In video generation scenarios, using Transformer as the denoising backbone of the diffusion model has been proven feasible by researchers such as Li Feifei. This can be considered a major success for Transformer in the field of video generation.
Recently, a video generation research has received a lot of praise, and was even rated as "the end of Hollywood" by an X netizen. Is it really that good? Let’s take a look at the effect first: 

#
It is obvious that these videos not only have almost no artifacts, but are also very coherent and full of details. It even seems that even if a few frames are really added to the movie blockbuster, it will not be obviously inconsistent. The author of these videos is the Window Attention Latent Transformer proposed by researchers from Stanford University, Google, and Georgia Institute of Technology, that is, the Window Attention Latent Transformer, referred to as W.A.L.T. This method successfully integrates the Transformer architecture into the latent video diffusion model. Professor Li Feifei of Stanford University is also one of the authors of the paper.
- Project website: https://walt-video-diffusion.github.io/
- Paper address: https://walt-video-diffusion.github.io/assets/W.A.L.T.pdf
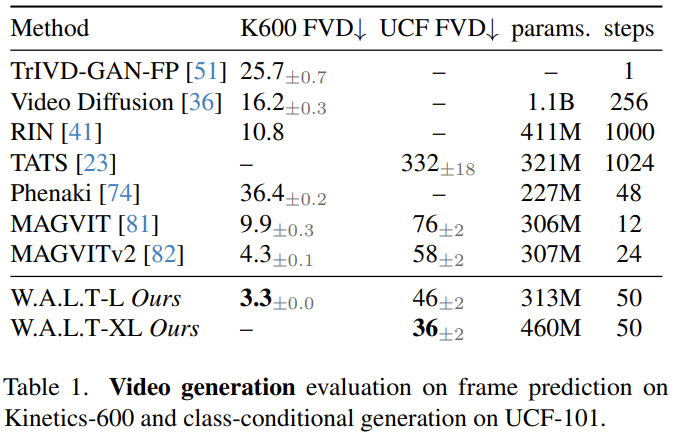
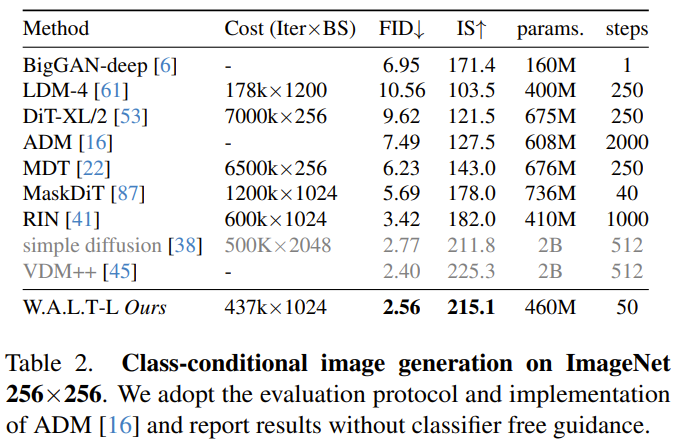
Prior to this, the Transformer architecture has been used in many different fields Great success has been achieved, with the exception of the area of generative modeling of images and videos, where currently the dominant paradigm is diffusion models. In the field of image and video generation, the diffusion model has become the main paradigm. However, among all video diffusion methods, the dominant backbone network is the U-Net architecture consisting of a series of convolutional and self-attention layers. U-Net is preferred because the memory requirements of the full attention mechanism in Transformer grow quadratically with the length of the input sequence. When processing high-dimensional signals such as video, this growth pattern makes the computational cost very high. The latent diffusion model (LDM) operates in a lower-dimensional latent space derived from autoencoders, thereby reducing computational requirements. In this case, a key design choice is the type of latent space: space compression versus space-time compression. People often prefer spatial compression because it enables the use of pretrained image autoencoders and LDMs, which are performed using large paired image-text datasets train. However, choosing spatial compression increases network complexity and makes Transformer difficult to use as the network backbone (due to memory constraints), especially when generating high-resolution videos. On the other hand, while spatiotemporal compression can alleviate these problems, it is not suitable for working with paired image-text datasets, which tend to be larger and more diverse than video-text datasets. W.A.L.T is a Transformer method for latent video diffusion models (LVDM). This method consists of two stages. #In the first stage, an autoencoder is used to map the video and image into a unified low-dimensional latent space. This allows a single generative model to be jointly trained on image and video datasets and significantly reduces the computational cost of generating high-resolution videos. For the second phase, the team designed a new Transformer block for latent video diffusion models, which consists of self-attention layers. Alternating between non-overlapping, window-restricted spatial and spatiotemporal attention. There are two main benefits of this design: First, it uses local window attention, which can significantly reduce computational requirements. Second, it facilitates joint training, where the spatial layer can process images and video frames independently, while the spatiotemporal layer is used to model temporal relationships in videos. #Although conceptually simple, this study is the first to experimentally demonstrate on a public benchmark that Transformer has superior generation quality and parameter efficiency in latent video diffusion . #Finally, to demonstrate the scalability and efficiency of the new method, the team also experimented with the difficult photorealistic image-to-video generation task. They trained three models cascaded together. These include a basic latent video diffusion model and two video super-resolution diffusion models. The result is a video with a resolution of 512×896 at 8 frames per second. This approach achieves state-of-the-art zero-shot FVD scores on the UCF-101 benchmark. 

Additionally, this model can be used to generate videos with consistent 3D camera motion. 
at In the field of generative modeling of video, a key design decision is the choice of latent space representation. Ideally, we would like to have a shared and unified compressed visual representation that can be used for generative modeling of both images and videos. Specifically, given a video sequence x, the goal is to learn a low-dimensional representation z that performs spatio-temporal compression at a certain temporal and spatial scale. In order to get a unified representation of video and still images, it is always necessary to encode the first frame of the video separately from the remaining frames. This allows you to treat still images as if they were only one frame of video. Based on this idea, the team’s actual design uses the MAGVIT-v2 tokenizer’s causal 3D CNN encoder-decoder architecture. After this stage, the input to the model becomes a batch of latent tensors, which represent a single video or a stack of discrete images (Figure 2). And the implicit representation here is real-valued and unquantized. Learn to generate images and videosPatchify. Following the original ViT design, the team tiled each hidden frame individually by converting it into a sequence of non-overlapping tiles. They also used learnable position embeddings, which are the sum of spatial and temporal position embeddings. The positional embedding is added to the linear projection of the tile. Note that for images, simply add the temporal position embedding corresponding to the first hidden frame. Window attention. Transformer models consisting entirely of global self-attention modules are computationally and memory expensive, especially for video tasks. For efficiency and joint processing of images and videos, the team computes self-attention in a windowed manner based on two types of non-overlapping configurations: space (S) and space-time (ST), see Figure 2. #The spatial window (SW) attention focuses on all tokens within a hidden frame. SW models spatial relationships in images and videos. The scope of the spatiotemporal window (STW) attention is a 3D window that models the temporal relationship between hidden frames of the video. Finally, in addition to absolute position embedding, they also used relative position embedding. According to reports, although this design is simple, it has high computational efficiency and can be jointly trained on image and video data sets. Unlike methods based on frame-level autoencoders, the new method does not produce flickering artifacts, a common problem with methods that encode and decode video frames separately. In order to achieve controllable video generation, in addition to taking the time step t as Conditional,diffusion models also tend to use additional conditional,information,c,such as category labels, natural language, past,frames or low-resolution videos. In the newly proposed Transformer backbone network, the team integrated three types of conditional mechanisms, as described below: Cross-attention. In addition to using self-attention layers in windowed Transformer blocks, they also added cross-attention layers for text conditional generation. When training the model with only videos, the cross-attention layer uses the same window-restricted attention as the self-attention layer, which means that S/ST will have a SW/STW cross-attention layer (Figure 2). However, for joint training, only the SW cross-attention layer is used. For cross-attention, the team’s approach is to concatenate input signals (queries) and conditional signals (key, value). AdaLN-LoRA. Adaptive normalization layers are important components in many generative and visual synthesis models. To incorporate adaptive normalization layers, a simple approach is to include an MLP layer for each layer i that regresses on the vector of conditional parameters. The number of parameters for these additional MLP layers grows linearly with the number of layers and quadratically with the model dimensionality. Inspired by LoRA, researchers proposed a simple solution to reduce model parameters: AdaLN-LoRA. Self-conditioning. In addition to being conditioned on external inputs, iterative generation algorithms can also be conditioned on samples they generate during inference. Specifically, Chen et al. modified the training process of the diffusion model in the paper "Analog bits: Generating discrete data using diffusion models with self-conditioning" so that the model generates a sample with a certain probability p_sc, and then based on this initial sample , use another forward pass to refine this estimate. There is also a certain probability that 1-p_sc only completes one forward pass.The team concatenated this model estimate with the input along the channel dimension and found that this simple technique worked well in combination with v-prediction. Autoregressive generationIn order to generate long videos through autoregressive prediction, the team The models were also jointly trained on the frame prediction task. This is achieved by giving the model a certain probability p_fp conditioned on past frames during the training process. The condition is either 1 hidden frame (image-to-video generation) or 2 hidden frames (video prediction). This condition is integrated into the model by channel dimensions along the noisy implicit input. Standard classifier-less bootstrapping is used during inference, with c_fp as the conditional signal. Computation of generating high-resolution video using a single model The cost is very high and basically difficult to achieve. The researchers refer to the paper "Cascaded diffusion models for high fidelity image generation" and use a cascade method to cascade the three models, and they operate at increasingly higher resolutions. The base model generates video at a resolution of 128×128, which is then upsampled twice through two super-resolution stages. The low-resolution input (video or image) is first spatially upsampled using a depth-to-space convolution operation. Note that unlike training (where ground truth low-resolution input is provided), inference relies on implicit representations generated in previous stages. To reduce this difference and make the super-resolution stage more robust to artifacts produced in the low-resolution stage, the team also used noise-conditional enhancement . Aspect ratio fine-tuning. To simplify training and exploit more data sources with different aspect ratios, they used a square aspect ratio in the base stage. They then fine-tuned the model on a subset of the data to generate videos with a 9:16 aspect ratio via positional embedding interpolation. The researchers evaluated the newly proposed method on a variety of tasks: with categories Conditional image and video generation, frame prediction, text-based video generation. They also explored the effects of different design choices through ablation studies. Video generation: in both UCF-101 and Kinetics-600 On each data set, W.A.L.T outperforms all previous methods in terms of FVD index, see Table 1. Image generation: Table 2 compares the results of W.A.L.T with other current best methods for generating 256×256 resolution images. The newly proposed model outperforms previous methods and does not require specialized scheduling, convolutional induction bias, improved diffusion loss, and classifier-free guidance. Although VDM has a slightly higher FID score, it has many more model parameters (2B). To understand the contribution of different design decisions, the team also conducted ablation studies. Table 3 presents the results of the ablation study in terms of patch size, window attention, self-conditioning, AdaLN-LoRA, and autoencoders. The team works on text-to-image and text-to-video We jointly trained W.A.L.T’s text-to-video generation capabilities. They used a dataset from the public internet and internal sources containing ~970M text-image pairs and ~89M text-video pairs. The resolution of the basic model (3B) is 17×128×128, and the two cascaded super-resolution models are 17×128×224 → 17× 256×448 (L, 1.3B, p = 2) and 17× 256×448→ 17×512×896 (L, 419M, p = 2). They also fine-tuned the aspect ratio in the base stage to produce videos at 128×224 resolution. All text-to-video generation results use a classifier-free bootstrapping approach. Below are some generated video examples, for more please visit the project website: Text: A squirrel eating a burger.
Text: A cat riding a ghost rider bike through the desert.
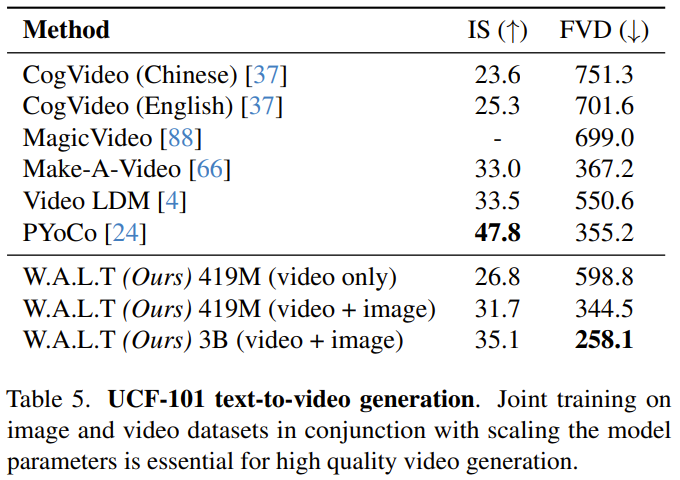
Evaluating text-based video generation in a scientific manner remains a challenge, in part due to the lack of standardized training datasets and benchmarks. So far, researchers' experiments and analyzes have focused on standard academic benchmarks, which use the same training data to ensure fair comparisons. Nevertheless, for comparison with previous text-to-video generation studies, the team reports results on the UCF-101 dataset in a zero-sample evaluation setting. It can be seen that the advantages of W.A.L.T are obvious. Please refer to the original paper for more details. The above is the detailed content of Using Transformer for the diffusion model, AI-generated videos achieve photorealism. For more information, please follow other related articles on the PHP Chinese website!





 Unable to locate program input point in dynamic link library
Unable to locate program input point in dynamic link library
 ps curve shortcut key
ps curve shortcut key
 The difference between injective and surjective
The difference between injective and surjective
 vue references js files
vue references js files
 What should I do if eDonkey Search cannot connect to the server?
What should I do if eDonkey Search cannot connect to the server?
 Can data between Hongmeng system and Android system be interoperable?
Can data between Hongmeng system and Android system be interoperable?
 Why can't Amazon open
Why can't Amazon open
 What is the mobile service password?
What is the mobile service password?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



