

MySQL字符编码的讨论:如何处理emoji等4字节的Unicode字符-utf8mb4vs.utf8Collation_MySQL

Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
简单说来,就是把世界上所有语言的字,加上所有能找到的符号(如高音谱号、麻将、emoji)用同一套编码表示出来。
2. UTF-8是什么
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码。可变长度的意思在于,如果能使用1字节编码,UTF-8绝对不会使用2字节去表示。举个例子,UTF-8的1字节部分和ASCII码是相同的。所以表示'A'这个字符的时候,UTF-8与ASCII码不仅编码相同,而且都是只使用1字节。
3. Character Set和Collation是什么
Character Set是一套符号以及编码。Collation是character set的排序方法。在中文版的MySQL中,character set被翻译为“字符集”,collation被翻译为“整理”。
举个例子,UTF-8是character set,utf8_unicode_ci和utf8mb4_unicode_ci就是collation。
Collation的作用主要有二:字符排序与查找字符。
字符排序的作用是显而易见的,不过还是要用几个例子加以说明。比如要比较a和b的大小,因为在26个英文字母里面,a在b前,所以在编码的时候,也把a放在b前面。这样就产生了第一种排序方式,通过字符编码的大小来排序。而在中文里面,“年”和“日”的排序,除了按照字符编码大小,还可以有另外一些标准。比如可以按照笔画序,“年”的第一笔是丿,“日”的第一笔是丨,而丨是排在丿前的,所以就将“日”排在前面;也可以按拼音序,“年”是n开头,“日”是r开头,于是把“年”排在前面。除此以外,还可以定义部首序、笔画数序等等,而不同的排序方法会有不同的结果。英文也有大小写敏感与不敏感的排序方式。种种不同的排序方式,就形成了不同的collations。
Collation的第二个作用则是查找字符是否在一个字符集里面。既然是一个有序的集合,则可以快速地通过一个编码值确定一个字符是否在集合内。这个特性是我们在不知不觉中使用的。比如使用中文输入法,就是通过输入法找到一个编码,通过collation把它查找出来的。
4. Unicode再深入:Plane和中日韩越统一表意文字
utf8_unicode_ci和utf8mb4_unicode_ci这两个collations都是基于UTF-8编码的,但排序方面或多或少会有差别。可是更大的差别是它查找字符的集合。这需要提到一个Unicode的概念:Plane。
4.1. PlanePlane中文译作“Unicode平面字符映射”,不过我们还是叫它plane好啦。目前的Unicode字符分为17个planes,而每个plane拥有65536(即2^16)个代码点。可以认为一个plane就是一个范围的编码。
Plane 0也叫做BMP(Basic Multilingual Plane,基本多文种平面),存放着世界上各种语言与标记中最常用的字符。
Plane 1也叫做SMP(Supplementary Multilingual Plane,多文种补充平面),放着表情符号(emoji)、字母与数学符号、音乐符号、太玄经(太极符号)、装饰符号、扑克牌、麻将符号、箭头扩展和一些世界上各种语言不太常用的文字等等。
Plane 2也叫做SIP(Supplementary Ideographic Plane,表意文字补充平面),用于存放统一汉字(见4.2)的一些罕用字与汉藏语系其他语言的用字(如粤语用字)。
4.2. 统一汉字的分布对于统一汉字(中日韩越统一表意文字,CJKV Unified Ideographs)来说,BMP存放着最初的版本(也是最常用字)与扩展A区的汉字。扩展B区到即将到来的扩展E区都放在SIP中。
在这些区中,除了独立字源的字,还有同一个字源或部首不同的变体或写法。比如“户”的第一笔,中国大陆与香港写作“户”,台湾写作“戶”,日本则写作“戸”。这些差异也会在Unicode中用三个不同的编码去表示。所以B区到E区有不少此种字体。
举些B区的例子。网络上之前流行的“不会功夫不要艹我”被写成““xx巭嫑莪”,其中“xx”这个字就是在B区。而粤语“x鸡”(阉鸡)、“x完松”(和一个人发生关系后弃之而去)两个词的首字也是在B区。
5. utf8_unicode_ci和utf8mb4_unicode_ci的异同
这两种collations所对应的字符都是UTF-8编码的一个子集。utf8_unicode_ci最多能找到3个字节的Unicode编码,而utf8mb4_unicode_ci则能找到4个字节的编码。由于调整后的UTF-8编码格式规定最多使用4字节(原来是6字节)编码,所以utf8mb4系列可以说是覆盖了整个Unicode编码。
由于utf8_unicode_ci最多能找到3个字节的编码,意味着它只支持BMP中的字符,对于SMP与SIP以及其他头一字节不为0x00、需要4字节编码的planes来说,utf8_unicode_ci这种collation是无法支持。当使用4字节的字符(如emoji与B区以后的统一汉字)对使用此种collation的字段进行增删查改时,数据库会报一个非法字符的异常。而utf8mb4则没有此问题。由此也看出,utf8mb4_unicode_ci是utf8_unicode_ci的超集。
6. utf8mb4_unicode_ci的优缺点
utf8mb4系列的Collation在MySQL 5.5以上开始支持。相比起utf8_unicode_ci,它有如下的特性:
1) 在数据表中,对于BMP中的字符(最多使用3字节的字符,最常用的字符),两种collations具有完全相同的存储特性:相同的码值,相同的编码方式,相同的存储长度。不会增加任何的存储开销。
2) 在数据表中,对于其他plains的字符,utf8系列的collation根本不能存储,而utf8mb4系列的collations则可以存储。
3) 在数据表中,对于变长的字段(如VARCHAR2,TEXT),utf8mb4最大可存储的字符可能少于utf8系列的collation。
4) 在索引中,对于文本类型的字段,utf8mb4可索引的字符少于utf8系列的collations。如InnoDB的索引最多使用767字节。如果使用utf8mb4,每一个字符都会预留4字节做索引,而utf8则预留3字节。故此前者是191个字符,后者是255个字符。
5) 由于4)的原因,加上字符集大,utf8mb4的性能可能比utf8系列的collations低。
6) 若升级前的字段做了索引,需要把索引字符限制在191字符或以内。
7. 当前系统用哪个好
在当前的系统,全部都使用utf8_unicode_ci这种collation。但是在存储网页标题时,标题带有SMP或者SIP的字符,如emoji、粤语字,会引发数据库写入异常。于是,就有两种解决方向:
1) 扔掉。
1.1) 扔掉或截断引发异常的字。采取此种方法,需要对每一个标题进行扫描。
1.2) 扔掉整条记录。可以采取扫描法,或者扔掉引发异常的记录。
2) 升级到utf8mb4。会略为降低数据库性能。
7.1. 性能考虑
首先对于写入性能,查找字体的性能损耗由于在写入前字符都已经变成编码,基本可以忽略。对于网络传输的性能,则需要继续查找相关资料继续查证。但初步估计由于目前数据库在本地,故此这部分开销的增长不太明显。
而对于索引的性能,由于网页标题这一字段没有做索引,在可预见的将来也未有此计划,故此没有性能的损耗,也没有升级兼容性的担心。
况且,倘若走扔掉数据的方向,若采取扫描法,则需要付出扫描的开销。若采取扔掉记录法,则会先触发事务回滚,其他记录需要下次重新写入。而且当一批记录写入时有k个记录引发异常,则需要回滚与重试k次,除非使用扫描法预先扫描出这些异常的记录。但这也会引入额外的程序与数据库开销。若不使用事务,则数据库总体写入性能会大为降低。
虽然没有实测过,但从感觉上来定性判断,似乎扔掉记录比升级collation带来的性能退化要大。
7.2. 存储空间考虑
当前的网页标题是使用VARCHAR2存储。对于现在可用的、常见的BMP字符,不会引入额外的存储开销。BMP字符在VARCHAR的类型下不会为每一字符引入额外33%的空间开销。反之,定长的CHAR就会引入这种额外开销。
7.3. 目标数据考虑
网页标题作为以后特征分析的数据源。在分析需求完全没有确定的情况下,我认为扔掉任何数据都是不宜采取的办法,特别是整条记录扔掉更是不推荐。因为现阶段我们没有一套标准去判定何为有效数据、何为无效数据。有可能引发异常的那部分数据确实是没用的数据,也有可能那部分人群更倾向于在我们平台上活跃使用。既然各种可能性都存在,我们主动放弃一部分可能性,似乎不太恰当。
7.4. API设计与兼容性考虑
由于utf8_unicode_ci与utf8mb4_unicode_ci都是使用UTF-8编码,所以对于JAVA,使用MyBatis生成的代码是一样的,都是使用String类型。这点已经实测过。加上这两种collations在BMP中的编码完全一致,所以使用3字节与4字节的系统,对于BMP中的字符都是完全兼容、正常显示的。而对于3字节的系统,4字节的字符一般会显示成一个方框,或者在一个方框中有几个小数字,不会引发系统异常。
8. 总结
诚然,emoji对分词分析目前来说还没有什么效果,粤语词而且在SIP中也只是其中一部分,也不知道有多少日本动漫或者爱情动作片的网页会遇到这些生僻字,音乐符号也少人用,太极符号也不是每次都出现,一些数学增补的字符与箭头增补图案也不是每个人都会用。这些加起来可能不知够不够全部的千分之一。
但是倘若每一两个小时就会由于字符不能写入,引发数据库的异常。通过上面的分析,我认为增加这种兼容性带来的成本是可以接受的。
故此,我建议使用升级的方法,兼容所有Unicode字符。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 1MB of storage capacity is equivalent to how many bytes
Mar 03, 2023 pm 05:42 PM
1MB of storage capacity is equivalent to how many bytes
Mar 03, 2023 pm 05:42 PM
1MB of storage capacity is equivalent to 2 to the 20th power bytes, or 1,048,576 bytes. MB is a storage unit in computers, pronounced as "mega"; because 1MB is equal to 1024KB, and 1KB is equal to 1024B (bytes), so 1MB is equal to 1048576 (1024 *1024) bytes.
 11 common classification feature encoding techniques
Apr 12, 2023 pm 12:16 PM
11 common classification feature encoding techniques
Apr 12, 2023 pm 12:16 PM
Machine learning algorithms only accept numerical input, so if we encounter categorical features, we will encode the categorical features. This article summarizes 11 common categorical variable encoding methods. 1. ONE HOT ENCODING The most popular and commonly used encoding method is One Hot Enoding. A single variable with n observations and d distinct values is converted into d binary variables with n observations, each binary variable is identified by a bit (0, 1). For example: the simplest implementation after coding is to use pandas' get_dummiesnew_df=pd.get_dummies(columns=[‘Sex’], data=df)2,
 1 bit equals how many bytes
Mar 09, 2023 pm 03:11 PM
1 bit equals how many bytes
Mar 09, 2023 pm 03:11 PM
1 bit is equal to one-eighth of a byte. In the binary number system, each 0 or 1 is a bit (bit), and a bit is the smallest unit of data storage; every 8 bits (bit, abbreviated as b) constitute a byte (Byte), so "1 byte ( Byte) = 8 bits”. In most computer systems, a byte is an 8-bit (bit) long data unit. Most computers use a byte to represent a character, number, or other character.
 How many bytes does an ascii code occupy?
Sep 07, 2023 pm 04:03 PM
How many bytes does an ascii code occupy?
Sep 07, 2023 pm 04:03 PM
An ASCII code occupies one byte. ASCII code is a coding standard used to represent characters. It uses 7-bit binary numbers to represent 128 different characters, including letters, numbers, punctuation marks, special characters, etc. A byte is the basic unit of computer storage unit. It consists of 8 binary bits. Each binary bit can be 0 or 1. One byte can represent 256 different values, so it can represent all characters in the ASCII code.
 How many bytes does one ascii character occupy?
Mar 09, 2023 pm 03:49 PM
How many bytes does one ascii character occupy?
Mar 09, 2023 pm 03:49 PM
One ascii character occupies 1 byte. ASCII code characters are represented by 7-bit or 8-bit binary encoding in the computer and are stored in one byte, that is, one ASCII code occupies one byte. ASCII code can be divided into standard ASCII code and extended ASCII code. Standard ASCII code is also called basic ASCII code. It uses 7-bit binary numbers (the remaining 1 binary digit is 0) to represent all uppercase and lowercase letters, and the numbers 0 to 9. Punctuation marks, and special control characters used in American English.
 How to type arrows in Word
Apr 16, 2023 pm 11:37 PM
How to type arrows in Word
Apr 16, 2023 pm 11:37 PM
How to use AutoCorrect to type arrows in Word One of the fastest ways to type arrows in Word is to use the predefined AutoCorrect shortcuts. If you type a specific sequence of characters, Word automatically converts those characters into arrow symbols. You can draw many different arrow styles using this method. To type an arrow in Word using AutoCorrect: Move your cursor to the location in the document where you want the arrow to appear. Type one of the following character combinations: If you don't want what you type to be corrected to an arrow symbol, press the backspace key on your keyboard to
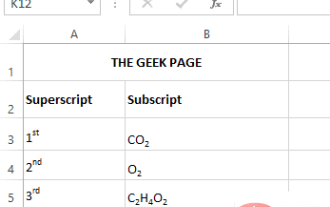 How to apply superscript and subscript formatting options in Microsoft Excel
Apr 14, 2023 pm 12:07 PM
How to apply superscript and subscript formatting options in Microsoft Excel
Apr 14, 2023 pm 12:07 PM
A superscript is a character or characters, either letters or numbers, that you need to set slightly above the normal line of text. For example, if you need to write 1st, the letter st needs to be slightly higher than the character 1. Likewise, a subscript is a group of characters or a single character and needs to be set slightly lower than normal text level. For example, when you write a chemical formula, you need to place the numbers below the normal line of characters. The following screenshots show some examples of superscript and subscript formatting. Although it may seem like a daunting task, applying superscript and subscript formatting to your text is actually quite simple. In this article, we will explain in some simple steps how to easily format text using superscript or subscript. Hope you enjoyed reading this article. How to apply superscript in Excel
 Knowledge graph: the ideal partner for large models
Jan 29, 2024 am 09:21 AM
Knowledge graph: the ideal partner for large models
Jan 29, 2024 am 09:21 AM
Large language models (LLMs) have the ability to generate smooth and coherent text, bringing new prospects to areas such as artificial intelligence conversation and creative writing. However, LLM also has some key limitations. First, their knowledge is limited to patterns recognized from training data, lacking a true understanding of the world. Second, reasoning skills are limited and cannot make logical inferences or fuse facts from multiple data sources. When faced with more complex and open-ended questions, LLM's answers may become absurd or contradictory, known as "illusions." Therefore, although LLM is very useful in some aspects, it still has certain limitations when dealing with complex problems and real-world situations. In order to bridge these gaps, retrieval-augmented generation (RAG) systems have emerged in recent years. The core idea is
