
 Technology peripherals
AI
Morph Studio: Free, 1080P, 7-second powerful dark horse video editing software is coming
Technology peripherals
AI
Morph Studio: Free, 1080P, 7-second powerful dark horse video editing software is coming
Morph Studio: Free, 1080P, 7-second powerful dark horse video editing software is coming

"Glowing jellyfish slowly rise from the ocean," continue typing in what you want to see in Morph Studio, "turning into shimmering constellations in the night sky."
After a few minutes, Morph Studio generates a short video. A jellyfish is completely transparent and sparkling, spinning and rising, its swaying figure contrasting with the stars in the night sky.
Luminous jellyfish rise from an enchanting sea, morphing into glittering stars in the dark sky.
Enter "joker cinematic", which once swept the world That face is back.
Joaquin Phoenix delivers a hyper-realistic performance as the Joker in the cinematic shot set in the neon-lit streets of New York. Smoke billows around him, adding to the atmosphere of chaos and darkness.
Recently, startup Morph Studio has made an important update to its text-to-video generation technology and community. Their model has undergone a major update, and these video productions show off the updated model, with clear images and vivid details.
Morph Studio is the first team in the world to publicly launch a text-to-video product that can be freely tested by the public, earlier than Runway launched Gen2 in public beta.
Compared with other popular text-to-video products, Morph Studio is different in terms of free services. It offers a default 1080P resolution and a maximum build time of 7 seconds from the start. For text-to-video products, higher resolution, longer generation time, and better expression of intent are three key indicators. Morph has reached the latest level in the industry in these three indicators.
The average length of a single shot of a Hollywood movie is 6 seconds. Extending the generation time to 7 seconds can unlock the creative needs of more users.
It’s easy to experience Morph Studio’s models. You can use it for free by registering on discord.
The model with the word "pro" in the red box on the screen is the updated model and is the subject of this article's experience.
Camera movement is the basic language of video production and a powerful narrative device. Morph provides several general camera languages, including zoom, pan (up, down, left, right), rotation (clockwise or counterclockwise), and still shots.
Morph also provides the MOTION function (1-10) to control video movement. The larger the value, the more violent and exaggerated the action. The smaller the value, the more subtle and smooth the action.
The frame rate (FPS) provides an adjustment range from 8 -30. The higher the value, the smoother the video and the larger the size. For example, -FPS 30 will produce the smoothest but also largest video. By default, all videos are created at 24 frames per second.
The default video length is 3 seconds. To generate a 7-second video, you can enter -s 7 in the command. Additionally, the model offers 5 video ratios to choose from.
If you have requirements for details such as lens, frame rate, and video length, please continue to enter the corresponding parameters after entering the content prompt. (Currently only English input is supported.)
We have experienced the updated model service and strongly feel the visual shock brought by 1080P.
Until recently, humans had the first photo of a snow leopard walking under the stars:

The first human photo of a snow leopard walking under the stars.
We want to know, can Morph Studio’s model be able to generate this relatively rare animal video?
With the same prompt, we put the works of Morph Studio in the upper part of the video, and the works generated with Pika in the lower part of the video.
a snow leopard walking under a starry night, cinematic realistic, super detail, -motion 10, -ar 16:9, -zoom in, -pan up, -fps 30, - s 7. negative: Extra limbs, Missing arms and legs, fused fingers and legs, extra fingers, disfigure
Morph Studio’s answer sheet, the text is understood accurately. In the 1080P picture, the snow leopard’s fur is rich in detail and lifelike. The Milky Way and stars can be seen in the background. However, the snow leopard's movement is not obvious.
In Pika’s homework, the snow leopard is indeed walking, but the night sky seems to be understood as a night with goose feathers and heavy snow. There is still a gap in terms of Snow Leopard style, details, and picture clarity.
Let’s take a look at the effect of character generation.
masterpiece best quality ultra detailed RAW video 1girl solo dancing digital painting beautiful cyborg girl age 21 long wavy red hair blue eyes delicate pale white skin perfect body singing in the eerie light of dawn in a post-apocalyp
In the works generated by Morph Studio, the high resolution brings extremely delicate facial contours and micro-expressions. Under dawn light, hair details are clearly visible.
Due to the lack of resolution, color, and light levels, the overall picture generated by Pika is bluish, and the facial details of the characters are not satisfactory.
People and animals have experienced it, let’s take a look at the generation effect of buildings (man-made objects).
La torre eifel starry night van gogh epic stylish fine art complex deep colors flowing fky moving clouds
and Pika’s works are more of a painting texture Compared with the picture, Morph Studio's work better balances Van Gogh elements and realistic elements. The light levels are very rich, especially the flowing details of the sea of clouds. The sky in Pika's work is almost static.
Finally, experience the creation of natural scenery.
One early morning the sun slowly rose from the sea level and the waves gently touched the beach.
You may wonder about Morph Studio The works are not real shots taken by human photographers under natural conditions.
Because the video generated by Pika lacks delicate light and shadow levels, the waves and the beach appear flat, and the movements of the waves hitting the beach are relatively dull.
In addition to the shocking experience brought by high resolution, with the same prompt to generate videos (such as animals, buildings, people and natural scenery themes), opponents will more or less " "Miss", Morph Studio's performance is relatively more stable, there are relatively fewer corner cases, and it can predict user intentions more accurately.
From the beginning, this startup’s understanding of Vincent Video is that the video must be able to describe user input very accurately, and all optimization work is also moving in this direction. The model structure of Morph Studio has a deeper understanding of textual intentions. This update has made some structural changes and specially made more detailed annotations for some data.
In addition to the relatively good text understanding ability, the detail processing of the picture is not stumped by the high-resolution output. In fact, after the model was updated, the motion content of the screen was richer, which is also reflected in the works we generated using Morph Studio.
"Girl with a Pearl Earring" When the head moves, the earrings are also shaking slightly; the scenes involving more complex actions such as horseback riding are also more smooth, coherent and logical, and the hand movements The output is also good.
1080P means that the model has to process more pixels, which brings greater challenges to detail generation. However, judging from the results, not only did the picture not collapse, but because of the rich layers More detailed and more expressive.
This is a set of natural landscapes we generated using models, including spectacular huge waves and volcanic eruptions, as well as delicate close-ups of flowers.
High-resolution output brings better visual enjoyment to users, but it also prolongs the model output time and affects the experience.
Morph Studio now generates 1080p videos in 3 and a half minutes, the same speed as Pika generates 720P videos. Start-up companies have limited computing resources, so it is not easy for Morph Studio to maintain SOTA.
In addition, in terms of video style, in addition to movie realism, Morph Studio models also support common styles such as comics and 3D animation.
Morph Studio’s focus on text-to-video technology is regarded as the next stage in the AI industry competition.
“Instant video may represent the next leap in AI technology,” the New York Times said in a headline of a technology report, arguing that it will be as important as the web browser and the iPhone.
In September 2022, Meta’s team of machine learning engineers launched a new system called Make-A-Video. Users enter a rough description of the scene, and the system will generate A corresponding short video.
In November 2022, researchers from Tsinghua University and Beijing Academy of Artificial Intelligence (BAAI) also released CogVideo.
At that time, the videos generated by these models were not only blurry (for example, the video resolution generated by CogVideo was only 480 x 480), the pictures were also relatively distorted, and there were many technical limitations. But they still represent a significant development in AI content generation.
On the surface, a video is just a series of frames (still images) put together in a way that gives the illusion of movement. However, it is much more difficult to ensure the consistency of a series of images in time and space.
The emergence of the diffusion model has accelerated the evolution of technology. Researchers have attempted to generalize the diffusion model to other domains such as audio, 3D, and video, and video synthesis technology has made significant advances.
Technology based on the diffusion model mainly allows the neural network to automatically learn some patterns by sorting out massive images, videos and text descriptions. When you input content requirements, the neural network generates a list of all the features it thinks might be used to create the image (think the outline of a cat's ears, the edges of a phone).
Then, a second neural network (also known as the diffusion model) is responsible for creating the image and generating the pixels needed for these features, and converting the pixels into a coherent image. By analyzing thousands of videos, the AI can learn to string many still images together in a similarly coherent manner. The key is to train a model that truly understands the relationships and consistency between each frame.
“This is one of the most impressive technologies we’ve built in the last hundred years,” Runway CEO Cristóbal Valenzuela once told the media. “You need to make people really Use it.”
2023 is regarded by some in the industry as a breakthrough year for video synthesis. There was no publicly available text-to-video model in January, and by the end of the year there were dozens of similar products and millions of users.
a16z partner Justine Moore shared the timeline of Vincent’s video model on social platforms. We can see from it that there are many other models besides big manufacturers. Startup companies, in addition, the speed of technology iteration is very fast. 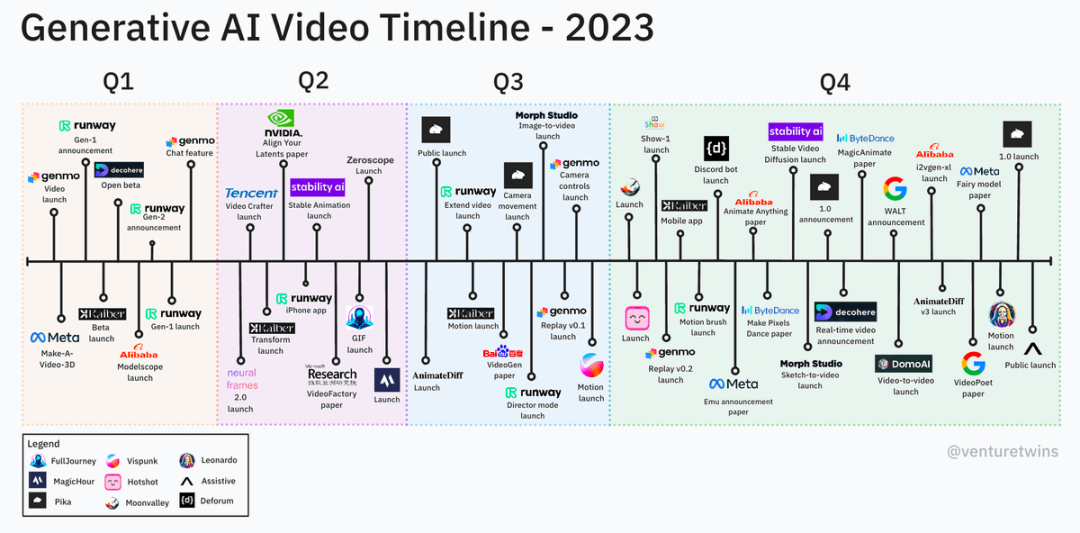
The current AI-generated videos have not formed a unified and clear technical paradigm similar to LLM. The industry is still in the exploratory stage on how to generate stable videos. But the researchers believe these flaws can be eliminated as their system is trained with more and more data. Eventually, this technology will make creating videos as easy as writing sentences.
A senior domestic AI industry investor told us that several of the most important papers on Vincent Video Technology were published from July to August 2022, which is similar to the industry of Vincent Picture In the process of industrialization, the point where this technology is close to industrialization will appear one year later, that is, from July to August 2023.
The entire video technology is developing very fast, and the technology is becoming more and more mature. This investor said that based on previous investment experience in the GAN field, they predict that the next six months to one year will be The productization period of text-to-video technology.
The Morph team brings together the best young researchers in the field of video generation. After intensive research and development day and night over the past year, founder Xu Huaizhe and co-founders Li Feng, Yin Zixin, Zhao Shihao, and Liu Shaoteng Together with other core technical backbones, we have overcome the problem of AI video generation.
In addition to the technical team, Morph Studio has also recently strengthened its product team. Hai is the contracted producer of Maoyan Films, a judge of the Shanghai International Film Festival, and a core member of the former Silicon Valley head AIGC company. Xin also recently joined Morph Studio.
Heising said that Morph Studio occupies a leading position in the entire industry in terms of technical research; the team is flat, communication efficiency and execution are particularly high; every member is passionate about the industry. Her biggest dream was to join an animation company. After the advent of the AI era, she quickly realized that the animation industry would change in the future. In the past few decades, the animation base was 3D engines, and a new era of AI engines would soon usher in. The Pixar of the future will be born in an AI company. And Morph was her choice.
Founder Xu Huaizhe said that Morph is actively laying out the AI video track. We are determined to be a Super App in the AI video era and realize dreams for users.
The track will have its own Midjourney moment in 2024, he added.
PS: To experience the original fun of free 1080P video generation, please go to:
https://discord.com/ invite/VVqS8QnBkA
The above is the detailed content of Morph Studio: Free, 1080P, 7-second powerful dark horse video editing software is coming. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
1. First open Weibo on your mobile phone and click [Me] in the lower right corner (as shown in the picture). 2. Then click [Gear] in the upper right corner to open settings (as shown in the picture). 3. Then find and open [General Settings] (as shown in the picture). 4. Then enter the [Video Follow] option (as shown in the picture). 5. Then open the [Video Upload Resolution] setting (as shown in the picture). 6. Finally, select [Original Image Quality] to avoid compression (as shown in the picture).
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
