
 Technology peripherals
AI
QTNet: New temporal fusion solution for point clouds, images and multi-modal detectors (NeurIPS 2023)
Technology peripherals
AI
QTNet: New temporal fusion solution for point clouds, images and multi-modal detectors (NeurIPS 2023)
QTNet: New temporal fusion solution for point clouds, images and multi-modal detectors (NeurIPS 2023)

Written in front & personal understanding
Time series fusion is an effective way to improve the perception ability of autonomous driving 3D target detection, but the current method has cost overhead when applied in actual autonomous driving scenarios. And other issues. The latest research article "Query-based Explicit Motion Timing Fusion for 3D Object Detection" proposed a new timing fusion method in NeurIPS 2023, which takes sparse queries as the object of timing fusion and uses explicit motion information to generate timing Attention matrices to adapt to the characteristics of large-scale point clouds. This method was proposed by researchers from Huazhong University of Science and Technology and Baidu, and is called QTNet: a temporal fusion method for 3D target detection based on query and explicit motion. Experiments have proven that QTNet can bring consistent performance improvements to point clouds, images, and multi-modal detectors at almost no cost overhead

- Paper link :https://openreview.net/pdf?id=gySmwdmVDF
- Code link: https://github.com/AlmoonYsl/QTNet
Problem background
Thanks to the temporal continuity of the real world, information in the time dimension can make the perception information more complete, thereby improving the accuracy and robustness of target detection. For example, timing information can help solve problems in target detection. It solves the occlusion problem, provides the target's motion status and speed information, and provides the target's persistence and consistency information. Therefore, how to efficiently utilize timing information is an important issue in autonomous driving perception. Existing timing fusion methods are mainly divided into two categories. One type is time series fusion based on dense BEV features (applicable to point cloud/image time series fusion), and the other type is time series fusion based on 3D Proposal features (mainly aimed at point cloud time series fusion methods). For temporal fusion based on BEV features, since more than 90% of points on BEV are background, this type of method does not pay more attention to foreground objects, which results in a lot of unnecessary computational overhead and sub-optimal performance. For the time series fusion algorithm based on 3D Proposal, it generates 3D Proposal features through time-consuming 3D RoI Pooling. Especially when there are many targets and a large number of point clouds, the overhead caused by 3D RoI Pooling is actually very high. It is often difficult to accept in applications. In addition, 3D Proposal features heavily rely on Proposal quality, which is often limited in complex scenes. Therefore, it is difficult for current methods to efficiently introduce temporal fusion to enhance the performance of 3D target detection in a very low-overhead manner.
How to achieve efficient timing fusion?
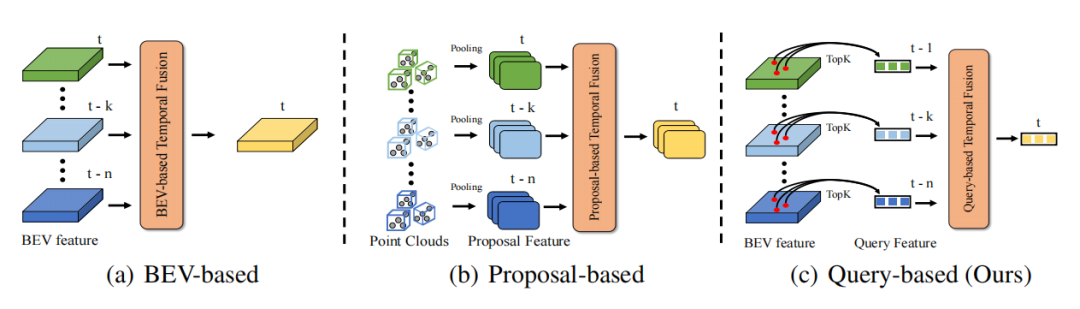
DETR is a very excellent target detection paradigm. Its Query design and Set Prediction ideas effectively realize an elegant detection paradigm without any post-processing. . In DETR, each Query represents an object, and Query is very sparse compared to dense features (generally the number of Query is set to a relatively small fixed number). If Quey is used as the object of timing fusion, the problem of computational overhead will naturally drop to a lower level. Therefore, DETR's Query paradigm is a paradigm naturally suitable for timing fusion. Temporal fusion requires the construction of object associations between multiple frames to achieve the synthesis of temporal context information. So the main problem is how to build a Query-based timing fusion pipeline and establish a correlation between the Query between the two frames.
- Due to the motion of the self-vehicle in actual scenes, the point clouds/images of the two frames are often misaligned in coordinate systems, and in practical applications it is impossible to compare all historical frames in the current frame. Re-forward the network to extract the features of the aligned point cloud/image. Therefore, this article uses Memory Bank to store only the Query features obtained from historical frames and their corresponding detection results to avoid repeated calculations.
- Because point clouds and images are very different in describing target features, it is not feasible to build a unified temporal fusion method through the feature level. However, in three-dimensional space, both point cloud and image modality can depict the correlation between adjacent frames through the geometric position/motion information relationship of the target. Therefore, this paper uses the geometric position of the object and the corresponding motion information to guide the attention matrix of the object between two frames.
Method introduction
The core idea of QTNet is to use Memory Bank to store the Query features obtained in historical frames and their corresponding detection results to avoid duplication Calculate the cost of historical frames. Between two frames of Query, use motion-guided attention matrix for relationship modeling
Overall framework
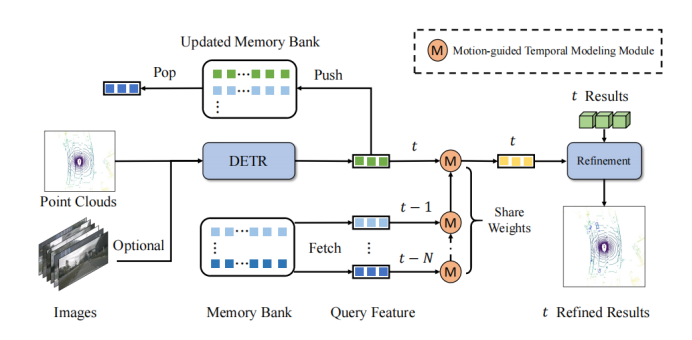
As shown in the framework diagram, QTNet includes a 3D target detector with a 3D DETR structure (LiDAR, Camera and multi-modal are available), a Memory Bank and a Motion-guided Temporal Modeling Module (MTM) for timing fusion. QTNet obtains the Query features and detection results of the corresponding frame through the 3D target detector of the DETR structure, and sends the obtained Query features and detection results to the Memory Bank in a first-in, first-out queue (FIFO) manner. The number of Memory Banks is set to the number of frames required for timing fusion. For timing fusion, QTNet reads data from the Memory Bank starting from the farthest time, and uses the MTM module to iteratively fuse all the features in the Memory Bank from the frame to the frame. Enhance the Query feature of the current frame, and Refine the corresponding detection result of the current frame based on the enhanced Query feature.
Specifically, QTNet fuses the Query features of and frames in frames and , and obtain the enhanced Query feature of the frame. Then, QTNet fuses the Query features of the and frames. In this way, it is continuously integrated to frames through iteration. Note that the MTM used here from the frame to the frame all share parameters.
Motion Guided Attention Module
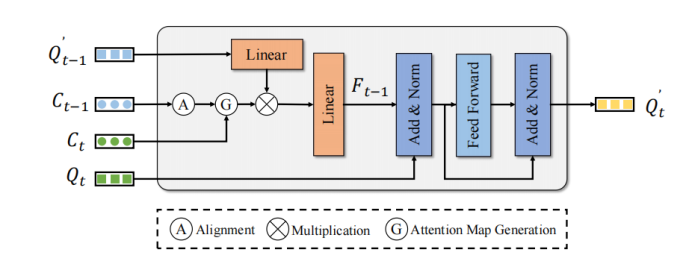
MTM uses the center point position of the object to explicitly generate frames Query and Attention matrix of frame Query. Given the ego pose matrix and , the center point of the object, and the speed. First, MTM uses the ego pose and the speed information of the object prediction to move the object in the previous frame to the next frame and align the coordinate systems of the two frames:
Then pass the frame object center point and The corrected center point of the frame constructs the Euclidean cost matrix . In addition, in order to avoid possible false matching, this article uses the category and distance threshold to construct the attention mask :
Convert the cost matrix The ultimate goal is to form an attention matrix
Apply the attention matrix to the enhanced Query features of the frame to aggregate the temporal features to enhance Query features of the frame:
Finally enhanced Query features of the frame Refine the corresponding detection results through simple FFN to achieve Enhance detection performance.
Decoupled temporal fusion structure
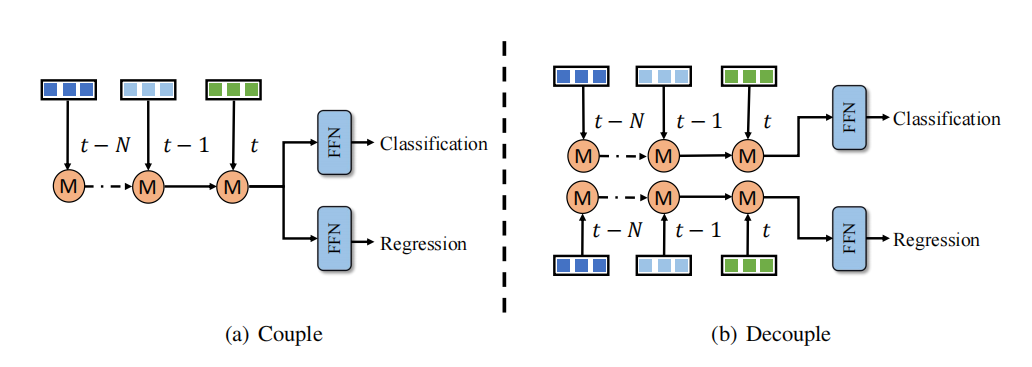
It is observed that there is an imbalance problem in classification and regression learning of temporal fusion, a solution Time series fusion branches are designed for classification and regression respectively. However, this decoupling approach adds more computational cost and latency, which is unacceptable for most methods. In contrast, QTNet utilizes an efficient timing fusion design, its computational cost and delay are negligible, and it performs better than the entire 3D detection network. Therefore, this article adopts the decoupling method of classification and regression branches in time series fusion to achieve better detection performance at negligible cost, as shown in the figure
Experimental Effect
QTNet achieves consistent point increase on point clouds/images/multi-modalities
After verification on the nuScenes data set, it was found that QTNet does not use the future When information, TTA and model are integrated, an mAP of 68.4 and an NDS of 72.2 are achieved, achieving SOTA performance. Compared with MGTANet that uses future information, QTNet performs better than MGTANet in the case of 3-frame timing fusion, increasing mAP by 3.0 and NDS by 1.0 respectively
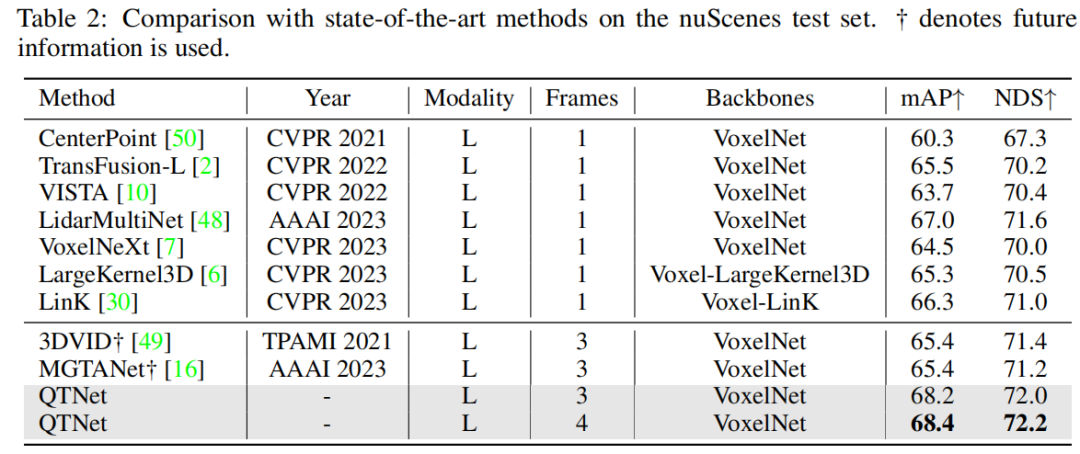
In addition, this article has also been verified on multi-modal and ring view-based methods. The experimental results on the nuScenes validation set prove the effectiveness of QTNet on different modalities.
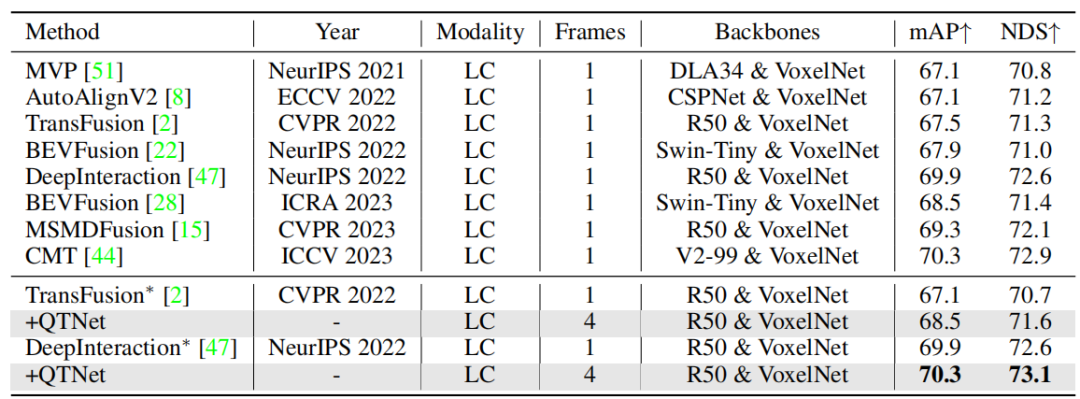

For practical applications, the cost overhead of timing fusion is very important. This article conducts analysis and experiments on QTNet in three aspects: calculation amount, delay and parameter amount. The results show that compared with the entire network, QTNet's computational overhead, time delay and parameter amount caused by different baselines are negligible, especially the calculation amount only uses 0.1G FLOPs (LiDAR baseline)
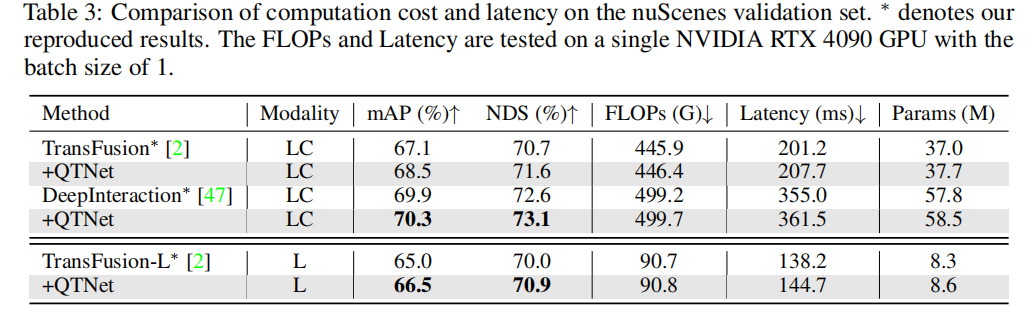
Comparison of different timing fusion paradigms
In order to verify the superiority of the Query-based timing fusion paradigm, we selected different representative frontier timings Fusion methods are compared. Through experimental results, it is found that the timing fusion algorithm based on Query paradigm is more efficient than those based on BEV and Proposal paradigm. Using only 0.1G FLOPs and 4.5ms overhead, QTNet shows better performance, while the overall parameter amount is only 0.3M
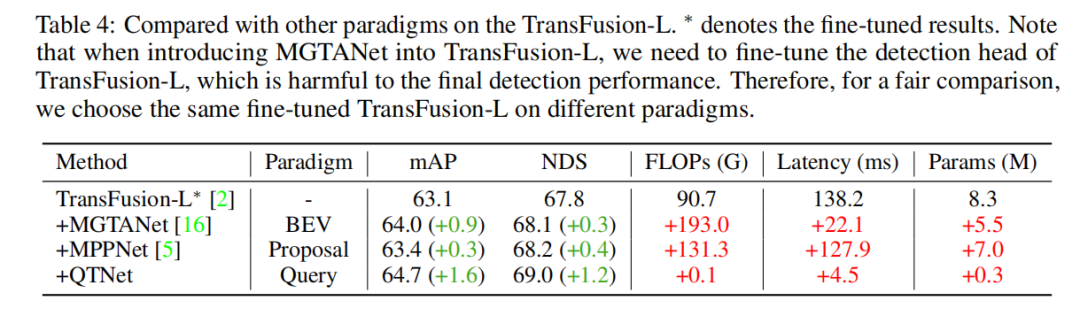
Ablation Experiment
This study conducted an ablation experiment based on LiDAR baseline on the nuScenes verification set, through 3-frame temporal fusion. Experimental results show that simply using Cross Attention to model temporal relationships has no obvious effect. However, when using MTM, the detection performance is significantly improved, which illustrates the importance of explicit motion guidance in large-scale point clouds. In addition, through ablation experiments, it was also found that the overall design of QTNet is very lightweight and efficient. When using 4 frames of data for timing fusion, the calculation amount of QTNet is only 0.24G FLOPs, and the delay is only 6.5 milliseconds
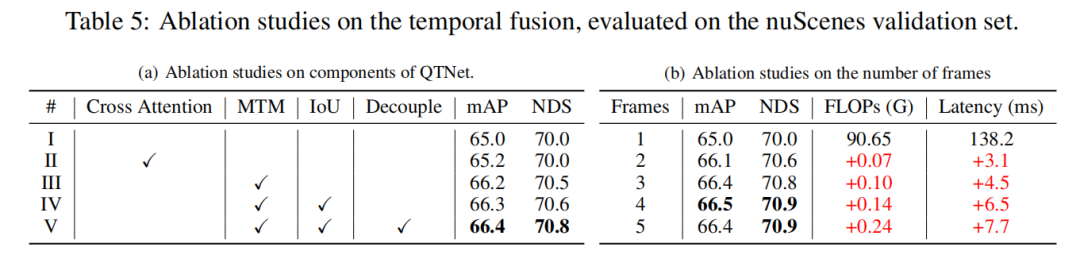
##Visualization of MTM
In order to explore why MTM is better than Cross Attention, this article visualizes the attention matrix of objects between two frames, where the same ID represents the same object between two frames. It can be found that the attention matrix (b) generated by MTM is more discriminative than the attention matrix (a) generated by Cross Attention, especially the attention matrix between small objects. This shows that the attention matrix guided by explicit motion makes it easier for the model to establish the association of objects between two frames through physical modeling. This article only briefly explores the issue of physically establishing timing correlations in timing fusion. It is still worth exploring how to better build timing correlations.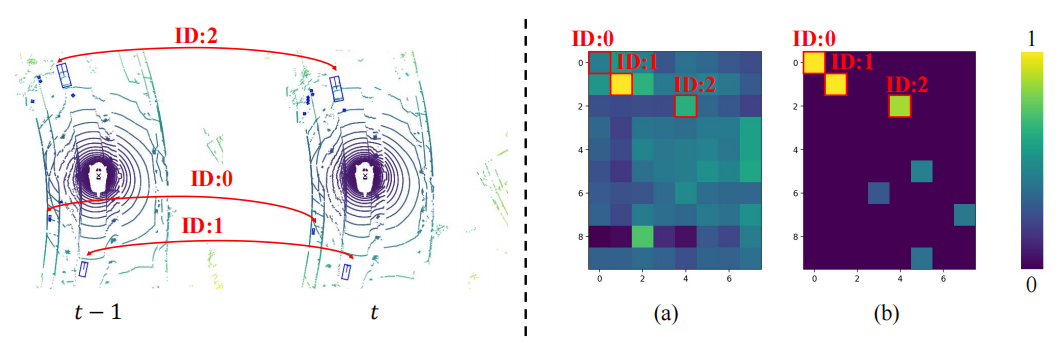
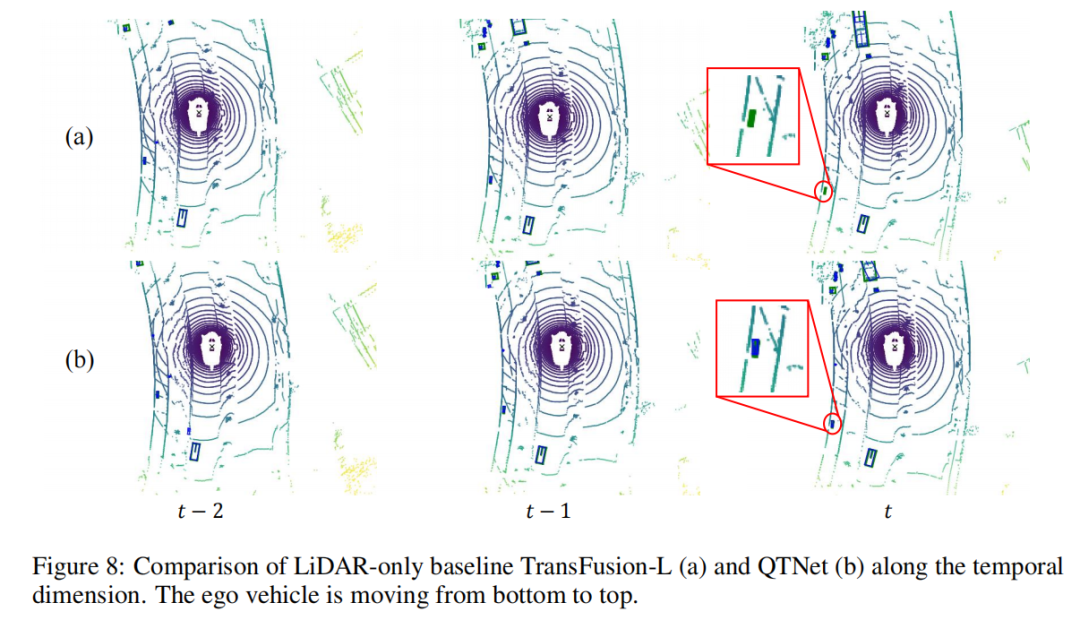
Visualization of detection results
This article uses scene sequences as the object to conduct visual analysis of detection results. It can be found that the small object in the lower left corner quickly moves away from the vehicle starting from frame, which causes the baseline to miss the object in frame . However, QTNet can still detect it in frame The object was detected, which proves the effectiveness of QTNet in temporal fusion.
Summary of this article
This article proposes a more efficient Query-based temporal fusion method QTNet for the current 3D target detection task. Its main core has two points: one is to use sparse Query as the object of temporal fusion and store historical information through Memory Bank to avoid repeated calculations; the other is to use explicit motion modeling to guide the generation of the attention matrix between temporal queries , to achieve temporal relationship modeling. Through these two key ideas, QTNet can efficiently implement timing fusion that can be applied to LiDAR, Camera, and multi-modality, and consistently enhance the performance of 3D target detection with negligible cost overhead.
The above is the detailed content of QTNet: New temporal fusion solution for point clouds, images and multi-modal detectors (NeurIPS 2023). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 Solution to i7-7700 unable to upgrade to Windows 11
Dec 26, 2023 pm 06:52 PM
Solution to i7-7700 unable to upgrade to Windows 11
Dec 26, 2023 pm 06:52 PM
The performance of i77700 is completely sufficient to run win11, but users find that their i77700 cannot be upgraded to win11. This is mainly due to restrictions imposed by Microsoft, so they can install it as long as they skip this restriction. i77700 cannot be upgraded to win11: 1. Because Microsoft limits the CPU version. 2. Only the eighth generation and above versions of Intel can directly upgrade to win11. 3. As the 7th generation, i77700 cannot meet the upgrade needs of win11. 4. However, i77700 is completely capable of using win11 smoothly in terms of performance. 5. So you can use the win11 direct installation system of this site. 6. After the download is complete, right-click the file and "load" it. 7. Double-click to run the "One-click
 Learn about 3D Fluent emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Learn about 3D Fluent emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
You must remember, especially if you are a Teams user, that Microsoft added a new batch of 3DFluent emojis to its work-focused video conferencing app. After Microsoft announced 3D emojis for Teams and Windows last year, the process has actually seen more than 1,800 existing emojis updated for the platform. This big idea and the launch of the 3DFluent emoji update for Teams was first promoted via an official blog post. Latest Teams update brings FluentEmojis to the app Microsoft says the updated 1,800 emojis will be available to us every day
 Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt
Apr 12, 2023 am 08:19 AM
Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt
Apr 12, 2023 am 08:19 AM
Hello everyone. Today I would like to share with you a fall detection project, to be precise, it is human movement recognition based on skeletal points. It is roughly divided into three steps: human body recognition, human skeleton point action classification project source code has been packaged, see the end of the article for how to obtain it. 0. chatgpt First, we need to obtain the monitored video stream. This code is relatively fixed. We can directly let chatgpt complete the code written by chatgpt. There is no problem and can be used directly. But when it comes to business tasks later, such as using mediapipe to identify human skeleton points, the code given by chatgpt is incorrect. I think chatgpt can be used as a toolbox that is independent of business logic. You can try to hand it over to c
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Paint 3D in Windows 11: Download, Installation, and Usage Guide
Apr 26, 2023 am 11:28 AM
Paint 3D in Windows 11: Download, Installation, and Usage Guide
Apr 26, 2023 am 11:28 AM
When the gossip started spreading that the new Windows 11 was in development, every Microsoft user was curious about how the new operating system would look like and what it would bring. After speculation, Windows 11 is here. The operating system comes with new design and functional changes. In addition to some additions, it comes with feature deprecations and removals. One of the features that doesn't exist in Windows 11 is Paint3D. While it still offers classic Paint, which is good for drawers, doodlers, and doodlers, it abandons Paint3D, which offers extra features ideal for 3D creators. If you are looking for some extra features, we recommend Autodesk Maya as the best 3D design software. like
 Get a virtual 3D wife in 30 seconds with a single card! Text to 3D generates a high-precision digital human with clear pore details, seamlessly connecting with Maya, Unity and other production tools
May 23, 2023 pm 02:34 PM
Get a virtual 3D wife in 30 seconds with a single card! Text to 3D generates a high-precision digital human with clear pore details, seamlessly connecting with Maya, Unity and other production tools
May 23, 2023 pm 02:34 PM
ChatGPT has injected a dose of chicken blood into the AI industry, and everything that was once unthinkable has become basic practice today. Text-to-3D, which continues to advance, is regarded as the next hotspot in the AIGC field after Diffusion (images) and GPT (text), and has received unprecedented attention. No, a product called ChatAvatar has been put into low-key public beta, quickly garnering over 700,000 views and attention, and was featured on Spacesoftheweek. △ChatAvatar will also support Imageto3D technology that generates 3D stylized characters from AI-generated single-perspective/multi-perspective original paintings. The 3D model generated by the current beta version has received widespread attention.
