
 Technology peripherals
AI
The TF-T2V technology jointly developed by Huake, Ali and other companies reduces the cost of AI video production!
Technology peripherals
AI
The TF-T2V technology jointly developed by Huake, Ali and other companies reduces the cost of AI video production!
The TF-T2V technology jointly developed by Huake, Ali and other companies reduces the cost of AI video production!

In the past two years, with the opening of large-scale graphic and text data sets such as LAION-5B, a series of methods with amazing effects have emerged in the field of image generation, such as Stable Diffusion, DALL-E 2, ControlNet and Composer . The emergence of these methods has made great breakthroughs and progress in the field of image generation. The field of image generation has developed rapidly in just the past two years.
However, video generation still faces huge challenges. First, compared with image generation, video generation needs to process higher-dimensional data and needs to take into account the additional time dimension, which brings about the problem of timing modeling. To drive learning of temporal dynamics, we need more video-text pair data. However, accurate temporal annotation of videos is very expensive, which limits the size of video-text datasets. Currently, the existing WebVid10M video dataset only contains 10.7M video-text pairs. Compared with the LAION-5B image dataset, the data size is far different. This severely restricts the possibility of large-scale expansion of video generation models.
In order to solve the above problems, the joint research team of Huazhong University of Science and Technology, Alibaba Group, Zhejiang University and Ant Group recently released the TF-T2V video solution:

##Paper address: https://arxiv.org/abs/2312.15770
Project Home page: https://tf-t2v.github.io/
Source code will be released soon: https://github.com/ali-vilab/i2vgen-xl (VGen project) .
This solution takes a different approach and proposes video generation based on large-scale text-free annotated video data, which can learn rich motion dynamics.
Let’s first take a look at the video generation effect of TF-T2V:
文生视频 Task
Prompt word: Generate a video of a large frost-like creature on a snow-covered land.

Prompt word: Generate an animated video of a cartoon bee.

Prompt word: Generate a video containing a futuristic fantasy motorcycle.

Prompt word: Generate a video of a little boy smiling happily.

Prompt words: Generate a video of an old man feeling a headache.

Combined video generation task
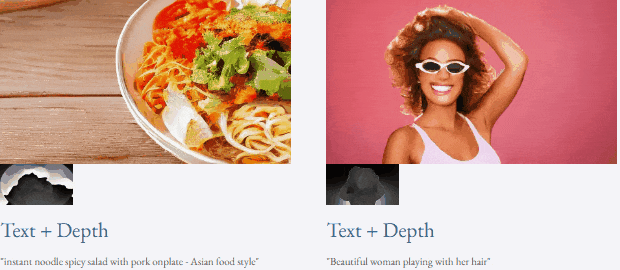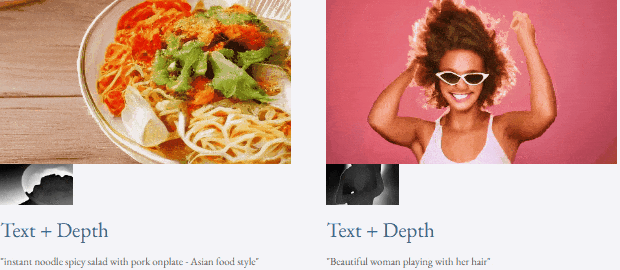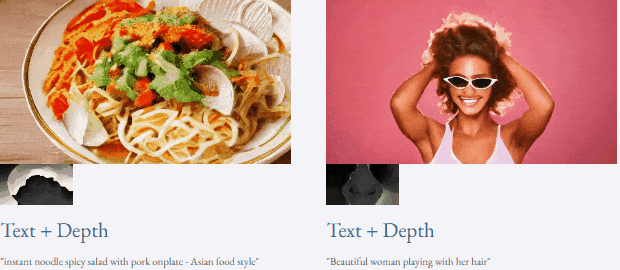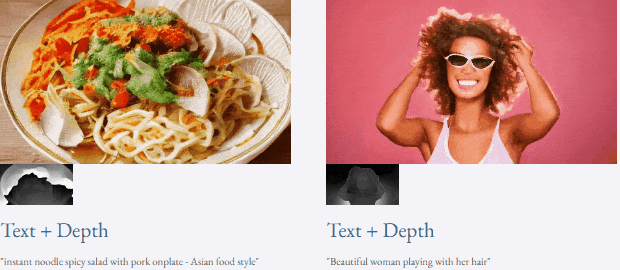
Given text and depth map Or text and sketches, TF-T2V can perform controllable video generation:
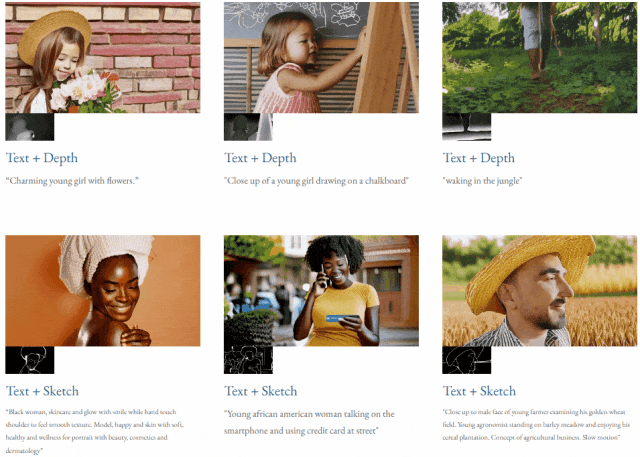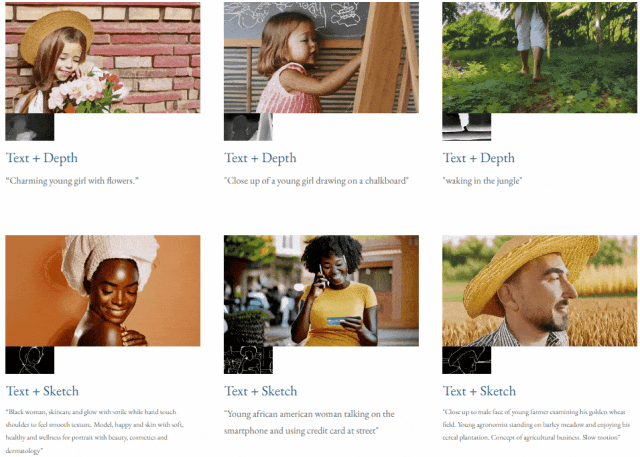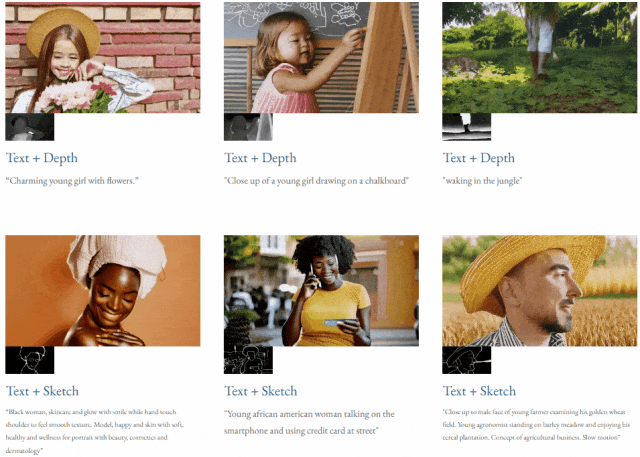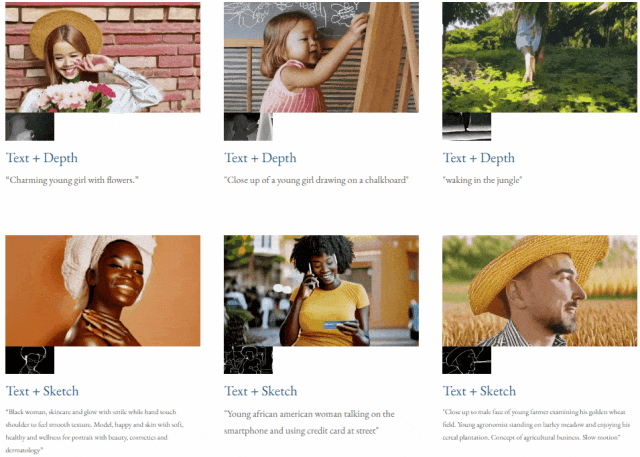
It can also perform high-resolution video synthesis:
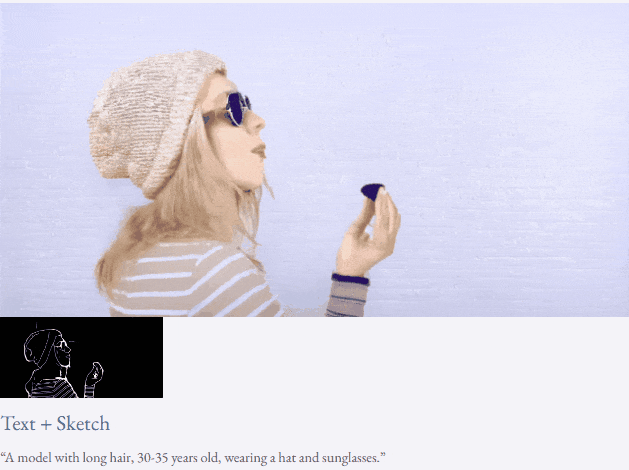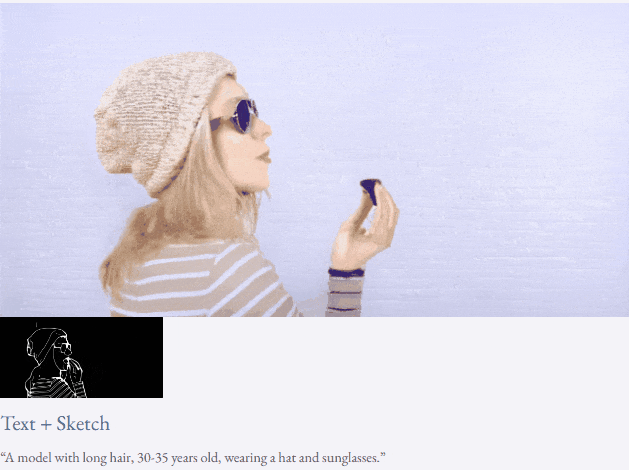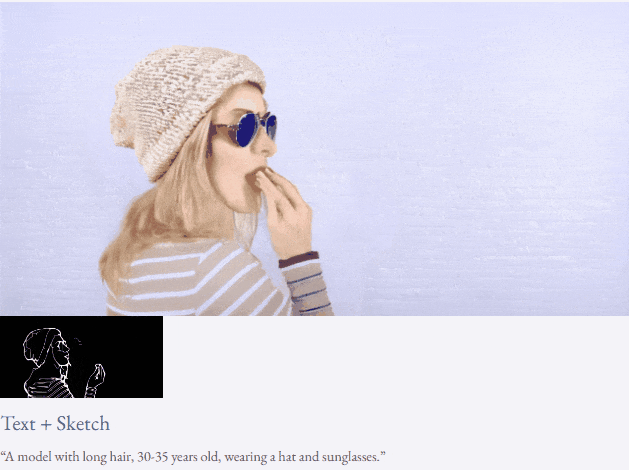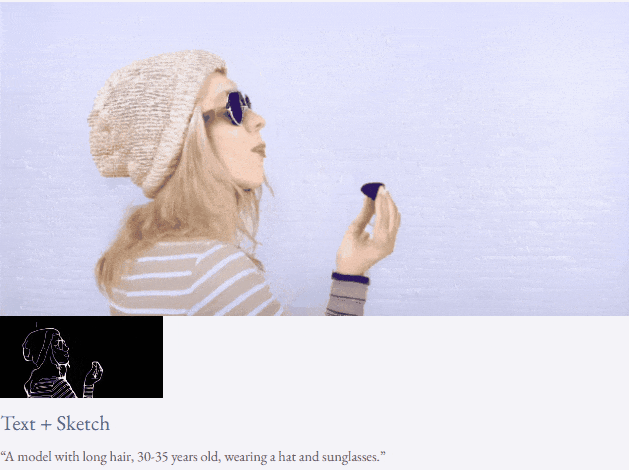
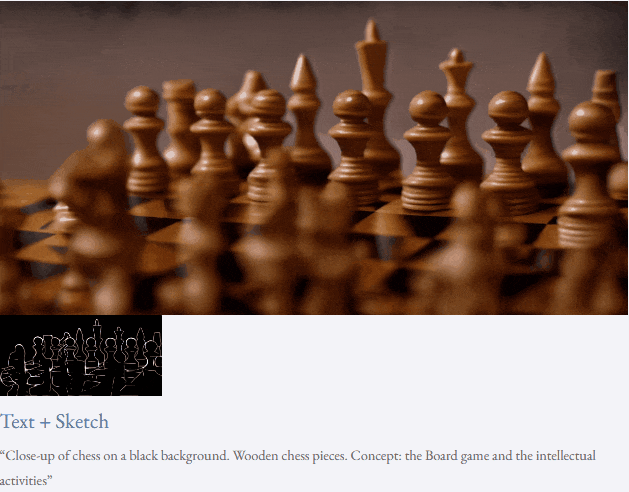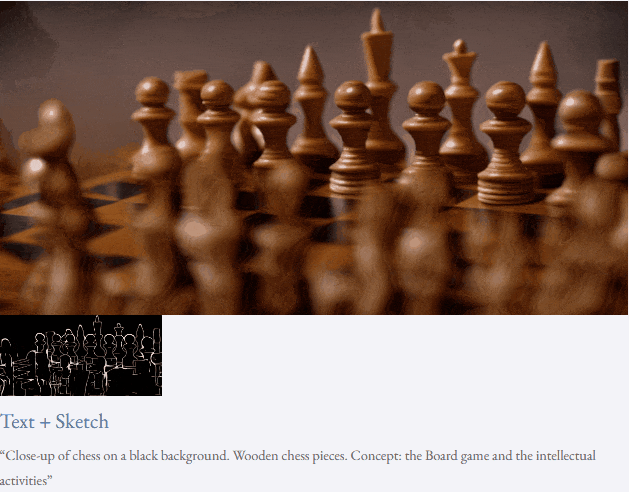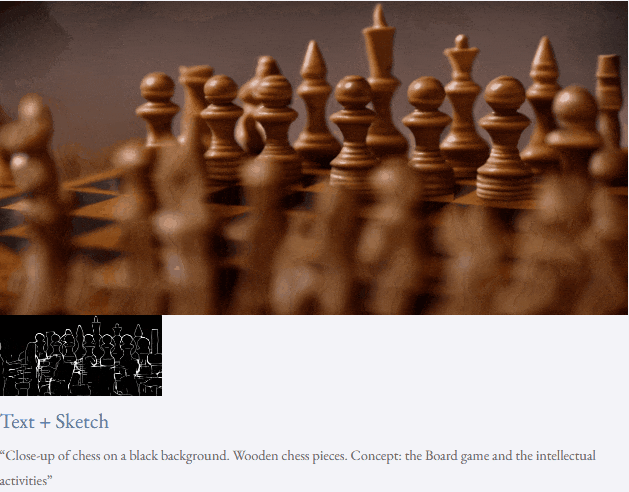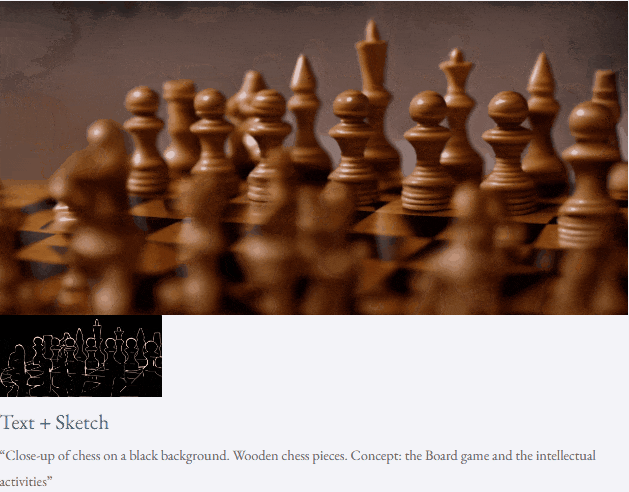
##
Semi-supervised setting
The TF-T2V method in the semi-supervised setting can also generate videos that conform to the description of motion text, such as "People run from right to left."


Method introduction
The core idea of TF-T2V The model is divided into a motion branch and an appearance branch. The motion branch is used to model motion dynamics, and the appearance branch is used to learn visual appearance information. These two branches are trained jointly, and finally can achieve text-driven video generation.
In order to improve the temporal consistency of generated videos, the author team also proposed a temporal consistency loss to explicitly learn the continuity between video frames.
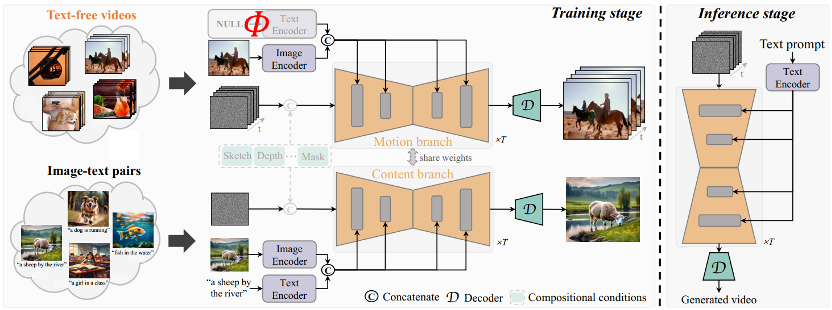
It is worth mentioning that TF-T2V is a general framework that is not only suitable for Vincent video tasks, but also for combined Video generation tasks, such as sketch-to-video, video inpainting, first frame-to-video, etc.
For specific details and more experimental results, please refer to the original paper or the project homepage.
In addition, the author team also used TF-T2V as a teacher model and used consistent distillation technology to obtain the VideoLCM model:

Paper address: https://arxiv.org/abs/2312.09109
Project homepage: https://tf-t2v.github.io/
The source code will be released soon: https://github.com/ali-vilab/i2vgen-xl (VGen project).
Unlike previous video generation methods that require about 50 steps of DDIM denoising, the VideoLCM method based on TF-T2V can generate high-fidelity videos with only about 4 steps of inference denoising. , greatly improving the efficiency of video generation.
Let’s take a look at the results of VideoLCM’s 4-step denoising inference:


For specific details and more experimental results, please refer to the original VideoLCM paper or the project homepage.
In short, the TF-T2V solution brings new ideas to the field of video generation and overcomes the challenges caused by data set size and labeling difficulties. Leveraging large-scale text-free annotation video data, TF-T2V is able to generate high-quality videos and is applied to a variety of video generation tasks. This innovation will promote the development of video generation technology and bring broader application scenarios and business opportunities to all walks of life.
The above is the detailed content of The TF-T2V technology jointly developed by Huake, Ali and other companies reduces the cost of AI video production!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
With the rise of short video platforms, Douyin has become an indispensable part of everyone's daily life. On TikTok, we can see interesting videos from all over the world. Some people like to post other people’s videos, which raises a question: Is Douyin infringing upon posting other people’s videos? This article will discuss this issue and tell you how to edit videos without infringement and how to avoid infringement issues. 1. Is it infringing upon Douyin’s posting of other people’s videos? According to the provisions of my country's Copyright Law, unauthorized use of the copyright owner's works without the permission of the copyright owner is an infringement. Therefore, posting other people’s videos on Douyin without the permission of the original author or copyright owner is an infringement. 2. How to edit a video without infringement? 1. Use of public domain or licensed content: Public
 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
With the rise of short video platforms, Xiaohongshu has become a platform for many people to share their lives, express themselves, and gain traffic. On this platform, publishing video works is a very popular way of interaction. So, how to publish Xiaohongshu video works? 1. How to publish Xiaohongshu video works? First, make sure you have a video content ready to share. You can use your mobile phone or other camera equipment to shoot, but you need to pay attention to the image quality and sound clarity. 2. Edit the video: In order to make the work more attractive, you can edit the video. You can use professional video editing software, such as Douyin, Kuaishou, etc., to add filters, music, subtitles and other elements. 3. Choose a cover: The cover is the key to attracting users to click. Choose a clear and interesting picture as the cover to attract users to click on it.
 How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
Douyin, the national short video platform, not only allows us to enjoy a variety of interesting and novel short videos in our free time, but also gives us a stage to show ourselves and realize our values. So, how to make money by posting videos on Douyin? This article will answer this question in detail and help you make more money on TikTok. 1. How to make money from posting videos on Douyin? After posting a video and gaining a certain amount of views on Douyin, you will have the opportunity to participate in the advertising sharing plan. This income method is one of the most familiar to Douyin users and is also the main source of income for many creators. Douyin decides whether to provide advertising sharing opportunities based on various factors such as account weight, video content, and audience feedback. The TikTok platform allows viewers to support their favorite creators by sending gifts,
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
1. First open Weibo on your mobile phone and click [Me] in the lower right corner (as shown in the picture). 2. Then click [Gear] in the upper right corner to open settings (as shown in the picture). 3. Then find and open [General Settings] (as shown in the picture). 4. Then enter the [Video Follow] option (as shown in the picture). 5. Then open the [Video Upload Resolution] setting (as shown in the picture). 6. Finally, select [Original Image Quality] to avoid compression (as shown in the picture).
