

Can win10 be installed on win7 motherboard?

When some friends disassemble the case and check their motherboard, they will find the word win7 written on the motherboard, so they are worried that the computer cannot install and use the win10 system. In fact, as long as the computer configuration is sufficient, the win10 system can be installed on the win7 motherboard. Let’s take a look at the detailed introduction below.
Can win10 be installed on a win7 motherboard?
Answer: You can install win10 as long as the configuration meets the requirements of win10.
According to the configuration requirements officially given by Microsoft, win10 can be installed as long as the following conditions are met, regardless of the motherboard.
Processor: 1 GHz or faster processor or SoC
RAM: 1 GB (32-bit) or 2 GB (64-bit)
Hard disk space: 16 GB (32-bit operating system) or 20 GB (64-bit operating system)
Graphics card: DirectX 9 or higher (includes WDDM 1.0 driver)
Monitor: 800 x 600 or above resolution Rate

win7 motherboard installation win10 tutorial
1. First download a win10 system from this site.This is a streamlined version of the system, which deletes many unnecessary services in win10, reduces the memory it occupies, and is more suitable for users with lower configurations.
At the same time, the system also has very good compatibility and stability. Even computers that previously used the win7 system can run this system smoothly and stably.

2. After downloading the system, find the download location and choose to load the system.
3. After the loading is complete, run the "One-click installation system"

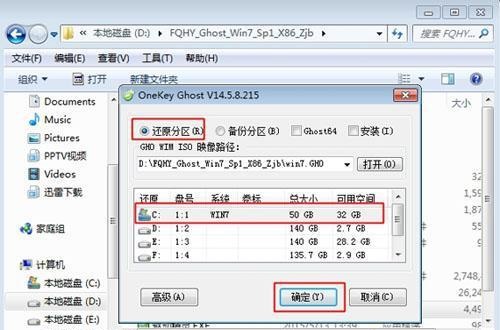
4. Check "Restore" Partition" select "c drive" and click "OK"
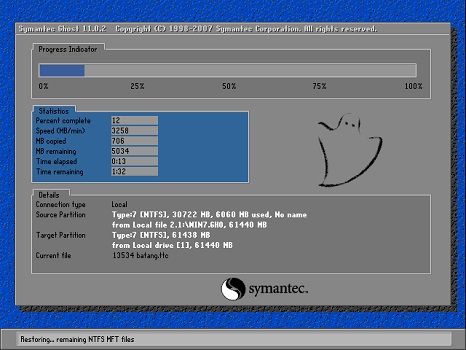
5, and then wait for the system to automatically install.
The above is the detailed content of Can win10 be installed on win7 motherboard?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 What are the methods of tuning performance of Zookeeper on CentOS
Apr 14, 2025 pm 03:18 PM
What are the methods of tuning performance of Zookeeper on CentOS
Apr 14, 2025 pm 03:18 PM
Zookeeper performance tuning on CentOS can start from multiple aspects, including hardware configuration, operating system optimization, configuration parameter adjustment, monitoring and maintenance, etc. Here are some specific tuning methods: SSD is recommended for hardware configuration: Since Zookeeper's data is written to disk, it is highly recommended to use SSD to improve I/O performance. Enough memory: Allocate enough memory resources to Zookeeper to avoid frequent disk read and write. Multi-core CPU: Use multi-core CPU to ensure that Zookeeper can process it in parallel.
 What is Linux actually good for?
Apr 12, 2025 am 12:20 AM
What is Linux actually good for?
Apr 12, 2025 am 12:20 AM
Linux is suitable for servers, development environments, and embedded systems. 1. As a server operating system, Linux is stable and efficient, and is often used to deploy high-concurrency applications. 2. As a development environment, Linux provides efficient command line tools and package management systems to improve development efficiency. 3. In embedded systems, Linux is lightweight and customizable, suitable for environments with limited resources.
 How Debian improves Hadoop data processing speed
Apr 13, 2025 am 11:54 AM
How Debian improves Hadoop data processing speed
Apr 13, 2025 am 11:54 AM
This article discusses how to improve Hadoop data processing efficiency on Debian systems. Optimization strategies cover hardware upgrades, operating system parameter adjustments, Hadoop configuration modifications, and the use of efficient algorithms and tools. 1. Hardware resource strengthening ensures that all nodes have consistent hardware configurations, especially paying attention to CPU, memory and network equipment performance. Choosing high-performance hardware components is essential to improve overall processing speed. 2. Operating system tunes file descriptors and network connections: Modify the /etc/security/limits.conf file to increase the upper limit of file descriptors and network connections allowed to be opened at the same time by the system. JVM parameter adjustment: Adjust in hadoop-env.sh file
 Where is the Redis restart service
Apr 10, 2025 pm 02:36 PM
Where is the Redis restart service
Apr 10, 2025 pm 02:36 PM
How to restart the Redis service in different operating systems: Linux/macOS: Use the systemctl command (systemctl restart redis-server) or the service command (service redis-server restart). Windows: Use the services.msc tool (enter "services.msc" in the Run dialog box and press Enter) and right-click the "Redis" service and select "Restart".
 Who invented the mac system
Apr 12, 2025 pm 05:12 PM
Who invented the mac system
Apr 12, 2025 pm 05:12 PM
The macOS operating system was invented by Apple. Its predecessor, System Software, was launched in 1984. After many iterations, it was updated to Mac OS X in 2001 and changed its name to macOS in 2012.
 What language is apache written in?
Apr 13, 2025 pm 12:42 PM
What language is apache written in?
Apr 13, 2025 pm 12:42 PM
Apache is written in C. The language provides speed, stability, portability, and direct hardware access, making it ideal for web server development.
 Debian Hadoop data transmission optimization method
Apr 12, 2025 pm 08:24 PM
Debian Hadoop data transmission optimization method
Apr 12, 2025 pm 08:24 PM
The key to improving the efficiency of data transmission in DebianHadoop cluster lies in the comprehensive application of multiple strategies. This article will elaborate on optimization methods to help you significantly improve cluster performance. 1. The data localization strategy maximizes the allocation of computing tasks to the data storage nodes, effectively reducing data transmission between nodes. Hadoop's data localization mechanism will automatically move data blocks to the node where the computing task is located, thereby avoiding performance bottlenecks caused by network transmission. 2. Data compression technology adopts data compression technology during data transmission to reduce the amount of data transmitted on the network and thereby improve transmission efficiency. Hadoop supports a variety of compression algorithms, such as Snappy, Gzip, LZO, etc. You can choose the optimal algorithm according to the actual situation. three,
