
 Technology peripherals
AI
Breaking through the dimensional wall, X-Dreamer brings high-quality text to 3D generation, integrating the fields of 2D and 3D generation.
Technology peripherals
AI
Breaking through the dimensional wall, X-Dreamer brings high-quality text to 3D generation, integrating the fields of 2D and 3D generation.
Breaking through the dimensional wall, X-Dreamer brings high-quality text to 3D generation, integrating the fields of 2D and 3D generation.

In recent years, important progress has been made in automatically converting text into 3D content, driven by the development of pre-trained diffusion models [1, 2, 3]. Among them, DreamFusion[4] introduces an effective method that utilizes a pre-trained 2D diffusion model[5] to automatically generate 3D assets from text without the need for a dedicated 3D asset dataset
One of the key innovations introduced in DreamFusion is the Fractional Distillation Sampling (SDS) algorithm. The algorithm evaluates a single 3D representation using a pretrained 2D diffusion model, such as NeRF [6], optimizing it to ensure that the rendered image from any camera perspective maintains a high consistency with the given text. Inspired by the seminal SDS algorithm, several works [7, 8, 9, 10, 11] have emerged to advance text-to-3D generation tasks by applying pre-trained 2D diffusion models.
Although text-to-3D generation has made significant progress by leveraging pre-trained text-to-2D diffusion models, there is still a large gap between 2D images and 3D assets. big field gap. This distinction is clearly demonstrated in Figure 1.
First, text-to-2D models produce camera-agnostic generation results that focus on generating high-quality images from specific angles while ignoring other angles. In contrast, 3D content creation is intricately tied to camera parameters such as position, shooting angle, and field of view. Therefore, text-to-3D models must produce high-quality results over all possible camera parameters.
In addition, text-to-2D generative models need to generate foreground and background elements simultaneously to maintain the overall coherence of the image. In contrast, text-to-3D generative models only need to focus on creating foreground objects. This difference enables text-to-3D models to allocate more resources and attention to accurately represent and generate foreground objects. Therefore, when using pre-trained 2D diffusion models directly for 3D asset creation, the domain difference between text-to-2D and text-to-3D generation becomes a significant performance barrier
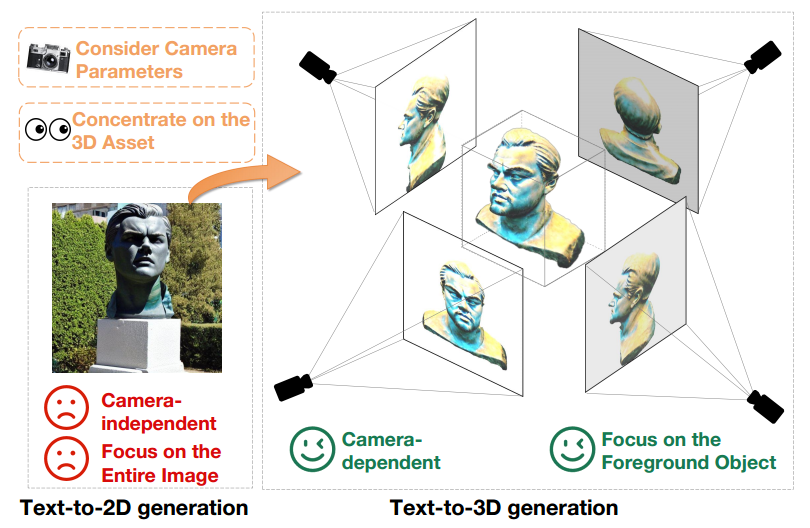
Figure 1 The output of text-to-2D generative model (left) and text-to-3D generative model (right) under the same text prompt, namely "A statue of Leonardo DiCaprio's head ."
To solve this problem, the paper proposes X-Dreamer, a novel method for high-quality text-to-3D content creation that can effectively bridge text-to- -Domain gap between 2D and text-to-3D generation.
The key components of X-Dreamer are two innovative designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) and Attention-Mask Alignment (AMA) loss.
First of all, existing methods [7, 8, 9, 10] usually use 2D pre-trained diffusion models [5, 12] for text-to-3D generation, which lacks the ability to work with cameras. inherent relationship between parameters. To address this limitation and ensure that X-Dreamer produces results that are directly affected by camera parameters, the paper introduces CG-LoRA to adjust the pre-trained 2D diffusion model. Notably, the parameters of CG-LoRA are dynamically generated based on camera information during each iteration, thereby establishing a robust relationship between the text-to-3D model and camera parameters.
Secondly, the pre-trained text-to-2D diffusion model allocates attention to foreground and background generation, while the creation of 3D assets requires more attention to the accurate generation of foreground objects. To address this issue, the paper proposes the AMA loss, which uses a binary mask of 3D objects to guide the attention map of a pre-trained diffusion model to prioritize the creation of foreground objects. By incorporating this module, X-Dreamer prioritizes the generation of foreground objects, significantly improving the overall quality of the generated 3D content.

Project homepage:
https://xmu-xiaoma666.github.io/Projects/ X-Dreamer/
Github homepage: https://github.com/xmu-xiaoma666/X-Dreamer
Discussion 文Address: https://arxiv.org/abs/2312.00085
X-Dreamer has made the following contributions to the field of text-to-3D generation contribute:
- The paper proposes a novel method, X-Dreamer, for high-quality text-to-3D content creation, effectively bridging text-to-2D and text-to-3D The main gap between the builds.
- In order to enhance the alignment between the generated results and the camera perspective, the paper proposes CG-LoRA, which uses camera information to dynamically generate specific parameters of the 2D diffusion model.
-
In order to prioritize the creation of foreground objects in text-to-3D models, the paper introduces the AMA loss, which uses a binary mask of foreground 3D objects to guide the attention map of the 2D diffusion model.
Method
X-Dreamer consists of two main stages: geometry learning and appearance study. For geometry learning, this study uses DMTET as the 3D representation and utilizes a 3D ellipsoid to initialize it. When initialized, the loss function uses mean square error (MSE) loss. Next, DMTET and CG-LoRA are optimized using Fractional Distillation Sampling (SDS) loss and the AMA loss proposed in this study to ensure alignment between the 3D representation and the input text prompt
For appearance learning, the paper uses bidirectional reflection distribution function (BRDF) modeling. Specifically, the paper utilizes MLP with trainable parameters to predict surface materials. Similar to the geometry learning stage, the paper uses SDS loss and AMA loss to optimize the trainable parameters of MLP and CG-LoRA to achieve alignment between 3D representations and text cues. Figure 2 shows the detailed composition of X-Dreamer.

Figure 2 Overview of X-Dreamer, including geometry learning and appearance learning.
Geometry Learning (Geometry Learning)
In this module, X-Dreamer The DMTET is parameterized into a 3D representation using the MLP network . In order to enhance the stability of geometric modeling, this article uses 3D ellipsoid as the initial configuration of DMTET
. In order to enhance the stability of geometric modeling, this article uses 3D ellipsoid as the initial configuration of DMTET  . For each vertex
. For each vertex 
 belonging to the tetrahedral mesh , this paper trains
belonging to the tetrahedral mesh , this paper trains  to predict two important quantities: SDF value
to predict two important quantities: SDF value  and deformation bias Shift amount
and deformation bias Shift amount  . In order to initialize
. In order to initialize  to an ellipsoid, this article samples N points evenly distributed within the ellipsoid, and calculates the corresponding SDF value
to an ellipsoid, this article samples N points evenly distributed within the ellipsoid, and calculates the corresponding SDF value  . Subsequently, the mean square error (MSE) loss is used to optimize
. Subsequently, the mean square error (MSE) loss is used to optimize  . This optimization process ensures that
. This optimization process ensures that  efficiently initializes the DMTET so that it resembles a 3D ellipsoid. The formula for MSE loss is as follows:
efficiently initializes the DMTET so that it resembles a 3D ellipsoid. The formula for MSE loss is as follows:

After initializing the geometry, align the DMTET's geometry with the input text prompt. This is done by using differential rendering techniques to generate a normal map n and an object's mask m from an initialized DMTET given a randomly sampled camera pose c. Subsequently, the normal map n is input into a frozen Stable Diffusion model (SD) with a trainable CG-LoRA embedding, and the parameters in  are updated using the SDS loss, defined as follows:
are updated using the SDS loss, defined as follows: 

Among them,  represents the parameters of SD,
represents the parameters of SD,  is the value of SD at a given noise level t and text embedding y The prediction noise of the SD of the case. Additionally,
is the value of SD at a given noise level t and text embedding y The prediction noise of the SD of the case. Additionally,  , where
, where 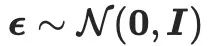 represents noise sampled from a normal distribution. The implementation of
represents noise sampled from a normal distribution. The implementation of  ,
,  and
and  is based on DreamFusion [4].
is based on DreamFusion [4].
Additionally, in order to focus SD on generating foreground objects, X-Dreamer introduces an additional AMA loss to align the object mask with SD’s attention map as follows:

## represents the number of attention layers,  is the attention map of the i-th attention layer. Function
is the attention map of the i-th attention layer. Function  is used to adjust the size of the rendered 3D object mask to ensure that its size is aligned with the size of the attention map.
is used to adjust the size of the rendered 3D object mask to ensure that its size is aligned with the size of the attention map. 
Appearance Learning (Appearance Learning) After obtaining the geometry of a 3D object, the goal of this article is to calculate the appearance of the 3D object using a Physically Based Rendering (PBR) material model. The material model includes diffusion terms on the surface of the geometry, the multilayer perceptron (MLP) parameterized by Among them, Among them, Camera-Guided Low-Rank Adaptation (CG-LoRA) In order to solve the problem of generating sub-optimal 3D results caused by the domain gap between generating text into 2D and 3D, X-Dreamer proposed a low-rank adaptation method based on camera guidance such as As shown in Figure 3, camera parameters and direction-aware text are used to guide the generation of parameters in CG-LoRA, so that X-Dreamer can effectively perceive the position and direction information of the camera. Figure 3 Illustration of camera-guided CG-LoRA. Specifically, given the text prompt where, Among them, is used to transform the shape of a tensor from where, What needs to be re-expressed is: attention mask alignment loss (AMA loss) SD is pre- Trained to generate 2D images taking into account both foreground and background elements. However, text-to-3D generation requires more attention to the generation of foreground objects. Given this requirement, X-Dreamer proposes the Attention-Mask Alignment Loss (AMA loss) to align the attention map of SD with the rendered mask image of the 3D object. Specifically, for each attention layer in pre-trained SD, this method uses query image features Among them, Since the softmax function is used to normalize the attention map values, the activation values in the attention map may become very small when the image feature resolution is high. However, directly aligning the attention map with the mask of the rendered 3D object is not optimal, considering that each element in the rendered 3D object mask is a binary value of 0 or 1. To solve this problem, the paper proposes a normalization technique that maps the values in the attention map to between (0, 1). The formula for this normalization process is as follows: where The paper uses four Nvidia RTX 3090 GPUs and the PyTorch library to conduct experiments. To calculate the SDS loss, the Stable Diffusion model implemented via Hugging Face Diffusers was utilized. For DMTET and material encoders, they are implemented as two-layer MLP and single-layer MLP respectively, with a hidden layer dimension of 32. Generate text-to-3D starting from ellipsoid Paper presentation The text-to-3D generation result of X-Dreamer using ellipsoid as the initial geometric shape is shown in Figure 4. The results demonstrate X-Dreamer's ability to generate high-quality and photorealistic 3D objects that accurately correspond to the input text prompts. Figure 4 uses the ellipsoid as the starting point to generate text-to-3D Start text-to-3D generation from coarse-grained meshes Although a large number of coarse-grained meshes can be downloaded from the Internet, Using these meshes directly to create 3D content often results in poor performance due to the lack of geometric detail. However, these meshes can provide X-Dreamer with better 3D shape prior information than 3D ellipsoids. Therefore, it is also possible to use a coarse-grained guide grid to initialize DMTET instead of using an ellipsoid. As shown in Figure 5, X-Dreamer can generate 3D assets with precise geometric detail based on given text, even if the provided coarse-grained mesh lacks detail. Figure 5 Text-to-3D generation starting from a coarse-grained mesh. The content that needs to be rewritten is: Qualitative Comparison. In order to evaluate the effectiveness of X-Dreamer, this The paper compares it with four advanced methods: DreamFusion [4], Magic3D [8], Fantasia3D [7] and ProlificDreamer [11], as shown in Figure 6 When compared to SDS-based methods [4, 7, 8], X-Dreamer outperforms them in generating high-quality and realistic 3D assets. Furthermore, X-Dreamer produces 3D content with comparable or even better visual effects compared to VSD-based methods [11] while requiring significantly less optimization time. Specifically, the geometry and appearance learning process only takes about 27 minutes for X-Dreamer, compared to more than 8 hours for ProlificDreamer. Figure 6 Comparison with state-of-the-art (SOTA) methods. The content that needs to be rewritten is: ablation experiment In order to gain a deeper understanding of the capabilities of CG-LoRA and AMA loss, the paper conducted an ablation study in which each module was added individually to evaluate its impact. As shown in Figure 7, the ablation results show that when CG-LoRA is excluded from X-Dreamer, the geometry and appearance quality of the generated 3D objects decrease significantly. Additionally, X-Dreamer’s missing AMA loss also has a deleterious effect on the geometry and appearance fidelity of the resulting 3D assets. These need to be re-written: The ablation experiments provide valuable investigation into the individual contributions of CG-LoRA and AMA losses in enhancing the geometry, appearance and overall quality of the generated 3D objects. Figure 7 Ablation study of X-Dreamer. The purpose of introducing AMA loss is to reduce the noise in the denoising process. Attention is focused on foreground objects. This is achieved by aligning the attention map of the SD with the rendering mask of the 3D object. In order to evaluate the effectiveness of AMA loss in achieving this goal, this paper compares the attention maps of SD with and without AMA loss in the geometry learning and appearance learning stages respectively. According to Figure 8 It can be observed that adding AMA loss not only improves the geometry and appearance of the generated 3D assets, but also allows SD to focus its attention specifically on foreground object areas. The visualization results confirm the effectiveness of the AMA loss in guiding SD attention, thereby improving the quality of the geometry and appearance learning stages and the focusing of foreground objects The content that needs to be rewritten is: Figure 8 shows the visualization results of the attention map, rendering mask and rendered image, including and excluding the AMA loss This research introduces A groundbreaking framework called X-Dreamer aims to enhance text-to-3D generation by addressing the domain gap between text-to-2D and text-to-3D generation. To achieve this goal, the paper first proposes CG-LoRA, a module that incorporates three-dimensional relevant information (including direction-aware text and camera parameters) into a pre-trained Stable Diffusion (SD) model. By doing so, this paper is able to effectively capture information related to the three-dimensional domain. Furthermore, this paper designs an AMA loss to align the SD-generated attention map with the rendering mask of the 3D object. The main goal of AMA loss is to guide the focus of text to 3D models towards the generation of foreground objects. Through extensive experiments, this paper comprehensively evaluates the effectiveness of the proposed method and demonstrates that X-Dreamer is able to generate high-quality and realistic 3D content based on given text prompts , roughness and metal terms
, roughness and metal terms  , and normal change terms
, and normal change terms  . For any point
. For any point 
 is used to obtain three material terms, which can be expressed as follows:
is used to obtain three material terms, which can be expressed as follows: 
 represents position encoding using hash grid technology. After that, each pixel of the rendered image can be calculated using the following formula:
represents position encoding using hash grid technology. After that, each pixel of the rendered image can be calculated using the following formula: 
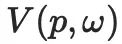 represents the pixel value of the point on the surface of the 3D object rendered from the direction
represents the pixel value of the point on the surface of the 3D object rendered from the direction 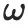
 .
.  represents the hemisphere defined by the set of incident directions that satisfies the condition
represents the hemisphere defined by the set of incident directions that satisfies the condition 
 , where
, where  represents the incident direction,
represents the incident direction, 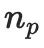 Represents the surface normal at point
Represents the surface normal at point  .
.  corresponds to the incident light from the ready-made environment map, and
corresponds to the incident light from the ready-made environment map, and  is the bidirectional reflection distribution function related to the material properties (i.e.
is the bidirectional reflection distribution function related to the material properties (i.e.  ) (BRDF). By aggregating all rendered pixel colors, the rendered image
) (BRDF). By aggregating all rendered pixel colors, the rendered image  can be obtained. Similar to the geometry learning stage, the rendered image
can be obtained. Similar to the geometry learning stage, the rendered image 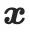 is fed into SD and optimized
is fed into SD and optimized  using SDS loss and AMA loss.
using SDS loss and AMA loss. 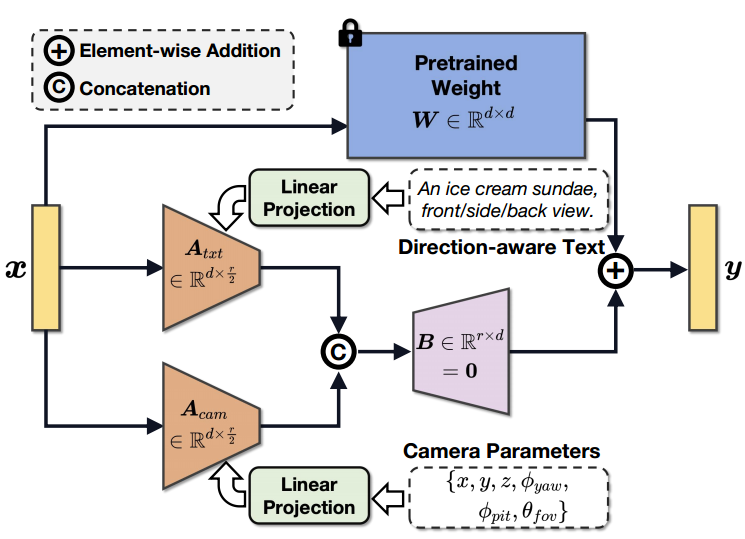
 and camera parameters
and camera parameters  , first use the pre-trained text CLIP encoder
, first use the pre-trained text CLIP encoder  and trainable The MLP
and trainable The MLP , projects these inputs into the feature space:
, projects these inputs into the feature space: 
 and
and 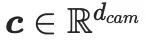 are text features and camera features respectively. After that, use two low-rank matrices to project
are text features and camera features respectively. After that, use two low-rank matrices to project  and
and  into a trainable dimensionality reduction matrix in CG-LoRA:
into a trainable dimensionality reduction matrix in CG-LoRA: 
 and
and  are the two dimensionality reduction matrices of CG-LoRA. Function
are the two dimensionality reduction matrices of CG-LoRA. Function 
 to
to  .
. 
 and
and  are two low-rank matrices. Therefore, they can be decomposed into the product of two matrices to reduce the trainable parameters in the implementation, i.e.
are two low-rank matrices. Therefore, they can be decomposed into the product of two matrices to reduce the trainable parameters in the implementation, i.e.  ;
;  , where
, where  ,
,  ,
,  ,
, 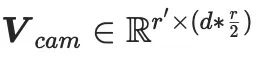 ,
, is a small number ( Such as: 4). According to the composition of LoRA, the dimension expansion matrix
is a small number ( Such as: 4). According to the composition of LoRA, the dimension expansion matrix  is initialized to zero to ensure that the model starts training with SD's pre-trained parameters. Therefore, the feedforward process formula of CG-LoRA is as follows:
is initialized to zero to ensure that the model starts training with SD's pre-trained parameters. Therefore, the feedforward process formula of CG-LoRA is as follows: 
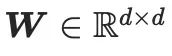 represents the frozen parameters of the pre-trained SD model,
represents the frozen parameters of the pre-trained SD model,  is a cascade operation. In the implementation of this method, CG-LoRA is integrated into the linear embedding layer of the attention module in SD to effectively capture orientation and camera information.
is a cascade operation. In the implementation of this method, CG-LoRA is integrated into the linear embedding layer of the attention module in SD to effectively capture orientation and camera information.  and key CLS label features
and key CLS label features  to calculate the attention map. Calculated as follows:
to calculate the attention map. Calculated as follows:
 represents the number of heads in the multi-head attention mechanism,
represents the number of heads in the multi-head attention mechanism,  represents the attention map, and then, through all attention heads The attention values of the attention map
represents the attention map, and then, through all attention heads The attention values of the attention map  are averaged to calculate the value of the overall attention map
are averaged to calculate the value of the overall attention map  .
. 
 represents a small constant value (such as
represents a small constant value (such as  ) to prevent 0 from appearing in the denominator. Finally, the AMA loss is used to align the attention maps of all attention layers to the rendered mask of the 3D object.
) to prevent 0 from appearing in the denominator. Finally, the AMA loss is used to align the attention maps of all attention layers to the rendered mask of the 3D object. Experimental results





The above is the detailed content of Breaking through the dimensional wall, X-Dreamer brings high-quality text to 3D generation, integrating the fields of 2D and 3D generation.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
To create a data table using phpMyAdmin, the following steps are essential: Connect to the database and click the New tab. Name the table and select the storage engine (InnoDB recommended). Add column details by clicking the Add Column button, including column name, data type, whether to allow null values, and other properties. Select one or more columns as primary keys. Click the Save button to create tables and columns.
 How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
Creating an Oracle database is not easy, you need to understand the underlying mechanism. 1. You need to understand the concepts of database and Oracle DBMS; 2. Master the core concepts such as SID, CDB (container database), PDB (pluggable database); 3. Use SQL*Plus to create CDB, and then create PDB, you need to specify parameters such as size, number of data files, and paths; 4. Advanced applications need to adjust the character set, memory and other parameters, and perform performance tuning; 5. Pay attention to disk space, permissions and parameter settings, and continuously monitor and optimize database performance. Only by mastering it skillfully requires continuous practice can you truly understand the creation and management of Oracle databases.
 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
The core of Oracle SQL statements is SELECT, INSERT, UPDATE and DELETE, as well as the flexible application of various clauses. It is crucial to understand the execution mechanism behind the statement, such as index optimization. Advanced usages include subqueries, connection queries, analysis functions, and PL/SQL. Common errors include syntax errors, performance issues, and data consistency issues. Performance optimization best practices involve using appropriate indexes, avoiding SELECT *, optimizing WHERE clauses, and using bound variables. Mastering Oracle SQL requires practice, including code writing, debugging, thinking and understanding the underlying mechanisms.
 How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
Field operation guide in MySQL: Add, modify, and delete fields. Add field: ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT] Modify field: ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
The integrity constraints of Oracle databases can ensure data accuracy, including: NOT NULL: null values are prohibited; UNIQUE: guarantee uniqueness, allowing a single NULL value; PRIMARY KEY: primary key constraint, strengthen UNIQUE, and prohibit NULL values; FOREIGN KEY: maintain relationships between tables, foreign keys refer to primary table primary keys; CHECK: limit column values according to conditions.
 Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Nested queries are a way to include another query in one query. They are mainly used to retrieve data that meets complex conditions, associate multiple tables, and calculate summary values or statistical information. Examples include finding employees above average wages, finding orders for a specific category, and calculating the total order volume for each product. When writing nested queries, you need to follow: write subqueries, write their results to outer queries (referenced with alias or AS clauses), and optimize query performance (using indexes).
 How Tomcat logs help troubleshoot memory leaks
Apr 12, 2025 pm 11:42 PM
How Tomcat logs help troubleshoot memory leaks
Apr 12, 2025 pm 11:42 PM
Tomcat logs are the key to diagnosing memory leak problems. By analyzing Tomcat logs, you can gain insight into memory usage and garbage collection (GC) behavior, effectively locate and resolve memory leaks. Here is how to troubleshoot memory leaks using Tomcat logs: 1. GC log analysis First, enable detailed GC logging. Add the following JVM options to the Tomcat startup parameters: -XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log These parameters will generate a detailed GC log (gc.log), including information such as GC type, recycling object size and time. Analysis gc.log
