

使用SQL语句操作MYSQL字符编码_MySQL

-- 查看所有的字符编码
SHOW CHARACTER SET;
-- 查看创建数据库的指令并查看数据库使用的编码
show create database dbtest;
-- 查看数据库编码:
show variables like '%char%';
-- 设置character_set_server、set character_set_client和set character_set_results
set character_set_server = utf8; -- 服务器的默认字符集。使用这个语句可以修改成功,但重启服务后会失效。根本的办法是修改配置MYSQL文件MY.INI,character_set_server=utf8,配置到mysqld字段下。
set character_set_client = gbk; -- 来自客户端的语句的字符集。服务器使用character_set_client变量作为客户端发送的查询中使用的字符集。
set character_set_results = gbk; -- 用于向客户端返回查询结果的字符集。character_set_results变量指示服务器返回查询结果到客户端使用的字符集。包括结果数据,例如列值和结果元数据(如列名)。
-- 创建数据库时,设置数据库的编码方式
-- CHARACTER SET:指定数据库采用的字符集,utf8不能写成utf-8
-- COLLATE:指定数据库字符集的排序规则,utf8的默认排序规则为utf8_general_ci(通过show character set查看)
drop database if EXISTS dbtest;
create database dbtest CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 修改数据库编码
alter database dbtest CHARACTER SET GBK COLLATE gbk_chinese_ci;
alter database dbtest CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 创建表时,设置表、字段编码
use dbtest;
drop table if exists tbtest;
create table tbtest(
id int(10) auto_increment,
user_name varchar(60) CHARACTER SET GBK COLLATE gbk_chinese_ci,
email varchar(60),
PRIMARY key(id)
)CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 修改表编码
alter table tbtest character set utf8 COLLATE utf8_general_ci;
-- 修改字段编码
ALTER TABLE tbtest MODIFY email VARCHAR(60) CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 查看某字段使用的编码:
SELECT CHARSET(email) FROM tbtest;

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 11 common classification feature encoding techniques
Apr 12, 2023 pm 12:16 PM
11 common classification feature encoding techniques
Apr 12, 2023 pm 12:16 PM
Machine learning algorithms only accept numerical input, so if we encounter categorical features, we will encode the categorical features. This article summarizes 11 common categorical variable encoding methods. 1. ONE HOT ENCODING The most popular and commonly used encoding method is One Hot Enoding. A single variable with n observations and d distinct values is converted into d binary variables with n observations, each binary variable is identified by a bit (0, 1). For example: the simplest implementation after coding is to use pandas' get_dummiesnew_df=pd.get_dummies(columns=[‘Sex’], data=df)2,
 How many bytes do utf8 encoded Chinese characters occupy?
Feb 21, 2023 am 11:40 AM
How many bytes do utf8 encoded Chinese characters occupy?
Feb 21, 2023 am 11:40 AM
UTF8 encoded Chinese characters occupy 3 bytes. In UTF-8 encoding, one Chinese character is equal to three bytes, and one Chinese punctuation mark occupies three bytes; while in Unicode encoding, one Chinese character (including traditional Chinese) is equal to two bytes. UTF-8 uses 1~4 bytes to encode each character. One US-ASCIl character only needs 1 byte to encode. Latin, Greek, Cyrillic, Armenian, and Hebrew with diacritical marks. , Arabic, Syriac and other letters require 2-byte encoding.
 How to type arrows in Word
Apr 16, 2023 pm 11:37 PM
How to type arrows in Word
Apr 16, 2023 pm 11:37 PM
How to use AutoCorrect to type arrows in Word One of the fastest ways to type arrows in Word is to use the predefined AutoCorrect shortcuts. If you type a specific sequence of characters, Word automatically converts those characters into arrow symbols. You can draw many different arrow styles using this method. To type an arrow in Word using AutoCorrect: Move your cursor to the location in the document where you want the arrow to appear. Type one of the following character combinations: If you don't want what you type to be corrected to an arrow symbol, press the backspace key on your keyboard to
 Use java's Character.isDigit() function to determine whether a character is a number
Jul 27, 2023 am 09:32 AM
Use java's Character.isDigit() function to determine whether a character is a number
Jul 27, 2023 am 09:32 AM
Use Java's Character.isDigit() function to determine whether a character is a numeric character. Characters are represented in the form of ASCII codes internally in the computer. Each character has a corresponding ASCII code. Among them, the ASCII code values corresponding to the numeric characters 0 to 9 are 48 to 57 respectively. To determine whether a character is a number, you can use the isDigit() method provided by the Character class in Java. The isDigit() method is of the Character class
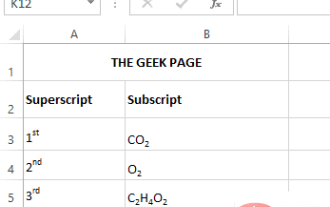 How to apply superscript and subscript formatting options in Microsoft Excel
Apr 14, 2023 pm 12:07 PM
How to apply superscript and subscript formatting options in Microsoft Excel
Apr 14, 2023 pm 12:07 PM
A superscript is a character or characters, either letters or numbers, that you need to set slightly above the normal line of text. For example, if you need to write 1st, the letter st needs to be slightly higher than the character 1. Likewise, a subscript is a group of characters or a single character and needs to be set slightly lower than normal text level. For example, when you write a chemical formula, you need to place the numbers below the normal line of characters. The following screenshots show some examples of superscript and subscript formatting. Although it may seem like a daunting task, applying superscript and subscript formatting to your text is actually quite simple. In this article, we will explain in some simple steps how to easily format text using superscript or subscript. Hope you enjoyed reading this article. How to apply superscript in Excel
 Knowledge graph: the ideal partner for large models
Jan 29, 2024 am 09:21 AM
Knowledge graph: the ideal partner for large models
Jan 29, 2024 am 09:21 AM
Large language models (LLMs) have the ability to generate smooth and coherent text, bringing new prospects to areas such as artificial intelligence conversation and creative writing. However, LLM also has some key limitations. First, their knowledge is limited to patterns recognized from training data, lacking a true understanding of the world. Second, reasoning skills are limited and cannot make logical inferences or fuse facts from multiple data sources. When faced with more complex and open-ended questions, LLM's answers may become absurd or contradictory, known as "illusions." Therefore, although LLM is very useful in some aspects, it still has certain limitations when dealing with complex problems and real-world situations. In order to bridge these gaps, retrieval-augmented generation (RAG) systems have emerged in recent years. The core idea is
 How do you enter extended characters, such as the degree symbol, on iPhone and Mac?
Apr 22, 2023 pm 02:01 PM
How do you enter extended characters, such as the degree symbol, on iPhone and Mac?
Apr 22, 2023 pm 02:01 PM
Your physical or numeric keyboard provides a limited number of character options on the surface. However, there are several ways to access accented letters, special characters, and more on iPhone, iPad, and Mac. The standard iOS keyboard gives you quick access to uppercase and lowercase letters, standard numbers, punctuation, and characters. Of course, there are many other characters. You can choose from letters with diacritics to upside-down question marks. You may have stumbled upon a hidden special character. If not, here's how to access them on iPhone, iPad, and Mac. How to Access Extended Characters on iPhone and iPad Getting extended characters on your iPhone or iPad is very simple. In "Information", "
 Correct way to display Chinese characters in matplotlib
Jan 13, 2024 am 11:03 AM
Correct way to display Chinese characters in matplotlib
Jan 13, 2024 am 11:03 AM
Correctly displaying Chinese characters in matplotlib is a problem often encountered by many Chinese users. By default, matplotlib uses English fonts and cannot display Chinese characters correctly. To solve this problem, we need to set the correct Chinese font and apply it to matplotlib. Below are some specific code examples to help you display Chinese characters correctly in matplotlib. First, we need to import the required libraries: importmatplot
