

Currently, GPT-4 Vision has shown amazing capabilities in language understanding and visual processing.
However, for those looking for a cost-effective alternative without compromising performance, open source is an option with unlimited potential.
Youssef Hosni is a foreign developer who provides us with three open source alternatives with absolutely guaranteed accessibility to replace GPT-4V.
The three open source visual language models LLaVa, CogAgent and BakLLaVA have great potential in the field of visual processing and are worthy of our in-depth understanding. The research and development of these models can provide us with more efficient and accurate visual processing solutions. By using these models, we can improve the accuracy and efficiency of tasks such as image recognition, target detection, and image generation, and bring insights to research and applications in the field of visual processing.
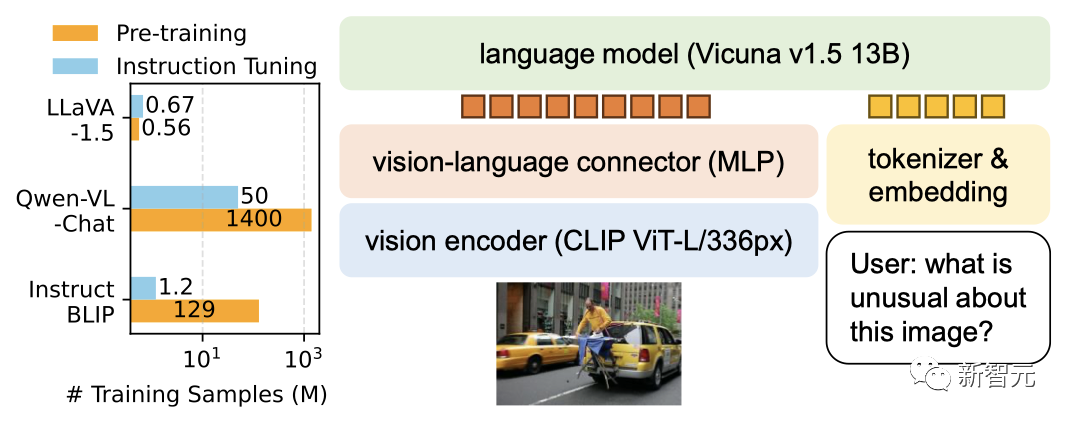
##LLaVa LLaVA is a multi-modal large model developed in collaboration between researchers at the University of Wisconsin-Madison, Microsoft Research, and Columbia University. The initial version was released in April. It combines a visual encoder and Vicuna (for general visual and language understanding) to demonstrate excellent chat capabilities.
LLaVA is a multi-modal large model developed in collaboration between researchers at the University of Wisconsin-Madison, Microsoft Research, and Columbia University. The initial version was released in April. It combines a visual encoder and Vicuna (for general visual and language understanding) to demonstrate excellent chat capabilities.
Picture
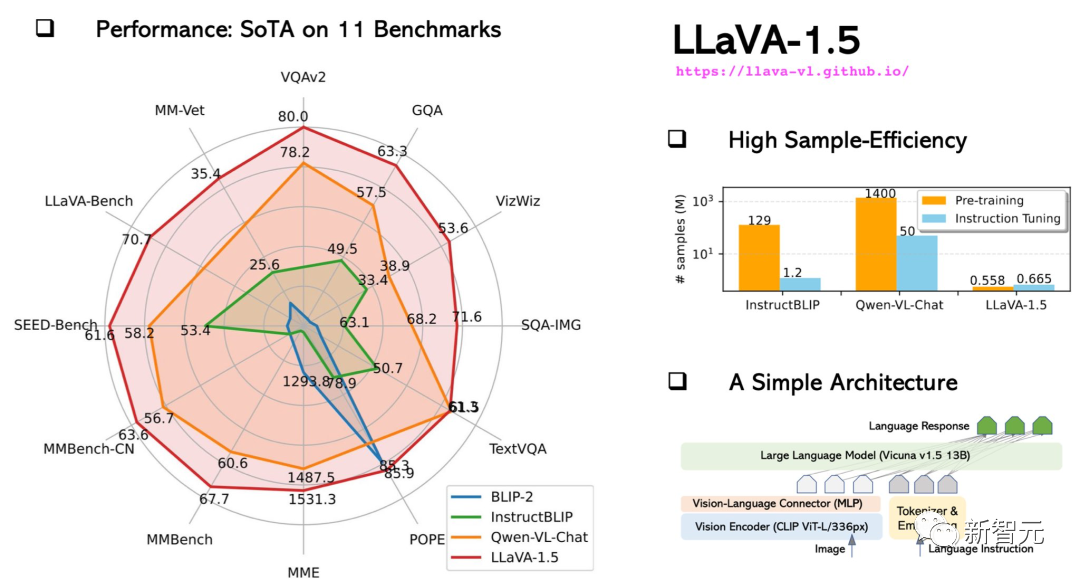
In October, the upgraded LLaVA-1.5 was close to multi-modal GPT-4 in performance, and performed well on the Science QA data set State-of-the-art results (SOTA) were achieved. Picture
Picture
 Picture
Picture
 LLaVA demonstrates some multi-modal capabilities close to the level of GPT-4, with a GPT-4 relative score of 85% in visual chat. In terms of reasoning question and answer, LLaVA even reached the new SoTA-92.53%, defeating the multi-modal thinking chain.
LLaVA demonstrates some multi-modal capabilities close to the level of GPT-4, with a GPT-4 relative score of 85% in visual chat. In terms of reasoning question and answer, LLaVA even reached the new SoTA-92.53%, defeating the multi-modal thinking chain.
Picture
In terms of visual reasoning, its performance is very eye-catching. Picture
Picture
 Picture
Picture
 LLaVA still can't answer completely correctly. The upgraded LLaVA-1.5 gave the perfect answer: "There is no desert at all in the picture, but there are palm trees beaches, city skylines and a large body of water."
LLaVA still can't answer completely correctly. The upgraded LLaVA-1.5 gave the perfect answer: "There is no desert at all in the picture, but there are palm trees beaches, city skylines and a large body of water."
Picture
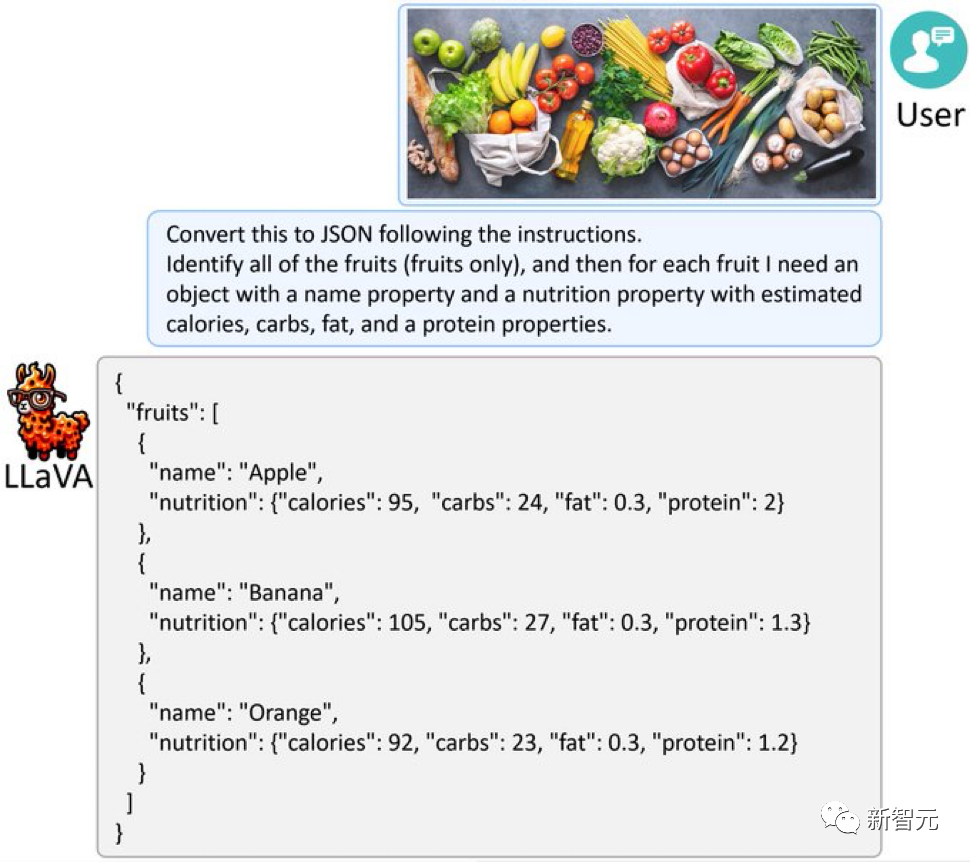
In addition, LLaVA-1.5 can also extract information from the picture and answer according to the required format, such as outputting it in JSON format. Picture
Picture
 Picture
Picture
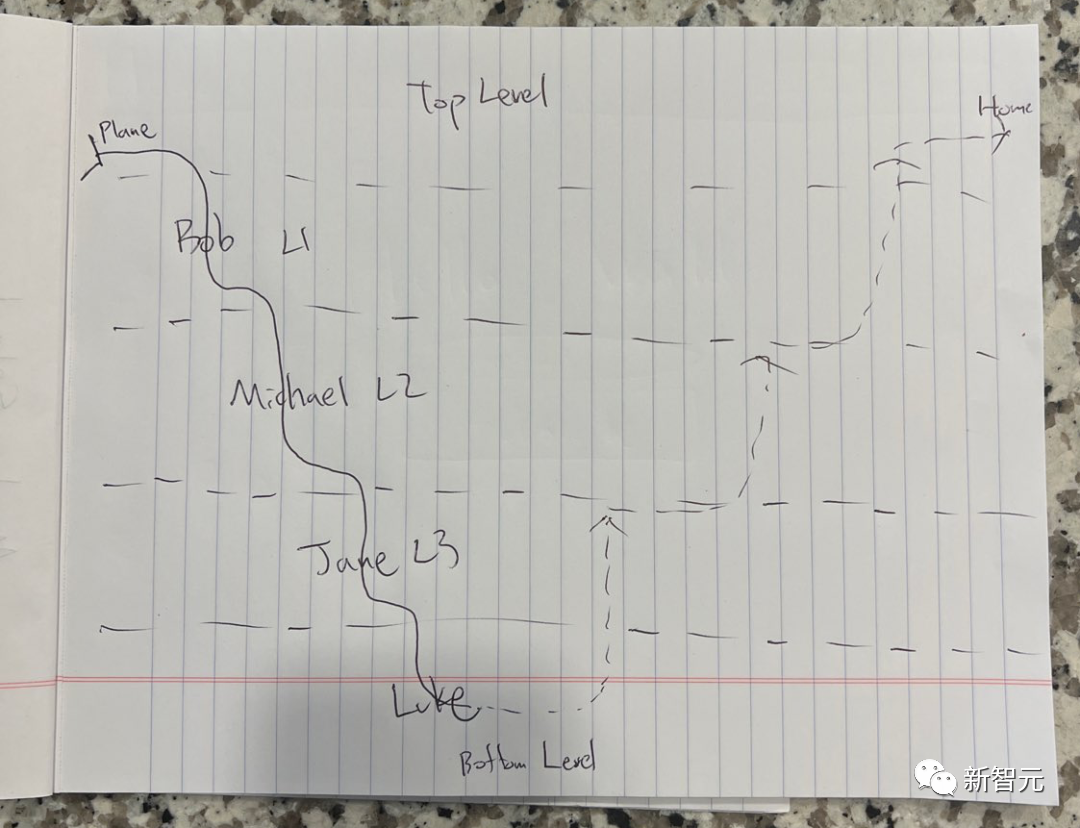
What does the picture below mean?
 Picture
Picture
This is a simplified sketch based on Nolan's "Inception". In order to increase the difficulty, the character's name has been changed to a pseudonym. .
LLaVA-1.5 surprisingly answered: "This is a picture about the movie "Inception". It shows different levels in the dream world, each level is represented by a line. The picture is written in A piece of paper, the paper is placed on a table."
 Picture
Picture
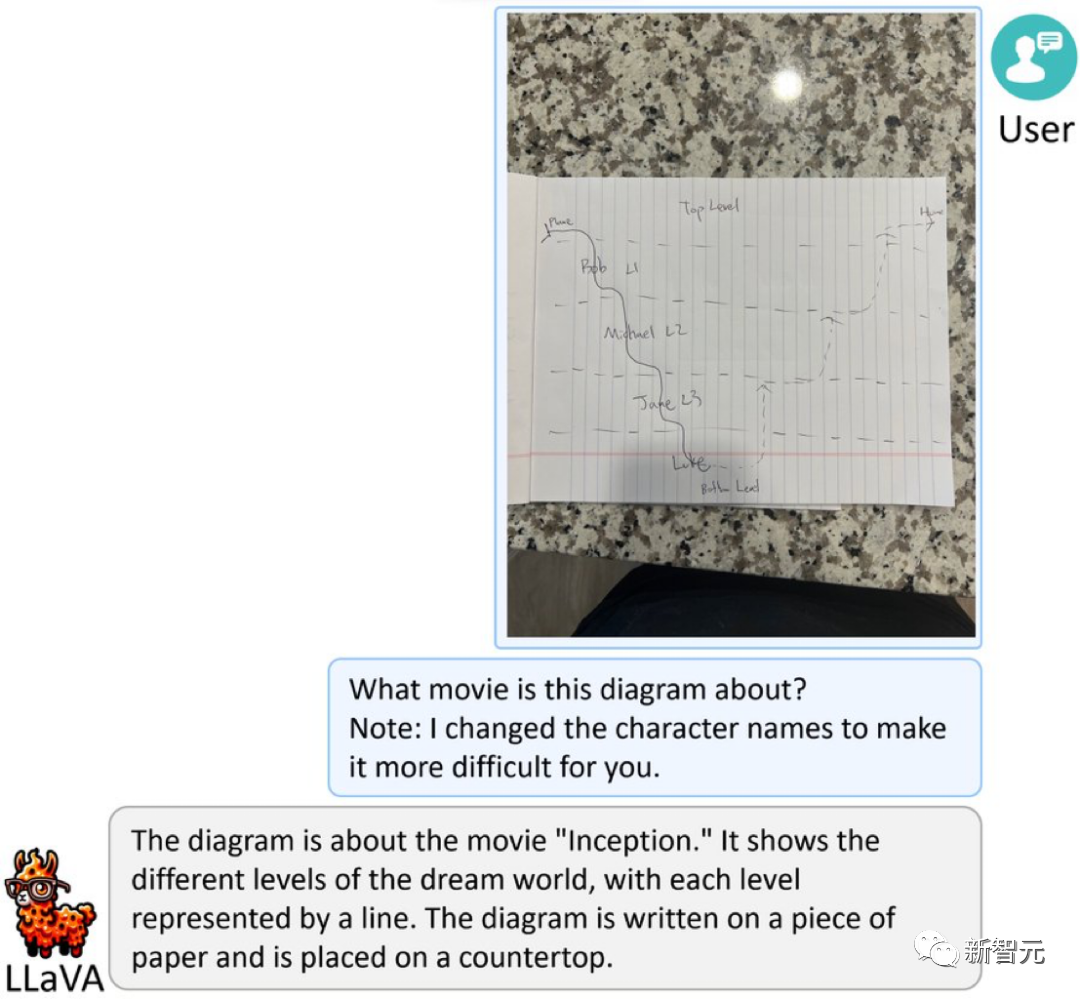
A food picture is sent directly to LLaVA-1.5, and it will be given to you quickly Generate a recipe.
 Picture
Picture
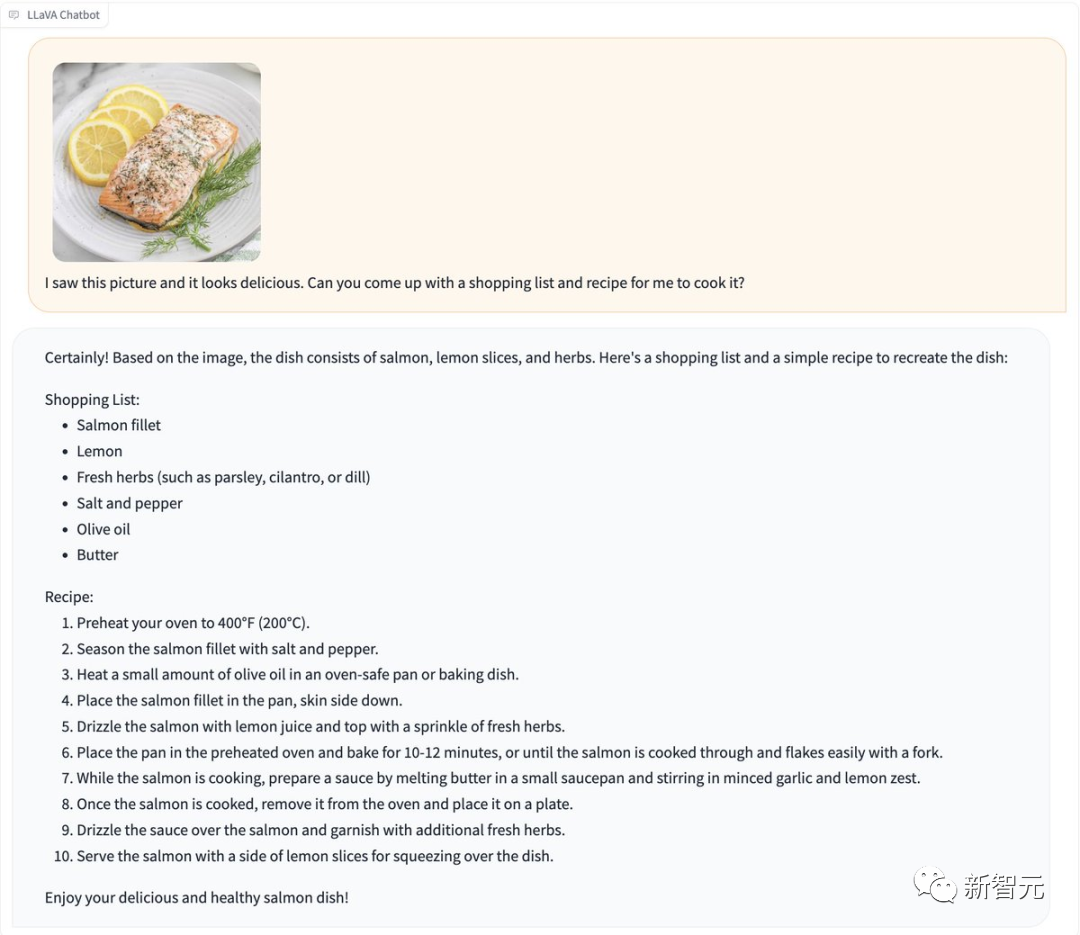
Moreover, LLaVA-1.5 can recognize the verification code without "jailbreaking".
 Picture
Picture
It can also detect what kind of coin is in the picture.
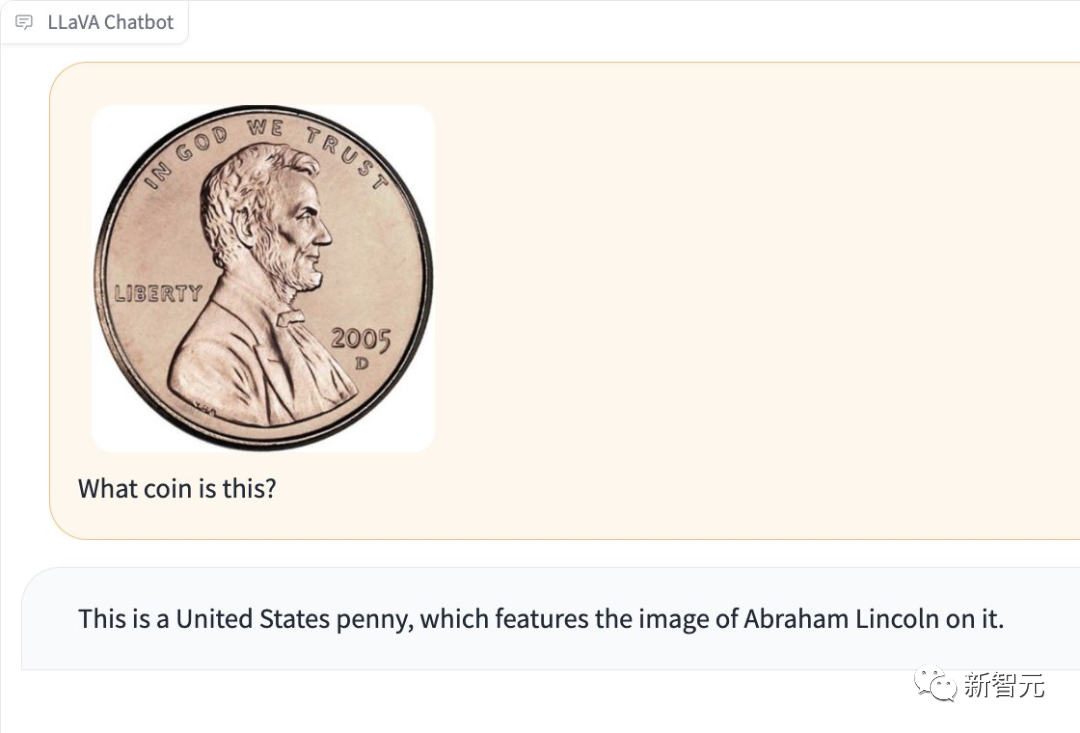 Picture
Picture
What’s particularly impressive is that LLaVA-1.5 can also tell you what breed the dog in the picture is.
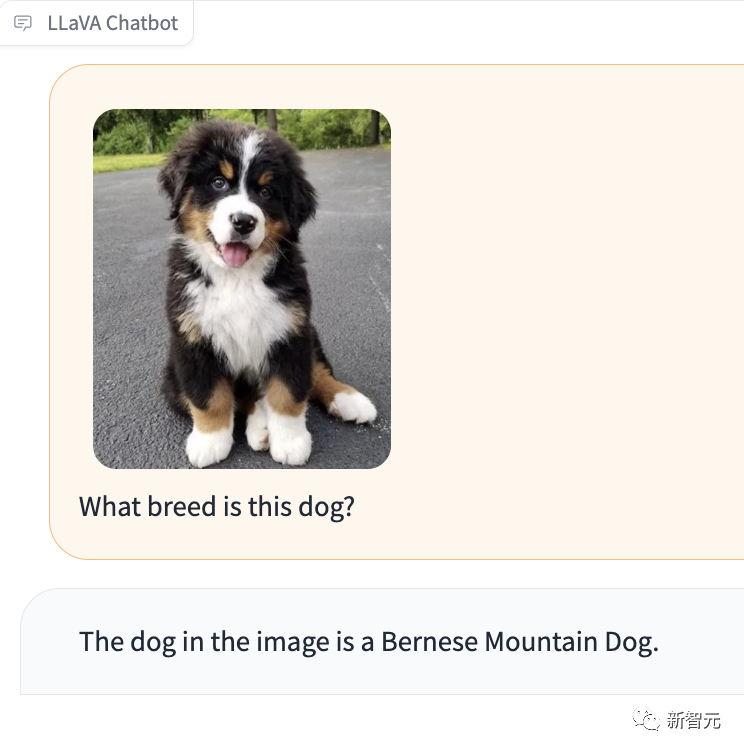 Picture
Picture
Some netizens used Bing to generate a picture of a man wearing a winter coat on a sunny summer beach and asked LLaVA 1.5 to point it out What are the problems in the picture? Its eye is very sharp -
This is a processed or Photoshopped photo, in which a man is wearing a jacket and standing on the beach. The man opened his coat and the sun shone down on him. The problem with this image is that it's not an actual beach scene. The man was not actually standing on the beach and the sun was not shining on him. This image was photoshopped to create the illusion of a beach scene, but it does not truly represent the scene.
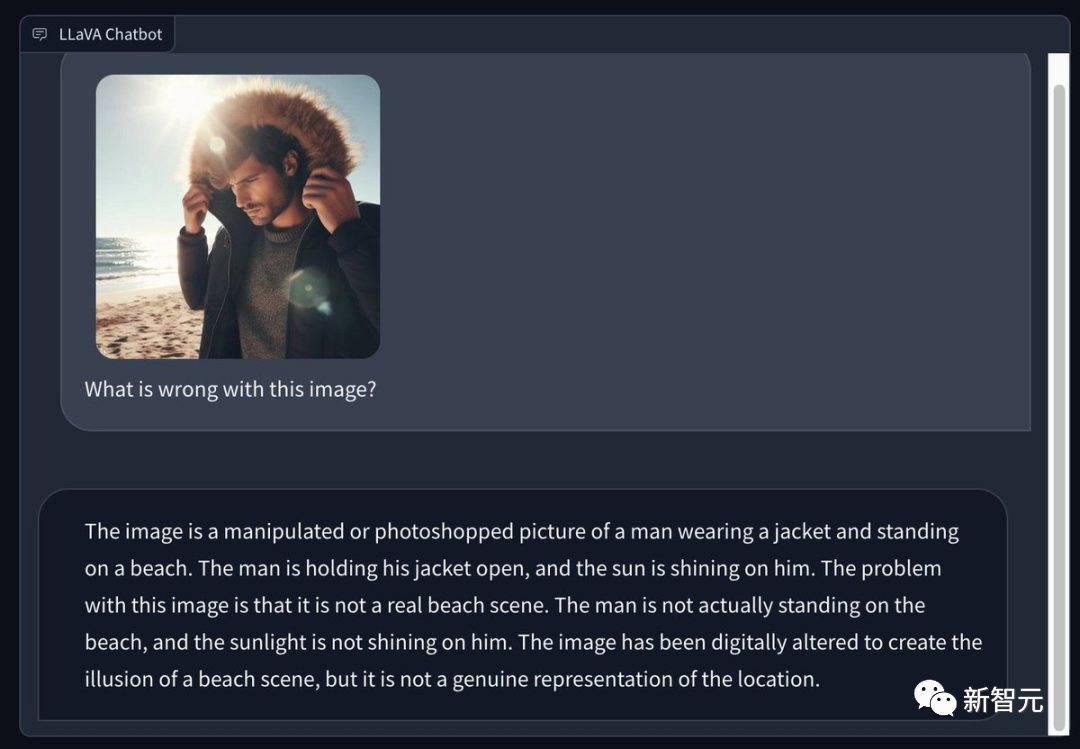 Picture
Picture
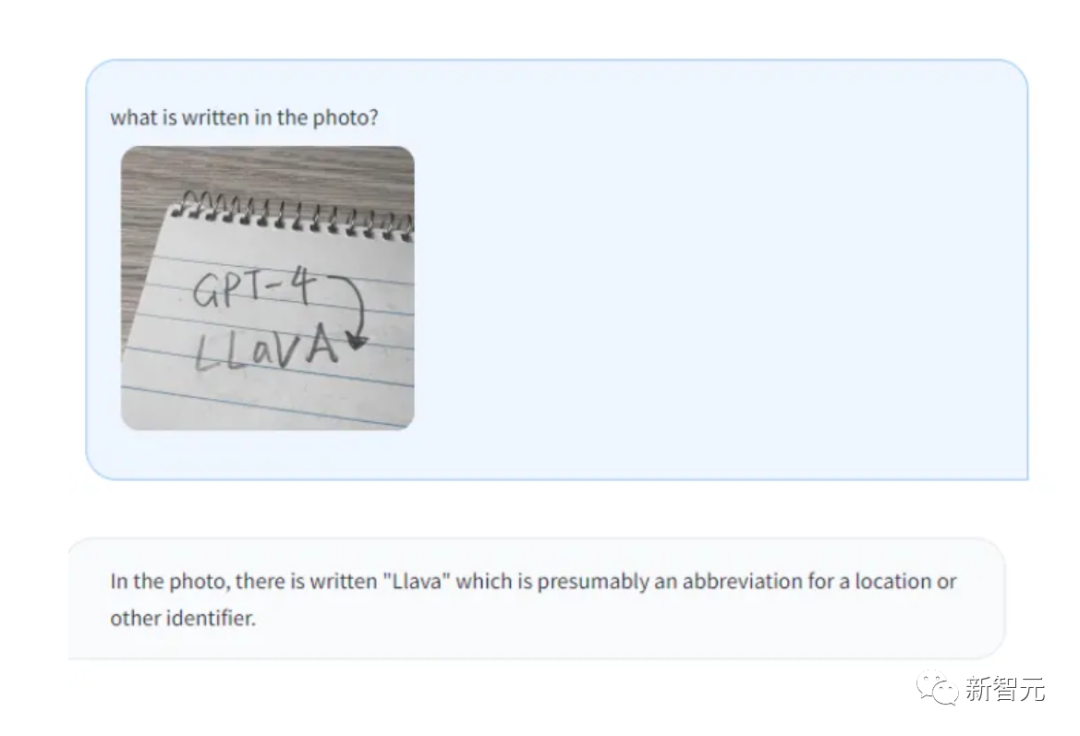
OCR recognition, LLaVA’s performance is also very powerful.
 Picture
Picture
 Picture
Picture
 Picture
Picture
CogAgent is an open source visual language model improved on the basis of CogVLM, a researcher from Tsinghua University.
CogAgent-18B has 11 billion visual parameters and 7 billion language parameters.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2312.08914.pdf
CogAgent-18B achieves state-of-the-art general performance on 9 classic cross-modal benchmarks (including VQAv2, OK-VQ, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet and POPE) .
It significantly outperforms existing models on graphical user interface manipulation datasets such as AITW and Mind2Web.
In addition to all the existing functions of CogVLM (visualized multi-turn dialogue, visual grounding), CogAgent.NET also provides more functions:
1. Support higher resolution visual input and dialogue answering questions. Supports ultra-high resolution image input of 1120x1120.
2. Have the ability to visualize the agent, and be able to return the plan, next action and specific operation with coordinates for any given task on any graphical user interface screenshot.
3. The GUI-related question answering function has been enhanced to enable it to handle issues related to screenshots of any GUI such as web pages, PC applications, mobile applications, etc.
4. By improving pre-training and fine-tuning, the capabilities of OCR-related tasks are enhanced.
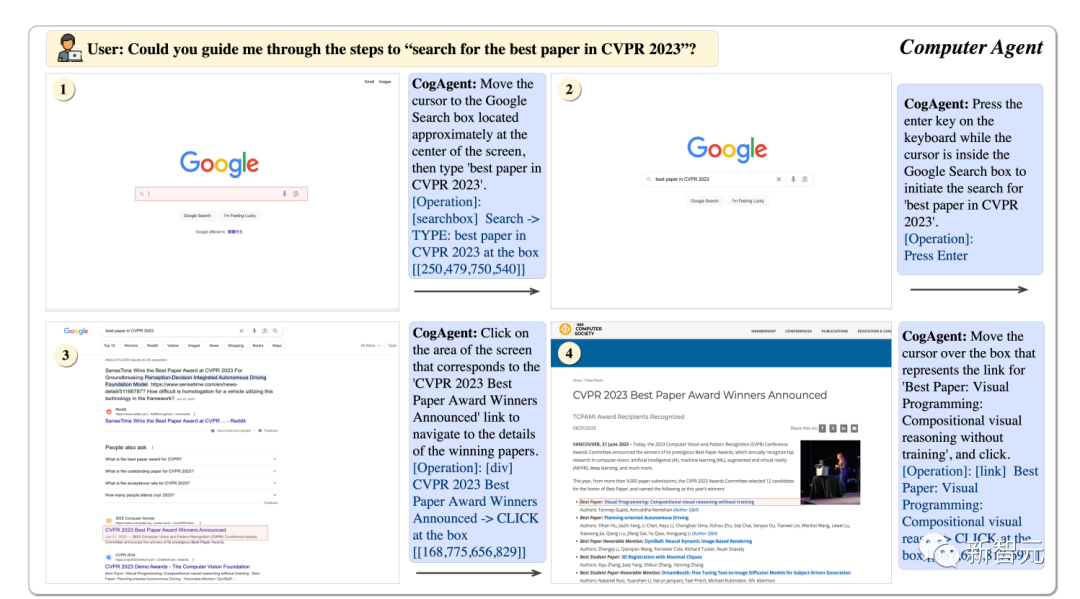
Using CogAgent, it can help us find the best papers of CVPR23 step by step.
 Picture
Picture
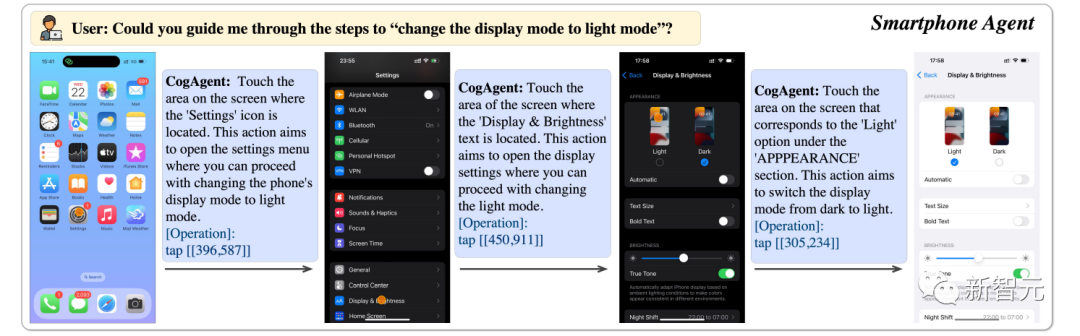
can help us adjust the phone display to bright mode.
 Picture
Picture
CogAgent can analyze how many likes this tweet has and why it is so popular, and even reply with a "Brilliant" , it can all operate.
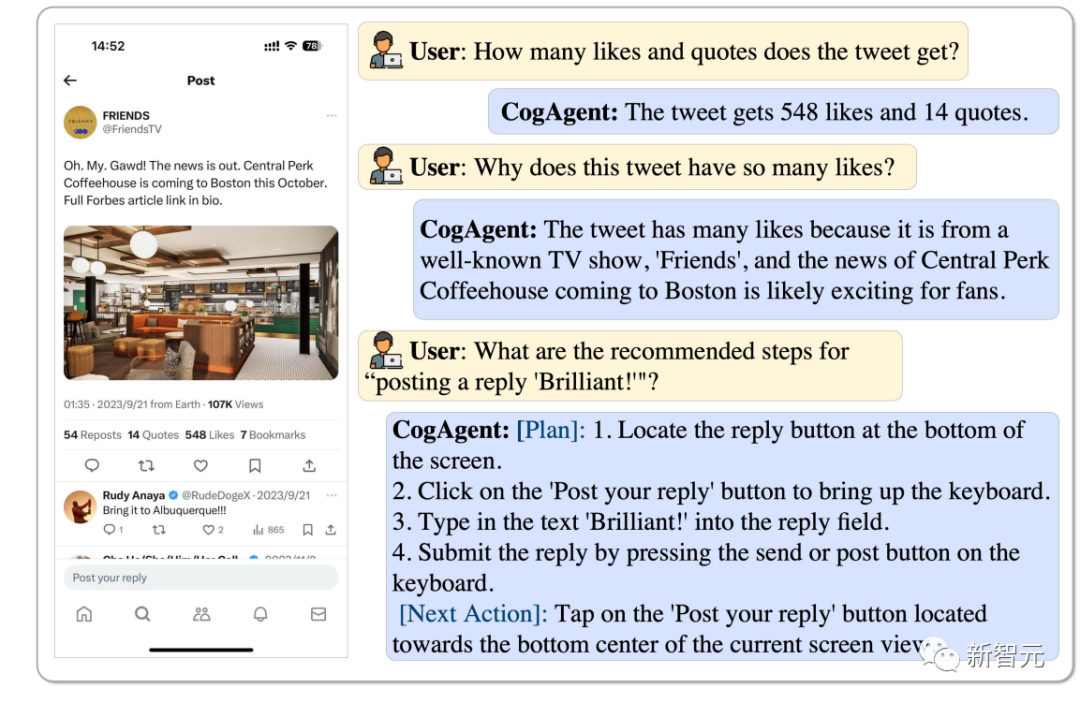 Picture
Picture
How to choose the fastest route from the University of Florida to Hollywood? If you start at 8am, how do you estimate how long it will take? CogAgent can answer all.
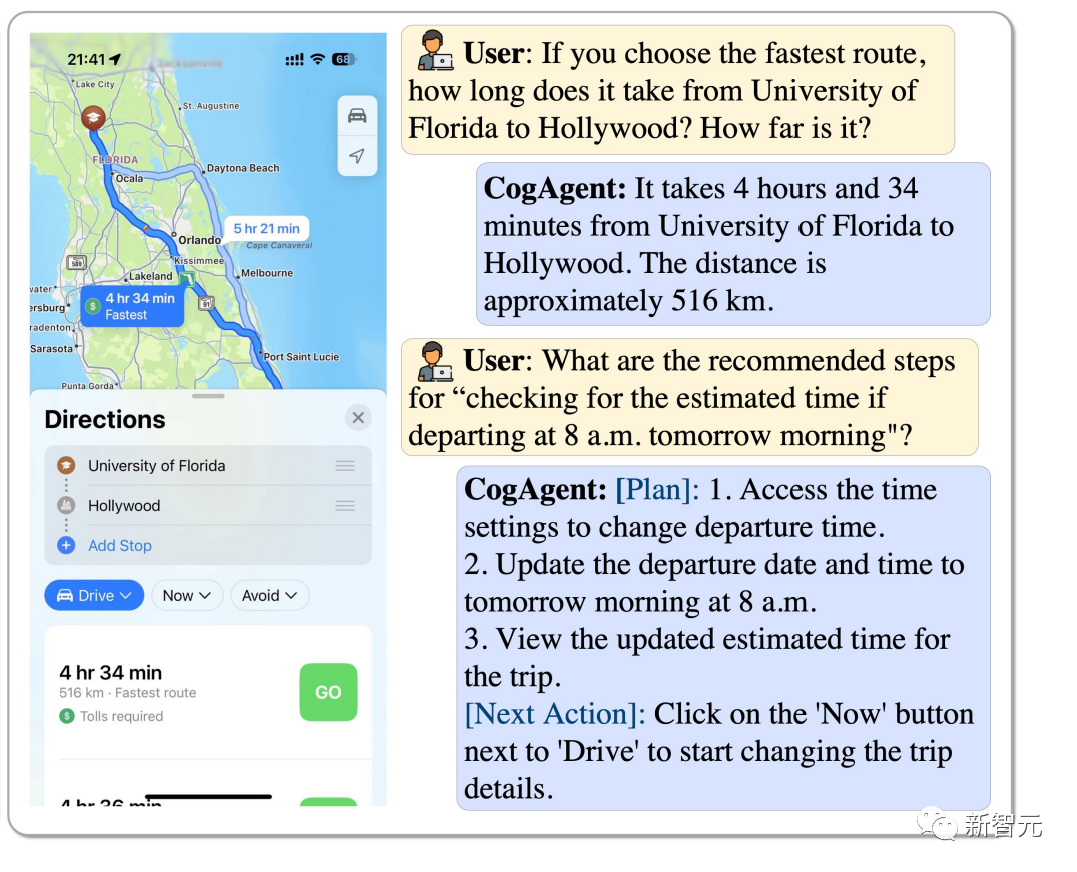 Picture
Picture
You can set a specific subject and let CogAgent send emails to the specified mailbox.
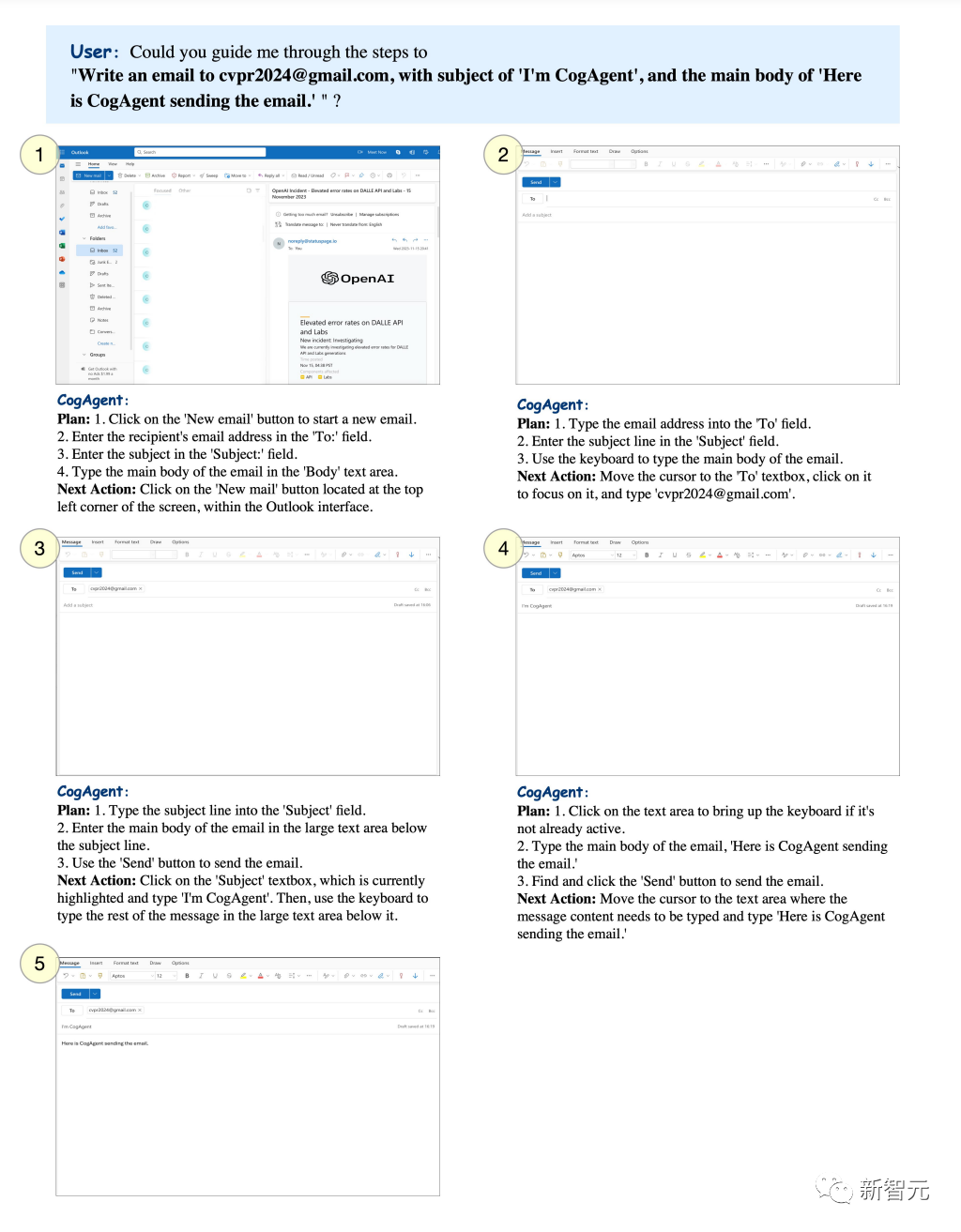 Picture
Picture
If you want to listen to the song "You raise me up", CogAgent can list the steps step by step.
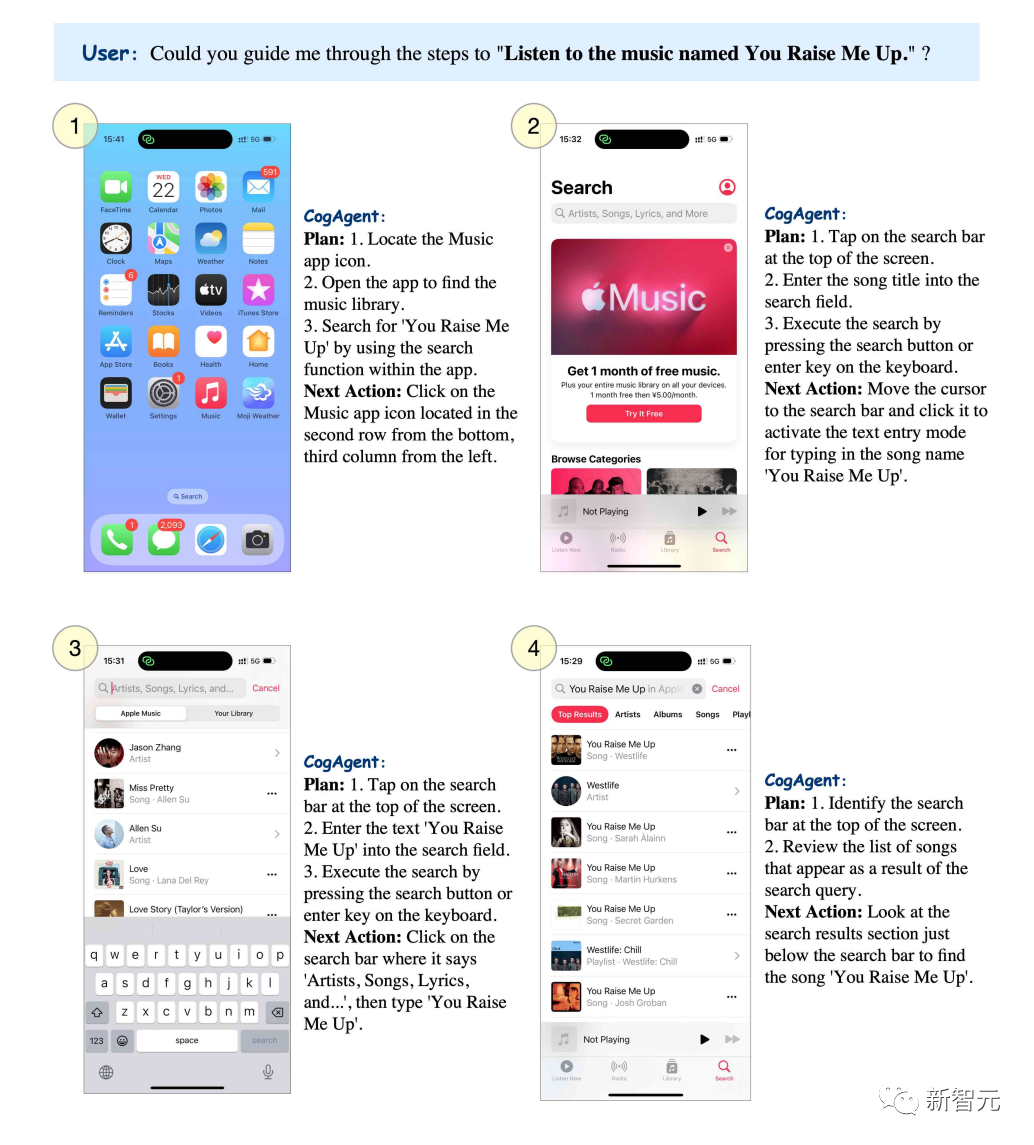 Picture
Picture
CogAgent can accurately describe the scenes in "Genshin Impact" and can also guide you on how to get to the teleportation point.
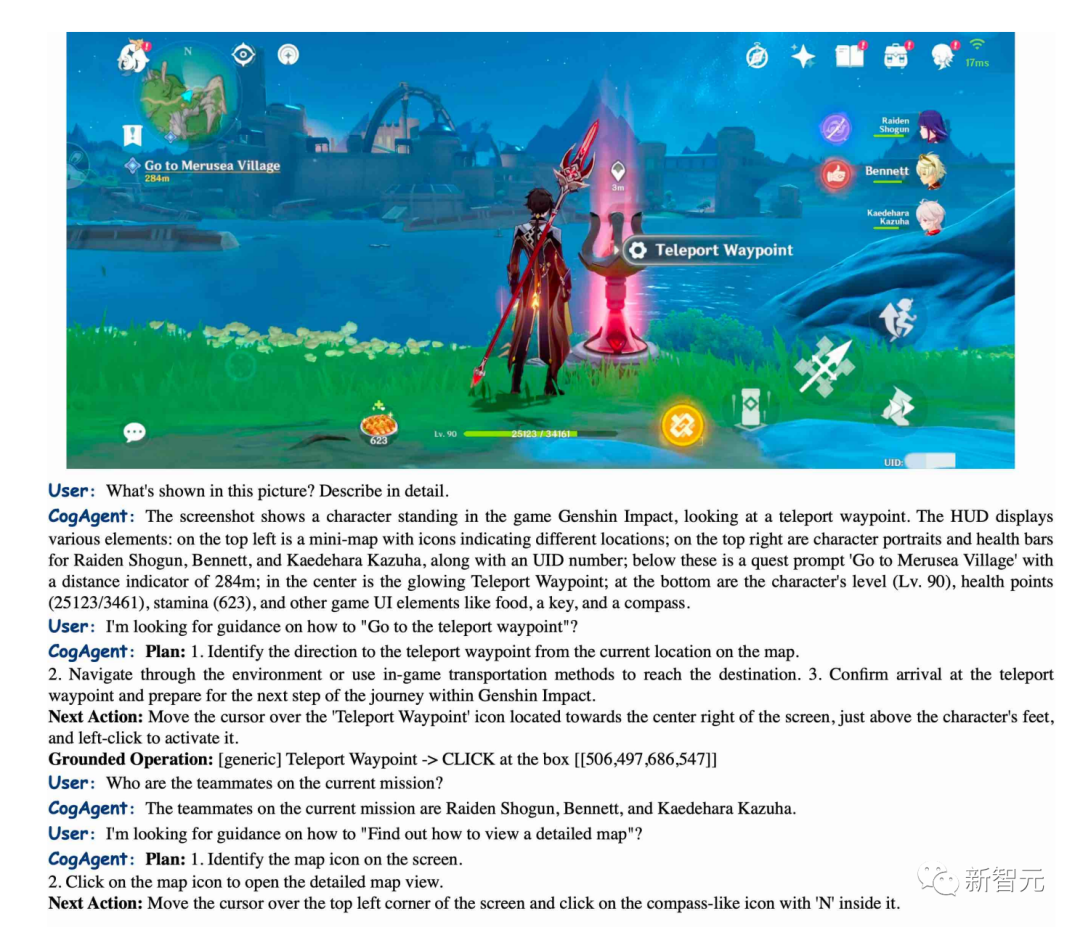 Picture
Picture
BakLLaVA1 is a Mistral 7B base model enhanced with LLaVA 1.5 architecture.
In the first release, the Mistral 7B base model outperformed the Llama 2 13B in multiple benchmarks.
In their repo, you can run BakLLaVA-1. The page is constantly being updated to facilitate fine-tuning and reasoning. (https://github.com/SkunkworksAI/BakLLaVA)
BakLLaVA-1 is completely open source, but was trained on some data, including LLaVA’s corpus, and is therefore not allowed for commercial use.
BakLLaVA 2 uses a larger data set and an updated architecture, surpassing the current LLaVa method. BakLLaVA gets rid of the limitations of BakLLaVA-1 and can be commercially used.
Reference:
https://yousefhosni.medium.com/discover-4-open-source-alternatives-to-gpt-4-vision-82be9519dcc5
The above is the detailed content of Tsinghua University and Zhejiang University lead the explosion of open source visual models, and GPT-4V, LLaVA, CogAgent and other platforms bring revolutionary changes. For more information, please follow other related articles on the PHP Chinese website!
 Which mobile phone models does Hongmeng OS 3.0 support?
Which mobile phone models does Hongmeng OS 3.0 support?
 A memory that can exchange information directly with the CPU is a
A memory that can exchange information directly with the CPU is a
 Dual graphics card notebook
Dual graphics card notebook
 The role of index.html
The role of index.html
 webstorm adjust font size
webstorm adjust font size
 webservice calling method
webservice calling method
 Introduction to carriage return and line feed characters in java
Introduction to carriage return and line feed characters in java
 Learn C# from scratch
Learn C# from scratch
 How to apply for registration of email address
How to apply for registration of email address








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



