
 System Tutorial
LINUX
Will machine learning put database management system operators out of work?
System Tutorial
LINUX
Will machine learning put database management system operators out of work?
Will machine learning put database management system operators out of work?

| Introduction | The database management system (DBMS) is the most important part of any data-intensive application system. They can handle large amounts of data and complex workloads. But they are difficult to manage because they have hundreds or thousands of configuration "knobs" that control factors such as the amount of memory used for caching and how often data is written to the storage device. Organizations often hire experts to help fine-tune their campaigns, but experts are prohibitively expensive for many businesses. |
This article was written by three guests from Carnegie Mellon University: Dana Van Aken, Andy Pavlo and Geoff Gordon Co-authored article. This project demonstrates how academic researchers can use the AWS Cloud Credits for Research Program (https://aws.amazon.com/research-credits/) to support their scientific breakthroughs.
OtterTune is a new tool developed by students and researchers in the Carnegie Mellon University Database Group (http://db.cs.cmu.edu/projects/autotune/) that automatically Configure button to find the appropriate setting. The goal is to make it easier for anyone to deploy a DBMS, even those with no expertise in database administration.
OtterTune is different from other DBMS configuration tools because it fully leverages the knowledge gained from tuning previously deployed DBMSs to tune newly deployed DBMSs. This significantly reduces the time and resources required to tune a newly deployed DBMS. To this end, OtterTune maintains a database containing tuning data collected from previous tuning sessions. It uses this data to build machine learning models that capture information about how the DBMS reacts to different configurations. OtterTune uses these models to guide users when trying out new applications, suggesting settings that improve specific goals, such as reducing latency or increasing throughput.
In this article we explore each component of OtterTune’s machine learning pipeline and demonstrate how they relate to each other to tune the configuration of your DBMS. We then evaluated OtterTune's performance on MySQL and Postgres by comparing the performance of its optimal configurations with configurations chosen by database administrators (DBAs) and other automated tuning tools.
OtterTune is an open source tool developed by students and researchers in the Database Group at Carnegie Mellon University. All code is placed on GitHub (https://github.com/cmu-db/ottertune) and is released under the Apache License 2.0.
working principleThe picture below shows the components and workflow of OtterTune.
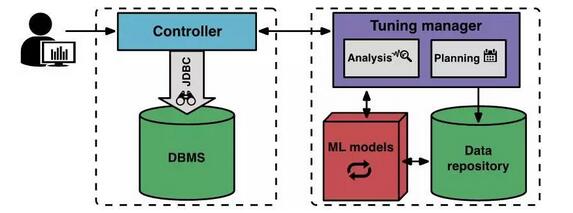
At the beginning of a new tuning session, the user tells OtterTune which specific goal to optimize for (such as latency or throughput). The client controller connects to the target DBMS and collects the Amazon EC2 instance type and current target.
The controller then begins the first observation period, during which it observes the DBMS and logs specific targets. After the observation period is over, the controller collects internal metrics from the DBMS, such as MySQL counts of pages read from disk and pages written to disk. The controller returns both specific goals and internal metrics to the tuning manager.
After OtterTune's tuning manager receives the metrics, it stores them in the database. OtterTune uses the results to calculate the next configuration the controller should be installed on the target DBMS. The tuning manager returns this configuration to the controller and estimates the expected improvements through actual runs. The user can decide to continue the tuning session or terminate it.
illustrateOtterTune maintains a button blacklist for each DBMS version it supports. The blacklist includes buttons that do not need to be tuned (such as the path name of the DBMS storage file), or buttons that may have serious or hidden consequences (such as may cause the DBMS to lose data). At the beginning of each tuning session, OtterTune provides users with a blacklist so they can add any other buttons they want OtterTune to avoid tuning.
OtterTune makes certain assumptions that may limit its usefulness to some users. For example, it assumes that the user has administrator rights, allowing the controller to modify the DBMS configuration. If the user does not have administrator rights, they can deploy a second copy of the database to other hardware for OtterTune tuning experiments. This requires users to replay workload traces or forward queries from a production-grade DBMS. For a complete discussion of assumptions and limitations, see our paper (http://db.cs.cmu.edu/papers/2017/tuning-sigmod2017.pdf).
Machine Learning PipelineThe diagram below shows how data is processed as it passes through OtterTune’s machine learning pipeline. All observations are placed in OtterTune's database.
OtterTune first transmits the observation results to the Workload Characterization component. This component identifies a small set of DBMS metrics that most accurately capture performance changes and unique characteristics of different workloads.
Next, the Knob Identification component generates a button sorting list, listing the buttons that have the greatest impact on the performance of the DBMS. OtterTune then feeds all this information to Automatic Tuner. This component maps the workload of the target DBMS to the most similar workload in the data repository and reuses the workload data to generate a more appropriate configuration.

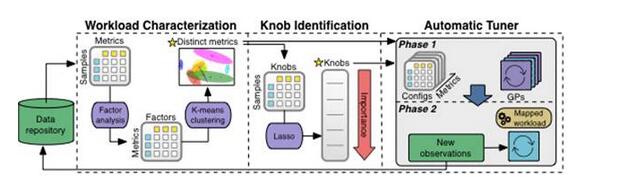
Now let’s dive into each component of the machine learning pipeline.
Workload Characterization: OtterTune uses the DBMS's internal runtime metrics to describe the behavioral characteristics of the workload. These metrics accurately represent the workload because they capture many aspects of runtime behavior. However, many metrics are redundant: some are the same metric value recorded in different units, and others represent independent parts of the DBMS where values are highly correlated. Streamlining redundant metrics is important because it reduces the complexity of the machine learning models that use them. To this end, we divide DBMS metrics into clusters based on correlation patterns. We then select a representative metric from each cluster, specifically the one closest to the cluster center. Subsequent components in the machine learning pipeline use these metrics.
Knob Identification: A DBMS may have hundreds of buttons, but only a small number of buttons affect the performance of the DBMS. OtterTune uses a popular feature selection technique called Lasso to decide which buttons significantly affect the overall performance of your system. By applying this technique to data in a database, OtterTune can identify the DBMS' button order of importance.
OtterTune then has to decide how many buttons to use in the proposed configuration. Using too many buttons greatly increases OtterTune's optimization time. Using too few buttons prevents OtterTune from finding the optimal configuration. To automate this process, OtterTune uses an incremental approach. It gradually increases the number of buttons used in a tuning session. This approach allows OtterTune to explore and optimize configurations for a small set of the most important buttons, and then expand the scope to consider additional buttons.
Automatic Tuner: The Automated Tuning component determines which configuration OtterTune should recommend by performing a two-step analysis after each observation period.
First, the system identifies the workload from a previous tuning session that best represents the target DBMS workload using performance data for the metrics identified in the Workload Characterization component. It compares the session's metrics to metrics from previous workloads to see which ones respond similarly to different button settings.
Then, OtterTune selects another button configuration to give it a try. It fits statistical models to the data that has been collected, as well as data from the most similar workloads in the repository. This model allows OtterTune to predict how the DBMS will perform using every possible configuration. OtterTune optimizes the next configuration to strike a balance between exploration (gathering information to improve the model) and exploitation (performing as well as possible on a specific metric).
accomplishOtterTune is written in Python.
As far as the two components of Workload Characterization and Knob Identification are concerned, runtime performance is not the main issue to worry about, so we used scikit-learn to implement the corresponding machine learning algorithm. These algorithms run in a background process and will integrate new data as soon as it becomes available in OtterTune's database.
As for the Automatic Tuner, the machine learning algorithm is on the critical path. They run after each observation period, integrating new data so that OtterTune can select a button configuration to try next. Since performance is a consideration, we implemented these algorithms using TensorFlow.
To collect data on DBMS hardware, button configurations and runtime performance metrics, we integrated OtterTune's controller with the OLTP-Bench benchmarking framework.
EvaluateFor evaluation, we compared the best configuration selected by OtterTune with the following configurations for MySQL and Postgres performance:
- Default: Configuration provided by DBMS
- Tuning script: Configuration generated by open source tuning advisory tool
- DBA: Database Administrator Generated Configuration
- RDS: Configuration customized for DBMS, managed by Amazon RD, deployed on EC2 instances of the same type.
We conducted all experiments on Amazon EC2 Spot Instances. We conducted each trial on two instances: one for OtterTune's controller and another for the deployed target DBMS system. We used m4.large and m3.xlarge instance types respectively. We deployed OtterTune's tuning manager and data database on a local server equipped with 20 cores and 128GB of memory.
We used the TPC-C workload, which is the industry standard for evaluating the performance of online transaction processing (OLTP) systems.
We measured latency and throughput against each database we used in our experiments: MySQL and Postgres. The following figures show the results. The first graph shows the amount of 99th percentile latency, which represents the "worst case" time it takes for a transaction to complete. The second graph shows the results for throughput, measured as the average number of transactions completed per second.
MySQL results:
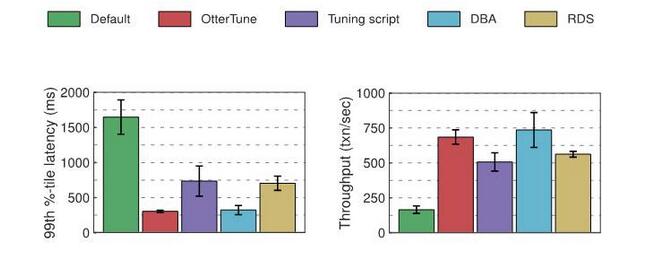
Comparing the optimal configuration generated by OtterTune with the configuration generated by the tuning script and RDS, you will find that if you use OtterTune configuration, MySQL's latency is reduced by about 60% and the throughput is increased by 35%. OtterTune also produces configurations with results that are as good as those chosen by the database administrator.
A few MySQL buttons have a significant impact on the performance of TPC-C workloads. The configurations generated by OtterTune and the database administrator provide good settings for each of these buttons. RDS performed a little less well due to providing sub-optimal settings for one button. The configuration of the tuning script performed the worst since only one button was modified.
Results for Postgres:
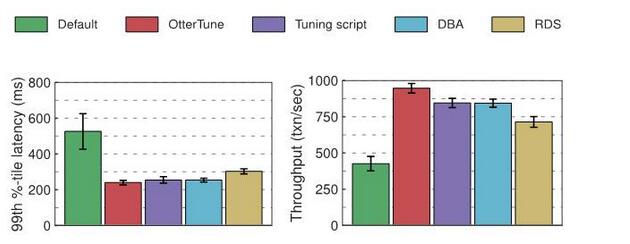
In terms of latency, OtterTune, tuning tools, database management, and RDS-generated configurations all offer similar improvements over Postgres' default settings. We can probably attribute this to the overhead required for the round trip between the OLTP-Bench client and the DBMS over the network. As for throughput, if you use the configuration recommended by OtterTune, Postgres performance is about 12% higher than the configuration selected by the database administrator and tuning script, and about 32% higher than RDS.
Similar to MySQL, only a few buttons have a significant impact on Postgres performance. OtterTune, database administrators, tuning scripts, and RDS-generated configurations all modify these buttons, and most provide pretty good settings.
ConclusionOtterTune automates the process of finding the appropriate settings for a DBMS configuration button. To tune a newly deployed DBMS, it reuses training data collected from previous tuning sessions. Because OtterTune does not require the generation of initial data sets for training machine learning models, tuning time is significantly reduced.
What’s next? To accommodate the growing popularity of DBaaS deployments that do not have remote access to the DBMS's host system, OtterTune will soon be able to automatically detect the hardware capabilities of the target DMBS without requiring remote access.
For more details on OtterTune, see our paper or the code on GitHub. Please stay tuned to this website (http://ottertune.cs.cmu.edu/), we will soon launch OtterTune, an online tuning service.
About the Author:
Dana Van Aken is a doctoral student in computer science at Carnegie Mellon University, mentored by Dr. Andrew Pavlo.
Andy Pavlo is an assistant professor of database science in the Department of Computer Science at Carnegie Mellon University.
Geoff Gordon is an associate professor and associate director of education in the Machine Learning Department at Carnegie Mellon University.
The above is the detailed content of Will machine learning put database management system operators out of work?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
The key differences between CentOS and Ubuntu are: origin (CentOS originates from Red Hat, for enterprises; Ubuntu originates from Debian, for individuals), package management (CentOS uses yum, focusing on stability; Ubuntu uses apt, for high update frequency), support cycle (CentOS provides 10 years of support, Ubuntu provides 5 years of LTS support), community support (CentOS focuses on stability, Ubuntu provides a wide range of tutorials and documents), uses (CentOS is biased towards servers, Ubuntu is suitable for servers and desktops), other differences include installation simplicity (CentOS is thin)
 How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use Docker Desktop? Docker Desktop is a tool for running Docker containers on local machines. The steps to use include: 1. Install Docker Desktop; 2. Start Docker Desktop; 3. Create Docker image (using Dockerfile); 4. Build Docker image (using docker build); 5. Run Docker container (using docker run).
 How to install centos
Apr 14, 2025 pm 09:03 PM
How to install centos
Apr 14, 2025 pm 09:03 PM
CentOS installation steps: Download the ISO image and burn bootable media; boot and select the installation source; select the language and keyboard layout; configure the network; partition the hard disk; set the system clock; create the root user; select the software package; start the installation; restart and boot from the hard disk after the installation is completed.
 Centos options after stopping maintenance
Apr 14, 2025 pm 08:51 PM
Centos options after stopping maintenance
Apr 14, 2025 pm 08:51 PM
CentOS has been discontinued, alternatives include: 1. Rocky Linux (best compatibility); 2. AlmaLinux (compatible with CentOS); 3. Ubuntu Server (configuration required); 4. Red Hat Enterprise Linux (commercial version, paid license); 5. Oracle Linux (compatible with CentOS and RHEL). When migrating, considerations are: compatibility, availability, support, cost, and community support.
 How to view the docker process
Apr 15, 2025 am 11:48 AM
How to view the docker process
Apr 15, 2025 am 11:48 AM
Docker process viewing method: 1. Docker CLI command: docker ps; 2. Systemd CLI command: systemctl status docker; 3. Docker Compose CLI command: docker-compose ps; 4. Process Explorer (Windows); 5. /proc directory (Linux).
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 What to do if the docker image fails
Apr 15, 2025 am 11:21 AM
What to do if the docker image fails
Apr 15, 2025 am 11:21 AM
Troubleshooting steps for failed Docker image build: Check Dockerfile syntax and dependency version. Check if the build context contains the required source code and dependencies. View the build log for error details. Use the --target option to build a hierarchical phase to identify failure points. Make sure to use the latest version of Docker engine. Build the image with --t [image-name]:debug mode to debug the problem. Check disk space and make sure it is sufficient. Disable SELinux to prevent interference with the build process. Ask community platforms for help, provide Dockerfiles and build log descriptions for more specific suggestions.
 What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
