

Exploration of Large Model Applications—Enterprise Knowledge Steward


1. Background and challenges of traditional knowledge management
1. The necessity of enterprise knowledge management
In modern enterprises, knowledge Management is a crucial link. It can help enterprises effectively organize and utilize internal and external knowledge resources, thereby improving the efficiency and competitiveness of enterprises. In order to better manage knowledge, many companies have introduced the concept of knowledge stewards. Knowledge steward is a role or system specifically responsible for managing and disseminating enterprise knowledge. Through knowledge stewards, enterprises can better collect and organize
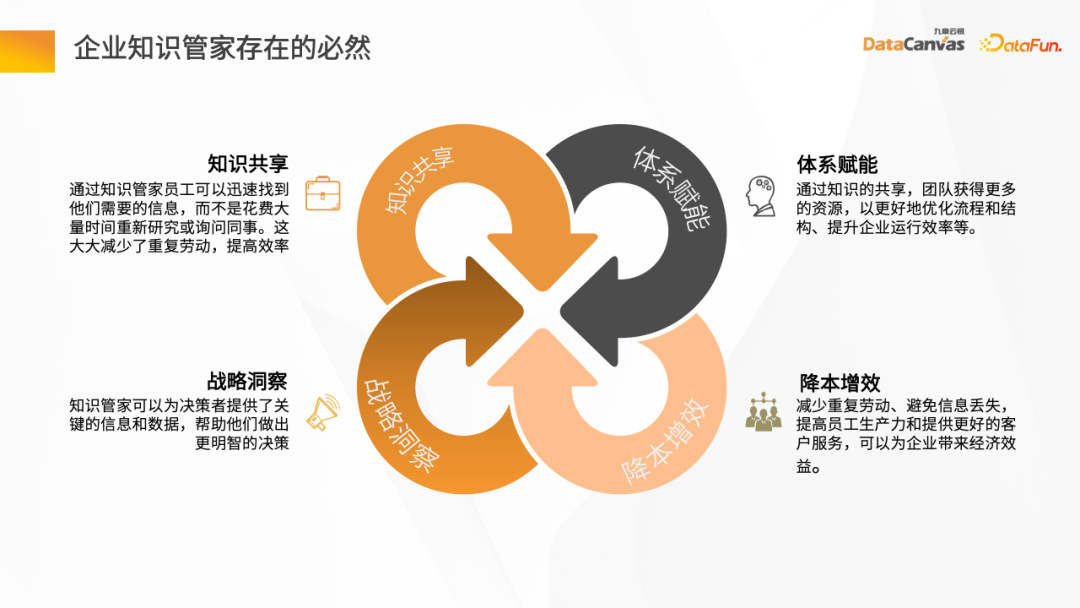
##With the rapid development and Knowledge is growing explosively, and companies are faced with the challenge of sharing knowledge. How to effectively transfer and share knowledge within an enterprise has become an important issue. Through knowledge sharing, companies can not only improve work efficiency, but also avoid duplication of work.
Another way is to adopt a knowledge sharing model to establish a mechanism that can empower enterprises, thereby better optimizing processes and results, and improving enterprise operating efficiency. This model allows employees within the enterprise to share their knowledge and experience so that everyone on the team can benefit. By sharing knowledge, companies can avoid duplication of effort, reduce errors and mistakes, and be better able to respond to challenges and changes. This
In addition, as a knowledge steward, it can also provide key information and data to decision-makers to help them make more informed decisions. Knowledge Butler has powerful information retrieval and analysis capabilities, and can extract useful information from massive data, integrate and analyze it. This information and data can include market trends, competitor analysis, consumer insights, technology development, etc.
In addition, a very key factor is to reduce the workload of corporate employees and prevent information loss, and improve employee work efficiency and customer service levels, thereby achieving the goals of reducing costs and improving efficiency.
2. Enterprise knowledge management challengesBefore there was a large model, the logic of building a knowledge steward was quite complicated. Usually, we use the concept of knowledge base to build a knowledge base with the help of enterprise knowledge graph or internal data of the enterprise. However, there are many challenges faced during this construction process. First, the construction of a knowledge base requires a lot of manpower and time investment. Collecting, organizing and summarizing knowledge and information within an enterprise is a tedious and time-consuming task. A professional team is needed to process and manage this data and ensure its
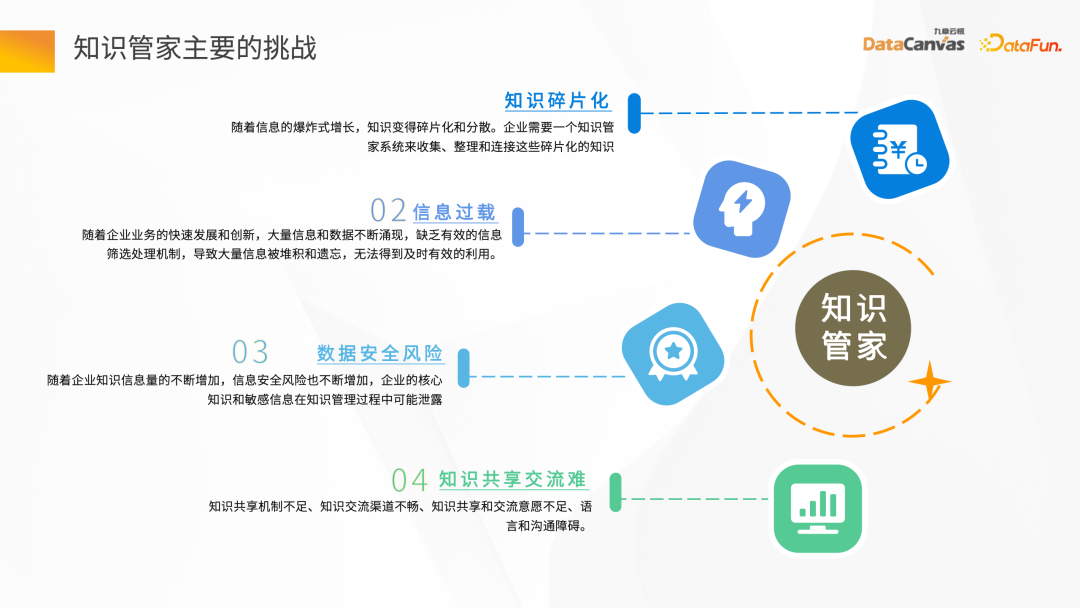
- Knowledge fragmentation
Knowledge fragmentation is mainly reflected in two aspects. One aspect is that the enterprise's data is very scattered. For example, the data of the OA system has different departments and different teams. On the other hand, these data are basically provided in unstructured forms, such as Word, PDF, pictures, videos, etc. In the process of building knowledge stewards, how to quickly centralize the fragmented information is the first challenge.
- Information overload
- Data security risks
- Difficulty in knowledge sharing and communication
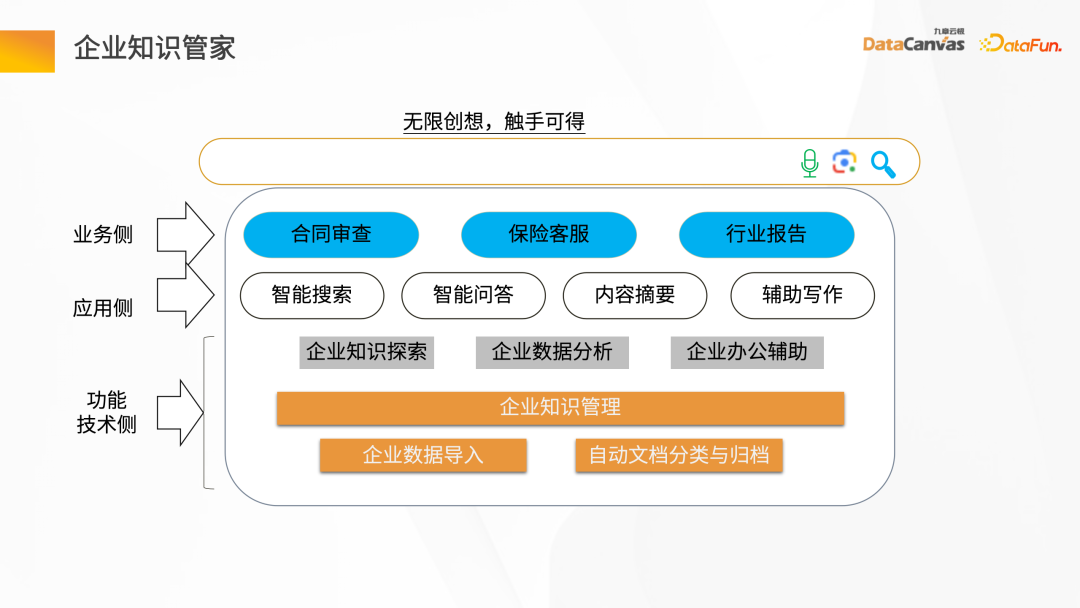
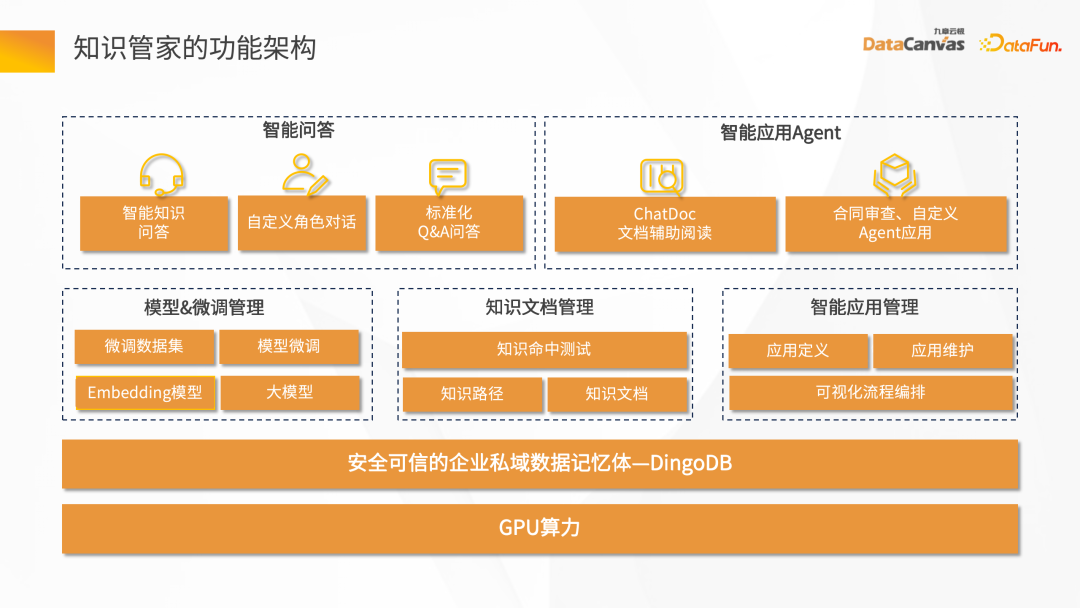
Enterprise knowledge steward is similar to a person’s brain to assist in the storage and understanding of the entire knowledge and create knowledge. Enterprise knowledge stewards are generally divided into three levels: the first level is the functional and technical needs, mainly responsible for the management of enterprise knowledge, including enterprise Data import, automatic classification and archiving of documents, and other basic functional requirements; the middle layer is the requirement of the application side, including providing some intelligent question and answer, intelligent search, summary generation, auxiliary writing and other functions; the upper layer is the requirement of the business side , including contract review, insurance customer service, and industry report generation. There are generally three modes of interfaces presented by Knowledge Butler: the first interface is similar to a text box, providing knowledge exploration and analysis; the other is to use API tokens to Intelligent Agents involved in different application scenarios are published as API Tokens to integrate with the enterprise's business system; the third method is intelligent Agent, which explores and analyzes knowledge through conversation mode. Enterprise knowledge steward is mainly responsible for enterprise-specific knowledge management and creation, including the following business scenarios: Combined with the company’s own private domain data, through After vectorization, it is stored in a vector database, and uses the question and answer mode to create intelligent question and answer scenarios. Through these scenarios, many more specific business needs can be derived. ## Do some exploration and analysis through documents, such as To explore the paper, you can ask questions about the content of the paper, and you can also conduct independent analysis of the document, providing segmented preview, contextual retrieval, summary summary and other capabilities of the entire document. Combined with the private domain data of different roles within the enterprise, Coupled with the prompt word mode, it provides the design of some customized scenarios, such as assisted writing of documents, intelligent meeting minutes, etc. adopts the human-computer dialogue mode to conduct various audits of the enterprise Review the contract information on some key terms to see if the corresponding information is accurate. The main functions of the Enterprise Knowledge Butler product include: Functional architecture of Knowledge Butler: The bottom is the GPU calculation Power includes two categories, one is reasoning computing power, and the other is fine-tuning computing power. The middle layer is a secure and trustworthy enterprise private domain data memory - DingoDB multi-mode vector database. The next layer is the functional points of the entire technical layer, including model fine-tuning management, knowledge document management, and intelligent application management. The top one is for business scenario needs. In intelligent Q&A, you can customize some dialogues of roles, standard QA Q&A, and agents for intelligent applications, document-based auxiliary reading, contract review, and insurance. personal assistant. ##3. Exploration of core technology of knowledge steward1. Knowledge steward construction process
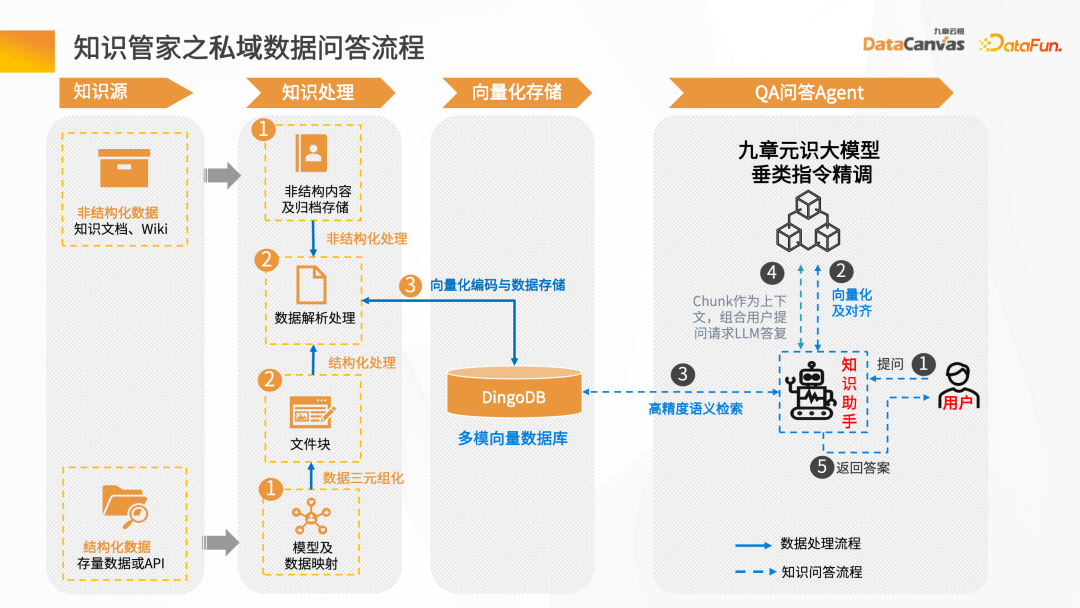
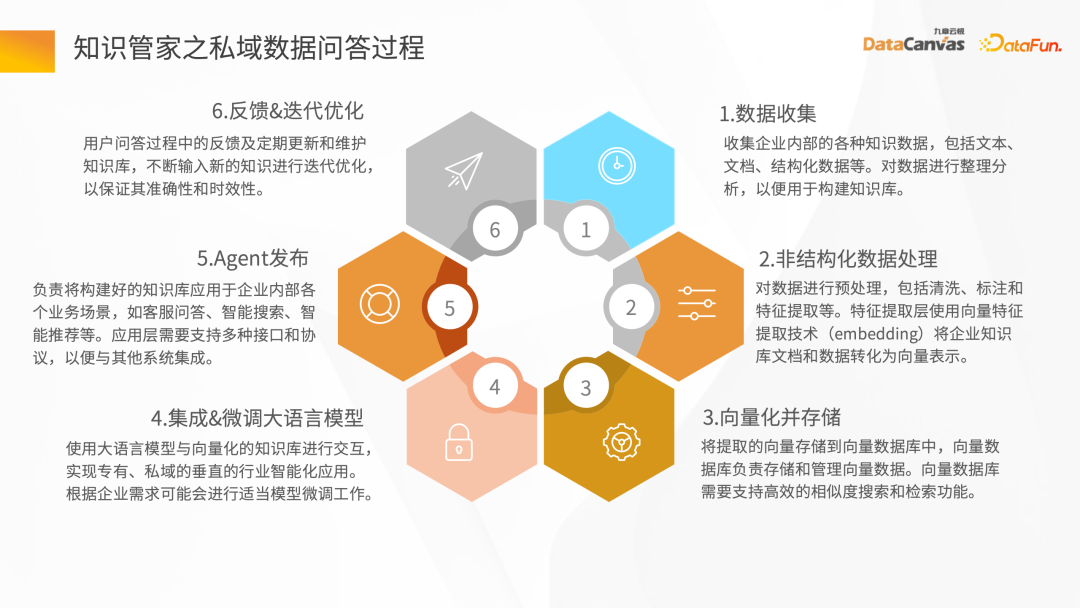
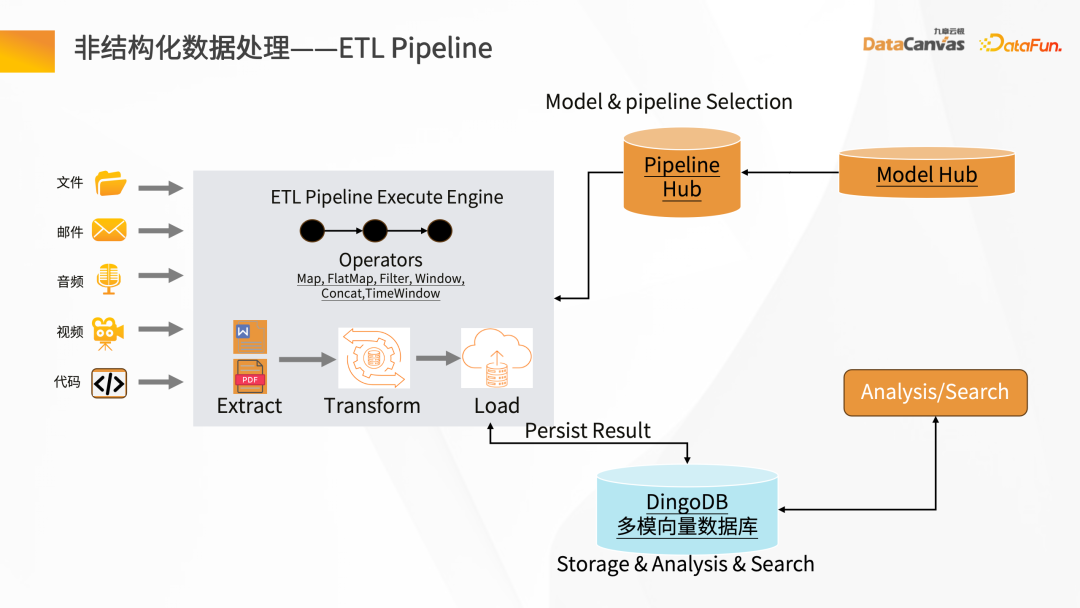
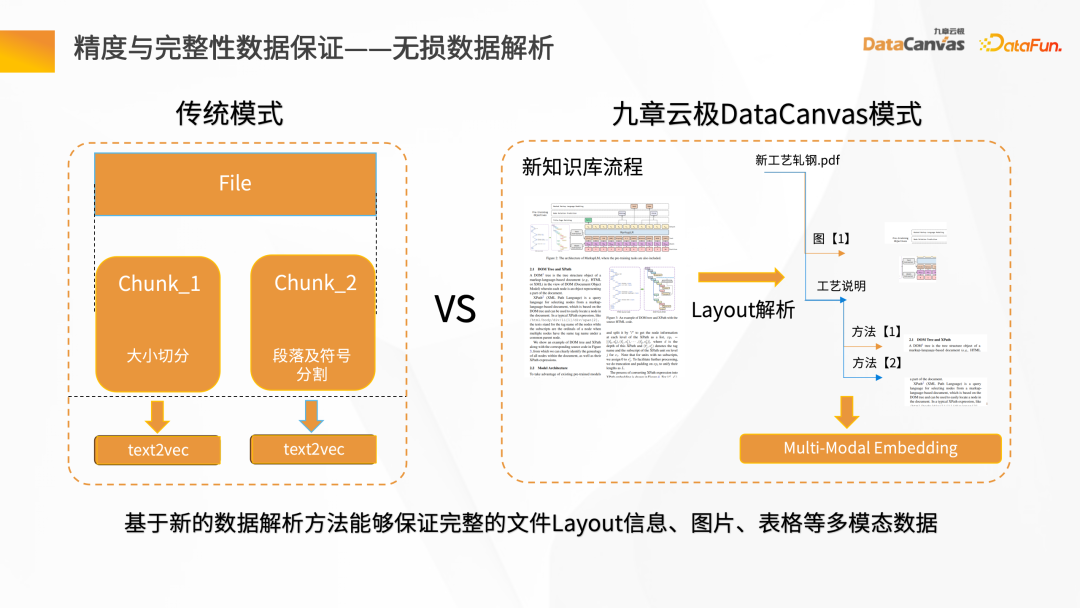
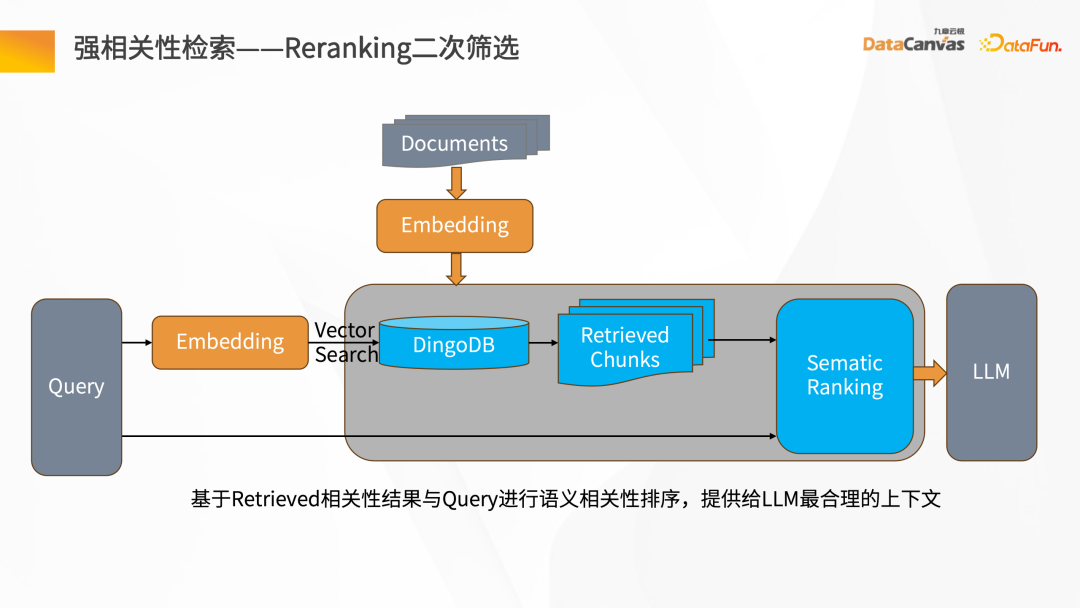
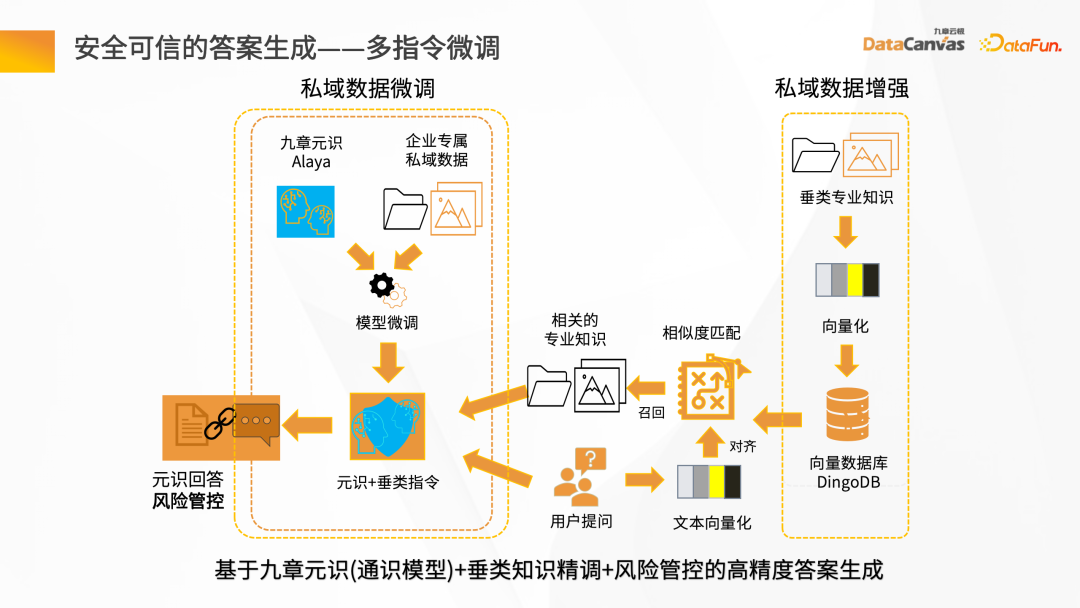
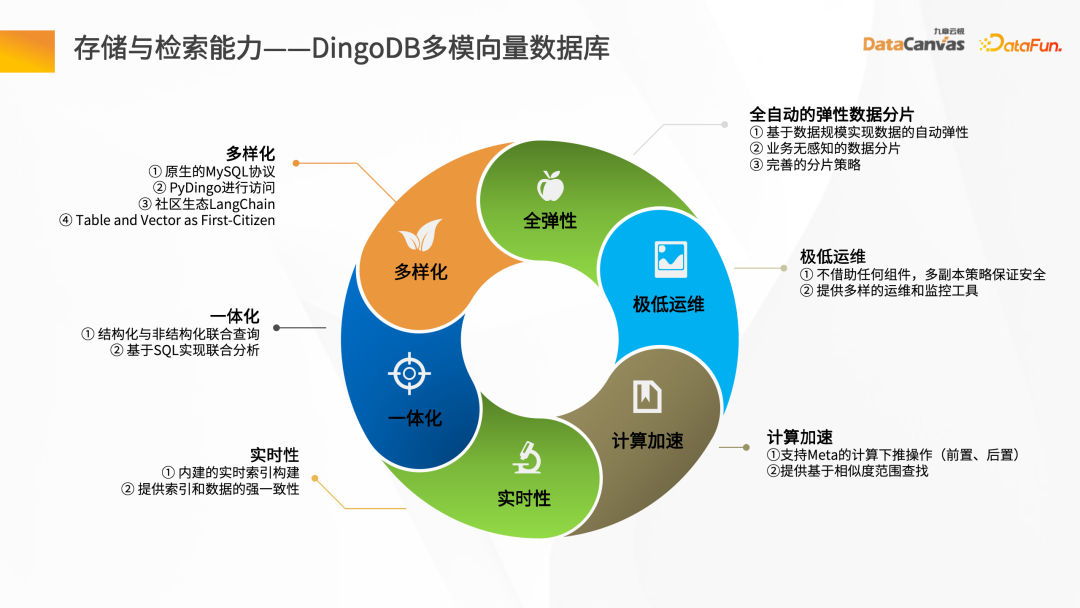
Next, we will introduce the entire knowledge steward construction process through the intelligent question and answer scenario. First of all, there needs to be a data source. There may be structured and unstructured data. Generally speaking, the construction of knowledge base is based on unstructured data. Mainly, such as Word, PDF, Excel, as well as enterprise systems, Jira, knowledge management platforms, etc. These data go through the knowledge processing link and are converted into vectors and stored in the database. You need to load the document first, then give the layout information or structure information of the document, do document vector analysis to generate file blocks, and then call the corresponding Embedding model based on the file blocks to convert them into vectors and store the vectors. The process of intelligent question and answer interaction: after the user raises a question, first use the intelligent assistant to vectorize the question, and then go to the database to perform semantic retrieval to obtain the context of the article with similar semantics. By combining the context with the prompt words and reasoning through the large model, the answer is finally returned. The overall process is a process of continuous iteration and feedback optimization. Only in this way can we obtain the exclusive intelligent expert role based on the enterprise's private domain data. Unstructured data ETL processing requires the help of some tools. Knowledge Manager provides some special operators from the technical model. These operators can clean the entire Map, Filter, and Window-based changes, and convert data through the entire ETL Pipeline. By parsing various files (such as PDF parsers), and then passing through the Hub Operators of different application scenarios corresponding to the middle layer, the Pipeline Hub can be quickly constructed, and then After the data is cleaned and converted, it is Embedding and finally stored in the vector database. To get a good To improve the model debugging effect, it is necessary to ensure accurate and complete data and have good data processing quality. Constructing a traditional data retrieval is very simple, but the actual knowledge is more complicated. In addition to the information in the text itself, there are also pictures and table data , paragraph information, etc. In this regard, Jiuzhang Yunji DataCanvas provides Layout parsing mode, which can realize the full storage of multi-modal data such as Layout information, tables, and pictures, and comprehensively improves the quality of the data parsing process. After the document is vectorized , after saving to the DingoDB multi-modal vector database, retrieval is performed through Query. The retrieval results will include the results of the retrieval content itself, as well as the correlation results. At this time, it is necessary to perform secondary screening of Reranking on the Chunks recalled by the retrieval. #During Reranking secondary screening, the Retrieval Chunk and the corresponding Query must be related to each other. The analysis includes finding the closest semantic match, and then re-pushing the retrieval Chunk after secondary screening to the large language model. In order to ensure the security and credibility of the answer generation process, Jiuzhang Yunji DataCanvas is based on the general large speech model, limits the prompt words for the recalled data, and combines the enterprise's private domain data with the large model Fine-tuning vertical knowledge and adding a wind direction control mechanism ensure high accuracy in answer generation. DingoDB can provide a variety of The standardized API supports data query through SQL and Python toolkits, and also provides an integrated way to implement structured and unstructured joint queries. For real-time scenarios, DingoDB provides the ability to query in real-time by writing in real-time, and can perform real-time retrieval while importing data. ##DingoDB also provides calculation acceleration capabilities and supports pre- and post-filtering of Meta. , and range search based on similarity. DingoDB also provides multi-copy tools that can perform partial migration and data migration. It also provides diversified operation and maintenance and monitoring tools to reduce operation and maintenance costs. DingoDB can also provide automatic elastic sharding capabilities, which can dynamically balance data to different machines to achieve load balancing on each node. In enterprise private domain data For general scenarios, fine-tuning is needed to build a large language model exclusive to the enterprise in a certain scenario. The knowledge manager summarizes the pain points in the entire fine-tuning process and provides a tool-based approach in the product. Data on all problems can be obtained by uploading documents. After having the data, fine-tuning can be performed directly on the interface by configuring parameters. At the same time, the product also provides some fine-tuning data indicators to evaluate the results of fine-tuning. Traditional large model applications are often complex to build. Knowledge Butler built its own large model IDE based on Jiuzhang Yunji DataCanvas's own FS capabilities, which can provide a wealth of components and tools, and use a concise application construction method to build The template is published as an agent for intelligent applications. ##4. Summary and Outlook
Knowledge Manager is AIFS based on Jiuzhang Yunji DataCanvas, providing a complete set of GPU computing power and model scheduling from bare metal to above, and realizing model fine-tuning. Pipeline mode. It uses the general language model and the company's private domain data to perform combination and fine-tuning to form the company's own large language model. Based on the scalability of the large language model, combined with the DingoDB multi-modal vector database, it can realize search Q&A, summary generation and other applications in the enterprise, and carry out enterprise knowledge management. 2. Knowledge steward solution
1. What is enterprise knowledge steward
2. Enterprise knowledge steward solution

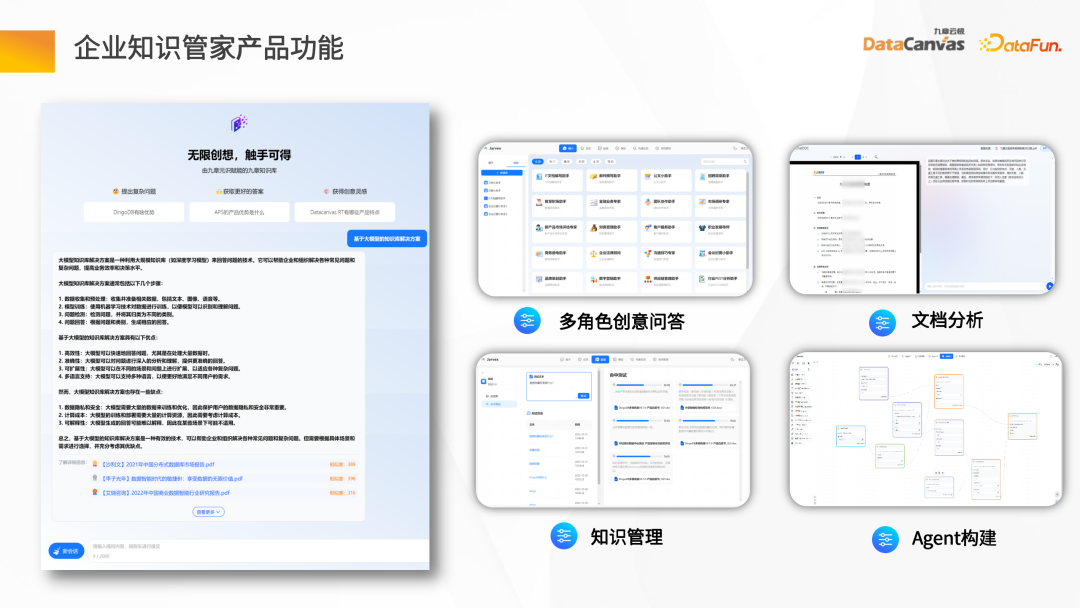

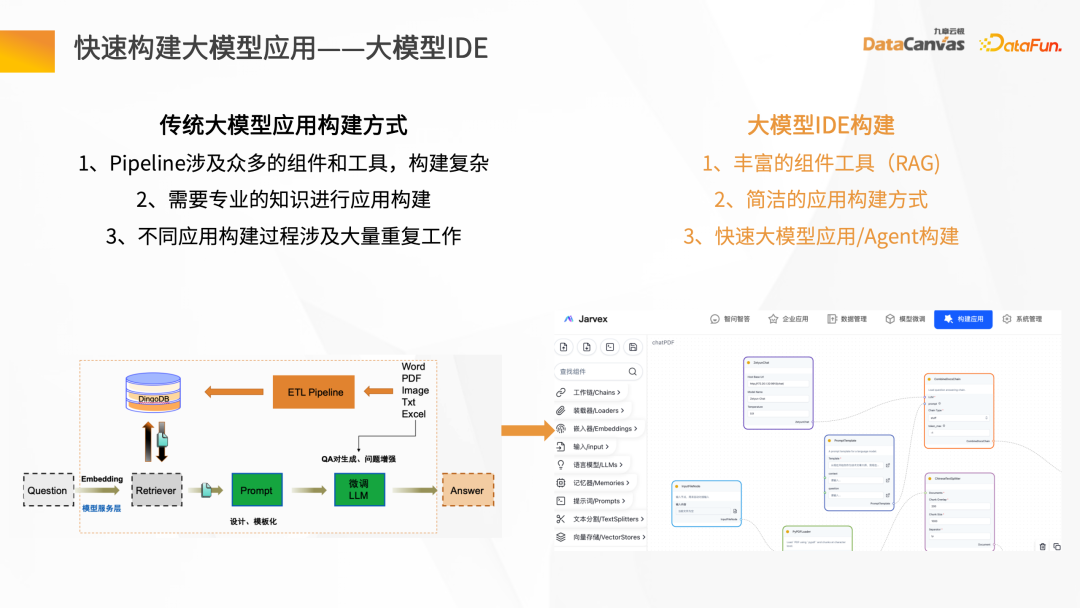
1. Knowledge Summary of the Butler Solution
The technical highlights of Knowledge Butler mainly include the following six aspects: high-precision retrieval, convenient ETL Pipeline, high availability and scalability, security compliance, intelligent data fusion, and rich scenarios . 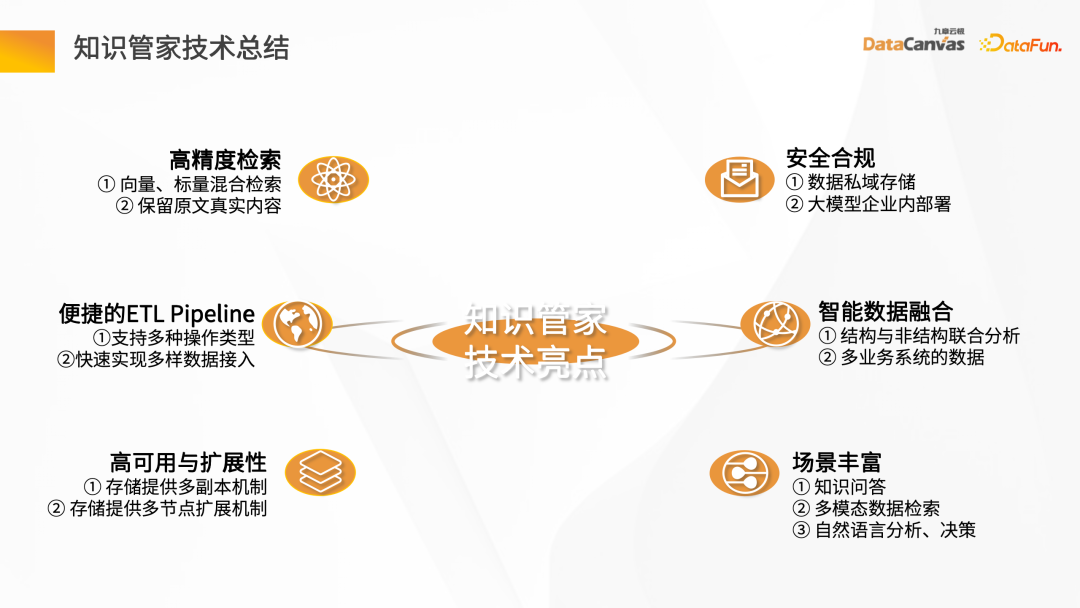
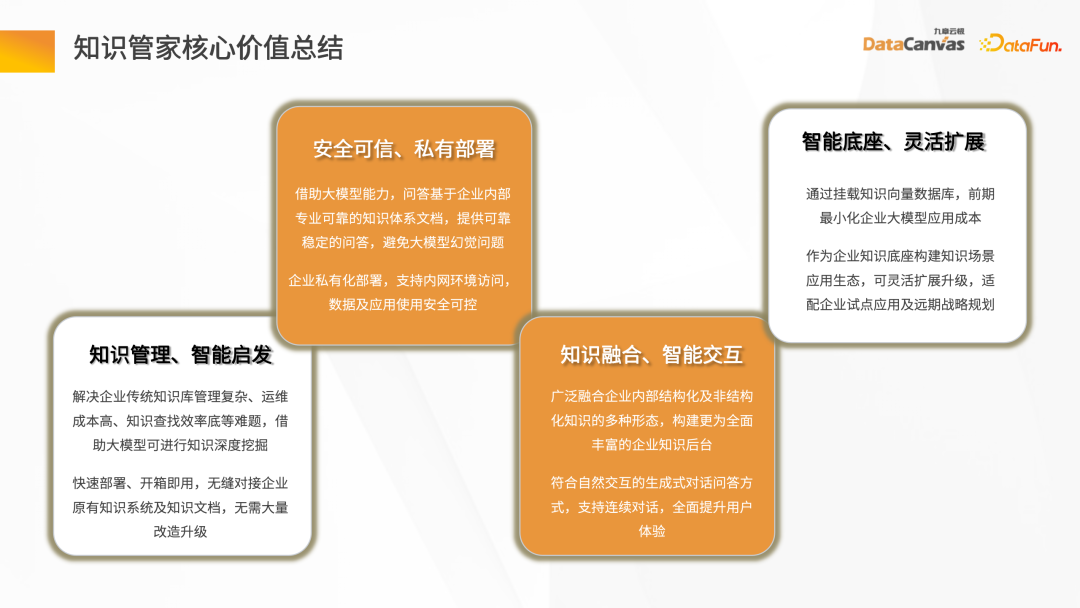
2. Future Outlook
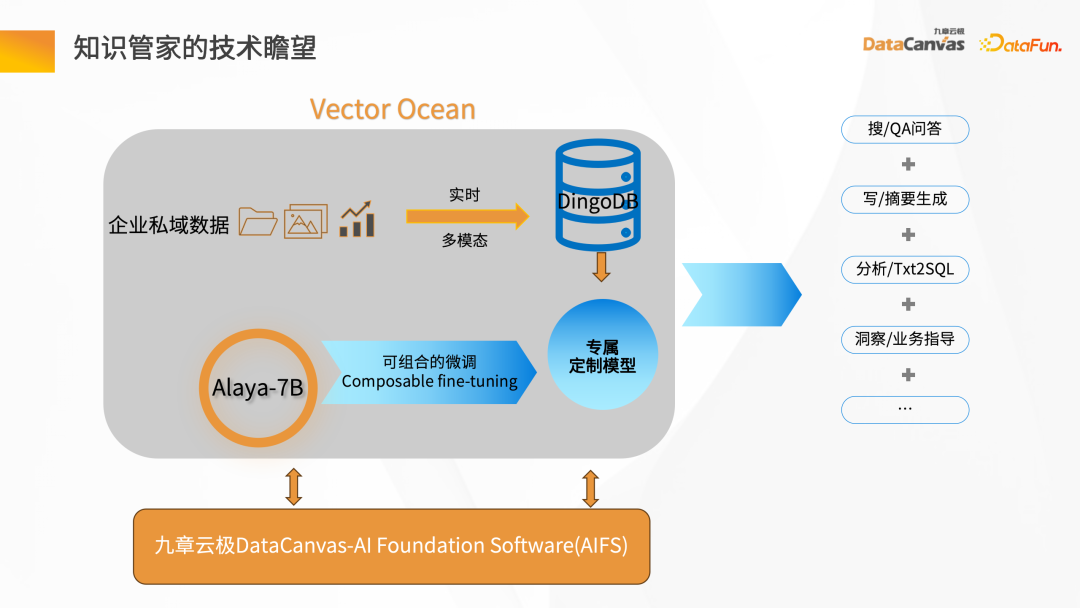
The above is the detailed content of Exploration of Large Model Applications—Enterprise Knowledge Steward. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
37
110
52
37
110

 Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
On May 30, Tencent announced a comprehensive upgrade of its Hunyuan model. The App "Tencent Yuanbao" based on the Hunyuan model was officially launched and can be downloaded from Apple and Android app stores. Compared with the Hunyuan applet version in the previous testing stage, Tencent Yuanbao provides core capabilities such as AI search, AI summary, and AI writing for work efficiency scenarios; for daily life scenarios, Yuanbao's gameplay is also richer and provides multiple features. AI application, and new gameplay methods such as creating personal agents are added. "Tencent does not strive to be the first to make large models." Liu Yuhong, vice president of Tencent Cloud and head of Tencent Hunyuan large model, said: "In the past year, we continued to promote the capabilities of Tencent Hunyuan large model. In the rich and massive Polish technology in business scenarios while gaining insights into users’ real needs
 Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Tan Dai, President of Volcano Engine, said that companies that want to implement large models well face three key challenges: model effectiveness, inference costs, and implementation difficulty: they must have good basic large models as support to solve complex problems, and they must also have low-cost inference. Services allow large models to be widely used, and more tools, platforms and applications are needed to help companies implement scenarios. ——Tan Dai, President of Huoshan Engine 01. The large bean bag model makes its debut and is heavily used. Polishing the model effect is the most critical challenge for the implementation of AI. Tan Dai pointed out that only through extensive use can a good model be polished. Currently, the Doubao model processes 120 billion tokens of text and generates 30 million images every day. In order to help enterprises implement large-scale model scenarios, the beanbao large-scale model independently developed by ByteDance will be launched through the volcano
 Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
1. Background Introduction First, let’s introduce the development history of Yunwen Technology. Yunwen Technology Company...2023 is the period when large models are prevalent. Many companies believe that the importance of graphs has been greatly reduced after large models, and the preset information systems studied previously are no longer important. However, with the promotion of RAG and the prevalence of data governance, we have found that more efficient data governance and high-quality data are important prerequisites for improving the effectiveness of privatized large models. Therefore, more and more companies are beginning to pay attention to knowledge construction related content. This also promotes the construction and processing of knowledge to a higher level, where there are many techniques and methods that can be explored. It can be seen that the emergence of a new technology does not necessarily defeat all old technologies. It is also possible that the new technology and the old technology will be integrated with each other.
 Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
According to news on June 13, according to Byte's "Volcano Engine" public account, Xiaomi's artificial intelligence assistant "Xiao Ai" has reached a cooperation with Volcano Engine. The two parties will achieve a more intelligent AI interactive experience based on the beanbao large model. It is reported that the large-scale beanbao model created by ByteDance can efficiently process up to 120 billion text tokens and generate 30 million pieces of content every day. Xiaomi used the beanbao large model to improve the learning and reasoning capabilities of its own model and create a new "Xiao Ai Classmate", which not only more accurately grasps user needs, but also provides faster response speed and more comprehensive content services. For example, when a user asks about a complex scientific concept, &ldq
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 iOS 18 adds a new 'Recovered' album function to retrieve lost or damaged photos
Jul 18, 2024 am 05:48 AM
iOS 18 adds a new 'Recovered' album function to retrieve lost or damaged photos
Jul 18, 2024 am 05:48 AM
Apple's latest releases of iOS18, iPadOS18 and macOS Sequoia systems have added an important feature to the Photos application, designed to help users easily recover photos and videos lost or damaged due to various reasons. The new feature introduces an album called "Recovered" in the Tools section of the Photos app that will automatically appear when a user has pictures or videos on their device that are not part of their photo library. The emergence of the "Recovered" album provides a solution for photos and videos lost due to database corruption, the camera application not saving to the photo library correctly, or a third-party application managing the photo library. Users only need a few simple steps
 AI hardware adds another member! Rather than replacing mobile phones, can NotePin last longer?
Sep 02, 2024 pm 01:40 PM
AI hardware adds another member! Rather than replacing mobile phones, can NotePin last longer?
Sep 02, 2024 pm 01:40 PM
So far, no product in the AI wearable device track has achieved particularly good results. AIPin, which was launched at MWC24 at the beginning of this year, once the evaluation prototype was shipped, the "AI myth" that was hyped at the time of its release began to be shattered, and it experienced large-scale returns in just a few months; RabbitR1, which also sold well at the beginning, was relatively It's better, but it also received negative reviews similar to "Android cases" when it was delivered in large quantities. Now, another company has entered the AI wearable device track. Technology media TheVerge published a blog post yesterday saying that AI startup Plaud has launched a product called NotePin. Unlike AIFriend, which is still in the "painting" stage, NotePin has now started
 Detailed tutorial on establishing a database connection using MySQLi in PHP
Jun 04, 2024 pm 01:42 PM
Detailed tutorial on establishing a database connection using MySQLi in PHP
Jun 04, 2024 pm 01:42 PM
How to use MySQLi to establish a database connection in PHP: Include MySQLi extension (require_once) Create connection function (functionconnect_to_db) Call connection function ($conn=connect_to_db()) Execute query ($result=$conn->query()) Close connection ( $conn->close())
