

Comparing Java crawler frameworks: Which is the best choice?


Exploring the best Java crawler framework: Which one is better?
In today's information age, a large amount of data is constantly generated and updated on the Internet. In order to extract useful information from massive data, crawler technology came into being. In crawler technology, Java, as a powerful and widely used programming language, has many excellent crawler frameworks to choose from. This article will explore several common Java crawler frameworks, analyze their characteristics and applicable scenarios, and finally find the best one.
- Jsoup
Jsoup is a very popular Java crawler framework that can process HTML documents simply and flexibly. Jsoup provides a simple and powerful API that makes parsing, traversing and manipulating HTML very easy. Here is a basic Jsoup example:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupExample {
public static void main(String[] args) throws Exception {
// 发送HTTP请求获取HTML文档
String url = "http://example.com";
Document doc = Jsoup.connect(url).get();
// 解析并遍历HTML文档
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println(link.attr("href"));
}
}
}- Apache Nutch
Apache Nutch is an open source web scraping and search engine software. It is developed based on Java and provides rich functions and flexible scalability. Apache Nutch supports large-scale distributed crawling and can efficiently process large amounts of web page data. The following is a simple Apache Nutch example:
import org.apache.nutch.crawl.CrawlDatum;
import org.apache.nutch.crawl.Inlinks;
import org.apache.nutch.fetcher.Fetcher;
import org.apache.nutch.parse.ParseResult;
import org.apache.nutch.protocol.Content;
import org.apache.nutch.util.NutchConfiguration;
public class NutchExample {
public static void main(String[] args) throws Exception {
String url = "http://example.com";
// 创建Fetcher对象
Fetcher fetcher = new Fetcher(NutchConfiguration.create());
// 抓取网页内容
Content content = fetcher.fetch(new CrawlDatum(url));
// 处理网页内容
ParseResult parseResult = fetcher.parse(content);
Inlinks inlinks = parseResult.getInlinks();
// 输出入链的数量
System.out.println("Inlinks count: " + inlinks.getInlinks().size());
}
}- WebMagic
WebMagic is an open source Java crawler framework based on Jsoup and HttpClient and provides a simple and easy-to-use API. WebMagic supports multi-threaded concurrent crawling, making it easy to define crawling rules and process crawling results. The following is a simple WebMagic example:
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class WebMagicExample implements PageProcessor {
public void process(Page page) {
// 解析HTML页面
String title = page.getHtml().$("title").get();
// 获取链接并添加新的抓取任务
page.addTargetRequests(page.getHtml().links().regex("http://example.com/.*").all());
// 输出结果
page.putField("title", title);
}
public Site getSite() {
return Site.me().setRetryTimes(3).setSleepTime(1000);
}
public static void main(String[] args) {
Spider.create(new WebMagicExample())
.addUrl("http://example.com")
.addPipeline(new ConsolePipeline())
.run();
}
}Comprehensive comparison of the above crawler frameworks, they all have their own advantages and applicable scenarios. Jsoup is suitable for relatively simple scenarios of parsing and operating HTML; Apache Nutch is suitable for crawling and searching large-scale distributed data; WebMagic provides a simple and easy-to-use API and multi-threaded concurrent crawling features. Depending on specific needs and project characteristics, choosing the most appropriate framework is key.
The above is the detailed content of Comparing Java crawler frameworks: Which is the best choice?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to enable nfc function on Xiaomi Mi 14 Pro?
Mar 19, 2024 pm 02:28 PM
How to enable nfc function on Xiaomi Mi 14 Pro?
Mar 19, 2024 pm 02:28 PM
Nowadays, the performance and functions of mobile phones are becoming more and more powerful. Almost all mobile phones are equipped with convenient NFC functions to facilitate users for mobile payment and identity authentication. However, some Xiaomi 14Pro users may not know how to enable the NFC function. Next, let me introduce it to you in detail. How to enable nfc function on Xiaomi 14Pro? Step 1: Open the settings menu of your phone. Step 2: Find and click the "Connect and Share" or "Wireless & Networks" option. Step 3: In the Connection & Sharing or Wireless & Networks menu, find and click "NFC & Payments". Step 4: Find and click "NFC Switch". Normally, the default is off. Step 5: On the NFC switch page, click the switch button to switch it to on.
 How to use TikTok on Huawei Pocket2 remotely?
Mar 18, 2024 pm 03:00 PM
How to use TikTok on Huawei Pocket2 remotely?
Mar 18, 2024 pm 03:00 PM
Sliding the screen through the air is a feature of Huawei that is highly praised in the Huawei mate60 series. This feature uses the laser sensor on the phone and the 3D depth camera of the front camera to complete a series of functions that do not require The function of touching the screen is, for example, to use TikTok from a distance. But how should Huawei Pocket 2 use TikTok from a distance? How to take screenshots from the air with Huawei Pocket2? 1. Open the settings of Huawei Pocket2 2. Then select [Accessibility]. 3. Click to open [Smart Perception]. 4. Just turn on the [Air Swipe Screen], [Air Screenshot], and [Air Press] switches. 5. When using it, you need to stand 20~40CM away from the screen, open your palm, and wait until the palm icon appears on the screen.
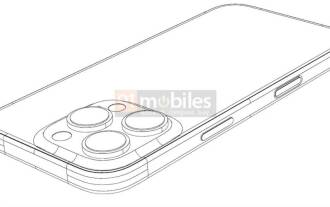 iPhone 16 Pro CAD drawings exposed, adding a second new button
Mar 09, 2024 pm 09:07 PM
iPhone 16 Pro CAD drawings exposed, adding a second new button
Mar 09, 2024 pm 09:07 PM
The CAD files of the iPhone 16 Pro have been exposed, and the design is consistent with previous rumors. Last fall, the iPhone 15 Pro added an Action button, and this fall, Apple appears to be planning to make minor adjustments to the size of the hardware. Adding a Capture button According to rumors, the iPhone 16 Pro may add a second new button, which will be the second consecutive year to add a new button after last year. It is rumored that the new Capture button will be set on the lower right side of the iPhone 16 Pro. This design is expected to make camera control more convenient and also allow the Action button to be used for other functions. This button will no longer be just an ordinary shutter button. Regarding the camera, from the current iP
 How to switch language in microsoft teams
Feb 23, 2024 pm 09:00 PM
How to switch language in microsoft teams
Feb 23, 2024 pm 09:00 PM
There are many languages to choose from in Microsoft Teams, so how to switch languages? Users need to click the menu, then find Settings, select General there, then click Language, select the language and save it. This introduction to switching language methods can tell you the specific content. The following is a detailed introduction. Take a look. Bar! How to switch language in Microsoft Teams Answer: Select the specific process in Settings-General-Language: 1. First, click the three dots next to the avatar to enter the settings. 2. Then click on the general options inside. 3. Then click on the language and scroll down to see more languages. 4. Finally, click Save and Restart.
 How to set line spacing in WPS Word to make the document neater
Mar 20, 2024 pm 04:30 PM
How to set line spacing in WPS Word to make the document neater
Mar 20, 2024 pm 04:30 PM
WPS is our commonly used office software. When editing long articles, the fonts are often too small to be seen clearly, so the fonts and the entire document are adjusted. For example: adjusting the line spacing of the document will make the entire document very clear. I suggest that all friends learn this operation step. I will share it with you today. The specific operation steps are as follows, come and take a look! Open the WPS text file you want to adjust, find the paragraph setting toolbar in the [Start] menu, and you will see the small line spacing setting icon (shown as a red circle in the picture). 2. Click the small inverted triangle in the lower right corner of the line spacing setting, and the corresponding line spacing value will appear. You can choose 1 to 3 times the line spacing (as shown by the arrow in the figure). 3. Or right-click the paragraph and it will appear.
 How to set a custom ringtone for Redmi K70E?
Feb 24, 2024 am 10:00 AM
How to set a custom ringtone for Redmi K70E?
Feb 24, 2024 am 10:00 AM
The Redmi K70E is undoubtedly excellent. As a mobile phone with a price of just over 2,000 yuan, the Redmi K70E can be said to be one of the most cost-effective mobile phones in its class. Many users who pursue cost-effectiveness have purchased this phone to experience various functions on Redmi K70E. So how to set a custom ringtone for Redmi K70E? How to set a custom ringtone for Redmi K70E? To set a custom incoming call ringtone for Redmi K70E, you can follow the steps below: Open the settings application of your phone, find the "Sounds and vibration" or "Sound" option in the settings application, and click "Incoming call ringtone" or "Phone ringtone" " option. In ringtone settings
 TrendX Research Institute: Merlin Chain project analysis and ecological inventory
Mar 24, 2024 am 09:01 AM
TrendX Research Institute: Merlin Chain project analysis and ecological inventory
Mar 24, 2024 am 09:01 AM
According to statistics on March 2, the total TVL of Bitcoin’s second-layer network MerlinChain has reached US$3 billion. Among them, Bitcoin ecological assets accounted for 90.83%, including BTC worth US$1.596 billion and BRC-20 assets worth US$404 million. Last month, MerlinChain’s total TVL reached US$1.97 billion within 14 days of launching staking activities, surpassing Blast, which was launched in November last year and is also the most recent and equally eye-catching. On February 26, the total value of NFTs in the MerlinChain ecosystem exceeded US$420 million, becoming the public chain project with the highest NFT market value besides Ethereum. Project Introduction MerlinChain is an OKX support
 Comparison and analysis of advantages and disadvantages of PHP7.2 and 5 versions
Feb 27, 2024 am 10:51 AM
Comparison and analysis of advantages and disadvantages of PHP7.2 and 5 versions
Feb 27, 2024 am 10:51 AM
Comparison and analysis of advantages and disadvantages of PHP7.2 and 5. PHP is an extremely popular server-side scripting language and is widely used in Web development. However, PHP is constantly being updated and improved in different versions to meet changing needs. Currently, PHP7.2 is the latest version, which has many noteworthy differences and improvements compared with the previous PHP5 version. In this article, we will compare PHP7.2 and PHP5 versions, analyze their advantages and disadvantages, and provide specific code examples. 1. Performance PH
