

2023 Telecom AI Company Summit Papers and Competition Sharing

In recent years, China Telecom has continued to work hard in the direction of artificial intelligence technology. On November 28, 2023, China Telecom Digital Intelligence Technology Branch officially changed its name to China Telecom Artificial Intelligence Technology Co., Ltd. (hereinafter referred to as "Telecom AI Company"). In 2023, Telecom AI Company won consecutive awards in 21 top domestic and foreign AI competitions, applied for more than 100 patents, and published more than 30 papers in top conferences and journals such as CVPR, ACM MM, and ICCV, demonstrating the performance of state-owned central enterprises. Preliminary achievements in the field of artificial intelligence technology
As a professional company for China Telecom to carry out artificial intelligence business, Telecom AI Company is a technology-based, capability-based and platform-based enterprise. The company is committed to conquering the core technologies of artificial intelligence, researching cutting-edge technologies and promoting the expansion of industrial space, aiming to become a tens of billions-level artificial intelligence service provider. In the past two years, Telecom AI Company has successfully independently developed a series of innovative application results, such as the Galaxy AI Algorithm Warehouse Empowerment Platform, the Nebula AI Level 4 Computing Power Platform, and the Star Universal Basic Large Model. Now, the company has more than 800 employees with an average age of 31 years old, 80% of whom are R&D personnel, and 70% are from major domestic and foreign Internet companies and leading AI companies. In order to accelerate R&D progress in the era of large models, the company has more than 2,500 training cards with equivalent computing power of A100 and more than 300 full-time data annotation personnel. At the same time, the company also cooperates with scientific research institutions such as Shanghai Artificial Intelligence Laboratory, Xi'an Jiaotong University, Beijing University of Posts and Telecommunications, and Zhiyuan Research Institute to jointly create world-class artificial intelligence technology and technology for China Telecom's 60 million video networks and hundreds of millions of user scenarios. Application
Next, we will review and share some important scientific research results achieved by telecom AI companies in 2023. This sharing will introduce the technical achievements of the CV algorithm team of the AI R&D Center that won the Temporal Action Localization track championship in the ICCV 2023 event. ICCV is one of the three top conferences in the field of international computer vision. It is held every two years and has a high reputation in the industry. This article will share the algorithmic ideas and solutions adopted by the team in this challenge
ICCV 2023 Perception Test Challenge-Time Action Positioning Champion Technology Sharing

Game Overview and Team Background
The ICCV 2023 first perceptual testing challenge launched by DeepMind aims to evaluate the model’s capabilities in video, audio and text modalities. The competition covers four skill areas, four reasoning types, and six computational tasks to comprehensively evaluate the capabilities of multimodal perception models. Among them, the core task of the Temporal Action Localization track is to conduct in-depth understanding and accurate action positioning of unedited video content. This technology is of great significance to various application scenarios such as autonomous driving systems and video surveillance analysis.
In this competition, the participating team is composed of members from the traffic algorithm direction of Telecom AI Company. The team is called CTCV. Telecom AI companies have conducted in-depth research in the field of computer vision technology and accumulated rich experience. Its technological achievements have been widely used in many business fields such as urban governance and traffic security, and continue to serve a large number of users
The introduction is the beginning of an article and is intended to interest the reader and provide background information. A good introduction grabs the reader's attention, summarizes the topic of the article, and inspires the reader to continue reading. When writing an introduction, you need to pay attention to concise and clear language and accurate and powerful content. The purpose of the introduction is to guide the reader into the topic of the article, so it is necessary to cite relevant facts, data or thought-provoking questions. In short, the introduction is the gateway to the article and can determine whether the reader continues reading
A challenging problem in video understanding is the task of localizing and classifying actions in videos, namely Temporal Action Localization (TAL)
TAL technology has made significant progress recently. For example, TadTR and ReAct adopt a Transformer-based decoder similar to DETR for action detection, modeling action instances as a learnable set. TallFormer uses a Transformer-based encoder to extract video representation
Although the above methods have achieved good results in temporal action positioning, there are some limitations in video perception capabilities. To better localize action instances, reliable video feature representation is key. Our team first adopted the VideoMAE-v2 framework, added an adapter linear layer, trained an action category prediction model with two different backbone networks, and used the previous layer of the model classification layer to extract features for the TAL task. Next, we trained the TAL task using the improved ActionFormer framework and modified the WBF method to adapt to the TAL task. In the end, our method achieved an mAP of 0.50 on the evaluation set, ranking first, 3 percentage points ahead of the second-place team, and 34 percentage points higher than the baseline model provided by Google DeepMind
2 Competition Solution
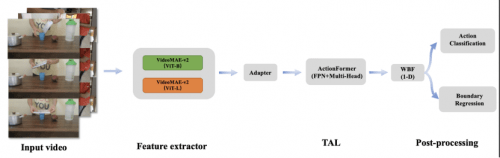
The algorithm overview is shown below:
2.1 Data enhancement
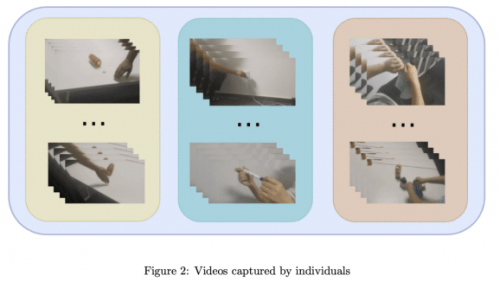
In the Temporal Action Localization track, the data set used by the CTCV team is an untrimmed video for action localization, has high resolution, and contains the characteristics of multiple action instances. By analyzing the data set, it was found that the training set lacked three category labels compared to the validation set. In order to ensure the adequacy of model verification and meet the requirements of the competition, the team collected a small amount of video data and added it to the training data set to enrich the training samples. At the same time, in order to simplify the annotation process, each video preset only contains one action
Please refer to the self-collected video sample in Figure 2
2.2 Action recognition and feature extraction
In recent years, many basic models based on large-scale data training have emerged. These models apply the powerful generalization capabilities of the basic models to multiple downstream tasks through methods such as zero-sample recognition, linear detection, prompt fine-tuning, and fine-tuning. , effectively promoting progress in many aspects of the field of artificial intelligence
Motion localization and recognition in TAL tracks are very challenging. For example, the two actions of "pretend to tear something into pieces" and "tear something into pieces" are very similar, which undoubtedly brings greater challenges to the feature level. Therefore, the effect of directly using existing pre-trained models to extract features is not ideal
Therefore, our team converted the TAL data set into an action recognition data set by parsing the JSON annotation file. Then, we use Vit-B and Vit-L as the backbone networks, add an adapter layer and a linear layer for classification after the VideoMAE-v2 network, and train action classifiers in the same data domain. We also remove the linear layer from the action classification model and use it for video feature extraction. The feature dimension of the VitB model is 768, while the feature dimension of the ViTL model is 1024. When we concat these two features at the same time, we generate a new feature with a dimension of 1792, which will be used as an alternative for training the temporal action localization model. In the early stage of training, we tried audio features, but the experimental results found that the mAP index declined. Therefore, we did not consider audio features
in subsequent experiments2.3 Timing action positioning
Actionformer is an anchor-free model designed with time-ordered action positioning. It incorporates multi-scale features and local self-attention in the temporal dimension. In this competition, the CTCV team selected Actionformer as the benchmark model for action positioning, which is used to predict the boundaries (start and end times) and categories of action
CTCV team unified processing of action boundary regression and action classification tasks. Relative to the baseline training structure, video features are first encoded into a multi-scale Transformer. Then a feature pyramid layer is introduced in the head branch of the model's regression and classification to enhance the network's feature expression ability. The head branch of each time step generates an action candidate. At the same time, by increasing the number of heads to 32 and introducing the fpn1D structure, the positioning and identification capabilities of the model are further improved
1-D’s 2.4 WBF
Weighted Boxes Fusion (WBF) is an innovative detection frame fusion method. This method uses the confidence of all detection frames to construct the final prediction frame, and shows good results in image target detection. Unlike NMS and soft-NMS methods, weighted box fusion does not discard any predictions, but utilizes the confidence scores of all proposed bounding boxes to construct an average box. This method greatly improves the accuracy of predicting rectangles
Inspired by WBF, the CTCV team analogized the one-dimensional bounding box of the action to a one-dimensional line segment and modified the WBF method to make it suitable for the TAL task. The experimental results show the effectiveness of this method, as shown in Figure 3
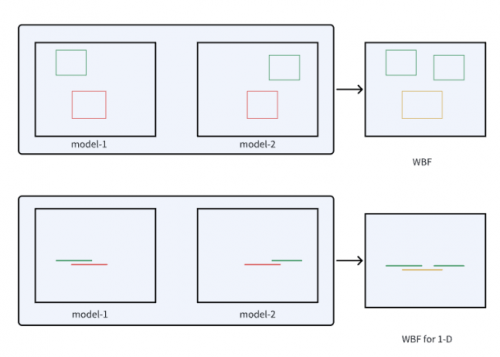
The improved one-dimensional WBF diagram is shown in Figure 3
3 Experimental results
3.1 Evaluation indicators. Evaluation Criteria
The evaluation indicator is mAP, which is used for this challenge. mAP is determined by calculating the average accuracy across different action categories and IoU thresholds. The CTCV team evaluates IoU thresholds in 0.1 increments, ranging from 0.1 to 0.5
3.2 The experimental details are rewritten as follows:
In order to obtain a diverse model, the CTCV team resampled 80% of the training data set, a total of 5 times. The features of Vit-B, Vit-L and concat were used for model training, and 15 diverse models were successfully obtained. Finally, the evaluation results of these models are input to the WBF module, and the same fusion weight is assigned to each model result
The experimental results are as follows:
Performance comparison of different features is shown in Table 1. The first and second rows show the results using ViT-B and ViT-L features. The third row shows the results of ViT-B and ViT-L feature cascade
During the experiment, the CTCV team found that the average precision (mAP) of the cascade features was slightly lower than ViT-L, but still better than ViT-B. Nevertheless, through the performance of various methods on the verification set, we fused the prediction results of different features in the evaluation set with the help of WBF, and the mAP finally submitted to the system was 0.50
The content that needs to be rewritten is: 4 Conclusion
The CTCV team adopted a number of strategies to improve performance in this competition. First, they augmented the training data with missing classes in the validation set through data collection. Secondly, they used the VideoMAE-v2 framework to add an adapter layer to train the video feature extractor, and trained the TAL task through the improved ActionFormer framework. Furthermore, they modified the WBF method to fuse the test results efficiently. In the end, the CTCV team achieved an mAP of 0.50 on the evaluation set, ranking first. Telecom AI companies have always adhered to the development philosophy of "technology comes from business and goes to business". They regard competitions as an important platform to test and improve technical capabilities, and continue to optimize and improve technical solutions through participating in competitions to provide customers with higher-quality services. At the same time, participating in the competition also provides valuable learning and growth opportunities for team members
The above is the detailed content of 2023 Telecom AI Company Summit Papers and Competition Sharing. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Replit Agent: A Guide With Practical Examples
Mar 04, 2025 am 10:52 AM
Replit Agent: A Guide With Practical Examples
Mar 04, 2025 am 10:52 AM
Revolutionizing App Development: A Deep Dive into Replit Agent Tired of wrestling with complex development environments and obscure configuration files? Replit Agent aims to simplify the process of transforming ideas into functional apps. This AI-p
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 How to Use DALL-E 3: Tips, Examples, and Features
Mar 09, 2025 pm 01:00 PM
How to Use DALL-E 3: Tips, Examples, and Features
Mar 09, 2025 pm 01:00 PM
DALL-E 3: A Generative AI Image Creation Tool Generative AI is revolutionizing content creation, and DALL-E 3, OpenAI's latest image generation model, is at the forefront. Released in October 2023, it builds upon its predecessors, DALL-E and DALL-E 2
 Elon Musk & Sam Altman Clash over $500 Billion Stargate Project
Mar 08, 2025 am 11:15 AM
Elon Musk & Sam Altman Clash over $500 Billion Stargate Project
Mar 08, 2025 am 11:15 AM
The $500 billion Stargate AI project, backed by tech giants like OpenAI, SoftBank, Oracle, and Nvidia, and supported by the U.S. government, aims to solidify American AI leadership. This ambitious undertaking promises a future shaped by AI advanceme
 5 Grok 3 Prompts that Can Make Your Work Easy
Mar 04, 2025 am 10:54 AM
5 Grok 3 Prompts that Can Make Your Work Easy
Mar 04, 2025 am 10:54 AM
Grok 3 – Elon Musk and xAi’s latest AI model is the talk of the town these days. From Andrej Karpathy to tech influencers, everyone is talking about the capabilities of this new model. Initially, access was limited to
 Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google DeepMind's GenCast: A Revolutionary AI for Weather Forecasting Weather forecasting has undergone a dramatic transformation, moving from rudimentary observations to sophisticated AI-powered predictions. Google DeepMind's GenCast, a groundbreak
