
 Technology peripherals
AI
The first universal 3D graphics and text model system for furniture and home appliances that requires no guidance and can be used in generalized visualization models
Technology peripherals
AI
The first universal 3D graphics and text model system for furniture and home appliances that requires no guidance and can be used in generalized visualization models
The first universal 3D graphics and text model system for furniture and home appliances that requires no guidance and can be used in generalized visualization models

These days, all housework is being done by robots.
The robot from Stanford that can use pots has just appeared, and the robot that can use coffee machines has just arrived, Figure-01.

#Figure-01 Just watch the demonstration video and conduct 10 hours of training to be able to operate the coffee machine proficiently. From inserting the coffee capsule to pressing the start button, it’s all done in one go.
However, it is a difficult problem to enable robots to independently learn to use various furniture and home appliances without the need for demonstration videos when encountering them. This requires the robot to have strong visual perception and decision-making planning capabilities, as well as precise manipulation skills.

Paper link: https://arxiv.org/abs/2312.01307
Project homepage: https://geometry.stanford.edu/projects/ sage/
Code: https://github.com/geng-haoran/SAGE
Overview of Research Problem

Figure 1: According to human instructions, the robotic arm can use various household appliances without any instruction.
Recently, PaLM-E and GPT-4V have promoted the application of large graphic models in robot task planning, and generalized robot control guided by visual language has become a popular research field.
The common method in the past was to build a two-layer system. The upper-layer large graphic model does planning and skill scheduling, and the lower-layer control skill strategy model is responsible for physically executing actions. But when robots face a variety of household appliances that they have never seen before and require multi-step operations in housework, both the upper and lower layers of the existing methods will be helpless.
Take the most advanced graphic model GPT-4V as an example. Although it can describe a single picture with text, when it comes to the detection, counting, positioning and status estimation of operable parts, it still has full of mistakes. The red highlights in Figure 2 are the various errors GPT-4V made when describing pictures of chests of drawers, ovens, and standing cabinets. Based on the wrong description, the robot's skill scheduling is obviously unreliable.

Figure 2: GPT-4V does not handle counting, detection,## very well #Positioning, state estimation and other tasks focused on generalized control.
The lower-level control skill strategy model is responsible for executing the tasks given by the upper-level graphic and text model in various actual situations. Most of the existing research results rigidly encode the grasping points and operation methods of some known objects based on rules, and cannot generally deal with new object categories that have not been seen before. However, end-to-end operation models (such as RT-1, RT-2, etc.) only use RGB modality, lack accurate perception of distance, and have poor generalization to changes in new environments such as height. Inspired by Professor Wang He’s team’s previous CVPR Highlight work GAPartNet [1], the research team focused on common parts (GAParts) in various categories of household appliances. Although household appliances are ever-changing, there are always a few parts that are indispensable. There are similar geometries and interaction patterns between each household appliance and these common parts. As a result, the research team introduced the concept of GAPart in the paper GAPartNet [1]. GAPart refers to a generalizable and interactive component. GAPart appears on different categories of hinged objects. For example, hinged doors can be found in safes, wardrobes, and refrigerators. As shown in Figure 3, GAPartNet [1] annotates the semantics and pose of GAPart on various types of objects.
Figure 3: GAPart: a generalizable and interactive component [1].
Based on previous research, the research team creatively introduced GAPart based on three-dimensional vision into the robot's object manipulation system SAGE. SAGE will provide information for VLM and LLM through generalizable 3D part detection and accurate pose estimation. At the decision-making level, the new method solves the problem of insufficient precise calculation and reasoning capabilities of the two-dimensional graphic model; at the execution level, the new method achieves generalized operations on each part through a robust physical operation API based on GAPart poses.
SAGE constitutes the first three-dimensional embodied graphic and text large-scale model system, providing new ideas for the entire link of robots from perception, physical interaction to feedback, and enabling robots to intelligently and universally control furniture and home appliances, etc. Complex objects explore a possible path.
System Introduction
Figure 4 shows the basic process of SAGE. First, an instruction interpretation module capable of interpreting context will parse the instructions input to the robot and its observations, and convert these parses into the next robot action program and its related semantic parts. Next, SAGE maps the semantic part (such as the container) to the part that needs to be operated (such as the slider button), and generates actions (such as the "press" action of the button) to complete the task.

Figure 4: Overview of the method.
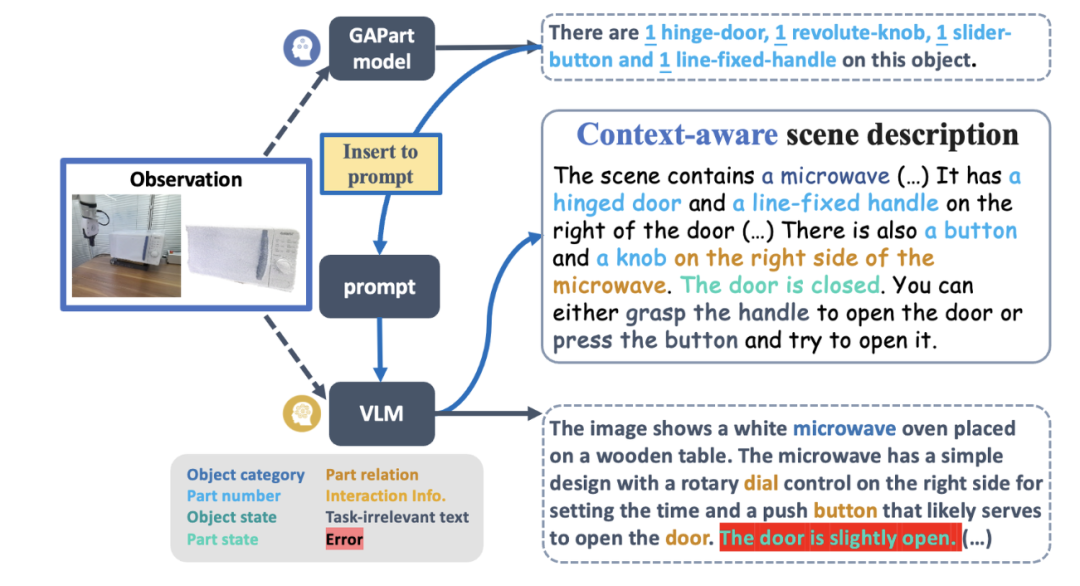
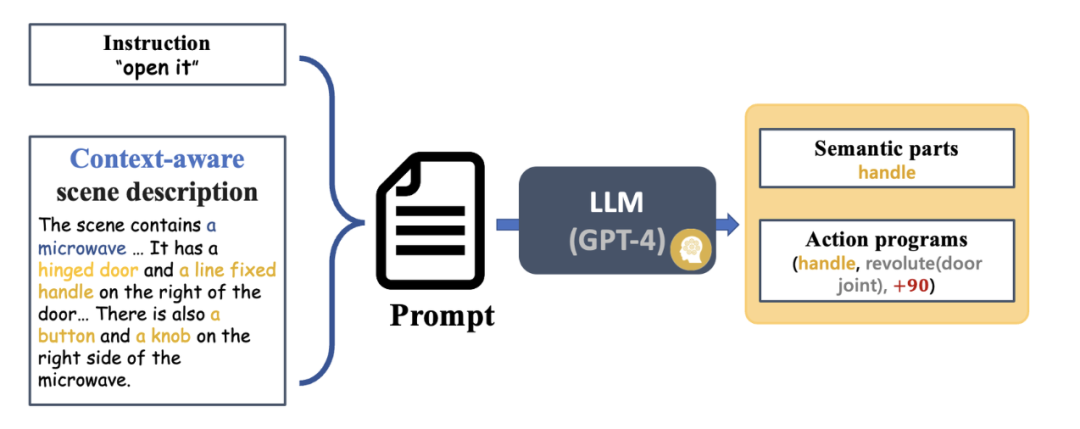
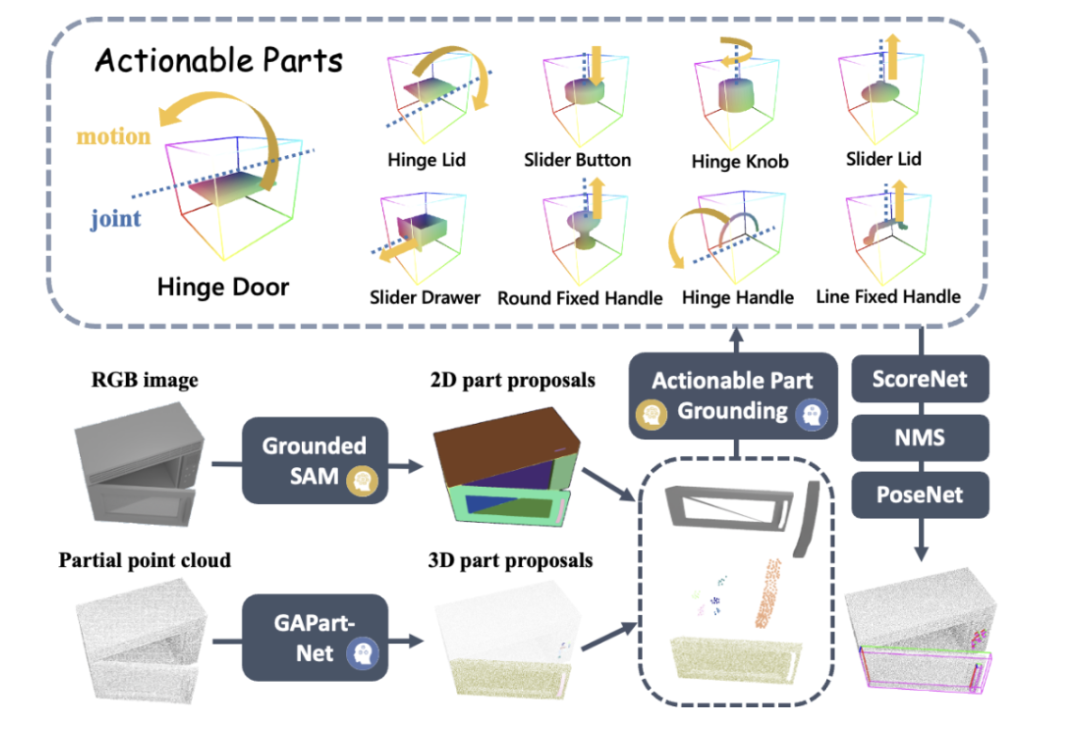



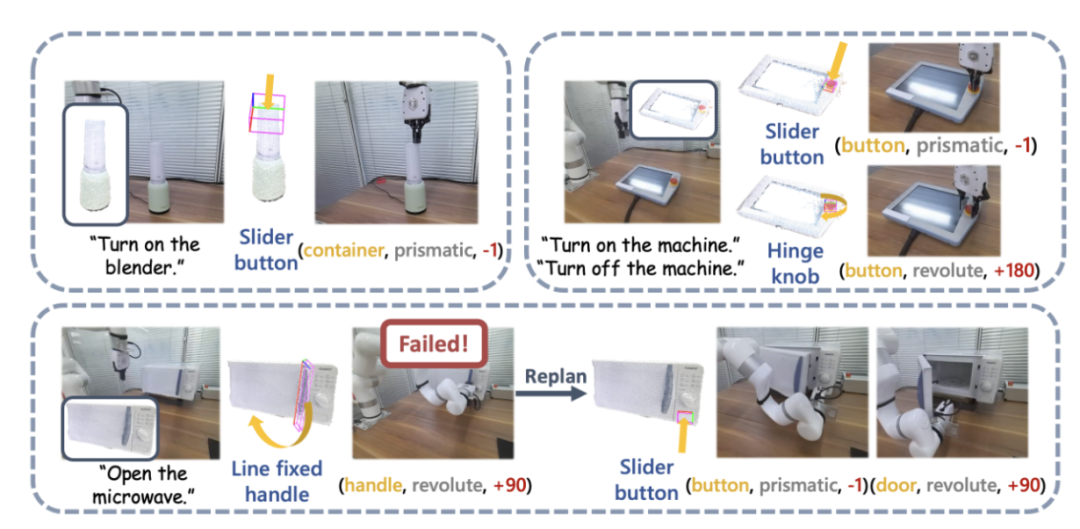
Figure 12: Real machine demonstration.
The research team also conducted large-scale real-world experiments using UFACTORY xArm 6 and a variety of different articulated objects. The upper left part of the image above shows an example of starting a blender. The top of the blender is perceived as a container for juice, but its actual function requires the push of a button to activate. SAGE's framework effectively bridges its semantic and action understanding and successfully performs the task.
The upper right part of the picture above shows the robot, which needs to press (down) the emergency stop button to stop operation and rotate (up) to restart. A robotic arm guided by SAGE accomplished both tasks with auxiliary input from a user manual. The image at the bottom of the image above shows more detail in the task of turning on a microwave.

Figure 13: More examples of real machine demonstration and command interpretation.
Summary
Team Introduction
SAGE This research result comes from the laboratory of Professor Leonidas Guibas of Stanford University, the Embodied Perception and Interaction (EPIC Lab) of Professor Wang He of Peking University, and the Intelligent Intelligence Laboratory. Source Artificial Intelligence Research Institute. The authors of the paper are Peking University student and Stanford University visiting scholar Geng Haoran (co-author), Peking University doctoral student Wei Songlin (co-author), Stanford University doctoral students Deng Congyue and Shen Bokui, and the supervisors are Professor Leonidas Guibas and Professor Wang He .
References:
[1] Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi , Siyuan Huang, and He Wang. Gapartnet: Cross-category domaingeneralizable object perception and manipulation via generalizable and actionable parts. arXiv preprint arXiv:2211.05272, 2022.
[2] Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao et al. "Segment anything." arXiv preprint arXiv:2304.02643 (2023).
[3] Zhang, Hao, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung-Yeung Shum. "Dino: Detr with improved denoising anchor boxes for end-to-end object detection." arXiv preprint arXiv:2203.03605 (2022).
[4] Xiang , Fanbo, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu et al. "Sapien: A simulated part-based interactive environment." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11097-11107.2020.
The above is the detailed content of The first universal 3D graphics and text model system for furniture and home appliances that requires no guidance and can be used in generalized visualization models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
It is also a Tusheng video, but PaintsUndo has taken a different route. ControlNet author LvminZhang started to live again! This time I aim at the field of painting. The new project PaintsUndo has received 1.4kstar (still rising crazily) not long after it was launched. Project address: https://github.com/lllyasviel/Paints-UNDO Through this project, the user inputs a static image, and PaintsUndo can automatically help you generate a video of the entire painting process, from line draft to finished product. follow. During the drawing process, the line changes are amazing. The final video result is very similar to the original image: Let’s take a look at a complete drawing.
 Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com The authors of this paper are all from the team of teacher Zhang Lingming at the University of Illinois at Urbana-Champaign (UIUC), including: Steven Code repair; Deng Yinlin, fourth-year doctoral student, researcher
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com In the development process of artificial intelligence, the control and guidance of large language models (LLM) has always been one of the core challenges, aiming to ensure that these models are both powerful and safe serve human society. Early efforts focused on reinforcement learning methods through human feedback (RL
 arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
cheers! What is it like when a paper discussion is down to words? Recently, students at Stanford University created alphaXiv, an open discussion forum for arXiv papers that allows questions and comments to be posted directly on any arXiv paper. Website link: https://alphaxiv.org/ In fact, there is no need to visit this website specifically. Just change arXiv in any URL to alphaXiv to directly open the corresponding paper on the alphaXiv forum: you can accurately locate the paragraphs in the paper, Sentence: In the discussion area on the right, users can post questions to ask the author about the ideas and details of the paper. For example, they can also comment on the content of the paper, such as: "Given to
 A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
Recently, the Riemann Hypothesis, known as one of the seven major problems of the millennium, has achieved a new breakthrough. The Riemann Hypothesis is a very important unsolved problem in mathematics, related to the precise properties of the distribution of prime numbers (primes are those numbers that are only divisible by 1 and themselves, and they play a fundamental role in number theory). In today's mathematical literature, there are more than a thousand mathematical propositions based on the establishment of the Riemann Hypothesis (or its generalized form). In other words, once the Riemann Hypothesis and its generalized form are proven, these more than a thousand propositions will be established as theorems, which will have a profound impact on the field of mathematics; and if the Riemann Hypothesis is proven wrong, then among these propositions part of it will also lose its effectiveness. New breakthrough comes from MIT mathematics professor Larry Guth and Oxford University
 Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Show the causal chain to LLM and it learns the axioms. AI is already helping mathematicians and scientists conduct research. For example, the famous mathematician Terence Tao has repeatedly shared his research and exploration experience with the help of AI tools such as GPT. For AI to compete in these fields, strong and reliable causal reasoning capabilities are essential. The research to be introduced in this article found that a Transformer model trained on the demonstration of the causal transitivity axiom on small graphs can generalize to the transitive axiom on large graphs. In other words, if the Transformer learns to perform simple causal reasoning, it may be used for more complex causal reasoning. The axiomatic training framework proposed by the team is a new paradigm for learning causal reasoning based on passive data, with only demonstrations
 The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Introduction In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the basic model for many downstream tasks, current MLLM consists of the well-known Transformer network, which
