

Reborn, I am reborn as MidReal in this life. An AI robot that can help others write "web articles".

# Classic setting who will do not love? I will reluctantly help these users realize their imagination.
##To be honest, in my previous life I saw everything I should and shouldn't see. The following topics are all my favorites.


#I’m not bragging, But if you need me to write, I can indeed create an excellent piece of work for you. If you are not satisfied with the ending, or if you like the character who "died in the middle", or even if the author encounters difficulties during the writing process, you can safely leave it to me and I will write content that satisfies you.

##After listening to MidReal’s self-report, what do you think about it? Does it understand?

Enter /start in the dialog box to start telling your story. Why not give it a try?
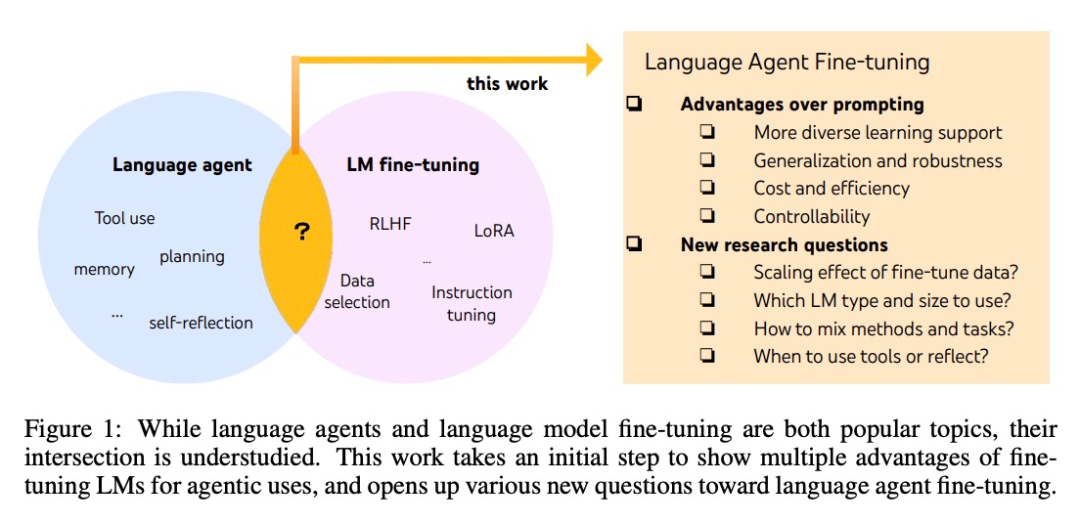
The technology behind MidReal originated from the paper "FireAct: Toward Language Agent Fine-tuning". The author of the paper first tried to use an AI agent to fine-tune a language model and found many advantages, thus proposing a new agent architecture.

Paper link: https://arxiv.org/pdf/2310.05915.pdf

Fine-tuning can be used to solve the above problems. It was also in this article that researchers took the first step towards a more systematic study of language intelligence. They proposed FireAct, which can use the agent "action trajectories" generated by multiple tasks and prompt methods to fine-tune the language model, allowing the model to better adapt to different tasks and situations, and improve its overall performance and applicability.
This research is mainly based on a popular AI Agent method: ReAct. A ReAct task-solving trajectory consists of multiple "think-act-observe" rounds. Specifically, let the AI agent complete a task, in which the language model plays a role similar to the "brain". It provides AI agents with problem-solving "thinking" and structured action instructions, and interacts with different tools based on context, receiving observed feedback in the process.
Based on ReAct, the author proposed FireAct, as shown in Figure 2. FireAct uses the few-sample prompts of a powerful language model to generate diverse ReAct trajectories for fine-tuning Smaller scale language models. Unlike previous similar studies, FireAct is able to mix multiple training tasks and prompting methods, greatly promoting data diversity.
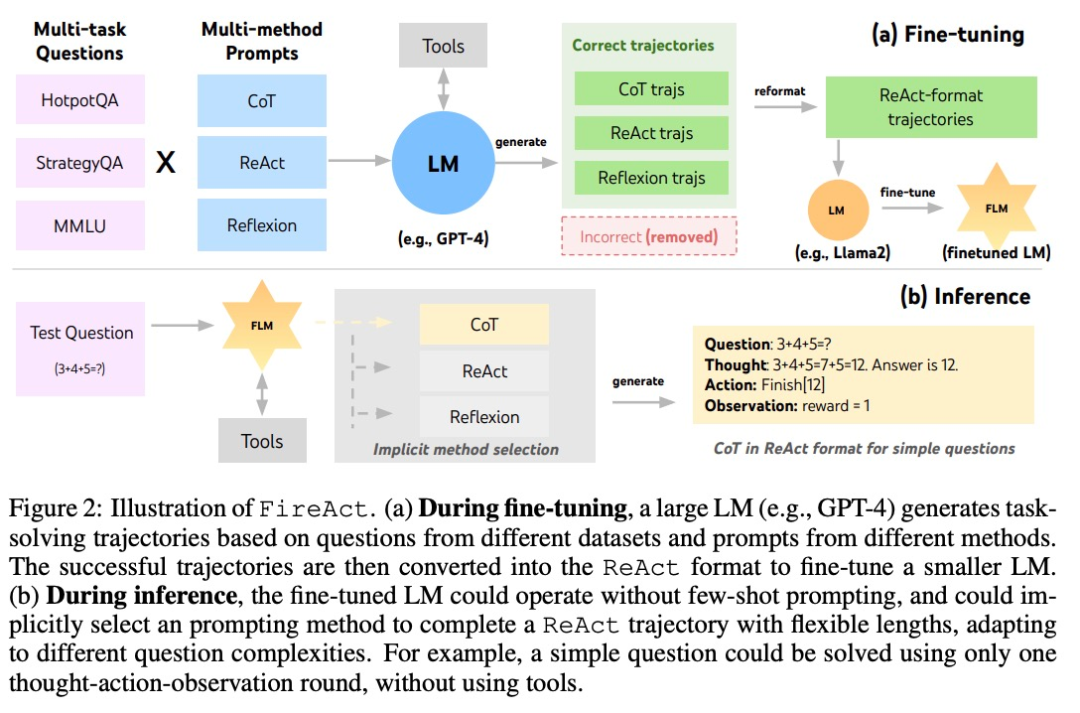
The author also refers to two methods compatible with ReAct:
During the reasoning process, the AI agent under the FireAct framework significantly reduces the number of sample prompt words required, making reasoning more efficient and simpler. It is able to implicitly select the appropriate method based on the complexity of the task. Because FireAct has broader and diverse learning support, it exhibits stronger generalization capabilities and robustness than traditional cue word fine-tuning methods.
HotpotQA data set is a data set widely used in natural language processing research, which contains A series of questions and answers on popular topics. Bamboogle is a search engine optimization (SEO) game where players need to solve a series of puzzles using search engines. StrategyQA is a strategy question answering dataset that contains a variety of questions and answers related to strategy formulation and execution. MMLU is a multi-modal learning data set used to study how to combine multiple perceptual modalities (such as images, speech, etc.) for learning and reasoning.
Tool: The researcher built a Google search tool using SerpAPI1, which will search from the "answer box", "answer fragment", "highlighted word" or "th Returns the first existing entry in a result fragment, ensuring replies are short and relevant. They found that such a simple tool is sufficient to meet basic quality assurance needs for different tasks and improves the ease of use and versatility of fine-tuned models.
The researchers studied three LM series: OpenAI GPT, Llama-2 and CodeLlama.
Fine-tuning method: The researchers used Low-Rank Adaptation (LoRA) in most fine-tuning experiments, but also used full-model fine-tuning in some comparisons. . Taking into account various fundamental factors in language agent fine-tuning, they divided the experiment into three parts, with increasing complexity:
The researchers explored the problem of fine-tuning using data from a single task (HotpotQA) and a single prompt method (ReAct). With this simple and controllable setup, they confirm the various advantages of fine-tuning over hints (performance, efficiency, robustness, generalization) and study the effects of different LMs, data sizes, and fine-tuning methods.
As shown in Table 2, fine-tuning can continuously and significantly improve the prompting effect of HotpotQA EM. While weaker LMs benefit more from fine-tuning (e.g., Llama-2-7B improved by 77%), even a powerful LM like GPT-3.5 can improve performance by 25% with fine-tuning, which is clearly Demonstrates the benefits of learning from more samples. Compared to the strong cueing baseline in Table 1, we found that fine-tuned Llama-2-13B outperformed all GPT-3.5 cueing methods. This suggests that fine-tuning a small open source LM may be more effective than prompting a more powerful commercial LM.
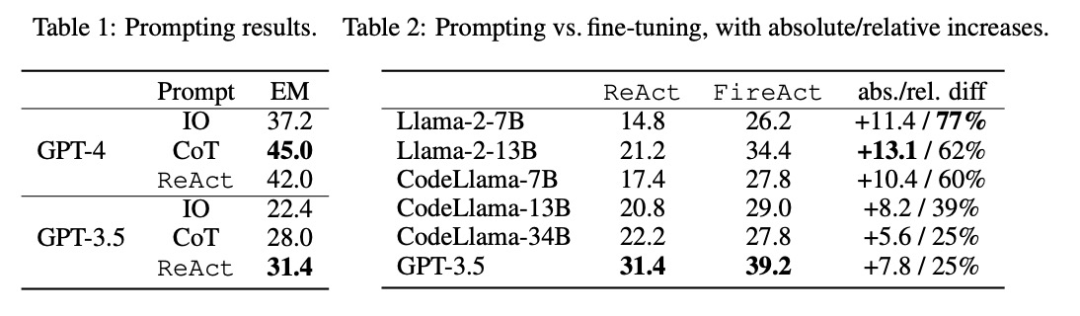
In the agent reasoning process, fine-tuning is cheaper and faster. Since fine-tuning LM does not require a small number of contextual examples, its inference is more efficient. For example, the first part of Table 3 compares the cost of fine-tuned inference to shiyongtishideGPT-3.5 inference and finds a 70% reduction in inference time and a reduction in overall inference cost.

The researchers considered a simplified and harmless setup, that is, in the search API, there are 50 % probability of returning "None" or a random search response, and asking the language agent whether it can still answer the question robustly. According to the data in the second part of Table 3, setting to "None" is more challenging, causing ReAct EM to drop by 33.8%, while FireAct EM only dropped by 14.2%. These preliminary results indicate that diverse learning support is important to improve robustness.
The third part of Table 3 shows the EM results of fine-tuned and using hinted GPT-3.5 on Bamboogle. While both GPT-3.5 fine-tuned with HotpotQA or using hints generalizes reasonably well to Bamboogle, the former (44.0 EM) still outperforms the latter (40.8 EM), indicating that fine-tuning has a generalization advantage.
The author integrated CoT and Reflexion with ReAct and tested the Performance of fine-tuning using multiple methods on the task (HotpotQA). Comparing the scores of FireAct and existing methods in each data set, they found the following:
First, the researchers fine-tuned the agent through a variety of methods to improve its flexibility . In the fifth figure, in addition to the quantitative results, the researchers also show two example problems to illustrate the benefits of multi-method fine-tuning. The first question was relatively simple, but the agent fine-tuned using only ReAct searched for an overly complex query, causing distraction and providing incorrect answers. In contrast, the agent fine-tuned using both CoT and ReAct chose to rely on internal knowledge and confidently completed the task within one round. The second problem is more challenging, and the agent fine-tuned using only ReAct failed to find useful information. In contrast, the agent that used both Reflexion and ReAct fine-tuning reflected when it encountered a dilemma and changed its search strategy, eventually getting the correct answer. The ability to choose flexible solutions to deal with different problems is a key advantage of FireAct over other fine-tuning methods.

Secondly, using multiple methods to fine-tune different language models will have different impacts. As shown in Table 4, using a combination of multiple agents for fine-tuning does not always lead to improvements, and the optimal combination of methods depends on the underlying language model. For example, ReAct CoT outperforms ReAct for GPT-3.5 and Llama-2 models, but not for CodeLlama model. For CodeLlama7/13B, ReAct CoT Reflexion had the worst results, but CodeLlama-34B achieved the best results. These results suggest that further research into the interaction between underlying language models and fine-tuning data is needed.
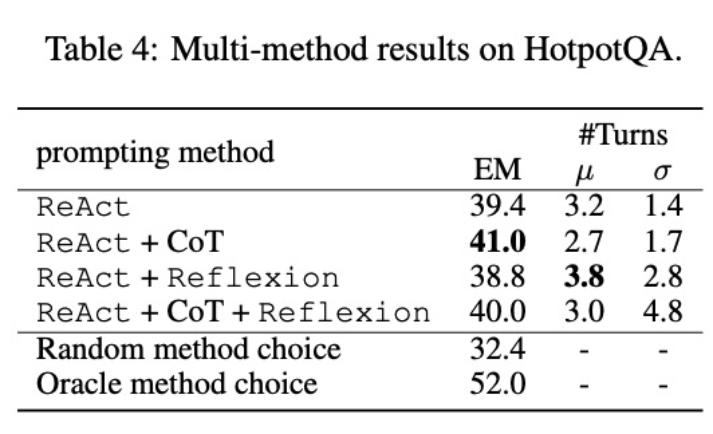
In order to further understand whether an agent that combines multiple methods can choose the appropriate solution according to the task, the researchers Scores were calculated for randomly selected methods during inference. This score (32.4) is much lower than all agents that combined multiple methods, indicating that choosing a solution is not an easy task. However, the best solution per instance also scored only 52.0, indicating that there is still room for improvement in prompting method selection.
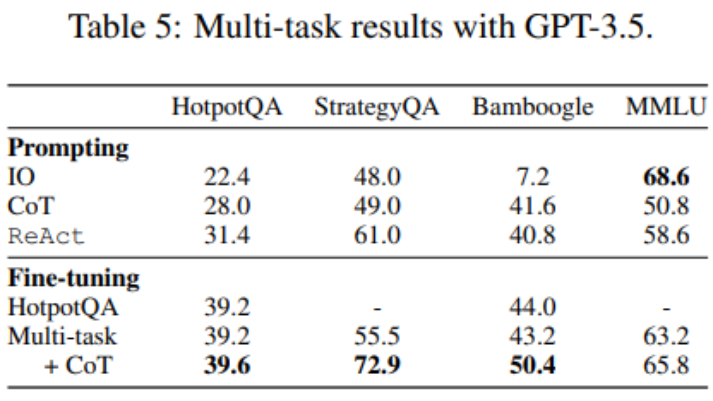
Up to this point, fine-tuning has only used HotpotQA data, but empirical research on LM fine-tuning shows that there are benefits to mixing different tasks. The researchers fine-tuned GPT-3.5 using mixed training data from three datasets: HotpotQA (500 ReAct samples, 277 CoT samples), StrategyQA (388 ReAct samples, 380 CoT samples), and MMLU (456 ReAct samples) samples, 469 CoT samples).
As shown in Table 5, after adding StrategyQA/MMLU data, the performance of HotpotQA/Bamboogle remains almost unchanged. On the one hand, the StrategyQA/MMLU tracks contain very different questions and tool usage strategies, making migration difficult. On the other hand, despite the change in distribution, adding StrategyQA/MMLU did not affect the performance of HotpotQA/Bamboogle, indicating that fine-tuning a multi-task agent to replace multiple single-task agents is a possible future direction. When the researchers switched from multi-task, single-method fine-tuning to multi-task, multi-method fine-tuning, they found performance improvements across all tasks, again clarifying the value of multi-method agent fine-tuning.
For more technical details, please read the original article.
Reference link:
The above is the detailed content of AI is reborn: regaining hegemony in the online literary world. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 Excel diagonal header is divided into two
Excel diagonal header is divided into two
 Introduction to the meaning of cloud download windows
Introduction to the meaning of cloud download windows
 nozoomer
nozoomer
 Usage of fclose function
Usage of fclose function
 How to center div in css
How to center div in css
 Detailed explanation of nginx configuration
Detailed explanation of nginx configuration
 exe virus solution
exe virus solution








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



