

IT House News on January 9th, Meta recently announced an AI framework called audio2photoreal, which can generate a series of realistic NPC character models and automatically "lip-sync" the character models with the help of existing dubbing files. ” “Swing motion”.


▲ Picture source Meta research report (the same below)
IT House learned from the official research report that after receiving the dubbing file, the Audio2photoreal framework first generates a series of NPC models, and then uses quantization technology and diffusion algorithm to generate model actions. The quantification technology provides action samples for the framework. The reference,diffusion algorithm is used to improve the character,action effects generated by the frame.
The researchers mentioned that the framework can generate "high-quality action samples" at 30 FPS, and can also simulate involuntary "habitual actions" such as "pointing fingers," "turning wrists," or "shrugs" during conversations. ".


The researchers cited the results of their own experiments. In the controlled experiment, 43% of the evaluators were "strongly satisfied" with the character dialogue scenes generated by the framework. Therefore, the researchers believe that the Audio2photoreal framework can generate "more dynamic" compared to competing products in the industry. and expressive” actions.
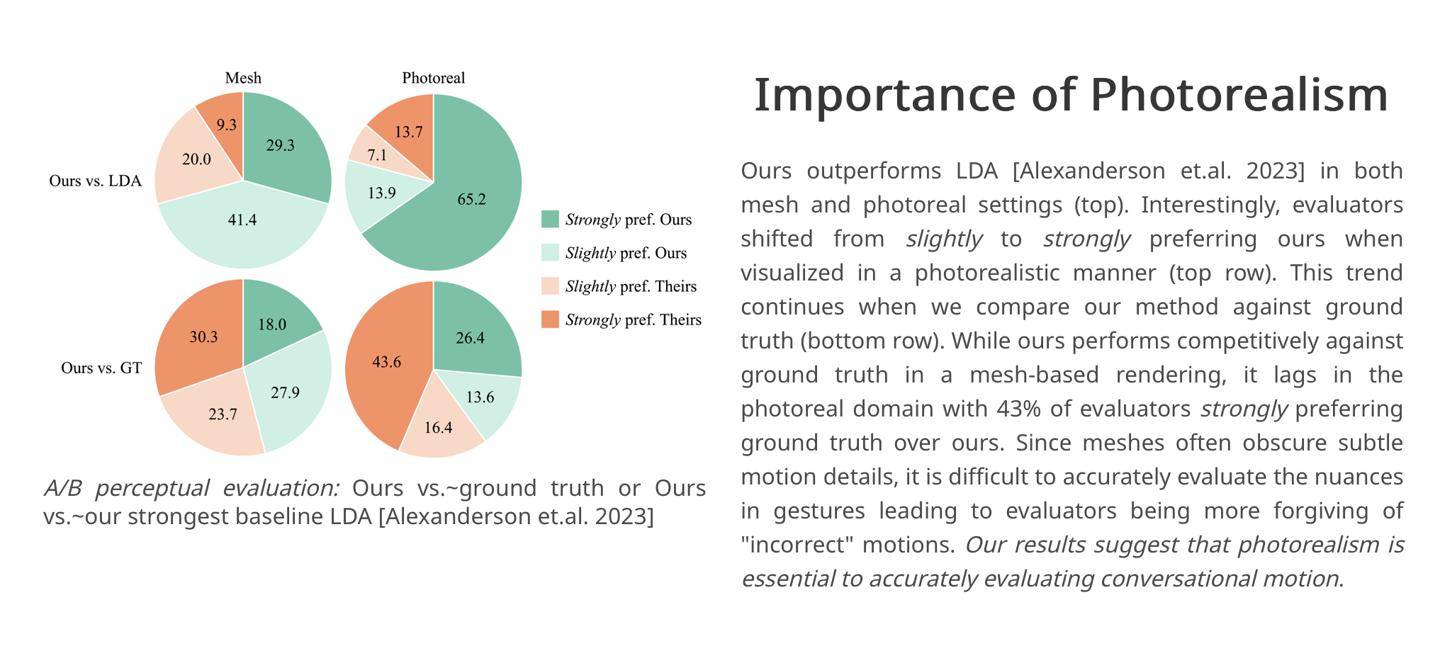
It is reported that the research team has now disclosed the relevant code and data sets on GitHub. Interested partners can click here to access.
The above is the detailed content of Meta launches audio-to-image AI framework for generating dubbing of character dialogue scenes. For more information, please follow other related articles on the PHP Chinese website!
 How to buy and sell Bitcoin on okex
How to buy and sell Bitcoin on okex
 How to implement linked list in go
How to implement linked list in go
 How to recover files emptied from Recycle Bin
How to recover files emptied from Recycle Bin
 Interview assessment tools
Interview assessment tools
 The difference between win10 home version and professional version
The difference between win10 home version and professional version
 Introduction to the three core components of hadoop
Introduction to the three core components of hadoop
 The difference between win10 sleep and hibernation
The difference between win10 sleep and hibernation
 Telecom cdma
Telecom cdma








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



