multimodal inputs including RGB images and point clouds. Dividing the entire model into feature extraction and feature decoding parts, as with DiffusionDet, it would be difficult to directly apply to the original 3D features in each iteration step. The feature extraction part is run only once to extract deep feature representations from the original input X, while the feature decoding component is conditioned on this deep feature and trained to gradually draw box predictions from noisy boxes. In order to take full advantage of the complementary information provided by the two modalities, the encoder and decoder of each modality are separated. Furthermore, the image decoder and point cloud decoder are trained separately to refine 2D and 3D features using a diffusion model to generate noise boxes and respectively. As for the connection of these two feature branches, simply connecting them will cause information shearing, resulting in performance degradation. To this end, a multi-head cross-attention mechanism is introduced to deeply align these features. These aligned features are input to the detection head to predict the final true value without generating noise.
For the point cloud encoder, voxel-based methods are used for extraction and sparse-based methods are used for processing. Voxel-based methods convert LiDAR points into voxels. Compared with other series of point feature extraction methods (such as point-based methods), these methods discretize point clouds into equally spaced 3D grids, reducing memory requirements while retaining the original 3D shape information as much as possible. The sparsity-based processing method further helps the network improve computational efficiency. These benefits balance the relatively high computational requirements of diffusion models.
Compared with 2D features, 3D features contain extra dimensions, making learning more challenging. With this in mind, in addition to extracting features from the original modality, a fusion path is added that adds the extracted image features as another input to the point encoder, facilitating information exchange and leveraging learning from more diverse sources . A PointFusion strategy is employed, where points from the LiDAR sensor are projected onto the image plane. The concatenation of image features and corresponding points is then jointly processed by the VoxelNet architecture.
Feature decoder. The extracted image features and extracted point features are used as inputs to the corresponding image and point decoders. Each decoder also combines input from a uniquely created noise box or and learns to refine 2D and 3D features respectively, in addition to the corresponding extracted features.
Inspired by Sparse RCNN, the image decoder receives input from a collection of 2D proposal boxes and crops the RoI features from the feature map created by the image encoder. The point decoder receives input from a collection of 3D proposal boxes and crops the RoI features from the feature map created by the image encoder. For the point decoder, the input is a set of 3D proposal boxes that are used to crop 3D RoI features from the feature map generated by the point encoder
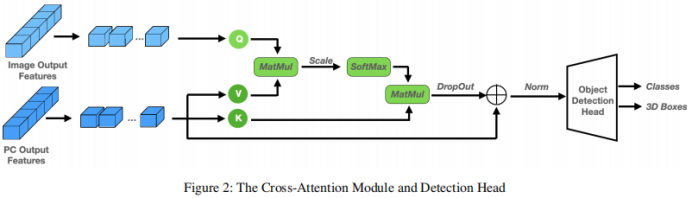
Cross Attention Module. After decoding the two feature branches, a way to combine them is needed. A straightforward approach is to simply connect the two feature branches by connecting them. This method appears to be too rough and may cause the model to suffer from information shearing, leading to performance degradation. Therefore, a multi-head cross-attention mechanism is introduced to deeply align and refine these features, as shown in Figure 1. Specifically, the output of the point decoder is treated as a source of k and v, while the output of the image decoder is projected onto q.
Experimental results
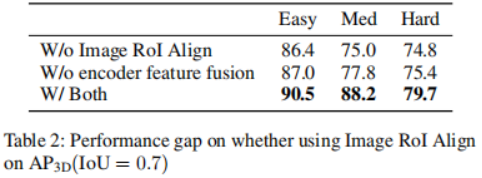
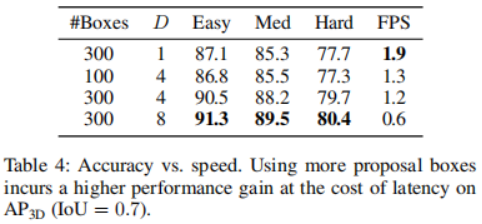
Experiments were conducted on the KITTI 3D object detection benchmark. Following the standard KITTI evaluation protocol for measuring detection performance (IoU = 0.7), Table 1 shows the mean precision (mAP) score of the 3DifFusionDet method compared to the state-of-the-art methods on the KITTI validation set. Performance is reported, following [diffusionDet, difficileist] and bolding the two best performing models for each task. According to the results in Table 1, the method of this study shows significant performance improvement compared to the baseline. When D=4, the method is able to surpass most baseline models in shorter inference time. When further increasing D to 8, the best performance is achieved among all models although the inference time is longer. This flexibility reveals that this method has a wide range of potential applications . To design a 3D object detector from Camera and LiDAR using diffusion models, the most straightforward approach should be to directly apply the generated noisy 3D boxes as input to fused 3D features. However, this approach may suffer from information shearing, resulting in performance degradation, as shown in Table 2. Using this, in addition to putting the point cloud RoIAlign under the encoded 3D features, we also create a second branch that puts the image RoIAlign under the encoded 2D features. The significantly improved performance suggests that the complementary information provided by both modes can be better exploited.
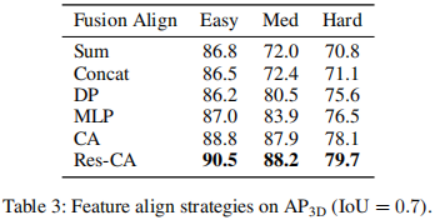
We will then analyze the impact of different fusion strategies: given the learned 2D and 3D representation features, how can we combine them more effectively. Compared with 2D features, 3D features have an extra dimension, which makes the learning process more challenging. We add an information flow path from image features to point features by projecting points from the LiDAR sensor onto image features and concatenating them with corresponding points to be jointly processed. This is the VoxelNet architecture. As can be seen from Table 3, this fusion strategy has great benefits for detection accuracy
The other part that needs to be fused is the connection of the two feature branches after decoding. Here, a multi-head cross-attention mechanism is applied to deeply align and refine these features. In addition to this, more direct methods such as the use of concatenation operations, summation operations, direct product operations, and the use of multilayer perceptrons (MLP) have also been studied. The results are shown in Table 4. Among them, the cross-attention mechanism shows the best performance, with almost the same training and inference speed. Study the trade-off between accuracy and inference speed. The impact of choosing different proposal boxes and D is shown by comparing 3D detection accuracy and frames per second (FPS). The number of proposal boxes is chosen from 100, 300, while D is chosen from 1, 4, 8. The running time is evaluated on a single NVIDIA RTX A6000 GPU with a batch size of 1. It was found that increasing the number of proposal boxes from 100 to 300 resulted in significant accuracy gains with negligible latency costs (1.3 FPS vs. 1.2 FPS). On the other hand, better detection accuracy leads to longer inference time. When changing D from 1 to 8, the 3D detection accuracy increases from sharp (Easy: 87.1 mAP to 90.5 mAP) to relatively slowly (Easy: 90.5 AP to 91.3 mAP), while FPS keeps decreasing. Case Research and Future Work Based on its unique properties, this article discusses the potential uses of 3DifFusionDet. Generally speaking, accurate, robust and real-time inference are three requirements for object detection tasks. In the field of perception for self-driving cars, perception models are particularly sensitive to real-time requirements, considering that cars traveling at high speeds need to spend extra time and distance to slow down or change direction due to inertia. More importantly, in order to ensure a comfortable ride experience, the car should drive as smoothly as possible with the smallest absolute value of acceleration under the premise of safety. One of its main advantages is a smoother ride experience compared to other similar self-driving car products. To do this, self-driving cars should start reacting quickly, whether accelerating, decelerating or turning. The faster the car responds, the more room it has for subsequent maneuvers and adjustments. This is more important than first obtaining the most precise classification or location of the detected target: when the car starts to respond, there is still time and distance to adjust the way it behaves, which can be used to make further decisions in a more precise way. Extrapolated, the results are then used to fine-tune the car's driving behavior. The rewritten content is as follows: According to the results in Table 4, when the inference step size is small, our 3DifFusionDet model can perform inference quickly and obtain relatively high accuracy. This initial perception is accurate enough to allow the self-driving car to develop new responses. As the number of inference steps increases, we are able to generate more accurate object detections and further fine-tune our responses. This progressive approach to detection is ideally suited to our task. Furthermore, since our model can adjust the number of proposal boxes during inference, we can leverage the prior information obtained from small steps to optimize the number of real-time proposal boxes. According to the results in Table 4, the performance under different a priori proposal frames is also different. Therefore, developing such adaptive detectors is a promising work In addition to self-driving cars, our model essentially matches any realistic scenario that requires short inference time in a continuous reaction space, especially In scenarios where the detector moves based on detection results. Benefiting from the properties of the diffusion model, 3DifFusionDet can quickly find an almost accurate real-space region of interest, triggering the machine to start new operations and self-optimization. Subsequent higher-precision perceptrons further fine-tune the machine's operation. In order to deploy models into these motion detectors, one open question is strategies for combining inference information between earlier inferences at larger steps and more recent inferences at smaller steps, and this is another open question. This article introduces a new 3D object detector called 3DifFusionDet, which has powerful LiDAR and camera fusion capabilities. Formulating 3D object detection as a generative denoising process, this is the first work to apply diffusion models to 3D object detection. In the context of generating a denoising process framework, this study explores the most effective camera lidar fusion alignment strategies and proposes a fusion alignment strategy to fully exploit the complementary information provided by both modes. Compared with mature detectors, 3DifFusionDet performs well, demonstrating the broad application prospects of diffusion models in object detection tasks. Its powerful learning results and flexible reasoning model make it have broad potential uses Original link: https://mp.weixin.qq.com/s/0Fya4RYelNUU5OdAQp9DVA 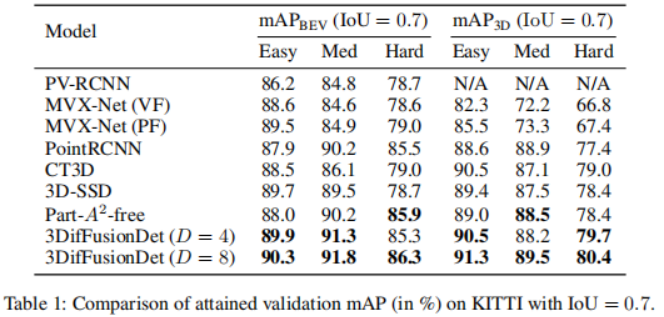
Summarize

The above is the detailed content of Spread everything? 3DifFusionDet: Diffusion model enters LV fusion 3D target detection!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
