

How Java thread pool works

| Introduction | The concept of "pool" is not uncommon in our development. There are database connection pools, thread pools, object pools, constant pools, etc. Below we mainly focus on the thread pool to uncover the veil of the thread pool step by step. |
1. Reduce resource consumption
You can reuse created threads to reduce the consumption caused by thread creation and destruction.
2. Improve response speed
When a task arrives, the task can be executed immediately without waiting for the thread to be created.
3. Improve thread manageability
Threads are scarce resources. If they are created without restrictions, they will not only consume system resources, but also reduce the stability of the system. The thread pool can be used for unified allocation, tuning and monitoring
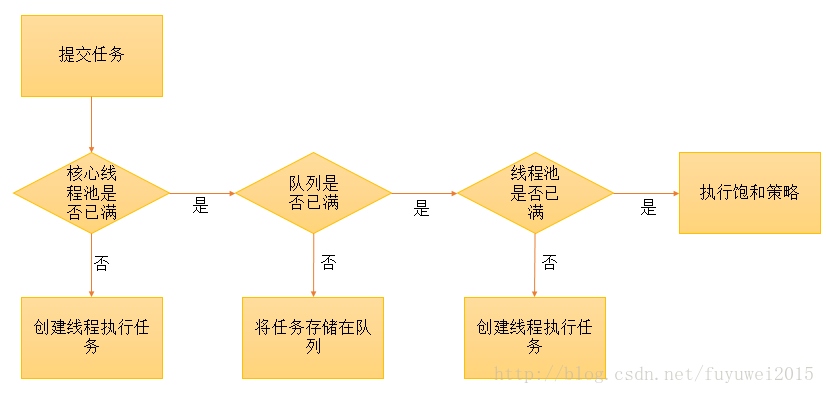
How thread pool worksFirst let's take a look at how the thread pool handles a new task after it is submitted to the thread pool
1. The thread pool determines whether all threads in the core thread pool are executing tasks. If not, a new worker thread is created to perform the task. If all threads in the core thread pool are executing tasks, perform the second step.
2. The thread pool determines whether the work queue is full. If the work queue is not full, newly submitted tasks are stored in this work queue and waited. If the work queue is full, execute the third step
3. The thread pool determines whether all threads in the thread pool are in working status. If not, a new worker thread is created to perform the task. If it is full, hand it over to the saturation strategy to handle this task
Thread pool saturation strategyThe saturation strategy of the thread pool is mentioned here, so let’s briefly introduce the saturation strategies:
AbortPolicy
is the default blocking strategy of the Java thread pool. This task is not executed and a runtime exception is thrown directly. Remember that ThreadPoolExecutor.execute requires try catch, otherwise the program will exit directly.
DiscardPolicy
Abandon it directly, the task will not be executed, empty method
DiscardOldestPolicy
Discard a task of head from the queue and execute the task again.
CallerRunsPolicy
Executing this command in the thread that calls execute will block the entry
User-defined rejection policy (most commonly used)
Implement RejectedExecutionHandler and define your own strategy mode
Let’s take ThreadPoolExecutor as an example to show the workflow diagram of the thread pool
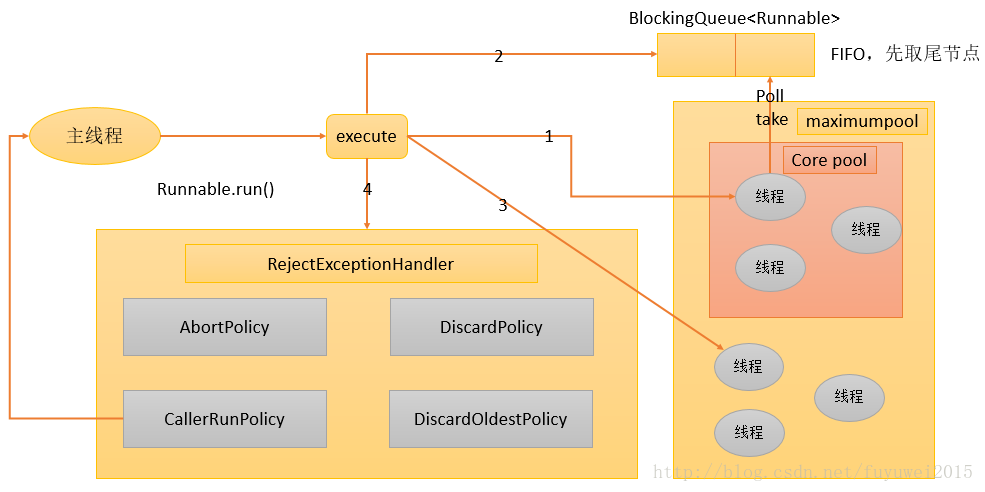
1. If the number of currently running threads is less than corePoolSize, create a new thread to perform the task (note that you need to obtain a global lock to perform this step).
2. If the running threads are equal to or more than corePoolSize, add the task to BlockingQueue.
3. If the task cannot be added to the BlockingQueue (the queue is full), create a new thread in a non-corePool to process the task (note that you need to obtain a global lock to perform this step).
4. If creating a new thread will cause the currently running thread to exceed maximumPoolSize, the task will be rejected and the RejectedExecutionHandler.rejectedExecution() method will be called.
The overall design idea of ThreadPoolExecutor taking the above steps is to avoid acquiring global locks as much as possible when executing the execute() method (that will be a serious scalability bottleneck). After ThreadPoolExecutor completes warm-up (the number of currently running threads is greater than or equal to corePoolSize), almost all execute() method calls execute step 2, and step 2 does not require acquiring a global lock.
Key method source code analysisLet’s take a look at the source code of the core method added to the thread pool method execute as follows:
//
//Executes the given task sometime in the future. The task
//may execute in a new thread or in an existing pooled thread.
//
// If the task cannot be submitted for execution, either because this
// executor has been shutdown or because its capacity has been reached,
// the task is handled by the current {@code RejectedExecutionHandler}.
//
// @param command the task to execute
// @throws RejectedExecutionException at discretion of
// {@code RejectedExecutionHandler}, if the task
// cannot be accepted for execution
// @throws NullPointerException if {@code command} is null
//
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//
// Proceed in 3 steps:
//
// 1. If fewer than corePoolSize threads are running, try to
// start a new thread with the given command as its first
// task. The call to addWorker atomically checks runState and
// workerCount, and so prevents false alarms that would add
// threads when it shouldn't, by returning false.
// 翻译如下:
// 判断当前的线程数是否小于corePoolSize如果是,使用入参任务通过addWord方法创建一个新的线程,
// 如果能完成新线程创建exexute方法结束,成功提交任务
// 2. If a task can be successfully queued, then we still need
// to double-check whether we should have added a thread
// (because existing ones died since last checking) or that
// the pool shut down since entry into this method. So we
// recheck state and if necessary roll back the enqueuing if
// stopped, or start a new thread if there are none.
// 翻译如下:
// 在第一步没有完成任务提交;状态为运行并且能否成功加入任务到工作队列后,再进行一次check,如果状态
// 在任务加入队列后变为了非运行(有可能是在执行到这里线程池shutdown了),非运行状态下当然是需要
// reject;然后再判断当前线程数是否为0(有可能这个时候线程数变为了0),如是,新增一个线程;
// 3. If we cannot queue task, then we try to add a new
// thread. If it fails, we know we are shut down or saturated
// and so reject the task.
// 翻译如下:
// 如果不能加入任务到工作队列,将尝试使用任务新增一个线程,如果失败,则是线程池已经shutdown或者线程池
// 已经达到饱和状态,所以reject这个他任务
//
int c = ctl.get();
// 工作线程数小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 直接启动新线程,true表示会再次检查workerCount是否小于corePoolSize
if (addWorker(command, true))
return;
c = ctl.get();
}
// 如果工作线程数大于等于核心线程数
// 线程的的状态未RUNNING并且队列notfull
if (isRunning(c) && workQueue.offer(command)) {
// 再次检查线程的运行状态,如果不是RUNNING直接从队列中移除
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
// 移除成功,拒绝该非运行的任务
reject(command);
else if (workerCountOf(recheck) == 0)
// 防止了SHUTDOWN状态下没有活动线程了,但是队列里还有任务没执行这种特殊情况。
// 添加一个null任务是因为SHUTDOWN状态下,线程池不再接受新任务
addWorker(null, false);
}
// 如果队列满了或者是非运行的任务都拒绝执行
else if (!addWorker(command, false))
reject(command);
}Let’s continue to see how addWorker is implemented:
private boolean addWorker(Runnable firstTask, boolean core) {
// java标签
retry:
// 死循环
for (;;) {
int c = ctl.get();
// 获取当前线程状态
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 这个逻辑判断有点绕可以改成
// rs >= shutdown && (rs != shutdown || firstTask != null || workQueue.isEmpty())
// 逻辑判断成立可以分为以下几种情况均不接受新任务
// 1、rs > shutdown:--不接受新任务
// 2、rs >= shutdown && firstTask != null:--不接受新任务
// 3、rs >= shutdown && workQueue.isEmppty:--不接受新任务
// 逻辑判断不成立
// 1、rs==shutdown&&firstTask != null:此时不接受新任务,但是仍会执行队列中的任务
// 2、rs==shotdown&&firstTask == null:会执行addWork(null,false)
// 防止了SHUTDOWN状态下没有活动线程了,但是队列里还有任务没执行这种特殊情况。
// 添加一个null任务是因为SHUTDOWN状态下,线程池不再接受新任务
if (rs >= SHUTDOWN &&! (rs == SHUTDOWN && firstTask == null &&! workQueue.isEmpty()))
return false;
// 死循环
// 如果线程池状态为RUNNING并且队列中还有需要执行的任务
for (;;) {
// 获取线程池中线程数量
int wc = workerCountOf(c);
// 如果超出容量或者最大线程池容量不在接受新任务
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 线程安全增加工作线程数
if (compareAndIncrementWorkerCount(c))
// 跳出retry
break retry;
c = ctl.get(); // Re-read ctl
// 如果线程池状态发生变化,重新循环
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 走到这里说明工作线程数增加成功
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock;
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
int rs = runStateOf(c);
// RUNNING状态 || SHUTDONW状态下清理队列中剩余的任务
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 检查线程状态
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// 将新启动的线程添加到线程池中
workers.add(w);
// 更新线程池线程数且不超过最大值
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 启动新添加的线程,这个线程首先执行firstTask,然后不停的从队列中取任务执行
if (workerAdded) {
//执行ThreadPoolExecutor的runWoker方法
t.start();
workerStarted = true;
}
}
} finally {
// 线程启动失败,则从wokers中移除w并递减wokerCount
if (! workerStarted)
// 递减wokerCount会触发tryTerminate方法
addWorkerFailed(w);
}
return workerStarted;
}AddWorker is followed by runWorker. When it is started for the first time, it will execute the task firstTask passed in during initialization; then it will take the task from the workQueue and execute it. If the queue is empty, it will wait for as long as keepAliveTime
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 允许中断
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 如果getTask返回null那么getTask中会将workerCount递减,如果异常了这个递减操作会在processWorkerExit中处理
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}Let’s see how getTask is executed
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
// 死循环
retry: for (;;) {
// 获取线程池状态
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 1.rs > SHUTDOWN 所以rs至少等于STOP,这时不再处理队列中的任务
// 2.rs = SHUTDOWN 所以rs>=STOP肯定不成立,这时还需要处理队列中的任务除非队列为空
// 这两种情况都会返回null让runWoker退出while循环也就是当前线程结束了,所以必须要decrement
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
// 递减workerCount值
decrementWorkerCount();
return null;
}
// 标记从队列中取任务时是否设置超时时间
boolean timed; // Are workers subject to culling?
// 1.RUNING状态
// 2.SHUTDOWN状态,但队列中还有任务需要执行
for (;;) {
int wc = workerCountOf(c);
// 1.core thread允许被超时,那么超过corePoolSize的的线程必定有超时
// 2.allowCoreThreadTimeOut == false && wc >
// corePoolSize时,一般都是这种情况,core thread即使空闲也不会被回收,只要超过的线程才会
timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 从addWorker可以看到一般wc不会大于maximumPoolSize,所以更关心后面半句的情形:
// 1. timedOut == false 第一次执行循环, 从队列中取出任务不为null方法返回 或者
// poll出异常了重试
// 2.timeOut == true && timed ==
// false:看后面的代码workerQueue.poll超时时timeOut才为true,
// 并且timed要为false,这两个条件相悖不可能同时成立(既然有超时那么timed肯定为true)
// 所以超时不会继续执行而是return null结束线程。
if (wc <= maximumPoolSize && !(timedOut && timed))
break;
// workerCount递减,结束当前thread
if (compareAndDecrementWorkerCount(c))
return null;
c = ctl.get(); // Re-read ctl
// 需要重新检查线程池状态,因为上述操作过程中线程池可能被SHUTDOWN
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
try {
// 1.以指定的超时时间从队列中取任务
// 2.core thread没有超时
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null)
return r;
timedOut = true;// 超时
} catch (InterruptedException retry) {
timedOut = false;// 线程被中断重试
}
}
}Let’s take a look at how processWorkerExit works
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// 正常的话再runWorker的getTask方法workerCount已经被减一了
if (completedAbruptly)
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 累加线程的completedTasks
completedTaskCount += w.completedTasks;
// 从线程池中移除超时或者出现异常的线程
workers.remove(w);
} finally {
mainLock.unlock();
}
// 尝试停止线程池
tryTerminate();
int c = ctl.get();
// runState为RUNNING或SHUTDOWN
if (runStateLessThan(c, STOP)) {
// 线程不是异常结束
if (!completedAbruptly) {
// 线程池最小空闲数,允许core thread超时就是0,否则就是corePoolSize
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果min == 0但是队列不为空要保证有1个线程来执行队列中的任务
if (min == 0 && !workQueue.isEmpty())
min = 1;
// 线程池还不为空那就不用担心了
if (workerCountOf(c) >= min)
return; // replacement not needed
}
// 1.线程异常退出
// 2.线程池为空,但是队列中还有任务没执行,看addWoker方法对这种情况的处理
addWorker(null, false);
}
}tryTerminate
The processWorkerExit method will try to call tryTerminate to terminate the thread pool. This method is executed after any action that may cause the thread pool to terminate: such as reducing the wokerCount or removing tasks from the queue in the SHUTDOWN state.
final void tryTerminate() {
for (;;) {
int c = ctl.get();
// 以下状态直接返回:
// 1.线程池还处于RUNNING状态
// 2.SHUTDOWN状态但是任务队列非空
// 3.runState >= TIDYING 线程池已经停止了或在停止了
if (isRunning(c) || runStateAtLeast(c, TIDYING) || (runStateOf(c) == SHUTDOWN && !workQueue.isEmpty()))
return;
// 只能是以下情形会继续下面的逻辑:结束线程池。
// 1.SHUTDOWN状态,这时不再接受新任务而且任务队列也空了
// 2.STOP状态,当调用了shutdownNow方法
// workerCount不为0则还不能停止线程池,而且这时线程都处于空闲等待的状态
// 需要中断让线程“醒”过来,醒过来的线程才能继续处理shutdown的信号。
if (workerCountOf(c) != 0) { // Eligible to terminate
// runWoker方法中w.unlock就是为了可以被中断,getTask方法也处理了中断。
// ONLY_ONE:这里只需要中断1个线程去处理shutdown信号就可以了。
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 进入TIDYING状态
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 子类重载:一些资源清理工作
terminated();
} finally {
// TERMINATED状态
ctl.set(ctlOf(TERMINATED, 0));
// 继续awaitTermination
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}shutdown This method will set runState to SHUTDOWN and terminate all idle threads. The shutdownNow method sets runState to STOP. The difference from the shutdown method is that this method will terminate all threads. The main difference is that shutdown calls the interruptIdleWorkers method, while shutdownNow actually calls the interruptIfStarted method of the Worker class:
Their implementation is as follows:
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 线程池状态设为SHUTDOWN,如果已经至少是这个状态那么则直接返回
advanceRunState(SHUTDOWN);
// 注意这里是中断所有空闲的线程:runWorker中等待的线程被中断 → 进入processWorkerExit →
// tryTerminate方法中会保证队列中剩余的任务得到执行。
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// STOP状态:不再接受新任务且不再执行队列中的任务。
advanceRunState(STOP);
// 中断所有线程
interruptWorkers();
// 返回队列中还没有被执行的任务。
tasks = drainQueue();
}
finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
// w.tryLock能获取到锁,说明该线程没有在运行,因为runWorker中执行任务会先lock,
// 因此保证了中断的肯定是空闲的线程。
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
}
finally {
mainLock.unlock();
}
}
void interruptIfStarted() {
Thread t;
// 初始化时state == -1
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}We can create a thread pool through ThreadPoolExecutor
/**
* @param corePoolSize 线程池基本大小,核心线程池大小,活动线程小于corePoolSize则直接创建,大于等于则先加到workQueue中,
* 队列满了才创建新的线程。当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,
* 等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,
* 线程池会提前创建并启动所有基本线程。
* @param maximumPoolSize 最大线程数,超过就reject;线程池允许创建的最大线程数。如果队列满了,
* 并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务
* @param keepAliveTime
* 线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率
* @param unit 线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、
* 毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微秒)
* @param workQueue 工作队列,线程池中的工作线程都是从这个工作队列源源不断的获取任务进行执行
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
// threadFactory用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}可以使用两个方法向线程池提交任务,分别为execute()和submit()方法。execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。通过以下代码可知execute()方法输入的任务是一个Runnable类的实例。
threadsPool.execute(new Runnable() {
@Override
public void run() {
}
});submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
Future<Object> future = executor.submit(harReturnValuetask);
try
{
Object s = future.get();
}catch(
InterruptedException e)
{
// 处理中断异常
}catch(
ExecutionException e)
{
// 处理无法执行任务异常
}finally
{
// 关闭线程池
executor.shutdown();
}可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
合理的配置线程池要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
1、任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
2、任务的优先级:高、中和低。
3、任务的执行时间:长、中和短。
4、任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行
如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
It is recommended to use bounded queue. Bounded queues can increase the stability and early warning capabilities of the system, and can be set larger as needed, such as several thousand. Sometimes the queue and thread pool of the background task thread pool in our system are full, and exceptions of abandoned tasks are constantly thrown. Through troubleshooting, it is found that there is a problem with the database, causing the execution of SQL to become very slow, because the background task thread pool has All tasks require querying and inserting data into the database, so all working threads in the thread pool are blocked and tasks are backlogged in the thread pool. If we set it to an unbounded queue at that time, there would be more and more queues in the thread pool, which might fill up the memory, causing the entire system to be unavailable, not just background tasks. Of course, all tasks in our system are deployed on separate servers, and we use thread pools of different sizes to complete different types of tasks, but when such problems occur, other tasks will also be affected.
Thread pool monitoringIf a large number of thread pools are used in the system, it is necessary to monitor the thread pool so that when a problem occurs, the problem can be quickly located based on the usage of the thread pool. It can be monitored through the parameters provided by the thread pool. When monitoring the thread pool, you can use the following attributes
- taskCount: The number of tasks that the thread pool needs to execute.
- completedTaskCount: The number of tasks that the thread pool has completed during operation, which is less than or equal to taskCount.
- largestPoolSize: The maximum number of threads ever created in the thread pool. Through this data, you can know whether the thread pool has ever been full. If this value is equal to the maximum size of the thread pool, it means that the thread pool has been full.
- getPoolSize: The number of threads in the thread pool. If the thread pool is not destroyed, the threads in the thread pool will not be automatically destroyed, so the size will only increase but not decrease.
- getActiveCount: Get the number of active threads.
Monitoring by extending the thread pool. You can customize the thread pool by inheriting the thread pool, rewriting the thread pool's beforeExecute, afterExecute, and terminated methods, or you can execute some code for monitoring before, after, and before the thread pool is closed. For example, monitor the average execution time, maximum execution time, and minimum execution time of tasks.
The above is the detailed content of How Java thread pool works. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
The key differences between CentOS and Ubuntu are: origin (CentOS originates from Red Hat, for enterprises; Ubuntu originates from Debian, for individuals), package management (CentOS uses yum, focusing on stability; Ubuntu uses apt, for high update frequency), support cycle (CentOS provides 10 years of support, Ubuntu provides 5 years of LTS support), community support (CentOS focuses on stability, Ubuntu provides a wide range of tutorials and documents), uses (CentOS is biased towards servers, Ubuntu is suitable for servers and desktops), other differences include installation simplicity (CentOS is thin)
 Centos options after stopping maintenance
Apr 14, 2025 pm 08:51 PM
Centos options after stopping maintenance
Apr 14, 2025 pm 08:51 PM
CentOS has been discontinued, alternatives include: 1. Rocky Linux (best compatibility); 2. AlmaLinux (compatible with CentOS); 3. Ubuntu Server (configuration required); 4. Red Hat Enterprise Linux (commercial version, paid license); 5. Oracle Linux (compatible with CentOS and RHEL). When migrating, considerations are: compatibility, availability, support, cost, and community support.
 How to install centos
Apr 14, 2025 pm 09:03 PM
How to install centos
Apr 14, 2025 pm 09:03 PM
CentOS installation steps: Download the ISO image and burn bootable media; boot and select the installation source; select the language and keyboard layout; configure the network; partition the hard disk; set the system clock; create the root user; select the software package; start the installation; restart and boot from the hard disk after the installation is completed.
 How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use Docker Desktop? Docker Desktop is a tool for running Docker containers on local machines. The steps to use include: 1. Install Docker Desktop; 2. Start Docker Desktop; 3. Create Docker image (using Dockerfile); 4. Build Docker image (using docker build); 5. Run Docker container (using docker run).
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to view the docker process
Apr 15, 2025 am 11:48 AM
How to view the docker process
Apr 15, 2025 am 11:48 AM
Docker process viewing method: 1. Docker CLI command: docker ps; 2. Systemd CLI command: systemctl status docker; 3. Docker Compose CLI command: docker-compose ps; 4. Process Explorer (Windows); 5. /proc directory (Linux).
 What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 What to do if the docker image fails
Apr 15, 2025 am 11:21 AM
What to do if the docker image fails
Apr 15, 2025 am 11:21 AM
Troubleshooting steps for failed Docker image build: Check Dockerfile syntax and dependency version. Check if the build context contains the required source code and dependencies. View the build log for error details. Use the --target option to build a hierarchical phase to identify failure points. Make sure to use the latest version of Docker engine. Build the image with --t [image-name]:debug mode to debug the problem. Check disk space and make sure it is sufficient. Disable SELinux to prevent interference with the build process. Ask community platforms for help, provide Dockerfiles and build log descriptions for more specific suggestions.
