
 Technology peripherals
AI
A deeper understanding of visual Transformer, analysis of visual Transformer
Technology peripherals
AI
A deeper understanding of visual Transformer, analysis of visual Transformer
A deeper understanding of visual Transformer, analysis of visual Transformer

This article is reprinted with the authorization of the Autonomous Driving Heart public account. Please contact the source when reprinting
Write in front&&The author’s personal understanding
Currently, algorithm models based on the Transformer structure have had a great impact in the field of computer vision (CV). They surpass previous convolutional neural network (CNN) algorithm models on many basic computer vision tasks. The following is the latest LeaderBoard ranking of different basic computer vision tasks that I found. Through LeaderBoard, we can see the dominance of the Transformer algorithm model in various computer vision tasks
- Image Classification Task
The first is LeaderBoard on ImageNet. It can be seen from the list that among the top five, each model uses the Transformer structure, while the CNN structure is only partially used, or combined with Transformer. Way.

LeaderBoard for image classification task
- Object detection task
The next step is on COCO test-dev LeaderBoard, as can be seen from the list, more than half of the top five are based on algorithm structures such as DETR.
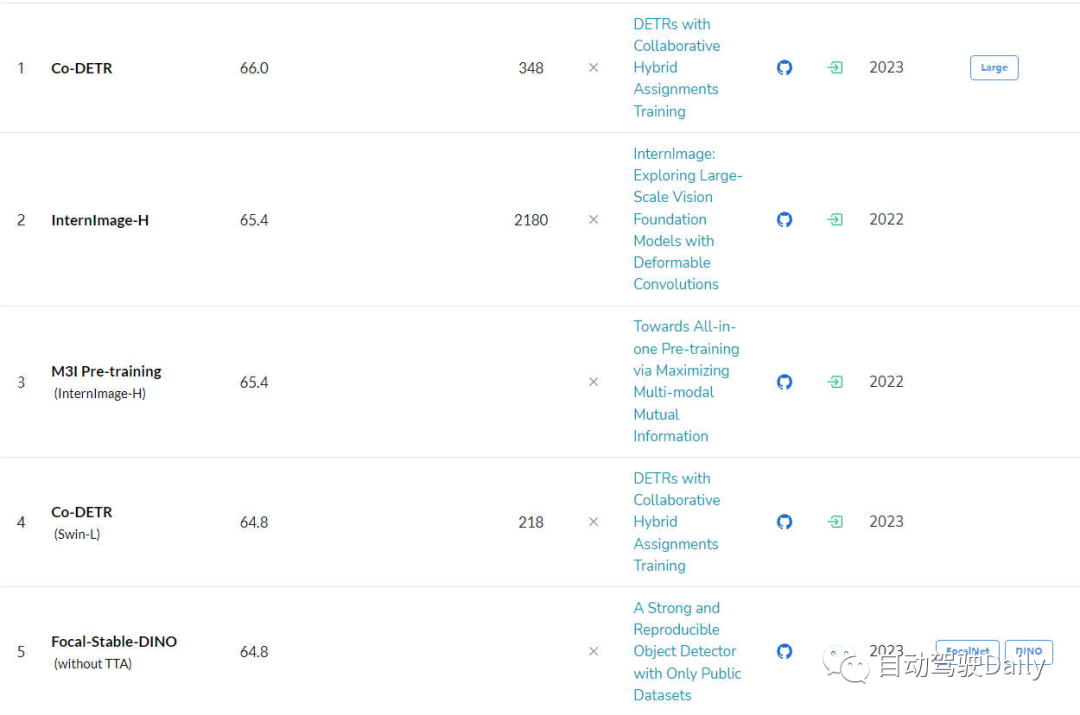 LeaderBoard for the target detection task
LeaderBoard for the target detection task
- Semantic segmentation task
The last is the LeaderBoard on the ADE20K val, which can also be viewed through the list It turns out that among the top few on the list, the Transformer structure still occupies the current main force.
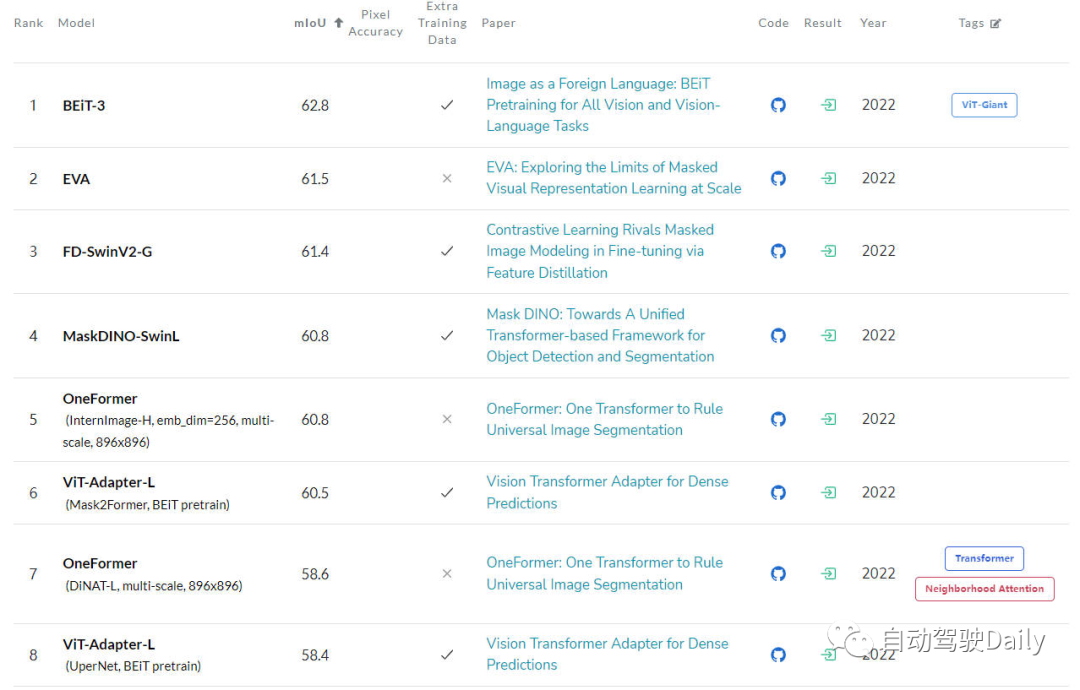 LeaderBoard for semantic segmentation tasks
LeaderBoard for semantic segmentation tasks
Although Transformer has shown great development potential in China, the current computer vision community has not fully grasped the inner working principles of Vision Transformer. It also does not grasp the basis for its decision-making (output prediction results), so the need for its interpretability gradually becomes prominent. Only by understanding how such models make decisions can we improve their performance and build trust in artificial intelligence systems
The main purpose of this article is to study the different interpretability methods of Vision Transformer and compare them according to different The research motivation, structure type and application scenarios of the algorithm are classified to form a review article
Analysis of Vision Transformer
Because just mentioned, the structure of Vision Transformer It has achieved very good results in various basic computer vision tasks. So many methods have emerged in the computer vision community to enhance its interpretability. In this article, we mainly focus on classification tasks, starting from Common Attribution Methods, Attention-based Methods, Pruning-based Methods, Inherently Explainable Methods、Other Tasks Among these five aspects, the latest and classic tasks are selected for introduction. Here is the mind map that appears in the paper. You can read it in more detail based on what you are interested in~
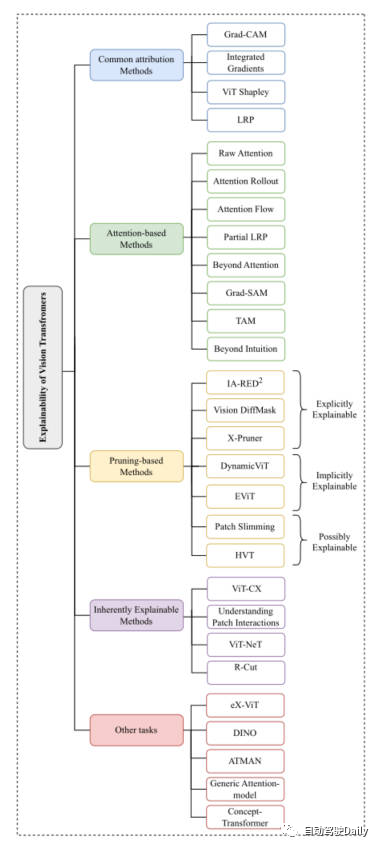
Mind map of this article
Common Attribution Methods
The explanation of attribute-based methods usually starts with the process of how the input features of the model gradually obtain the final output results. This type of method is mainly used to measure the correlation between the model's prediction results and the input features
Among these methods, such as Grad-CAM and Integrated Gradients algorithms It is directly applied to the algorithm based on visual Transformer. Some other methods like SHAP and Layer-Wise Relevance Propagation (LRP) have been used to explore ViT-based architectures. However, due to the very high computational cost of methods such as SHAP, the recent ViT Shapely algorithm was designed to adapt to ViT-related application research.
Attention-based Methods
Vision Transformer obtains powerful feature extraction capabilities through its attention mechanism. Among attention-based interpretability methods, visualizing the attention weight results is a very effective method. This article will introduce several visualization techniques
- Raw Attention: As the name suggests, this method is to visualize the attention weight map obtained by the middle layer of the network model, so as to analyze the effect of the model.
- Attention Rollout: This technology tracks the transmission of information from the input token to the intermediate embedding by expanding attention weights in different layers of the network.
- Attention Flow: This method treats the attention graph as a flow network and uses the maximum flow algorithm to calculate the maximum flow value from the intermediate embedding to the input token.
- partialLRP: This method is proposed for visualizing the multi-head attention mechanism in Vision Transformer, and also considers the importance of each attention head.
- Grad-SAM: This method is used to alleviate the limitations of relying solely on the original attention matrix to explain model predictions, prompting researchers to use gradients in the original attention weights.
- Beyond Intuition: This method is also a method for explaining attention, including two stages of attention perception and reasoning feedback.
Finally, here is an attention visualization diagram of different interpretability methods. You can feel the difference between different visualization methods for yourself.

Comparison of attention maps of different visualization methods
Pruning-based Methods
Pruning is a very effective method that is widely used Used to optimize the efficiency and complexity of transformer structures. The pruning method reduces the number of parameters and computational complexity of the model by deleting redundant or useless information. Although pruning algorithms focus on improving the computational efficiency of the model, this type of algorithm can still achieve interpretability of the model.
The pruning methods based on Vision-Transformer in this article can be roughly divided into three categories: explicitly explainable (explicitly explainable), implicitly explainable (implicitly explainable) formula can be explained), possibly explainable (may be explainable).
-
Explicitly Explainable
Among pruning-based methods, there are several types of methods that can provide simpler and more explainable models.
- IA-RED^2: The goal of this method is to achieve an optimal balance between the computational efficiency and interpretability of the algorithm model. And in this process, the flexibility of the original ViT algorithm model is maintained.
- X-Pruner: This method is a method for pruning salience units by creating an interpretable perceptual mask that measures the Predict the contribution in a specific class.
- Vision DiffMask: This pruning method includes adding a gating mechanism to each ViT layer. Through the gating mechanism, the output of the model can be maintained while shielding the input. Beyond this, the algorithmic model can clearly trigger a subset of the remaining images, allowing for better understanding of the model's predictions.
-
Implicitly Explainable
Among the pruning-based methods, there are also some classic methods that can be divided into the implicit explainability model category. - Dynamic ViT: This method uses a lightweight prediction module to estimate the importance of each token based on the current characteristics. This lightweight module is then added to different layers of ViT to prune redundant tokens in a hierarchical manner. Most importantly, this method enhances interpretability by gradually locating key image parts that contribute most to classification.
- Efficient Vision Transformer (EViT): The core idea of this method is to accelerate EViT by reorganizing tokens. By calculating attention scores, EViT retains the most relevant tokens while fusing less relevant tokens into additional tokens. At the same time, in order to evaluate the interpretability of EViT, the author of the paper visualized the token recognition process on multiple input images.
-
Possibly Explainable
Although this type of method was not originally intended to improve the explainability of ViT, this type of method provides a lot of opportunities for further research on the explainability of the model. Great potential.
- Patch Slimming: Accelerate ViT by focusing on redundant patches in images through a top-down approach. The algorithm selectively retains the ability of key patches to highlight important visual features, thereby enhancing interpretability.
- Hierarchical Visual Transformer (HVT): This method is introduced to enhance the scalability and performance of ViT. As the model depth increases, the sequence length gradually decreases. Furthermore, by dividing ViT blocks into multiple stages and applying pooling operations at each stage, the computational efficiency is significantly improved. Given the progressive concentration on the most important components of the model, there is an opportunity to explore its potential impact on enhancing interpretability and explainability.
Inherently Explainable Methods
Among the different interpretable methods, there is a class of methods that mainly develops models that can explain algorithms intrinsically. However, these models are usually difficult to achieve with more complex ones. The same level of accuracy as the black box model. Therefore, a careful balance must be considered between interpretability and performance. Next, some classic works are briefly introduced.
- ViT-CX: This method is a mask-based interpretation method customized for the ViT model. This approach relies on patch embedding and its impact on model output, rather than focusing on them. This method consists of two stages: mask generation and mask aggregation, thereby providing a more meaningful saliency map.
- ViT-NeT: This method is a new neural tree decoder that describes the decision-making process through tree structures and prototypes. At the same time, the algorithm also allows for visual interpretation of the results.
- R-Cut: This method enhances the interpretability of ViT through Relationship Weighted Out and Cut. This method includes two modules, namely Relationship Weighted Out and Cut modules. The former focuses on extracting specific classes of information from the middle layer, emphasizing relevant features. The latter performs fine-grained feature decomposition. By integrating both modules, dense class-specific interpretability maps can be generated.
Other Tasks
ViT-based architecture still needs to be explained for other computer vision tasks in the exploration. Some interpretability methods specifically targeted at other tasks have been proposed, and the latest work in related fields will be introduced below
- eX-ViT: This algorithm is a new interpretable visual transformer based on weakly supervised semantic segmentation. In addition, in order to improve interpretability, an attribute-oriented loss module is introduced, which contains three losses: global-level attribute-oriented loss, local-level attribute discriminability loss, and attribute diversity loss. The former uses attention maps to create interpretable features, while the latter two enhance attribute learning.
- DINO: This method is a simple self-supervised method and a self-distillation method without labels. The final learned attention map can effectively preserve the semantic areas of the image, thereby achieving interpretable purposes.
- Generic Attention-model: This method is an algorithm model for prediction based on the Transformer architecture. The method is applied to the three most commonly used architectures, namely pure self-attention, self-attention combined with joint attention, and encoder-decoder attention. To test the interpretability of the model, the authors used a visual question answering task, however, it is also applicable to other CV tasks such as object detection and image segmentation.
- ATMAN: This is a modality-agnostic perturbation method that uses an attention mechanism to generate a correlation map of the input relative to the output prediction. This approach attempts to understand deformation prediction through memory efficient attention operations.
- Concept-Transformer: This algorithm generates explanations of model output by highlighting attention scores for user-defined high-level concepts, ensuring trustworthiness and reliability.
Future Outlook
Currently, algorithm models based on the Transformer architecture have achieved outstanding results in various computer vision tasks. However, there is currently a lack of obvious research on how to use interpretability methods to promote model debugging and improvement, and improve model fairness and reliability, especially in ViT applications.
This article aims to use image classification The task is to classify and organize the interpretability algorithm models based on Vision Transformer to help readers better understand the architecture of such models. I hope it will be helpful to everyone

What needs to be rewritten is: Original link: https://mp.weixin.qq.com/s/URkobeRNB8dEYzrECaC7tQ
The above is the detailed content of A deeper understanding of visual Transformer, analysis of visual Transformer. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
