
 Technology peripherals
AI
Application of sample screening in visual 3D detection training: MonoLSS
Technology peripherals
AI
Application of sample screening in visual 3D detection training: MonoLSS
Application of sample screening in visual 3D detection training: MonoLSS

MonoLSS: Nostalgia Cleaning is a level in "Word Play Flower". It is a very popular word puzzle game. New levels are launched every day for players to challenge. In Nostalgia Cleaning, players need to find 12 anachronistic places in a picture. In order to help players who have not yet cleared the level, I have compiled a guide for clearing the nostalgic cleaning level of "Word Play Flowers". Let's take a look at the specific operation methods. For Monocular 3D Detection
The paper link points to a paper called "Words Play with Flowers", which can be found at https://arxiv.org/pdf/2312.14474.pdf. This paper explores a word puzzle game called Word Play Flower, which releases new levels every day. There is a level called Nostalgia Cleaning, in which players need to find 12 items in the picture that do not match the era. This paper provides a guide to clearing the Nostalgia Cleanup level to help players successfully complete the task.
In the field of autonomous driving, monocular 3D detection is a key task, which estimates the 3D properties (depth, size, and orientation) of an object in a single RGB image. Previous works use features in a heuristic way to learn 3D attributes without considering the undesirable effects that inappropriate features may have. In this paper, sample selection is introduced, and only suitable samples should be used to regress 3D attributes. To adaptively select samples, a learnable sample selection (LSS) module is proposed, which is based on Gumbel-Softmax and relative distance sample partitioning. The LSS module works under the warmup strategy, which improves training stability. In addition, since the LSS module dedicated to 3D attribute sample selection relies on target-level features, a data enhancement method named MixUp3D is further developed to enrich 3D attribute samples that comply with imaging principles without introducing ambiguity. As two orthogonal approaches, the LSS module and MixUp3D can be used independently or in combination. Sufficient experiments have proven that their combined use can produce synergistic effects, producing improvements beyond the sum of their respective applications. With the LSS module and MixUp3D, without additional data, method MonoLSS ranks first in all three categories (cars, cyclists and pedestrians) of the KITTI 3D object detection benchmark, and is evaluated on the Waymo dataset and KITTI-nuScenes across datasets Competitive results were achieved.
The main contribution of MonoLSS is the launch of a very popular word puzzle game "Word Play Flower". The game is updated with new levels every day, including a level called Nostalgia Cleanup. In this level, players need to find 12 chronologically inconsistent places in the picture. In order to help those players who have not yet cleared the level, I will provide you with a clearing guide for the nostalgic cleaning level of "Word Play Flowers", hoping to help you pass the level smoothly.
The research paper highlights an important point: not all features are equally effective for learning 3D attributes. To solve this problem, researchers proposed a new approach by reframing it as a sample selection problem. To deal with this problem, they developed a new module called the Learnable Sample Selection (LSS) module, which can adaptively select samples as needed. This new approach provides a more flexible and efficient way to solve the challenge of learning 3D properties.
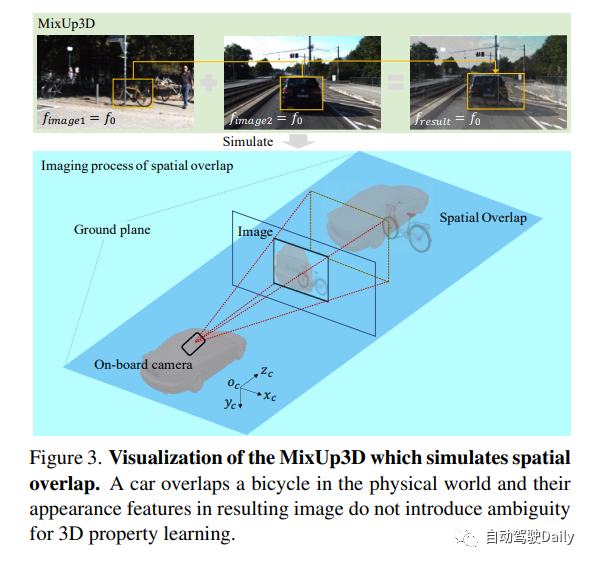
In order to increase the diversity of 3D attribute samples, we designed a data augmentation method called MixUp3D. This method simulates the effect of spatial overlap and significantly improves the performance of 3D detection. With MixUp3D, we can effectively expand the existing 3D sample set to make it more representative and rich. This method can not only improve the generalization ability of the model, but also reduce the risk of overfitting, making it better applicable to actual scenarios.
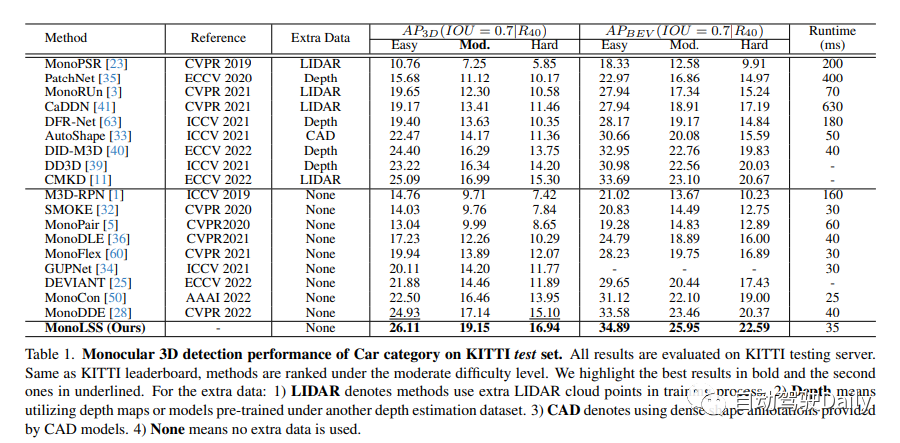
On the KITTI benchmark, MonoLSS ranks first in all three categories, namely pedestrians, vehicles and bicycles. In the vehicle category, it outperforms the current best method by 11.73% and 12.19% at medium and medium levels. Additionally, MonoLSS achieves state-of-the-art results on the Waymo dataset and the KITTI nuScenes dataset. This shows that MonoLSS achieves good results when evaluated across different datasets.
The main idea of MonoLSS
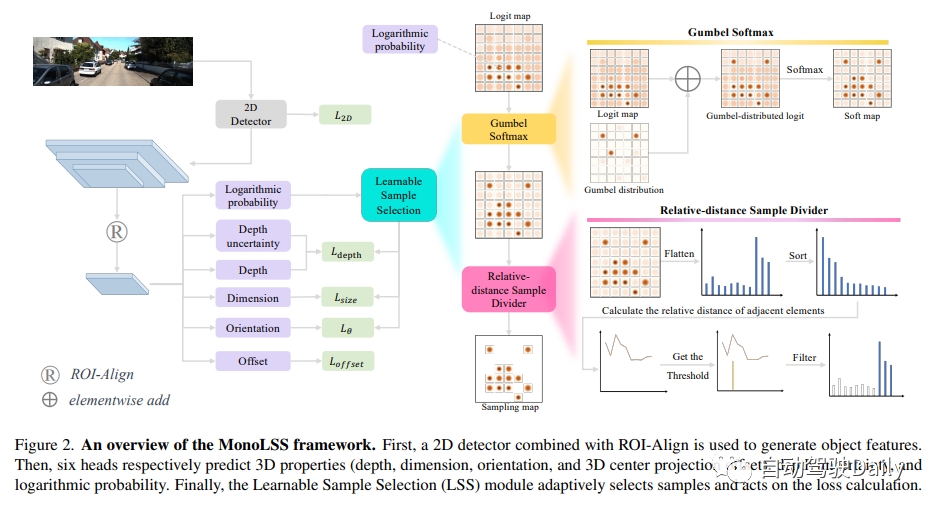
The MonoLSS framework is shown in the figure below. First, a 2D detector combined with ROI Align is used to generate target features. Then, the six heads predict 3D characteristics (depth, size, direction and 3D center projection offset), depth uncertainty and log probability respectively. Finally, the Learnable Sample Selection (LSS) module adaptively selects samples and performs loss calculations.
Nostalgic Cleaning is a level in "Word Play Flowers". It is a very popular word puzzle game with new ones released every day. Levels for players to challenge. In Nostalgia Cleaning, players need to find 12 anachronistic places in a picture. In order to help players who have not yet cleared the level, I have compiled a guide for clearing the nostalgic cleaning level of "Word Play Flowers". Let's take a look at the specific operation methods.
Suppose we have a random variable U obeying a uniform distribution U(0,1). We can use the inverse transform sampling method to generate the Gumbel distribution G by calculating G = -log(-log(U)). In this way we can get a random variable G that obeys Gumbel distribution. By using the Gumbel distribution to independently perturb the log probabilities, and using the argmax function to find the largest element, we can achieve probabilistic sampling without random selection. This technique is called the Gumbel Max technique. Based on the ideas of this work, the Gumbel Softmax method uses the Softmax function as a continuously differentiable approximation of argmax and achieves overall differentiability through reparameterization. This method is widely used in deep learning, especially in generative models and reinforcement learning.
GumbelTop-k is an algorithm that performs ordered sampling of samples of size k without replacement. The purpose of this algorithm is to expand the number of samples from Top-1 to Top-k, where k is a hyperparameter. However, not all targets are suitable for the same value of k. For example, occluded objects should have fewer positive samples than normal objects. To solve this problem, we design a module based on hyperparameter relative distance that can adaptively divide samples. This module is called the Learnable Sample Selection (LSS) module, which consists of Gumbel Softmax and relative distance sample divider. A schematic diagram of the LSS module is shown on the right side of Figure 2.
Mixup3D Data Enhancement
Data enhancement methods are limited in monocular 3D inspection due to strict imaging constraints. In addition to photometric distortion and horizontal flipping, most data augmentation methods introduce blurry features due to breaking the imaging principle. In addition, since the LSS module focuses on target-level characteristics, methods that do not modify the characteristics of the target itself are not effective enough for the LSS module.
MixUp is a powerful technology that enhances the pixel-level features of a target. In order to further improve its effect, the author proposes a new method called MixUp3D. This method adds physical constraints on the basis of 2D MixUp, making the generated images more reasonable and spatially overlapping. Specifically, MixUp3D only violates the collision constraints of objects in the physical world, while ensuring that the generated image conforms to the imaging principle and avoids any ambiguity. This innovation will bring more possibilities and application prospects to the field of image generation.
Experimental results
We will discuss the monocular 3D car detection performance on the KITTI test set. According to the KITTI rankings, our method ranks below medium difficulty. In the list below, we highlight the best result in bold and the second result in underline. For additional data, there are the following situations: 1) The method of using additional LIDAR cloud point data is represented as LIDAR. 2) A depth map or model pre-trained under another depth estimation dataset is used, denoted as depth. 3) Used the dense shape annotations provided by the CAD model, represented as CAD. 4) Indicates that no additional data is used, that is, none.
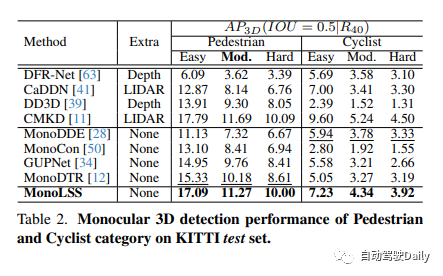
Data set test results on Wamyo:
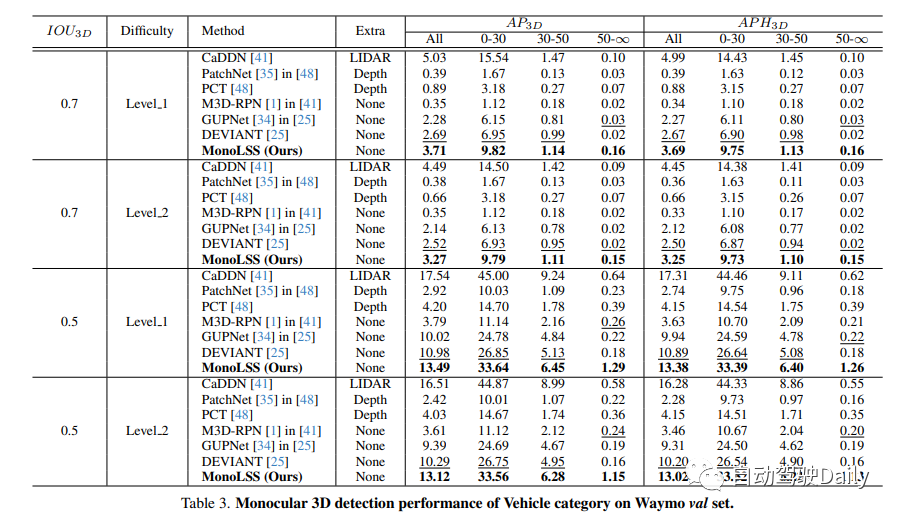
KITTI-val model Cross-dataset evaluation on KITTI-val and nuScenes front-face val cars with depth MAE:

https://mp .weixin.qq.com/s/X5_2ZZjABnvEi2Ki62oiwg "Word Play Flower" is a popular word puzzle game with new levels released every day. Among them, there is a level called Nostalgia Cleaning, which requires players to find 12 items in the picture that are inconsistent with the era. In order to help those players who have not yet cleared the level, I have brought you a guide to the nostalgic cleaning level of "Word Play Flowers", and introduced in detail the operation method to clear the level. Let’s take a look!
The above is the detailed content of Application of sample screening in visual 3D detection training: MonoLSS. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
