
 Technology peripherals
AI
Large model + robot, a detailed review report is here, with the participation of many Chinese scholars
Technology peripherals
AI
Large model + robot, a detailed review report is here, with the participation of many Chinese scholars
Large model + robot, a detailed review report is here, with the participation of many Chinese scholars

The outstanding capabilities of large models are obvious to all, and if they are integrated into robots, it is expected that robots will have a more intelligent brain, bringing new possibilities to the field of robotics, such as autonomous driving, home robots, industrial robots, and assistance Robots, medical robots, field robots and multi-robot systems.
Pre-trained Large Language Model (LLM), Large Vision-Language Model (VLM), Large Audio-Language Model (ALM) and Large Visual Navigation Model (VNM) can be used to better handle robots various tasks in the field. Integrating basic models into robotics is a rapidly growing field, and the robotics community has recently begun to explore the use of these large models in robotics areas that need to be rewritten: perception, prediction, planning, and control.
Recently, a joint research team composed of Stanford University, Princeton University, NVIDIA, Google DeepMind and other companies released a review report summarizing the development and future of basic models in the field of robotics research. Challenge

Paper address: https://arxiv.org/pdf/2312.07843.pdf
The rewritten content is: Paper library: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
There are many Chinese scholars we are familiar with among the team members , including Zhu Yuke, Song Shuran, Wu Jiajun, Lu Cewu, etc.
The basic model is extensively pre-trained using large-scale data and can be applied to various downstream tasks after fine-tuning. These basic models have made major breakthroughs in the fields of vision and language processing, including related models such as BERT, GPT-3, GPT-4, CLIP, DALL-E and PaLM-E
Before the emergence of the basic models, Traditional deep learning models for robotics are trained using limited data sets collected for different tasks. In contrast, base models are pre-trained using a wide range of diverse data and have demonstrated adaptability, generalization, and overall performance in other areas such as natural language processing, computer vision, and healthcare. Eventually, the basic model is also expected to show its potential in the field of robotics. Figure 1 shows an overview of the basic model in the field of robotics.
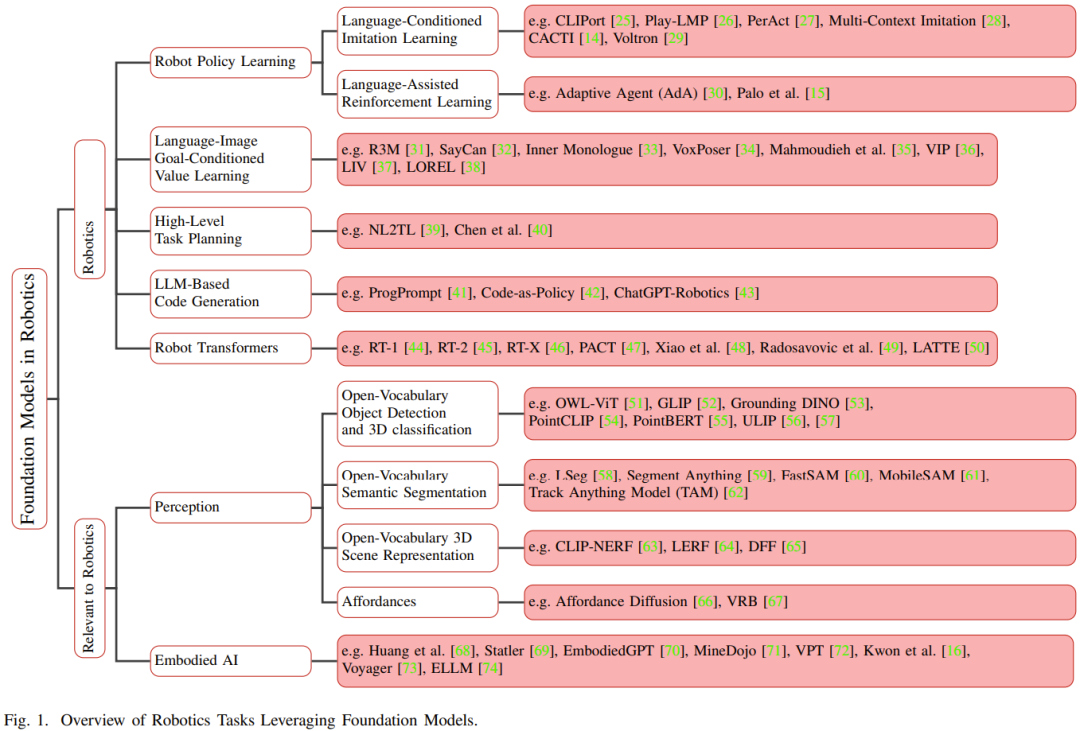
Transferring knowledge from a base model has the potential to reduce training time and computing resources compared to task-specific models. Especially in robotics-related fields, multimodal base models can fuse and align multimodal heterogeneous data collected from different sensors into compact homogeneous representations, which are needed for robot understanding and reasoning. The representations it learns can be used in any part of the automation technology stack, including those that need to be rewritten: perception, decision-making, and control.
Not only that, the basic model can also provide zero-sample learning capabilities, which means that the AI system has the ability to perform tasks without any examples or targeted training. This allows the robot to generalize the knowledge it has learned to new use cases, enhancing the robot's adaptability and flexibility in unstructured environments.
Integrating the basic model into the robot system can improve the robot's ability to perceive the environment and interact with the environment. It is possible to realize the context that needs to be rewritten: the perceptual robot system.
For example, in the field of perception that needs to be rewritten, large-scale visual-language models (VLM) can learn the association between visual and text data, so as to have cross-modal understanding capabilities, thereby assisting zero Tasks such as sample image classification, zero-sample target detection, and 3D classification. As another example, language grounding (i.e., aligning the VLM's contextual understanding with the 3D real world) in the 3D world can enhance the robot's spatial needs by associating utterances with specific objects, locations, or actions in the 3D environment. Rewritten: Perceptual ability. In the field of decision-making or planning, research has found that LLM and VLM can assist robots in specifying tasks involving high-level planning.
By exploiting language cues related to operation, navigation and interaction, robots can perform more complex tasks. For example, for robot policy learning technologies such as imitation learning and reinforcement learning, the basic model seems to have the ability to improve data efficiency and context understanding. In particular, language-driven rewards can guide reinforcement learning agents by providing shaped rewards.
In addition, researchers are already using language models to provide feedback for strategy learning technology. Some studies have shown that the visual question answering (VQA) capabilities of VLM models can be used for robotics use cases. For example, researchers have used VLM to answer questions related to visual content to help robots complete tasks. In addition, some researchers use VLM to help with data annotation and generate description labels for visual content.
Despite the transformative capabilities of the basic model in vision and language processing, generalization and fine-tuning of the basic model for real-world robotic tasks remains challenging.
These challenges include:
1) Lack of data: How to obtain Internet-scale data to support tasks such as robot operation, positioning, and navigation, and how to use these data for self-supervised training;
2) Huge diversity: How to deal with the huge diversity of physical environments, physical robotic platforms, and potential robotic tasks while maintaining the required generality of the underlying model;
3) Uncertain Quantitative issues: How to solve instance-level uncertainties (such as language ambiguity or LLM illusion), distribution-level uncertainties and distribution shift problems, especially the distribution shift problem caused by closed-loop robot deployment.
4) Safety assessment: How to rigorously test the robot system based on the basic model before deployment, during the update process, and during the work process.
5) Real-time performance: How to deal with the long inference time of some basic models - this will hinder the deployment of basic models on robots, and how to accelerate the inference of basic models - this is the key to online decision-making required.
This review paper summarizes the current use of basic models in the field of robotics. The researchers survey current methods, applications, and challenges and propose future research directions to address these challenges. They also pointed out the potential risks that may exist in using the base model to achieve robot autonomy
Background knowledge of the base model
The base model has billions of parameters , and uses Internet-level large-scale data for pre-training. Training such a large and complex model is very expensive. The cost of acquiring, processing and managing data can also be high. Its training process requires a large amount of computing resources, requires the use of dedicated hardware such as GPU or TPU, and also requires software and infrastructure for model training, which all require financial investment. In addition, the training time of the base model is also very long, which also leads to high costs. Therefore, these models are often used as pluggable modules, that is, the base model can be integrated into various applications without extensive customization work
Table 1 gives the details of commonly used base models.
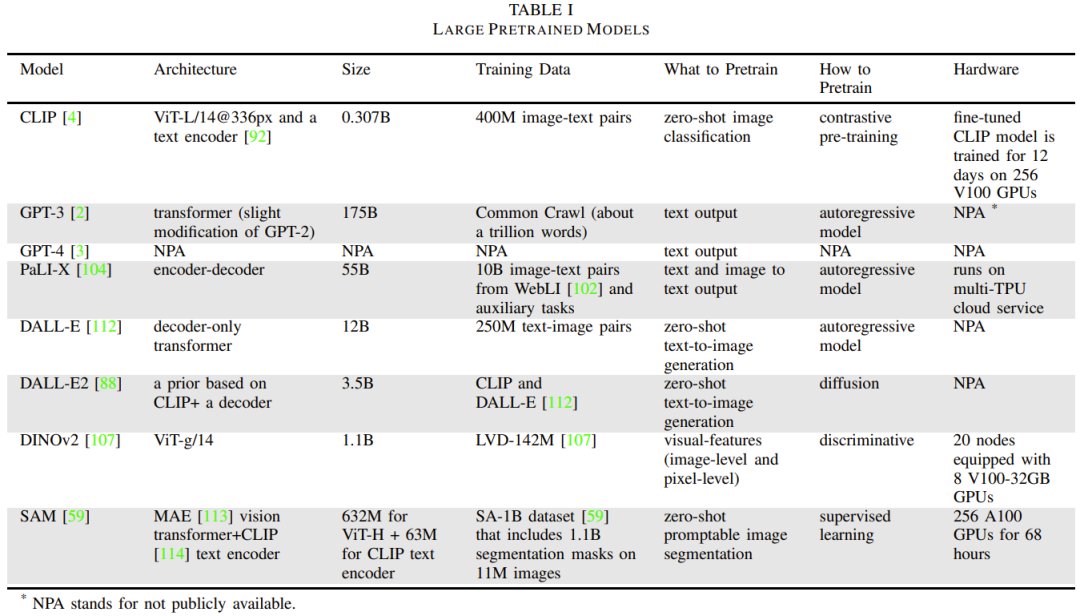
This section will focus on LLM, visual Transformer, VLM, embodied multi-modal language model and visual generative model. In addition, different training methods used to train the base model will also be introduced
They first introduce some related terminology and mathematical knowledge, which involves tokenization, generative models, discriminative models, Transformer architecture, autoregressive models, Masked automatic encoding, contrastive learning, and diffusion models.
They then introduce examples and historical background of large language models (LLMs). Afterwards, the visual Transformer, multimodal vision-language model (VLM), embodied multimodal language model, and visual generation model were highlighted.
Robot Research
This section focuses on robot decision-making, planning and control. In this area, both large language models (LLM) and visual language models (VLM) have the potential to be used to enhance the capabilities of robots. For example, LLM can facilitate the task specification process so that robots can receive and interpret high-level instructions from humans.
VLM is also expected to contribute to this area. VLM excels at analyzing visual data. For robots to make informed decisions and perform complex tasks, visual understanding is crucial. Now, robots can use natural language cues to enhance their ability to perform tasks related to manipulation, navigation, and interaction.
Goal-based visual-linguistic policy learning (whether through imitation learning or reinforcement learning) is expected to be improved by basic models. Language models can also provide feedback for policy learning techniques. This feedback loop helps continuously improve the robot's decision-making capabilities, as the robot can optimize its actions based on the feedback it receives from the LLM.
This section focuses on the application of LLM and VLM in the field of robot decision-making.
This section is divided into six parts. The first part introduces policy learning for decision-making and control and robots, including language-based imitation learning and language-assisted reinforcement learning.
The second part is goal-based language-image value learning.
The third part introduces the use of large-scale language models to plan robot tasks, which includes explaining tasks through language instructions and using language models to generate code for task planning.
The fourth part is contextual learning (ICL) for decision-making.
The next one to introduce is Robot Transformers
The sixth part is the robot navigation and operation of the open vocabulary library.
Table 2 gives some basic robot-specific models, reporting model size and architecture, pre-training tasks, inference time, and hardware setup.
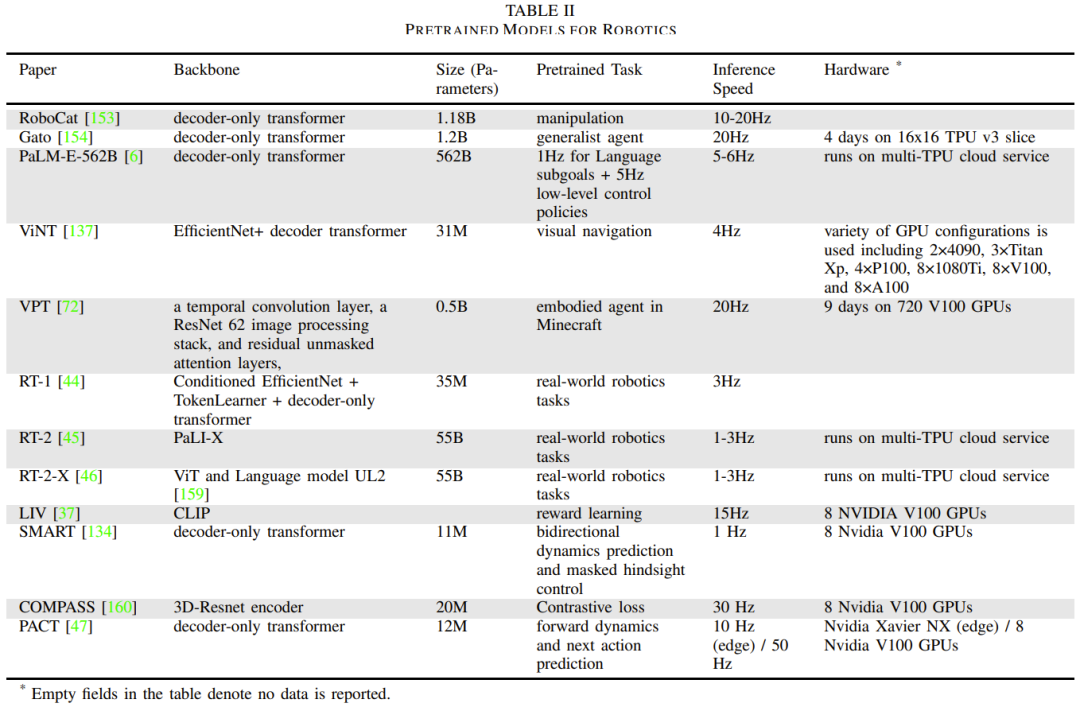
What needs to be rewritten is: perception
Robots that interact with their surrounding environment receive sensory information in different modalities, such as images, videos, audio, and language. This high-dimensional data is critical for robots to understand, reason, and interact with their environment. Basic models can transform these high-dimensional inputs into abstract structured representations that are easy to interpret and manipulate. In particular, multimodal base models allow robots to integrate input from different senses into a unified representation that contains semantic, spatial, temporal, and affordance information. These multimodal models require cross-modal interactions, often requiring alignment of elements from different modalities to ensure consistency and mutual correspondence. For example, image description tasks require alignment of text and image data.
This section will focus on what robots need to rewrite: a series of tasks related to perception that can be improved by using basic models to align modalities. The emphasis is on vision and language.
This section is divided into five parts, first is the target detection and 3D classification of the open vocabulary, then is the semantic segmentation of the open vocabulary, then is the 3D scene and target representation of the open vocabulary, and then are the learned affordances, and finally the predictive model.
Embodied AI
Recently, some studies have shown that LLM can be successfully used in the field of embodied AI, where "embodied" usually refers to the Virtual embodiment in a world simulator rather than having a physical robotic body.
Some interesting frameworks, data sets and models have emerged in this area. Of particular note is the use of the Minecraft game as a platform for training embodied agents. For example, Voyager uses GPT-4 to guide agents exploring Minecraft environments. It can interact with GPT-4 through contextual prompt design without the need to fine-tune GPT-4's model parameters.
Reinforcement learning is an important research direction in the field of robot learning. Researchers are trying to use basic models to design reward functions to optimize reinforcement learning
For robots to perform high-level planning, researchers have been Use basic models to assist in exploration. In addition, some researchers are trying to apply thinking chain-based reasoning and action generation methods to embodied intelligence
Challenges and future directions
This section will Challenges associated with using base models for robotics are given. The team will also explore future research directions that may address these challenges.
The first challenge is to overcome the data scarcity issue when training base models for robots, including:
1. Using unstructured game data and unlabeled human videos To expand robot learning
2. Use image inpainting (Inpainting) to enhance data
3. Overcome the problem of lack of 3D data when training 3D basic models
4. By High-fidelity simulation to generate synthetic data
5. Use VLM for data augmentation Using VLM for data augmentation is an effective method
6. The physical skills of the robot are limited by the distribution of skills
The second challenge is related to real-time performance, of which the key is the foundation Model inference time.
The third challenge involves the limitations of multimodal representation.
The fourth challenge is how to quantify uncertainty at different levels, such as the instance level and the distribution level. It also involves the problem of how to calibrate and deal with distribution shifts.
The fifth challenge involves security assessment, including security testing before deployment and runtime monitoring and detection of out-of-distribution situations.
The sixth challenge involves how to choose: use an existing base model or build a new base model for the robot?
The seventh challenge involves the high variability in the robot setup.
The eighth challenge is how to benchmark and ensure reproducibility in a robot setting.
For more research details, please refer to the original paper.
The above is the detailed content of Large model + robot, a detailed review report is here, with the participation of many Chinese scholars. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
On August 21, the 2024 World Robot Conference was grandly held in Beijing. SenseTime's home robot brand "Yuanluobot SenseRobot" has unveiled its entire family of products, and recently released the Yuanluobot AI chess-playing robot - Chess Professional Edition (hereinafter referred to as "Yuanluobot SenseRobot"), becoming the world's first A chess robot for the home. As the third chess-playing robot product of Yuanluobo, the new Guoxiang robot has undergone a large number of special technical upgrades and innovations in AI and engineering machinery. For the first time, it has realized the ability to pick up three-dimensional chess pieces through mechanical claws on a home robot, and perform human-machine Functions such as chess playing, everyone playing chess, notation review, etc.
 Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
The start of school is about to begin, and it’s not just the students who are about to start the new semester who should take care of themselves, but also the large AI models. Some time ago, Reddit was filled with netizens complaining that Claude was getting lazy. "Its level has dropped a lot, it often pauses, and even the output becomes very short. In the first week of release, it could translate a full 4-page document at once, but now it can't even output half a page!" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ in a post titled "Totally disappointed with Claude", full of
 At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference being held in Beijing, the display of humanoid robots has become the absolute focus of the scene. At the Stardust Intelligent booth, the AI robot assistant S1 performed three major performances of dulcimer, martial arts, and calligraphy in one exhibition area, capable of both literary and martial arts. , attracted a large number of professional audiences and media. The elegant playing on the elastic strings allows the S1 to demonstrate fine operation and absolute control with speed, strength and precision. CCTV News conducted a special report on the imitation learning and intelligent control behind "Calligraphy". Company founder Lai Jie explained that behind the silky movements, the hardware side pursues the best force control and the most human-like body indicators (speed, load) etc.), but on the AI side, the real movement data of people is collected, allowing the robot to become stronger when it encounters a strong situation and learn to evolve quickly. And agile
 AI hardware adds another member! Rather than replacing mobile phones, can NotePin last longer?
Sep 02, 2024 pm 01:40 PM
AI hardware adds another member! Rather than replacing mobile phones, can NotePin last longer?
Sep 02, 2024 pm 01:40 PM
So far, no product in the AI wearable device track has achieved particularly good results. AIPin, which was launched at MWC24 at the beginning of this year, once the evaluation prototype was shipped, the "AI myth" that was hyped at the time of its release began to be shattered, and it experienced large-scale returns in just a few months; RabbitR1, which also sold well at the beginning, was relatively It's better, but it also received negative reviews similar to "Android cases" when it was delivered in large quantities. Now, another company has entered the AI wearable device track. Technology media TheVerge published a blog post yesterday saying that AI startup Plaud has launched a product called NotePin. Unlike AIFriend, which is still in the "painting" stage, NotePin has now started
 Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Deep integration of vision and robot learning. When two robot hands work together smoothly to fold clothes, pour tea, and pack shoes, coupled with the 1X humanoid robot NEO that has been making headlines recently, you may have a feeling: we seem to be entering the age of robots. In fact, these silky movements are the product of advanced robotic technology + exquisite frame design + multi-modal large models. We know that useful robots often require complex and exquisite interactions with the environment, and the environment can be represented as constraints in the spatial and temporal domains. For example, if you want a robot to pour tea, the robot first needs to grasp the handle of the teapot and keep it upright without spilling the tea, then move it smoothly until the mouth of the pot is aligned with the mouth of the cup, and then tilt the teapot at a certain angle. . this
 ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
At this ACL conference, contributors have gained a lot. The six-day ACL2024 is being held in Bangkok, Thailand. ACL is the top international conference in the field of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and is held annually. ACL has always ranked first in academic influence in the field of NLP, and it is also a CCF-A recommended conference. This year's ACL conference is the 62nd and has received more than 400 cutting-edge works in the field of NLP. Yesterday afternoon, the conference announced the best paper and other awards. This time, there are 7 Best Paper Awards (two unpublished), 1 Best Theme Paper Award, and 35 Outstanding Paper Awards. The conference also awarded 3 Resource Paper Awards (ResourceAward) and Social Impact Award (
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
