
 Technology peripherals
AI
The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Technology peripherals
AI
The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams

Such a powerful AI imitation ability is really unstoppable, completely unstoppable. Has the development of AI reached this level now?
You let your facial features fly around with your front foot, and the exact same expression is reproduced with your back foot. Staring, raising eyebrows, pouting, no matter how exaggerated the expression is, it is all imitated very well. in place.

Increase the difficulty, raise your eyebrows higher, open your eyes wider, and even the mouth shape is crooked, virtual Character avatars can also perfectly reproduce expressions.

When you adjust the parameters on the left side, the virtual avatar on the right side will also change its movements accordingly
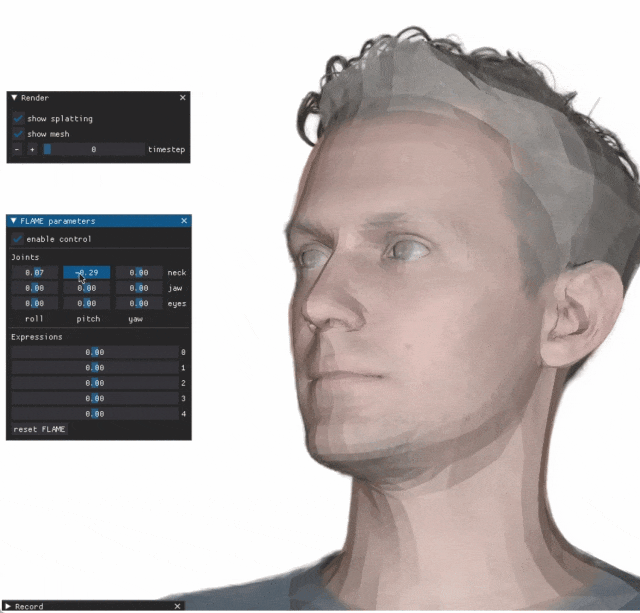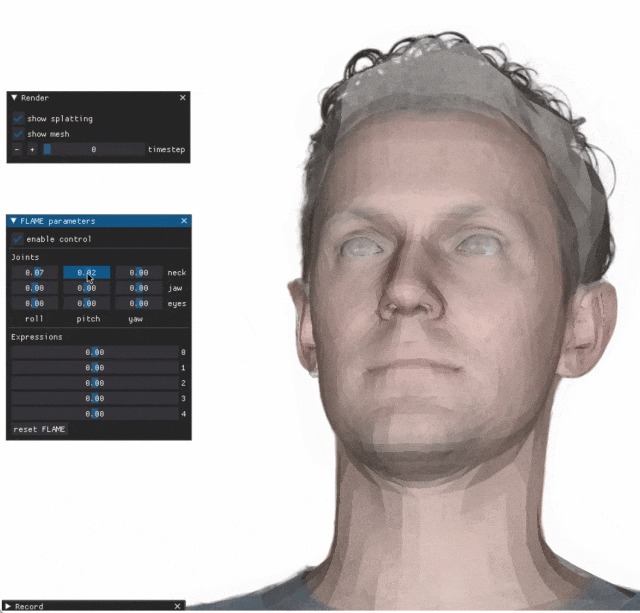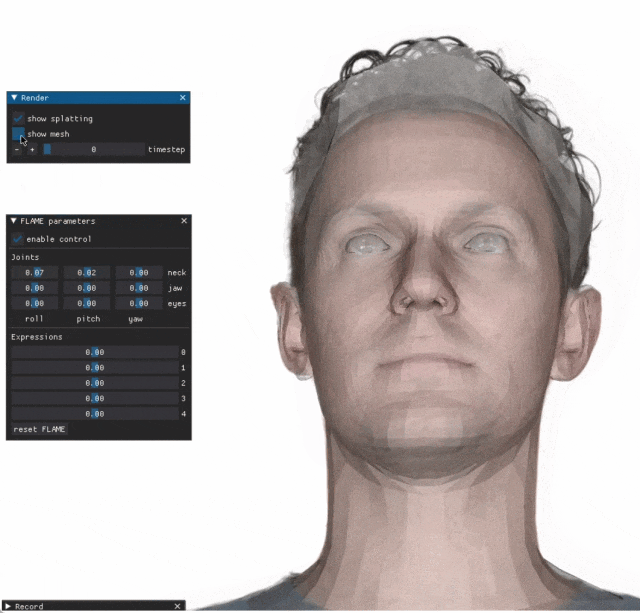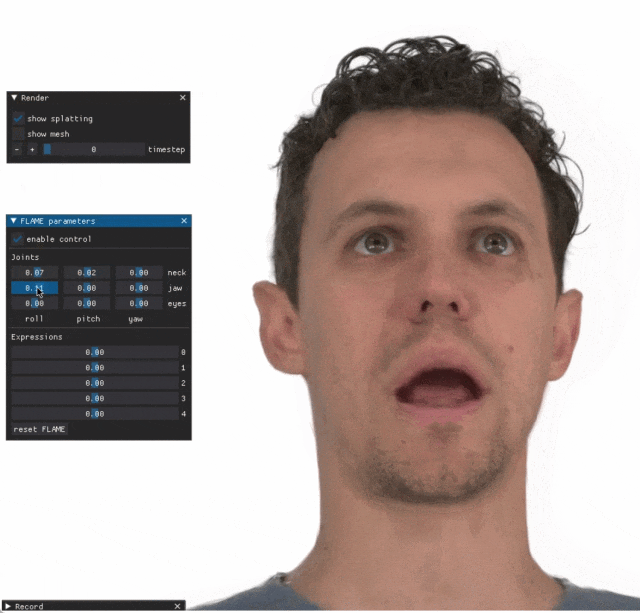
Give a close-up of the mouth and eyes. I cannot say that the imitation is exactly the same, I can only say that the expression is exactly the same (far right).

This research comes from institutions such as the Technical University of Munich, who proposed GaussianAvatars, a method that can be used to create expressions, poses and viewpoints (viewpoints) ), fully controllable, realistic head avatars.

- Paper address: https://arxiv.org/pdf/2312.02069.pdf
- Paper homepage: https://shenhanqian.github.io/gaussian-avatars
In the field of computer vision and graphics, Creating a virtual head that dynamically represents a human has always been a challenging problem. Especially in terms of expressing extreme facial expressions and details, it is quite difficult to capture details such as wrinkles and hair, and the generated virtual characters often suffer from visual artifacts
In the past period Over time, Neural Radiation Fields (NeRF) and its variants have achieved impressive results in reconstructing static scenes from multi-view observations. Subsequent research extended these methods, enabling NeRF to be used for dynamic scene modeling of human-tailored scenarios. However, a drawback of these methods is the lack of controllability and thus the inability to adapt well to new poses and expressions
The recently emerged “3D Gaussian Spraying” method achieves better performance than NeRF High rendering quality for real-time view compositing. However, this method does not support animation of the reconstructed output
This paper proposes GaussianAvatars, a dynamic 3D human head representation method based on three-dimensional Gaussian splats.
Specifically, given a FLAME (modeling the entire head) mesh, they initialized a 3D Gaussian at the center of each triangle. When a FLAME mesh is animated, each Gaussian model is translated, rotated, and scaled based on its parent triangle. The 3D Gaussian then forms a radiation field on top of the mesh, compensating for areas where the mesh is not accurately aligned or fails to reproduce certain visual elements.
In order to maintain a high degree of realism of virtual characters, this article adopts a binding inheritance strategy. At the same time, this paper also studies how to strike a balance between maintaining realism and stability to animate novel expressions and postures of virtual characters. The research results show that compared with existing research, GaussianAvatars performs well in novel view rendering and driving video reproduction

Method Introduction
As shown in Figure 2 below, the input to GaussianAvatars is a multi-view video record of the human head. For each time step, GaussianAvatars uses a photometric head tracker to match FLAME parameters to multi-view observations and known camera parameters.
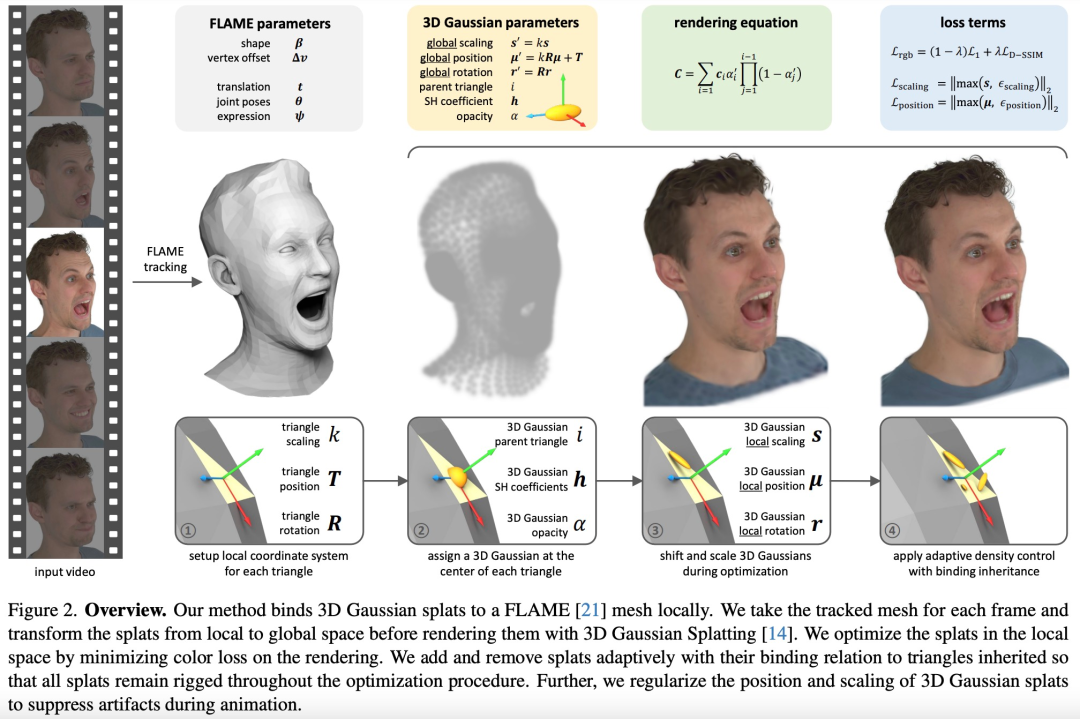
#FLAME The mesh’s vertex locations varied but the topology was the same, allowing the research team to create consistent connections between mesh triangles and 3D Gaussian splats. Render splat into an image using a differentiable tile rasterizer. Then, with real image supervision, realistic human head avatars are learned
#To obtain the best quality, static scenes need to be compacted and pruned by Gaussian splats through a set of adaptive density control operations. To achieve this, the research team designed a binding inheritance strategy that keeps new Gaussian points bound to the FLAME mesh without destroying the connection between the triangle and the splat
Experimental results
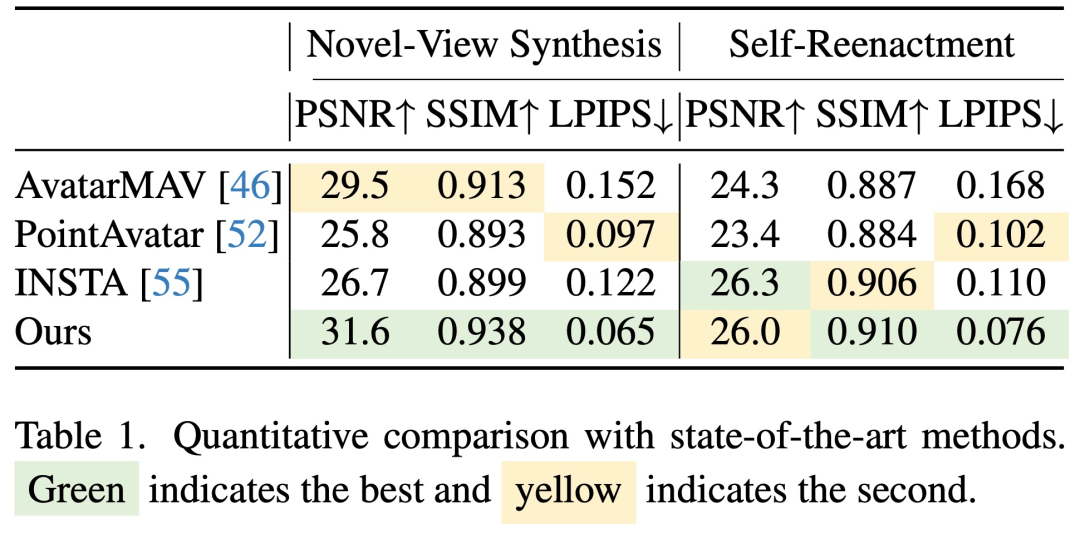
This study uses new perspective synthesis techniques to evaluate reconstruction quality and evaluate animation fidelity through self-reproduction. Figure 3 below shows the results of a qualitative comparison between different methods. In terms of new perspective synthesis, all methods are able to produce reasonable rendering results. However, upon closer inspection of PointAvatar's results, it can be seen that point artifacts occur due to its fixed point size. GaussianAvatars using 3D Gaussian anisotropic scaling technology can alleviate this problem

We can draw similar results from the quantitative comparison in Table 1 in conclusion. Compared with other methods, GaussianAvatars performs well in new view synthesis, is also excellent in self-reenactment, and has significantly reduced perceptual differences in LPIPS. It should be noted that self-reenactment is based on FLAME grid tracking and may not be fully aligned with the target image
In order to test the avatar animation in reality Performance in the world, this study conducted a cross-identity reproduction experiment in Figure 4. The results showed that the avatar accurately reproduced the source actor's blinking and mouth movements, showing lively and complex dynamics such as wrinkles.


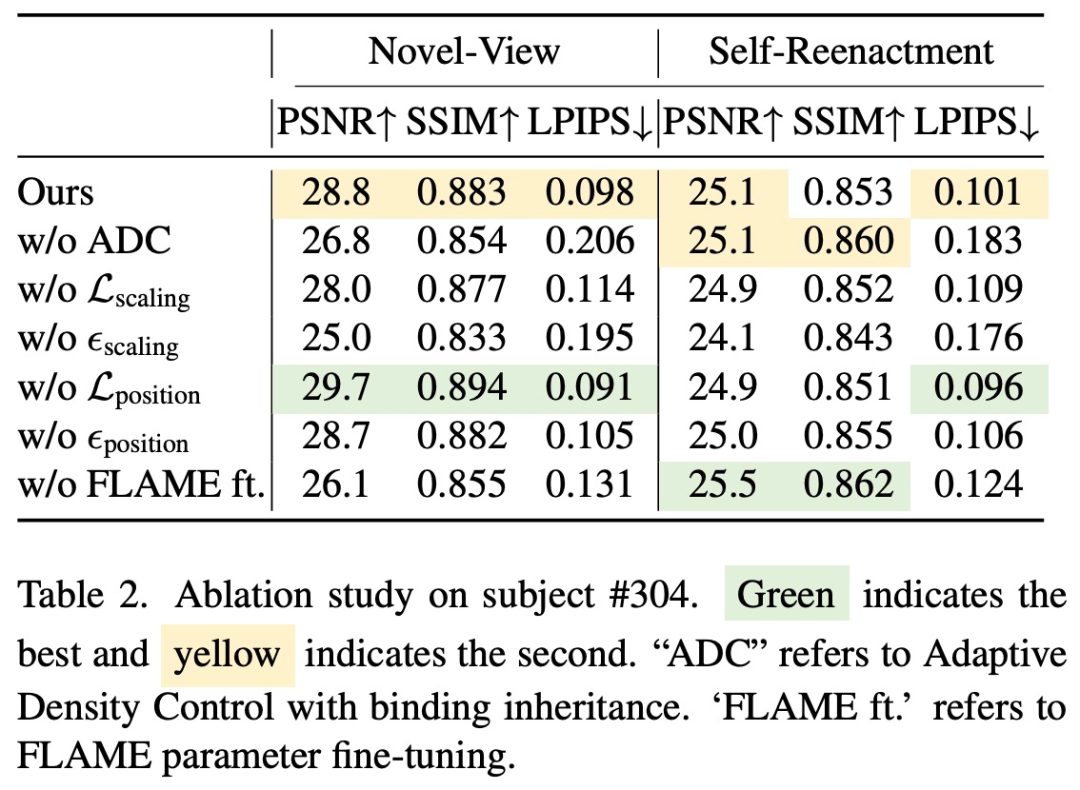
##In order to verify the effectiveness of the method components, the study also conducted an ablation experiment, and the results are as follows.
The above is the detailed content of The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
 The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
This week, FigureAI, a robotics company invested by OpenAI, Microsoft, Bezos, and Nvidia, announced that it has received nearly $700 million in financing and plans to develop a humanoid robot that can walk independently within the next year. And Tesla’s Optimus Prime has repeatedly received good news. No one doubts that this year will be the year when humanoid robots explode. SanctuaryAI, a Canadian-based robotics company, recently released a new humanoid robot, Phoenix. Officials claim that it can complete many tasks autonomously at the same speed as humans. Pheonix, the world's first robot that can autonomously complete tasks at human speeds, can gently grab, move and elegantly place each object to its left and right sides. It can autonomously identify objects
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
