

11 basic methods for determining the normality of data distributions

In the field of data science and machine learning, many models assume that the data is normally distributed, or that the data performs better under a normal distribution. For example, linear regression assumes that the residuals are normally distributed, and linear discriminant analysis (LDA) is derived based on assumptions such as normal distribution. Therefore, it is crucial for data scientists and machine learning practitioners to understand how to test data for normality.

This article aims to introduce 11 basic methods to test data Normality to help readers better understand the characteristics of data distribution and learn how to apply appropriate methods for analysis. In this way, the impact of data distribution on model performance can be better handled, and the process of machine learning and data modeling can be more convenient.
Plotting Methods
1.QQ Plot
QQ plot (quantile-quantile plot) is a widely used method to check whether the data distribution conforms to the normal distribution. In the QQ plot, the quantiles of the data are compared with the quantiles of the standard normal distribution. If the data distribution is close to the normal distribution, the points on the QQ plot will be close to a straight line.
To demonstrate QQ Figure, The example code below generates a set of random data that follows a normal distribution. After running the code, you can see the QQ plot along with the corresponding normal distribution curve. By observing the distribution of points on the graph, you can initially judge whether the data is close to a normal distribution
import numpy as npimport scipy.stats as statsimport matplotlib.pyplot as plt# 生成一组随机数据,假设它们服从正态分布data = np.random.normal(0, 1, 1000)# 绘制QQ图stats.probplot(data, dist="norm", plot=plt)plt.title('Q-Q Plot')plt.show()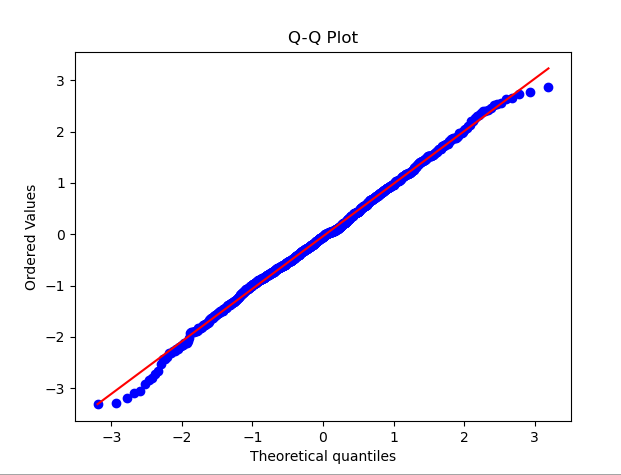
2.KDE Plot
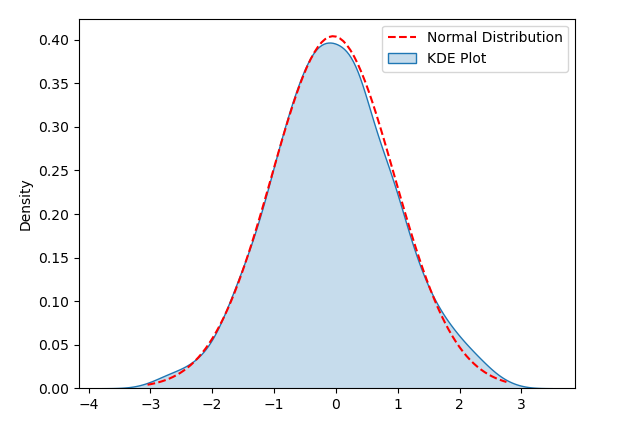
KDE (kernel density estimation) A graph is a method for visualizing the distribution of data and can help us detect the normality of the data. In the KDE plot, by estimating the density of the data and drawing it into a smooth curve, it helps us observe the distribution shape of the data
In order to demonstrate KDE Plot, the following sample code generates a set of normal distributions of random data. After running the code, you can see the KDE Plot and the corresponding normal distribution curve, and use visualization to detect whether the data distribution conforms to normality
import numpy as npimport seaborn as snsimport matplotlib.pyplot as plt# 生成随机数据np.random.seed(0)data = np.random.normal(loc=0, scale=1, size=1000)# 创建KDE Plotsns.kdeplot(data, shade=True, label='KDE Plot')# 添加正态分布曲线mu, sigma = np.mean(data), np.std(data)x = np.linspace(min(data), max(data), 100)y = (1/(sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)plt.plot(x, y, 'r--', label='Normal Distribution')# 显示图表plt.legend()plt.show()
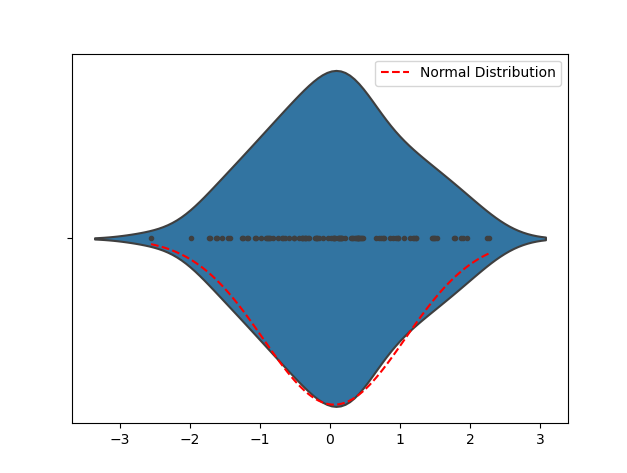
3.Violin Plot
By observing Violin Plot, you can find the distribution shape of the data, and thus initially judge whether the data is close to a normal distribution. If the Violin Plot takes on a bell-curve-like shape, the data are probably approximately normally distributed. If your Violin Plot is heavily skewed or has multiple peaks, the data may not be normally distributed.
The following sample code is used to generate random data that obeys a normal distribution to demonstrate Violin Plot. After running the code, you can see the Violin Plot and the corresponding normal distribution curve. Detect the shape of the data distribution through visualization to initially determine whether the data is close to a normal distribution
import numpy as npimport seaborn as snsimport matplotlib.pyplot as plt# 生成随机数据np.random.seed(0)data = np.random.normal(loc=0, scale=1, size=100)# 创建 Violin Plotsns.violinplot(data, inner="points")# 添加正态分布曲线mu, sigma = np.mean(data), np.std(data)x = np.linspace(min(data), max(data), 100)y = (1/(sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)plt.plot(x, y, 'r--', label='Normal Distribution')# 显示图表plt.legend()plt.show()
4.Histogram
Use histogram to Testing the normality of data distribution is also a common method. Histograms can help us intuitively understand the distribution of data, and can preliminarily determine whether the data is close to a normal distribution
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as stats# 生成一组随机数据,假设它们服从正态分布data = np.random.normal(0, 1, 1000)# 绘制直方图plt.hist(data, bins=30, density=True, alpha=0.6, color='g')plt.title('Histogram of Data')plt.xlabel('Value')plt.ylabel('Frequency')# 绘制正态分布的概率密度函数xmin, xmax = plt.xlim()x = np.linspace(xmin, xmax, 100)p = stats.norm.pdf(x, np.mean(data), np.std(data))plt.plot(x, p, 'k', linewidth=2)plt.show()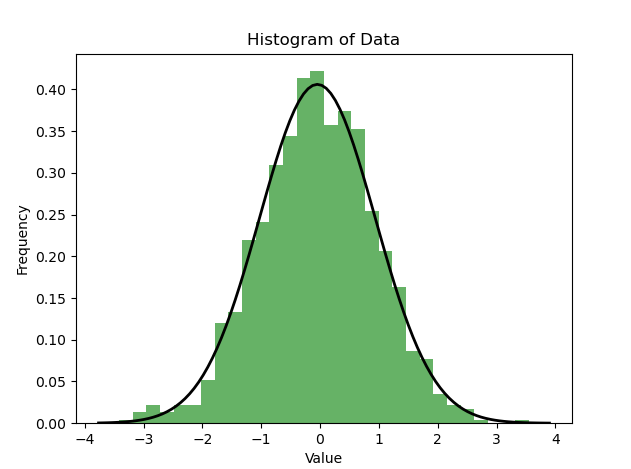
As shown in the figure above, if the histogram approximately presents If the distribution curve is similar to the corresponding normal distribution curve, then the data may conform to the normal distribution. Of course, visualization is only a preliminary judgment. If more precise detection is required, statistical methods such as normality testing can be used for analysis.
Statistical Methods
5. Shapiro-Wilk test
The Shapiro-Wilk test is a method used to test whether the data conforms to The statistical method of normal distribution is also called the W test. When performing the Shapiro-Wilk test, we usually focus on two main indicators:
- Statistic W: Calculate the statistic W based on the correlation between the observed data and the expected value under the normal distribution , the value range of W is between 0 and 1. When W is close to 1, it means that the observed data fits the normal distribution well.
- P value: The P value indicates the possibility of observing this correlation. If the P value is greater than the significance level (usually 0.05), it indicates that the observed data is likely to come from a normal distribution.
Therefore, when the statistic W is close to 1 and the P value is greater than 0.05, we can conclude that the observed data satisfies the normal distribution.
In the following code, a set of random data obeying the normal distribution is first generated, and then the Shapiro-Wilk test is performed to obtain the test statistic and P value. Based on the comparison between the P value and the significance level, you can determine whether the sample data comes from a normal distribution.
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Shapiro-Wilk检验stat, p = stats.shapiro(data)print('Shapiro-Wilk Statistic:', stat)print('P-value:', p)# 根据P值判断正态性alpha = 0.05if p > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
6.KS检验
KS检验(Kolmogorov-Smirnov检验)是一种用于检验数据是否符合特定分布(例如正态分布)的统计方法。它通过计算观测数据与理论分布的累积分布函数(CDF)之间的最大差异来评估它们是否来自同一分布。其基本步骤如下:
- 对两个样本数据进行排序。
- 计算两个样本的经验累积分布函数(ECDF),即计算每个值在样本中的累积百分比。
- 计算两个累积分布函数之间的差异,通常使用KS统计量衡量。
- 根据样本的大小和显著性水平,使用参考表活计算p值判断两个样本是否来自同一分布。
Python中使用KS检验来检验数据是否符合正态分布时,可以使用Scipy库中的kstest函数。下面是一个简单的示例,演示了如何使用Python进行KS检验来检验数据是否符合正态分布。
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行KS检验statistic, p_value = stats.kstest(data, 'norm')print('KS Statistic:', statistic)print('P-value:', p_value)# 根据P值判断正态性alpha = 0.05if p_value > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
7.Anderson-Darling检验
Anderson-Darling检验是一种用于检验数据是否来自特定分布(例如正态分布)的统计方法。它特别强调观察值在分布尾部的差异,因此在检测极端值的偏差方面非常有效
下面的代码使用stats.anderson函数执行Anderson-Darling检验,并获取检验统计量、临界值以及显著性水平。然后通过比较统计量和临界值,可以判断样本数据是否符合正态分布
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Anderson-Darling检验result = stats.anderson(data, dist='norm')print('Anderson-Darling Statistic:', result.statistic)print('Critical Values:', result.critical_values)print('Significance Level:', result.significance_level)# 判断正态性if result.statistic <p style="text-align:center;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/170255826239547.png" class="lazy" alt="11 basic methods for determining the normality of data distributions"></p><h4 id="Lilliefors检验">8.Lilliefors检验</h4><p>Lilliefors检验(也被称为Kolmogorov-Smirnov-Lilliefors检验)是一种用于检验数据是否符合正态分布的统计检验方法。它是Kolmogorov-Smirnov检验的一种变体,专门用于小样本情况。与K-S检验不同,Lilliefors检验不需要假定数据的分布类型,而是基于观测数据来评估是否符合正态分布</p><p>在下面的例子中,我们使用lilliefors函数进行Lilliefors检验,并获得了检验统计量和P值。通过将P值与显著性水平进行比较,我们可以判断样本数据是否符合正态分布</p><pre class="brush:php;toolbar:false">import numpy as npfrom statsmodels.stats.diagnostic import lilliefors# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Lilliefors检验statistic, p_value = lilliefors(data)print('Lilliefors Statistic:', statistic)print('P-value:', p_value)# 根据P值判断正态性alpha = 0.05if p_value > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
9.距离测量Distance Measures
距离测量(Distance measures)是一种有效的测试数据正态性的方法,它提供了更直观的方式来比较观察数据分布与参考分布之间的差异。
下面是一些常见的距离测量方法及其在测试正态性时的应用:
(1) "巴氏距离(Bhattacharyya distance)"的定义是:
- 测量两个分布之间的重叠,通常被解释为两个分布之间的接近程度。
- 选择与观察到的分布具有最小Bhattacharyya距离的参考分布,作为最接近的分布。
(2) 「海林格距离(Hellinger distance)」:
- 用于衡量两个分布之间的相似度,类似于Bhattacharyya距离。
- 与Bhattacharyya距离不同的是,Hellinger距离满足三角不等式,这使得它在一些情况下更为实用。
(3) "KL 散度(KL Divergence)":
- 它本身并不是严格意义上的“距离度量”,但在测试正态性时可以用作衡量信息丢失的指标。
- 选择与观察到的分布具有最小KL散度的参考分布,作为最接近的分布。
运用这些距离测量方法,我们能够比对观测到的分布与多个参考分布之间的差异,进而更好地评估数据的正态性。通过找出与观察到的分布距离最短的参考分布,我们可以更精确地判断数据是否符合正态分布
The above is the detailed content of 11 basic methods for determining the normality of data distributions. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1369
1369
 52
52

 This article will take you to understand SHAP: model explanation for machine learning
Jun 01, 2024 am 10:58 AM
This article will take you to understand SHAP: model explanation for machine learning
Jun 01, 2024 am 10:58 AM
In the fields of machine learning and data science, model interpretability has always been a focus of researchers and practitioners. With the widespread application of complex models such as deep learning and ensemble methods, understanding the model's decision-making process has become particularly important. Explainable AI|XAI helps build trust and confidence in machine learning models by increasing the transparency of the model. Improving model transparency can be achieved through methods such as the widespread use of multiple complex models, as well as the decision-making processes used to explain the models. These methods include feature importance analysis, model prediction interval estimation, local interpretability algorithms, etc. Feature importance analysis can explain the decision-making process of a model by evaluating the degree of influence of the model on the input features. Model prediction interval estimate
 Transparent! An in-depth analysis of the principles of major machine learning models!
Apr 12, 2024 pm 05:55 PM
Transparent! An in-depth analysis of the principles of major machine learning models!
Apr 12, 2024 pm 05:55 PM
In layman’s terms, a machine learning model is a mathematical function that maps input data to a predicted output. More specifically, a machine learning model is a mathematical function that adjusts model parameters by learning from training data to minimize the error between the predicted output and the true label. There are many models in machine learning, such as logistic regression models, decision tree models, support vector machine models, etc. Each model has its applicable data types and problem types. At the same time, there are many commonalities between different models, or there is a hidden path for model evolution. Taking the connectionist perceptron as an example, by increasing the number of hidden layers of the perceptron, we can transform it into a deep neural network. If a kernel function is added to the perceptron, it can be converted into an SVM. this one
 The evolution of artificial intelligence in space exploration and human settlement engineering
Apr 29, 2024 pm 03:25 PM
The evolution of artificial intelligence in space exploration and human settlement engineering
Apr 29, 2024 pm 03:25 PM
In the 1950s, artificial intelligence (AI) was born. That's when researchers discovered that machines could perform human-like tasks, such as thinking. Later, in the 1960s, the U.S. Department of Defense funded artificial intelligence and established laboratories for further development. Researchers are finding applications for artificial intelligence in many areas, such as space exploration and survival in extreme environments. Space exploration is the study of the universe, which covers the entire universe beyond the earth. Space is classified as an extreme environment because its conditions are different from those on Earth. To survive in space, many factors must be considered and precautions must be taken. Scientists and researchers believe that exploring space and understanding the current state of everything can help understand how the universe works and prepare for potential environmental crises
 Identify overfitting and underfitting through learning curves
Apr 29, 2024 pm 06:50 PM
Identify overfitting and underfitting through learning curves
Apr 29, 2024 pm 06:50 PM
This article will introduce how to effectively identify overfitting and underfitting in machine learning models through learning curves. Underfitting and overfitting 1. Overfitting If a model is overtrained on the data so that it learns noise from it, then the model is said to be overfitting. An overfitted model learns every example so perfectly that it will misclassify an unseen/new example. For an overfitted model, we will get a perfect/near-perfect training set score and a terrible validation set/test score. Slightly modified: "Cause of overfitting: Use a complex model to solve a simple problem and extract noise from the data. Because a small data set as a training set may not represent the correct representation of all data." 2. Underfitting Heru
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Translator | Reviewed by Li Rui | Chonglou Artificial intelligence (AI) and machine learning (ML) models are becoming increasingly complex today, and the output produced by these models is a black box – unable to be explained to stakeholders. Explainable AI (XAI) aims to solve this problem by enabling stakeholders to understand how these models work, ensuring they understand how these models actually make decisions, and ensuring transparency in AI systems, Trust and accountability to address this issue. This article explores various explainable artificial intelligence (XAI) techniques to illustrate their underlying principles. Several reasons why explainable AI is crucial Trust and transparency: For AI systems to be widely accepted and trusted, users need to understand how decisions are made
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 Is Flash Attention stable? Meta and Harvard found that their model weight deviations fluctuated by orders of magnitude
May 30, 2024 pm 01:24 PM
Is Flash Attention stable? Meta and Harvard found that their model weight deviations fluctuated by orders of magnitude
May 30, 2024 pm 01:24 PM
MetaFAIR teamed up with Harvard to provide a new research framework for optimizing the data bias generated when large-scale machine learning is performed. It is known that the training of large language models often takes months and uses hundreds or even thousands of GPUs. Taking the LLaMA270B model as an example, its training requires a total of 1,720,320 GPU hours. Training large models presents unique systemic challenges due to the scale and complexity of these workloads. Recently, many institutions have reported instability in the training process when training SOTA generative AI models. They usually appear in the form of loss spikes. For example, Google's PaLM model experienced up to 20 loss spikes during the training process. Numerical bias is the root cause of this training inaccuracy,
