
 Technology peripherals
AI
System research reveals indispensable large model for next-generation autonomous driving system
Technology peripherals
AI
System research reveals indispensable large model for next-generation autonomous driving system
System research reveals indispensable large model for next-generation autonomous driving system

With the emergence of large language models (LLM) and visual basic models (VFM), it is expected that multi-modal artificial intelligence systems with large models can comprehensively perceive the real world and make decisions like humans. In recent months, LLM has attracted widespread attention in the field of autonomous driving research. Despite the great potential of LLM, there are still key challenges, opportunities and future research directions in driving systems, which currently lack detailed elucidation
In this article, Tencent Maps, Pudu Researchers from the University, UIUC, and the University of Virginia have conducted systematic surveys in this field. This study first introduces the background of multimodal large language models (MLLM), the progress of developing multimodal models using LLM, and a review of the history of autonomous driving. The study then provides an overview of existing MLLM tools for driving, traffic and mapping systems, as well as existing datasets. The study also summarizes related work from the 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), the first workshop on applying LLM in autonomous driving. To further promote the development of this field, this study also discusses how to apply MLLM in autonomous driving systems and some important issues that need to be solved by academia and industry.

- ##Summary link: https://arxiv.org/abs/2311.12320
- Seminar link: https://llvm-ad.github.io/
- Github link: https://github.com/IrohXu/ Awesome-Multimodal-LLM-Autonomous-Driving
Multimodal Large Language Model (MLLM) has attracted much attention recently. This model combines the reasoning capabilities of LLM with image, video and audio data, and enables these data to perform various tasks more efficiently through multimodal alignment. , including image classification, aligning text with corresponding videos, and speech detection. In addition, some studies have shown that LLM can handle simple tasks in the field of robotics. However, currently in the field of autonomous driving, the integration of MLLM is progressing slowly. Is there any potential to improve existing autonomous driving systems, such as GPT-4, PaLM-2 and LLMs like LLaMA-2 still need further research and exploration
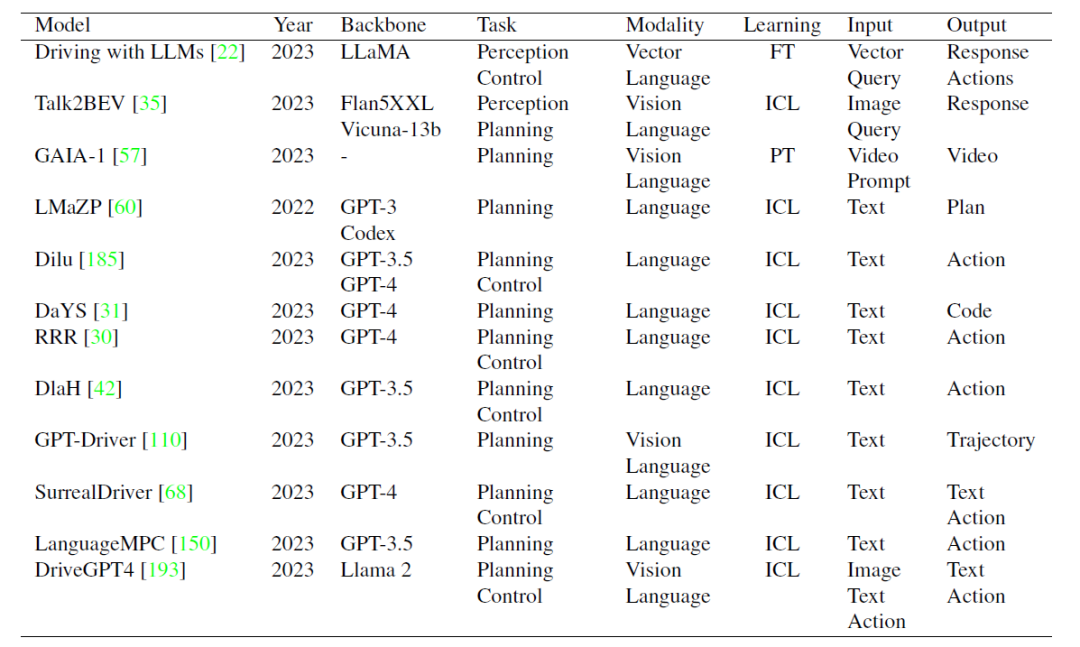
In this review, researchers believe that integrating LLMs into the field of autonomous driving can bring about a significant paradigm shift, thereby improving the driving experience. Perception, motion planning, human-vehicle interaction and motion control provide users with more adaptable and credible future transportation solutions. In terms of perception, LLM can use Tool Learning to call external APIs to access real-time information sources, such as high-precision maps, traffic reports and weather information, so that the vehicle can more comprehensively understand the surrounding environment. Self-driving cars can reason about congested routes through LLM and suggest alternative paths to improve efficiency and safe driving. In terms of motion planning and human-vehicle interaction, LLM can promote user-centered communication, enabling passengers to express their needs and preferences in everyday language. In terms of motion control, LLM first enables the control parameters to be customized according to the driver's preferences, realizing the personalized driving experience. Additionally, LLM can provide transparency to the user by explaining each step of the motion control process. The review predicts that in future SAE L4-L5 level autonomous vehicles, passengers can use language, gestures and even eyes to communicate their requests, with MLLM providing real-time in-car and driving feedback through integrated visual displays or voice responses.
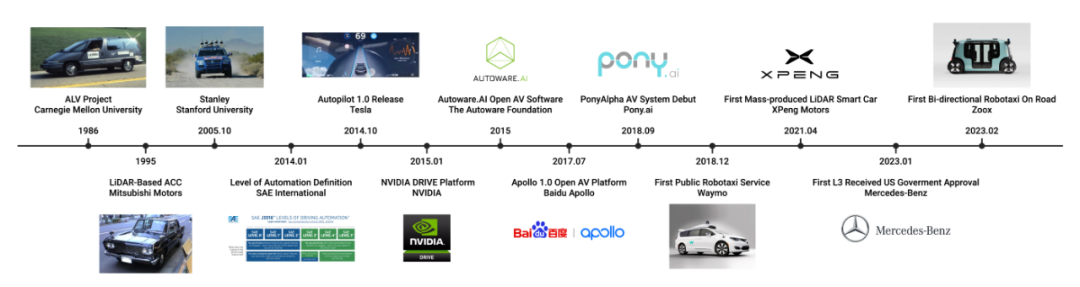
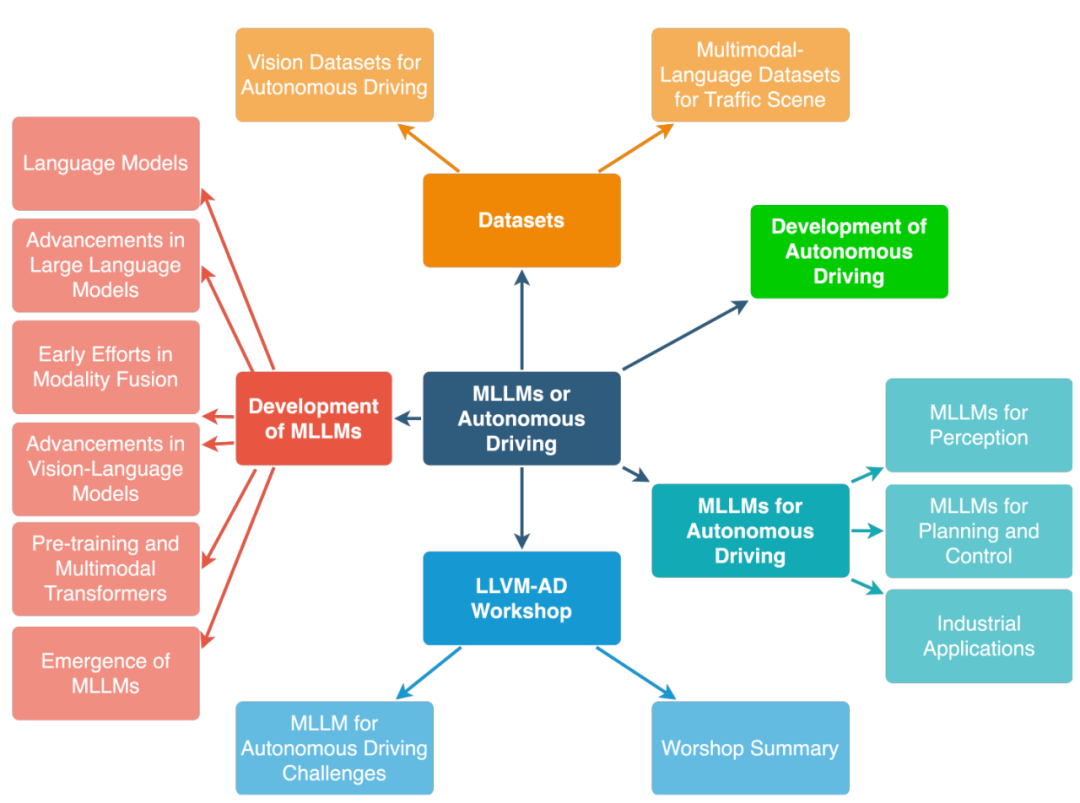
The development history of autonomous driving and multi-modal large language models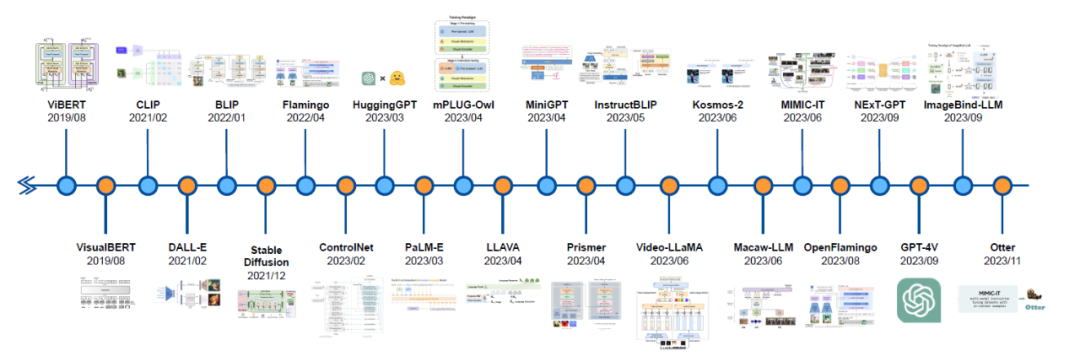
In order to build a bridge between autonomous driving and LLVM, relevant researchers organized the first Large Language and Vision Model Autonomous Driving Workshop (LLVM- AD). This workshop aims to enhance collaboration between academic researchers and industry professionals to explore the possibilities and challenges of implementing multi-modal large-scale language models in the field of autonomous driving. LLVM-AD will further promote the subsequent development of open source actual traffic language understanding datasets The first WACV Large-scale Language and Vision Model Autonomous Driving Workshop (LLVM-AD) accepted a total of nine papers paper. Some of these papers revolve around multimodal large language models in autonomous driving, focusing on integrating LLM into user-vehicle interaction, motion planning, and vehicle control. Several papers also explore new applications of LLM for human-like interaction and decision-making in autonomous vehicles. For example, "Imitating Human Driving" and "Driving by Language" explore LLM's interpretation and reasoning in complex driving scenarios, as well as frameworks for imitating human behavior. In addition, "Human-centered autonomous systems and LLM" emphasizes placing users at the center of designing LLM and using LLM to interpret user instructions. This approach represents an important shift toward human-centered autonomous systems. In addition to fused LLM, the workshop also covered some pure vision and data processing based methods. In addition, the workshop presented innovative data processing and evaluation methods. For example, NuScenes-MQA introduces a new annotation scheme for autonomous driving datasets. Collectively, these papers demonstrate progress in integrating language models and advanced techniques into autonomous driving, paving the way for more intuitive, efficient, and human-centered autonomous vehicles For future development, this study proposes the following research directions: The content that needs to be rewritten is: 1. Multi-modality in autonomous driving New Dataset for Big Language Models #Despite the success of big language models in language understanding, applying them to autonomous driving still faces challenges. This is because these models need to integrate and understand inputs from different modalities, such as panoramic images, 3D point clouds and high-precision maps. Current limitations in data size and quality mean that existing datasets cannot fully address these challenges. Furthermore, visual language datasets annotated from early open source datasets such as NuScenes may not provide a robust baseline for visual language understanding in driving scenarios. Therefore, there is an urgent need for new, large-scale datasets covering a wide range of traffic and driving scenarios to make up for the long-tail (imbalance) problem of previous dataset distributions to effectively test and enhance the performance of these models in autonomous driving applications. . 2. Hardware support required for medium and large language models in autonomous driving Different functions in autonomous vehicles Hardware requirements vary. Using LLM inside a vehicle for drive planning or involvement in vehicle control requires real-time processing and low latency to ensure safety, which increases computational requirements and affects power consumption. If LLM is deployed in the cloud, bandwidth for data exchange becomes another critical security factor. In contrast, using LLM for navigation planning or analyzing commands unrelated to driving (such as in-car music playback) does not require high query volume and real-time performance, making remote services a viable option. In the future, LLM in autonomous driving can be compressed through knowledge distillation to reduce computational requirements and latency. There is still a lot of room for development in this area. 3. Use large language models to understand high-precision maps High-precision maps play an important role in autonomous vehicle technology play a vital role as they provide basic information about the physical environment in which the vehicle operates. The semantic map layer in HD maps is important because it captures the meaning and contextual information of the physical environment. In order to effectively encode this information into the next generation of autonomous driving driven by Tencent's high-precision map AI automatic annotation system, new models are needed to map these multi-modal features into language space. Tencent has developed the THMA high-precision map AI automatic labeling system based on active learning, which can produce and label high-precision maps on a scale of hundreds of thousands of kilometers. In order to promote the development of this field, Tencent proposed the MAPLM dataset based on THMA, which contains panoramic images, 3D lidar point clouds and context-based high-precision map annotations, as well as a new question and answer benchmark MAPLM-QA 4. Large language model in human-vehicle interaction Human-vehicle interaction and understanding human driving behavior also pose a major challenge in autonomous driving. Human drivers often rely on nonverbal signals, such as slowing down to yield or using body movements to communicate with other drivers or pedestrians. These non-verbal signals play a vital role in communication on the road. There have been many accidents involving self-driving systems in the past because self-driving cars often behaved in a way that other drivers did not expect. In the future, MLLM will be able to integrate rich contextual information from a variety of sources and analyze the driver's gaze, gestures, and driving style to better understand these social signals and enable efficient planning. By estimating the social signals of other drivers, LLM can improve the decision-making capabilities and overall safety of autonomous vehicles. Personalized Autonomous Driving As autonomous vehicles develop, an important aspect is to consider how they Adapt to the user's personal driving preferences. There is a growing consensus that self-driving cars should mimic the driving style of their users. To achieve this, autonomous driving systems need to learn and integrate user preferences in various aspects, such as navigation, vehicle maintenance and entertainment. LLM's instruction tuning capabilities and contextual learning capabilities make it ideal for integrating user preferences and driving history information into autonomous vehicles to provide a personalized driving experience. For many years, autonomous driving has been the focus of attention and attracted many venture investors. Integrating LLM into autonomous vehicles presents unique challenges, but overcoming them will significantly enhance existing autonomous systems. It is foreseeable that smart cockpits supported by LLM have the ability to understand driving scenarios and user preferences, and establish a deeper trust between the vehicle and the occupants. Additionally, autonomous driving systems deploying LLM will be better able to deal with ethical dilemmas involving weighing the safety of pedestrians against the safety of vehicle occupants, promoting a decision-making process that is more likely to be ethical in complex driving scenarios. This article integrates insights from WACV 2024 LLVM-AD workshop committee members and aims to inspire researchers to contribute to the development of next-generation autonomous vehicles powered by LLM technology. Summary
The above is the detailed content of System research reveals indispensable large model for next-generation autonomous driving system. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to achieve the effect of high input elements but high text at the bottom?
Apr 04, 2025 pm 10:27 PM
How to achieve the effect of high input elements but high text at the bottom?
Apr 04, 2025 pm 10:27 PM
How to achieve the height of the input element is very high but the text is located at the bottom. In front-end development, you often encounter some style adjustment requirements, such as setting a height...
 How to correctly display the locally installed 'Jingnan Mai Round Body' on the web page?
Apr 05, 2025 pm 10:33 PM
How to correctly display the locally installed 'Jingnan Mai Round Body' on the web page?
Apr 05, 2025 pm 10:33 PM
Using locally installed font files in web pages Recently, I downloaded a free font from the internet and successfully installed it into my system. Now...
 How to select a child element with the first class name item through CSS?
Apr 05, 2025 pm 11:24 PM
How to select a child element with the first class name item through CSS?
Apr 05, 2025 pm 11:24 PM
When the number of elements is not fixed, how to select the first child element of the specified class name through CSS. When processing HTML structure, you often encounter different elements...
 Where to get the material for H5 page production
Apr 05, 2025 pm 11:33 PM
Where to get the material for H5 page production
Apr 05, 2025 pm 11:33 PM
The main sources of H5 page materials are: 1. Professional material website (paid, high quality, clear copyright); 2. Homemade material (high uniqueness, but time-consuming); 3. Open source material library (free, need to be carefully screened); 4. Picture/video website (copyright verified is required). In addition, unified material style, size adaptation, compression processing, and copyright protection are key points that need to be paid attention to.
 How to quickly build a foreground page using AI programming tools?
Apr 04, 2025 pm 08:24 PM
How to quickly build a foreground page using AI programming tools?
Apr 04, 2025 pm 08:24 PM
Quickly build the front-end page: Shortcuts for back-end developers As a back-end developer with three to four years of experience, you may be interested in basic JavaScript, CSS...
 Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
The H5 page needs to be maintained continuously, because of factors such as code vulnerabilities, browser compatibility, performance optimization, security updates and user experience improvements. Effective maintenance methods include establishing a complete testing system, using version control tools, regularly monitoring page performance, collecting user feedback and formulating maintenance plans.
 Setting flex: 1 1 0 What is the difference between setting flex-basis and not setting flex-basis?
Apr 05, 2025 am 09:39 AM
Setting flex: 1 1 0 What is the difference between setting flex-basis and not setting flex-basis?
Apr 05, 2025 am 09:39 AM
The difference between flex:110 in Flex layout and flex-basis not set In Flex layout, how to set flex...
 How to efficiently remove specific conditional expressions in script tags in HTML strings?
Apr 05, 2025 pm 12:45 PM
How to efficiently remove specific conditional expressions in script tags in HTML strings?
Apr 05, 2025 pm 12:45 PM
Efficiently modifying HTML string content This article will explore how to modify an HTML string, with the goal of removing...
