

After the multi-modal large model integrates the detection and segmentation module, image cutout becomes easier!
Our model can quickly label the objects you are looking for through natural language descriptions and provide text explanations to allow you to easily complete the task.
The new multi-modal large model developed by the NExT Laboratory of the National University of Singapore and Liu Zhiyuan's team at Tsinghua University provides us with strong support. This model has been carefully crafted to provide players with comprehensive help and guidance during the puzzle-solving process. It combines information from multiple modalities to present players with new puzzle-solving methods and strategies. The application of this model will benefit players

With the launch of GPT-4v, the multimodal field has ushered in a series of new models, such as LLaVA, BLIP-2, etc. wait. The emergence of these models has made great contributions in improving the performance and effectiveness of multi-modal tasks.
In order to further improve the regional understanding capabilities of multi-modal large models, the research team developed a multi-modal model called NExT-Chat. This model has the ability to conduct dialogue, detection, and segmentation simultaneously.
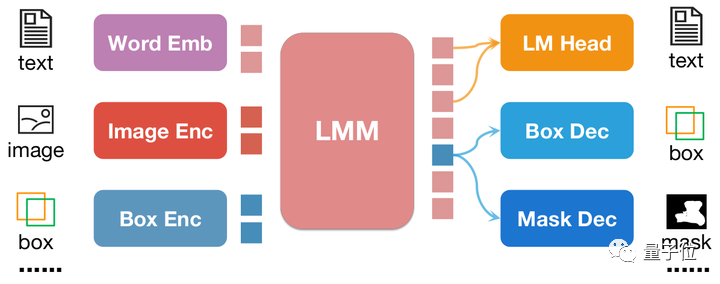
The biggest highlight of NExT-Chat is the ability to introduce positional input and output into its multi-modal model. This feature enables NExT-Chat to more accurately understand and respond to user needs during interaction. Through location input, NExT-Chat can provide relevant information and suggestions based on the user's geographical location, thereby improving the user experience. Through location output, NExT-Chat can convey relevant information about specific geographical locations to users to help them better
Among them, the location input capability refers to answering questions based on the specified area, while the location output capability is Specifies the location of the object mentioned in the conversation. These two abilities are very important in puzzle games.

Even complex positioning problems can be solved:

In addition to object positioning, NExT-Chat can also Describe the image or a part of it:
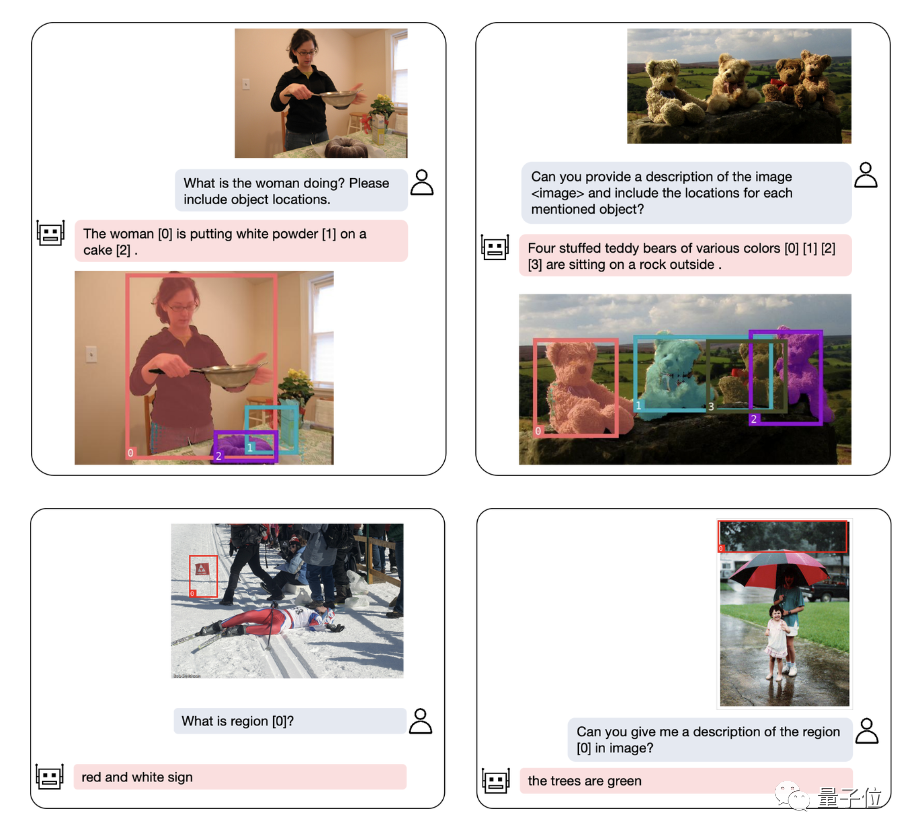
After analyzing the content of the image, NExT-Chat can use the obtained information to make inferences:

In order to accurately evaluate the performance of NExT-Chat, the research team conducted tests on multiple task data sets.
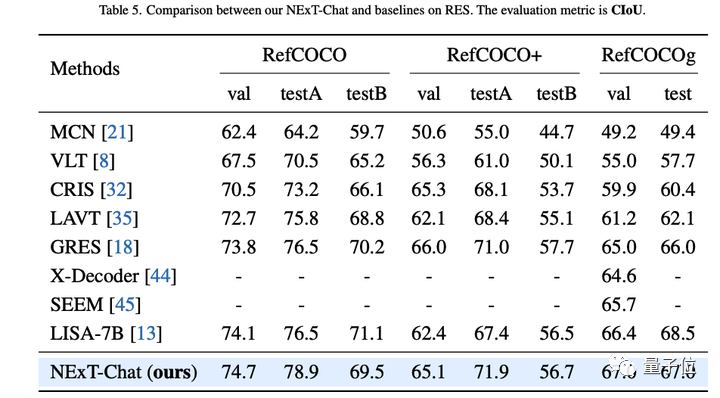
The author first showed the experimental results of NExT-Chat on the referential expression segmentation (RES) task.
Although only using a very small amount of segmentation data, NExT-Chat has demonstrated good referential segmentation capabilities, even defeating a series of supervised models (such as MCN, VLT, etc.) and using 5 times LISA method for segmentation mask annotation above.
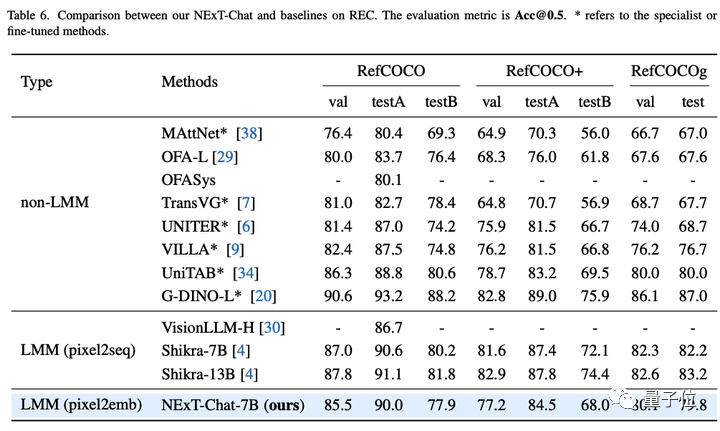
Then, the research team showed the experimental results of NExT-Chat on the REC task.
As shown in the table below, NExT-Chat can achieve better results than a series of supervised methods (such as UNITER).
An interesting finding is that NExT-Chat is slightly less effective than Shikra, which uses similar box training data.
The author speculates that this is due to the fact that LM loss and detection loss in the pix2emb method are more difficult to balance, and Shikra is closer to the pre-training form of the existing plain text large model.
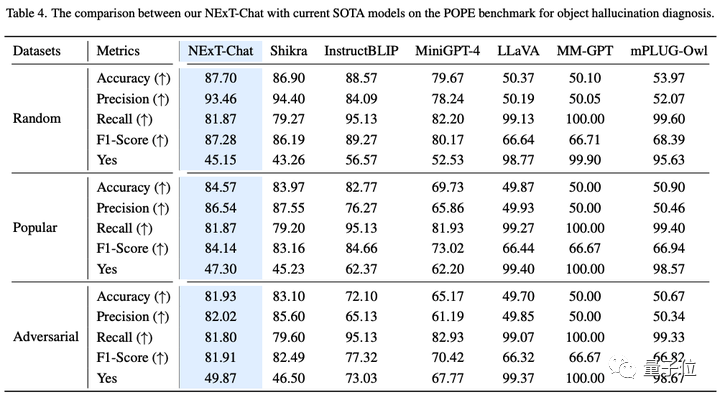
On the image illusion task, as shown in Table 3, NExT-Chat can perform on Random and Popular data achieve the best accuracy on the set.
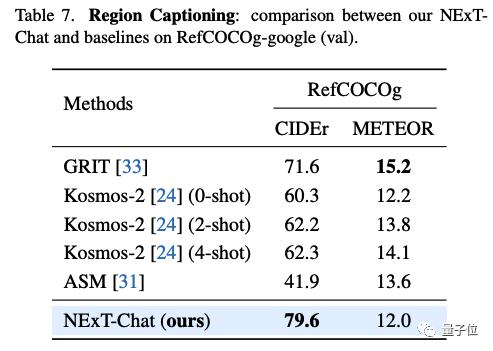
In the area description task, NExT-Chat can also achieve the best CIDEr performance, and beat Kosmos- in the 4-shot case in this indicator. 2.
So, what methods are used behind NExT-Chat?
The traditional model mainly performs LLM-related position modeling through pix2seq.
For example, Kosmos-2 divides the image into 32x32 blocks and uses the id of each block to represent the coordinates of the point; Shikra converts the coordinates of the object frame into plain text so that LLM can understand the coordinates. .
However, the model output using the pix2seq method is mainly limited to simple formats such as boxes and points, and it is difficult to generalize to other denser position representation formats, such as segmentation mask.
In order to solve this problem, this article proposes a new embedding-based position modeling method pix2emb.
Different from pix2seq, all position information of pix2emb is encoded and decoded through the corresponding encoder and decoder, rather than relying on the text prediction header of LLM itself.
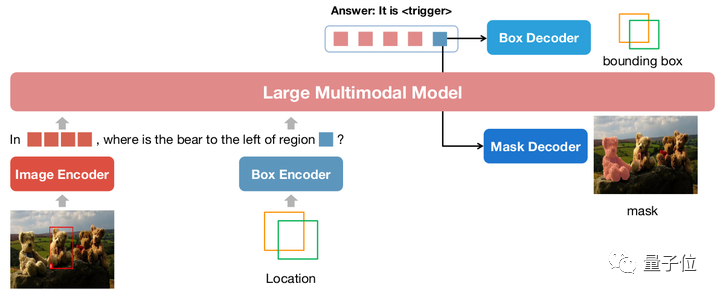
As shown in the figure above, the position input is encoded into position embedding by the corresponding encoder, and the output position embedding is passed through Box Decoder and Mask Decoder convert to boxes and masks.
This brings two benefits:
By combining pix2seq with pix2emb, the author trained a new NExT-Chat model.
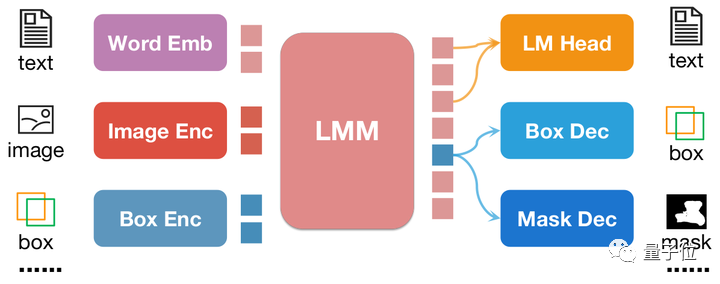
NExT-Chat adopts the LLaVA architecture as a whole, that is, through Image Encoder To encode image information and input it into LLM for understanding, and on this basis, the corresponding Box Encoder and the Decoder for two position outputs are added.
In order to solve the problem of LLM not knowing when to use the language's LM head or the position decoder, NExT-Chat additionally introduces a new token type to identify position information.
If the model outputs, the embedding of the token will be sent to the corresponding position decoder for decoding instead of the language decoder.
In addition, in order to maintain the consistency of position information in the input stage and output stage, NExT-Chat introduces an additional alignment constraint:
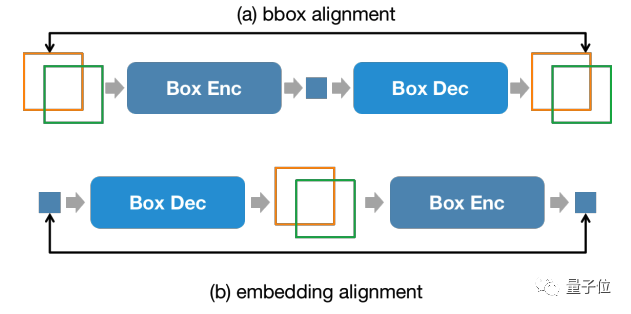
As shown in the figure above, the box and position embedding will be combined through the decoder, encoder or decoder-encoder respectively, and are required not to change before and after.
The author found that this method can greatly promote the convergence of position input capabilities.
The model training of NExT-Chat mainly includes three stages:
The advantage of such a training process is that the detection frame data is rich and the training overhead is smaller.
NExT-Chat trains basic position modeling capabilities on abundant detection frame data, and can then quickly expand to segmentation tasks that are more difficult and have scarcer annotations.
The above is the detailed content of Large-scale models can already annotate images with just a simple conversation! Research results from Tsinghua & NUS. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



