
 Technology peripherals
AI
Climbing along the network cable has become a reality, Audio2Photoreal can generate realistic expressions and movements through dialogue
Technology peripherals
AI
Climbing along the network cable has become a reality, Audio2Photoreal can generate realistic expressions and movements through dialogue
Climbing along the network cable has become a reality, Audio2Photoreal can generate realistic expressions and movements through dialogue

When you and your friends are chatting across the cold mobile screen, you have to guess the other person’s tone. When he speaks, his expressions and even actions can appear in your mind. It would obviously be best if you could make a video call, but in actual situations you cannot make video calls at any time.
If you are chatting with a remote friend, it is not through cold screen text or an avatar lacking expressions, but a realistic, dynamic, and expressive digital virtual person. This virtual person can not only perfectly reproduce your friend's smile, eyes, and even subtle body movements. Will you feel more kind and warm? It really embodies the sentence "I will crawl along the network cable to find you."
This is not a science fiction imagination, but a technology that can be realized in reality.
Facial expressions and body movements contain a large amount of information, which will greatly affect the meaning of the content. For example, speaking while looking at the other party all the time will give people a completely different feeling than speaking without making eye contact, which will also affect the other party's understanding of the communication content. We have an extremely keen ability to detect these subtle expressions and movements during communication and use them to develop a high-level understanding of the conversation partner's intention, comfort level, or understanding. Therefore, developing highly realistic conversational avatars that capture these subtleties is critical for interaction.
To this end, Meta and researchers from the University of California have proposed a method to generate realistic virtual humans based on the speech audio of a conversation between two people. It can synthesize a variety of high-frequency gestures and expressive facial movements that are closely synchronized with speech. For the body and hand, they exploit the advantages of an autoregressive VQ-based approach and a diffusion model. For faces, they use a diffusion model conditioned on audio. The predicted facial, body, and hand movements are then rendered into realistic virtual humans. We demonstrate that adding guided gesture conditions to the diffusion model can generate more diverse and reasonable conversational gestures than previous works.

- Paper address: https://huggingface.co/papers/2401.01885
- Project address: https://people.eecs.berkeley.edu/~evonne_ng/projects/audio2photoreal/
The researchers say they are the first team to study how to generate realistic facial, body and hand movements for interpersonal conversations. Compared with previous studies, the researchers synthesized more realistic and diverse actions based on VQ and diffusion methods.
Method Overview
The researchers extracted latent expression codes from recorded multi-view data to represent faces and used joint angles in the kinematic skeleton to express body posture. As shown in Figure 3, this system consists of two generative models, which generate expression codes and body posture sequences when inputting two-person conversation audio. The expression code and body pose sequences can then be rendered frame by frame using the Neural Avatar Renderer, which can generate a fully textured avatar with face, body and hands from a given camera view.
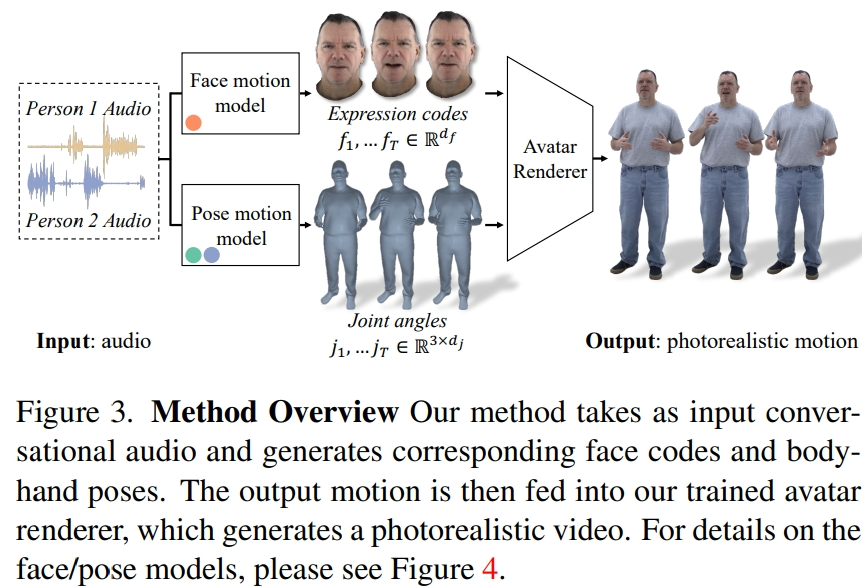
It should be noted that the dynamics of the body and face are very different. First, faces are strongly correlated with input audio, especially lip movements, while bodies are weakly correlated with speech. This results in a more complex diversity of body gestures in a given speech input. Second, since faces and bodies are represented in two different spaces, they each follow different temporal dynamics. Therefore, the researchers used two independent motion models to simulate the face and body. In this way, the face model can "focus" on facial details that are consistent with speech, while the body model can focus more on generating diverse but reasonable body movements.
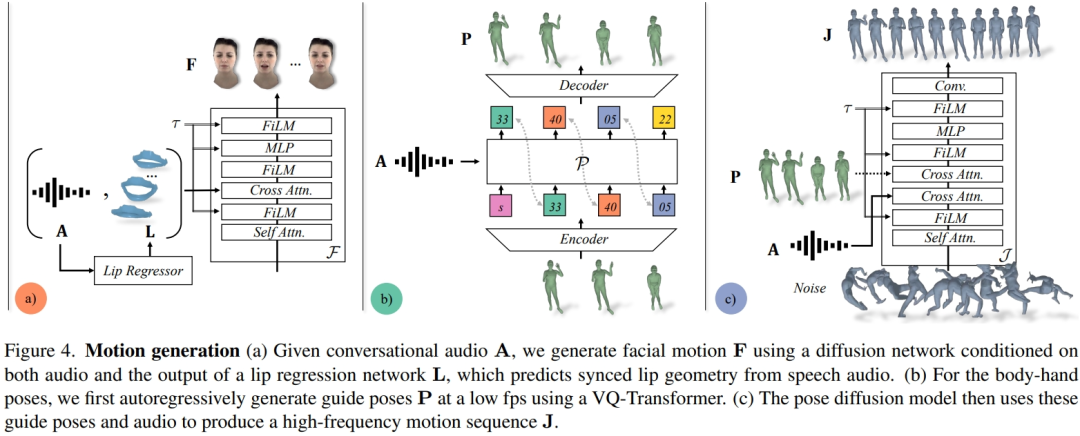
The facial motion model is a diffusion model conditioned on input audio and lip vertices generated by a pre-trained lip regressor (Figure 4a). For the limb movement model, researchers found that the movement produced by a pure diffusion model conditioned only on audio lacked diversity and was not coordinated enough in time series. However, the quality improved when the researchers conditioned on different guidance postures. Therefore, they split the body motion model into two parts: first, the autoregressive audio conditioner predicts coarse guidance poses at 1 fp (Fig. 4b), and then the diffusion model utilizes these coarse guidance poses to fill in fine-grained and high-frequency motions (Fig. 4c). See the original article for more details on method settings.
Experiments and results
The researchers quantitatively evaluated Audio2Photoreal’s effectiveness in generating realistic dialogue actions based on real data Ability. Perceptual evaluations were also performed to corroborate the quantitative results and measure the appropriateness of Audio2Photoreal in generating gestures in a given conversational context. Experimental results showed that evaluators were more sensitive to subtle gestures when the gestures were presented on a realistic avatar rather than a 3D mesh.
The researchers compared the generation results of this method with three baseline methods: KNN, SHOW, and LDA based on random motion sequences in the training set. Ablation experiments were conducted to test the effectiveness of each component of Audio2Photoreal without audio or guided gestures, without guided gestures but based on audio, and without audio but based on guided gestures.
Quantitative results
Table 1 shows that compared with previous studies, this method has the highest diversity in generation The FD score is lowest when exercising. While random has good diversity that matches GT, random segments do not match the corresponding conversation dynamics, resulting in high FD_g.
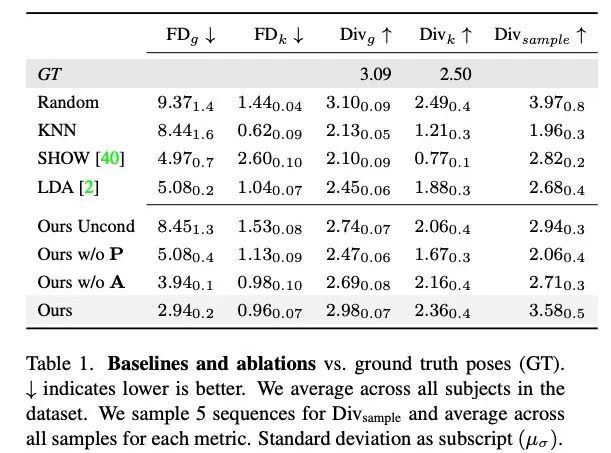
Figure 5 shows the diversity of guidance poses generated by our method. VQ-based transformer P-sampling enables the generation of very different gestures with the same audio input.

As shown in Figure 6, the diffusion model will learn to generate dynamic actions, and the actions will better match the dialogue audio .

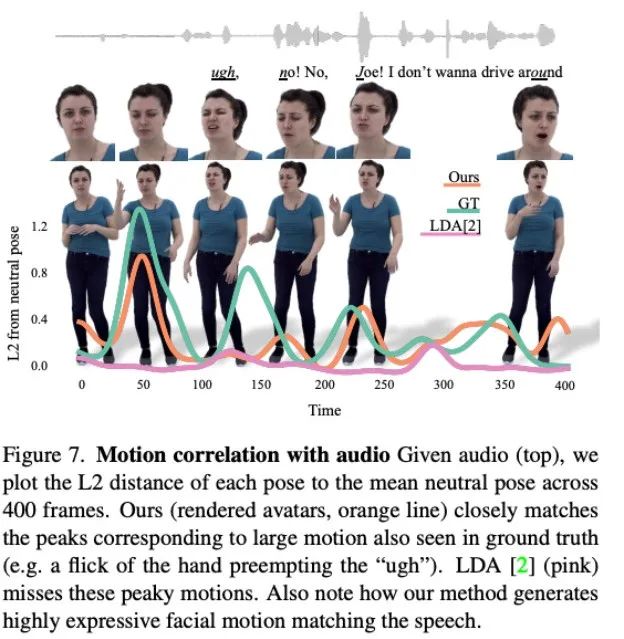
Figure 7 shows that the motion generated by LDA lacks energy and has less movement. In contrast, the motion changes synthesized by this method are more consistent with the actual situation.
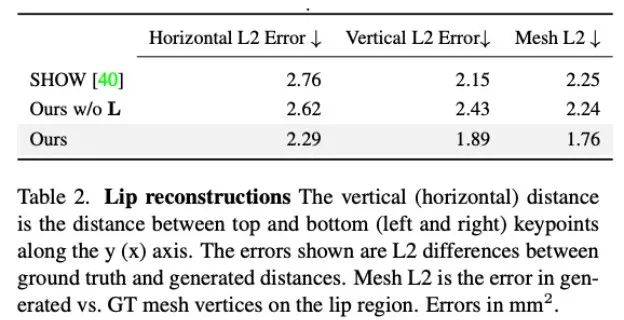
In addition, the researchers also analyzed the accuracy of this method in generating lip movements. As the statistics in Table 2 show, Audio2Photoreal significantly outperforms the baseline method SHOW, as well as the performance after removing the pretrained lip regressor in the ablation experiments. This design improves the synchronization of mouth shapes when speaking, effectively avoids random opening and closing movements of the mouth when not speaking, enables the model to achieve better lip movement reconstruction, and at the same time reduces the facial mesh vertices ( Grid L2) error.
Qualitative evaluation
Due to the coherence of gestures in dialogue, it is difficult to Quantitatively, the researchers used qualitative methods for evaluation. They conducted two sets of A/B tests on MTurk. Specifically, they asked evaluators to watch the generated results of our method and the baseline method or the video pair of our method and real scenes, and asked them to evaluate which video in which the motion looked more reasonable.
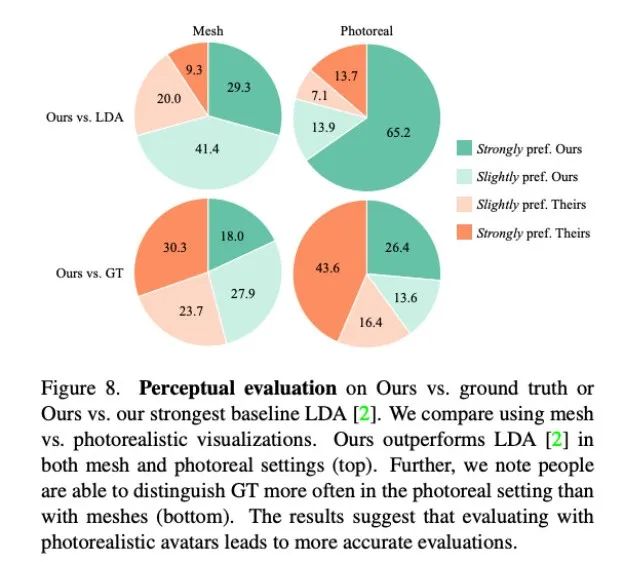
As shown in Figure 8, this method is significantly better than the previous baseline method LDA, and about 70% of the reviewers prefer Audio2Photoreal in terms of grid and realism.
As shown in the top chart of Figure 8, compared with LDA, the evaluators’ evaluation of this method changed from “slightly prefer” to “strongly like”. Compared with the real situation, the same evaluation is presented. Still, evaluators favored the real thing over Audio2Photoreal when it came to realism.
For more technical details, please read the original paper.
The above is the detailed content of Climbing along the network cable has become a reality, Audio2Photoreal can generate realistic expressions and movements through dialogue. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
Suggestions for choosing a cryptocurrency exchange: 1. For liquidity requirements, priority is Binance, Gate.io or OKX, because of its order depth and strong volatility resistance. 2. Compliance and security, Coinbase, Kraken and Gemini have strict regulatory endorsement. 3. Innovative functions, KuCoin's soft staking and Bybit's derivative design are suitable for advanced users.
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
 'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
The plunge in the cryptocurrency market has caused panic among investors, and Dogecoin (Doge) has become one of the hardest hit areas. Its price fell sharply, and the total value lock-in of decentralized finance (DeFi) (TVL) also saw a significant decline. The selling wave of "Black Monday" swept the cryptocurrency market, and Dogecoin was the first to be hit. Its DeFiTVL fell to 2023 levels, and the currency price fell 23.78% in the past month. Dogecoin's DeFiTVL fell to a low of $2.72 million, mainly due to a 26.37% decline in the SOSO value index. Other major DeFi platforms, such as the boring Dao and Thorchain, TVL also dropped by 24.04% and 20, respectively.
