

A new interpretation of the declining intelligence level of GPT-4

GPT-4, regarded as one of the most powerful language models in the world since its release, has unfortunately experienced a series of crises of trust.
If we connect the "intermittent intelligence" incident earlier this year with OpenAI's redesign of the GPT-4 architecture, then there are recent reports that GPT-4 has become "lazy" "The rumors are even more interesting. Someone tested and found that as long as you tell GPT-4 "it is winter vacation", it will become lazy, as if it has entered a hibernation state.
To solve the problem of poor zero-sample performance of the model on new tasks, we can take the following methods: 1. Data enhancement: Increase the generalization ability of the model by expanding and transforming existing data. For example, image data can be altered by rotation, scaling, translation, etc., or by synthesizing new data samples. 2. Transfer learning: Use models that have been trained on other tasks to transfer their parameters and knowledge to new tasks. This can leverage existing knowledge and experience to improve
Recently, researchers from the University of California, Santa Cruz published a new discovery in a paper that may It can explain the underlying reasons for the performance degradation of GPT-4.

“We found that LLM performed surprisingly better on datasets released before the training data creation date. Datasets released later."
They perform well on "seen" tasks and perform poorly on new tasks. This means that LLM is just a method of imitating intelligence based on approximate retrieval, mainly memorizing things without any level of understanding.
To put it bluntly, LLM’s generalization ability is “not as strong as stated” - the foundation is not solid, and there will always be mistakes in actual combat.
One of the major reasons for this result is "task pollution", which is one form of data pollution. The data pollution we are familiar with before is test data pollution, which is the inclusion of test data examples and labels in the pre-training data. "Task contamination" is the addition of task training examples to pre-training data, making the evaluation in zero-sample or few-sample methods no longer realistic and effective.
The researcher conducted a systematic analysis of the data pollution problem for the first time in the paper:

Paper link: https://arxiv.org/pdf/2312.16337.pdf
After reading the paper, someone said "pessimistically":
This is the fate of all machine learning (ML) models that do not have the ability to continuously learn, that is, ML models The weights are frozen after training, but the input distribution continues to change, and if the model cannot continue to adapt to this change, it will slowly degrade.
This means that as programming languages are constantly updated, LLM-based coding tools will also degrade. This is one of the reasons why you don't have to rely too heavily on such a fragile tool.
The cost of constantly retraining these models is high, and sooner or later someone will give up on these inefficient methods.
No ML model yet can reliably and continuously adapt to changing input distributions without causing severe disruption or performance loss to the previous encoding task.
And this is one of the areas where biological neural networks are good at. Due to the strong generalization ability of biological neural networks, learning different tasks can further improve the performance of the system, because the knowledge gained from one task helps to improve the entire learning process itself, which is called "meta-learning".
How serious is the problem of "task pollution"? Let’s take a look at the content of the paper.
Models and data sets
There are 12 models used in the experiment (as shown in Table 1), 5 of which are proprietary Of the GPT-3 series models, 7 are open models with free access to weights.
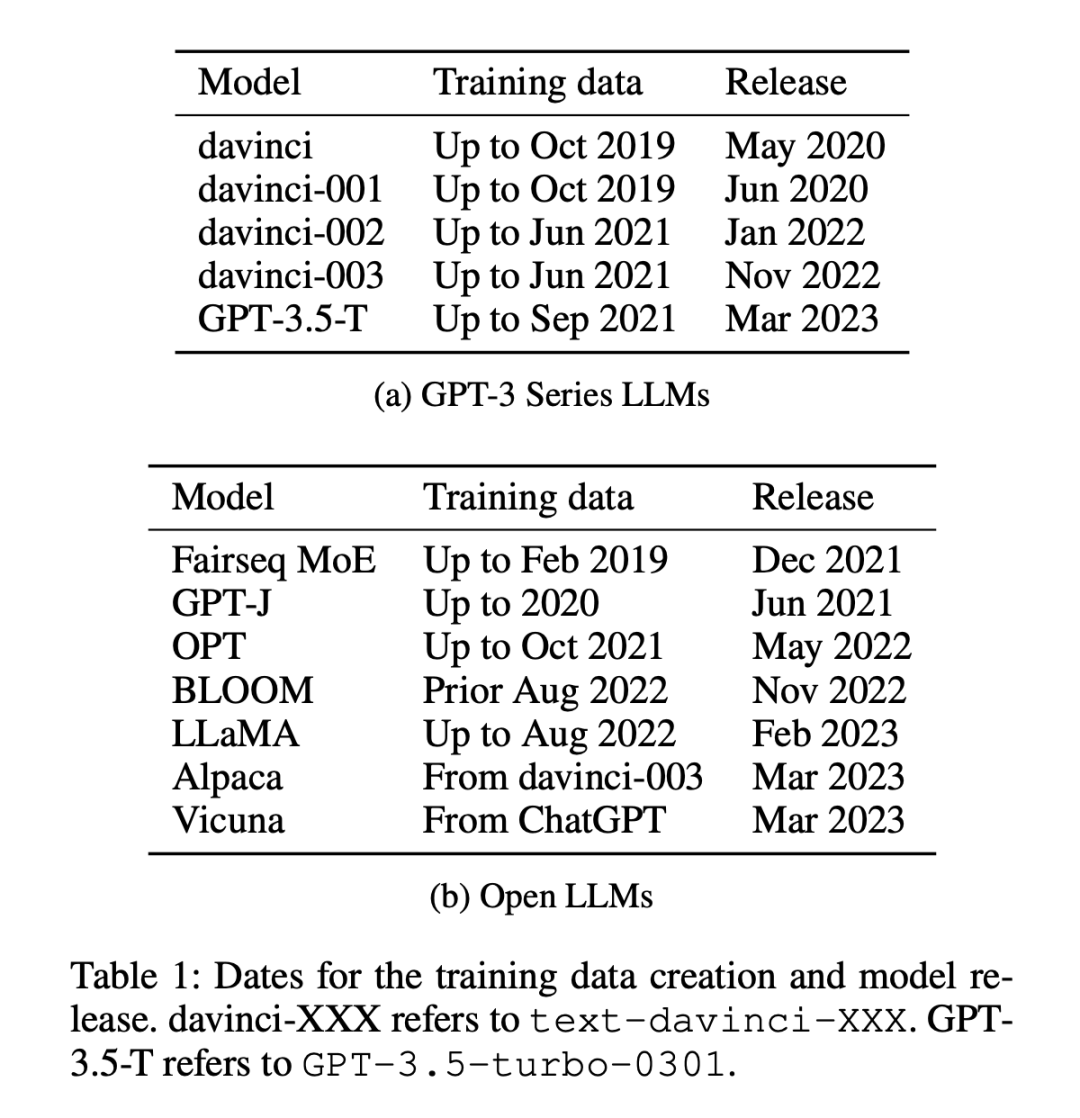
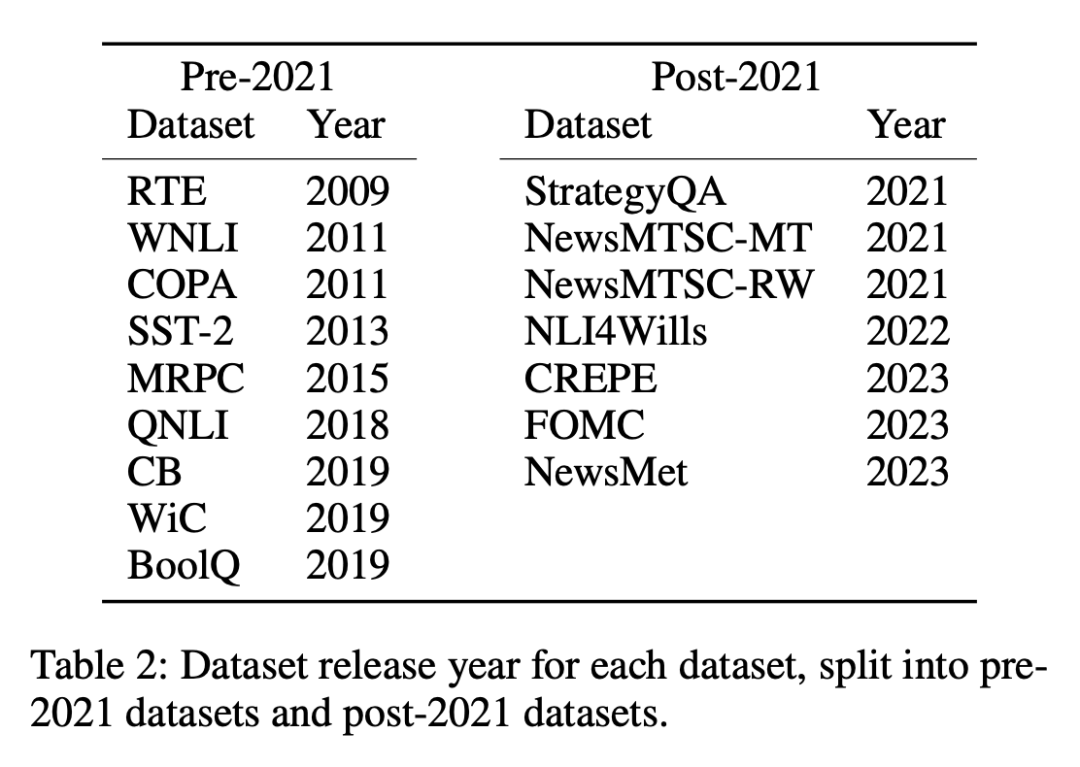
Datasets are divided into two categories: published before or after January 1, 2021 Data set, researchers use this partitioning method to analyze the zero-sample or few-sample performance difference between the old data set and the new data set, and use the same partitioning method for all LLMs. Table 1 lists the creation time of each model training data, and Table 2 lists the publication date of each dataset.
The consideration behind the above approach is that zero-shot and few-shot evaluations involve the model making predictions about tasks that it has never seen or only seen a few times during training. The key premise is that the model has no prior exposure to the specific task to be completed. , thereby ensuring a fair assessment of their learning abilities. However, tainted models can give the illusion of competence that they have not been exposed to or have only been exposed to a few times because they have been trained on task examples during pre-training. In a chronological data set, it will be relatively easier to detect such inconsistencies, as any overlaps or anomalies will be obvious.
Measurement methods
The researchers used four methods to measure "task pollution":
- Training data inspection: Search the training data for task training examples.
- Task example extraction: Extract task examples from existing models. Only instruction-tuned models can be extracted. This analysis can also be used for training data or test data extraction. Note that in order to detect task contamination, the extracted task examples do not have to exactly match existing training data examples. Any example that demonstrates a task demonstrates the possible contamination of zero-shot learning and few-shot learning.
- Member Reasoning: This method only applies to build tasks. Checks that the model-generated content for the input instance is exactly the same as the original dataset. If it matches exactly, we can infer that it is a member of the LLM training data. This differs from task example extraction in that the generated output is checked for an exact match. Exact matches on the open-ended generation task strongly suggest that the model saw these examples during training, unless the model is "psychic" and knows the exact wording used in the data. (Note, this can only be used for build tasks.)
- Time series analysis: For a model set where training data was collected during a known time frame, measure its performance on a dataset with a known release date, and use Temporal evidence checks for contamination evidence.
The first three methods have high precision, but low recall rate. If you can find the data in the task's training data, you can be sure that the model has seen the example. However, due to changes in data formats, changes in keywords used to define tasks, and the size of data sets, finding no evidence of contamination using the first three methods does not prove the absence of contamination.
The fourth method, the recall rate of chronological analysis is high, but the precision is low. If performance is high due to task contamination, then chronological analysis has a good chance of spotting it. But other factors may also cause performance to improve over time and therefore be less accurate.
Therefore, the researchers used all four methods to detect task contamination and found strong evidence of task contamination in certain model and dataset combinations.
They first performed timing analysis on all tested models and datasets as it was most likely to find possible contamination; then used training data inspection and task example extraction to find task contamination Further evidence; we next observe the performance of LLM on a pollution-free task, and finally conduct additional analysis using membership inference attacks.
The key conclusions are as follows:
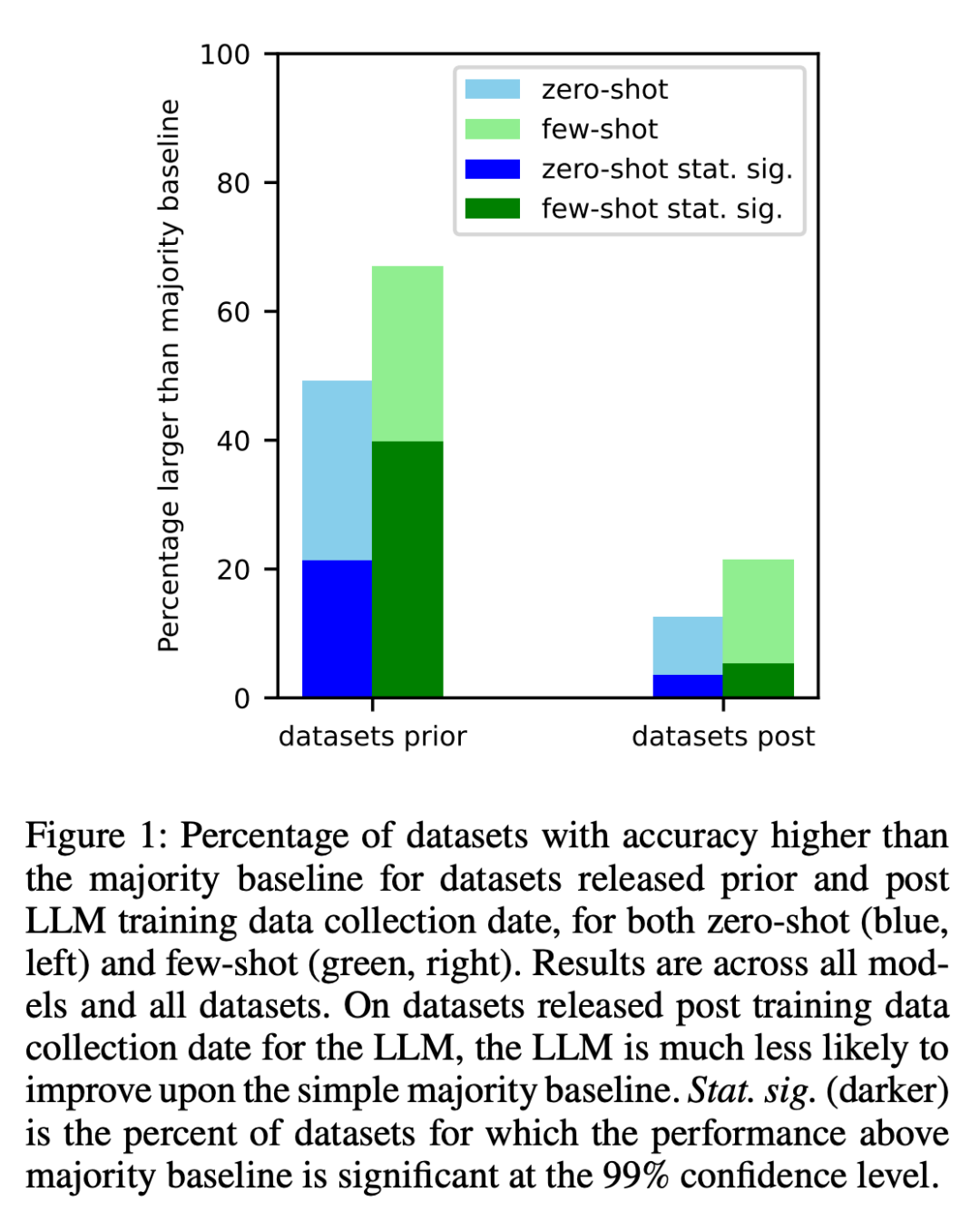
1. The researcher created a data set for each model before its training data was crawled on the Internet. and then analyzed the data set created. It was found that the odds of performing above most baselines were significantly higher for datasets created before collecting LLM training data (Figure 1).
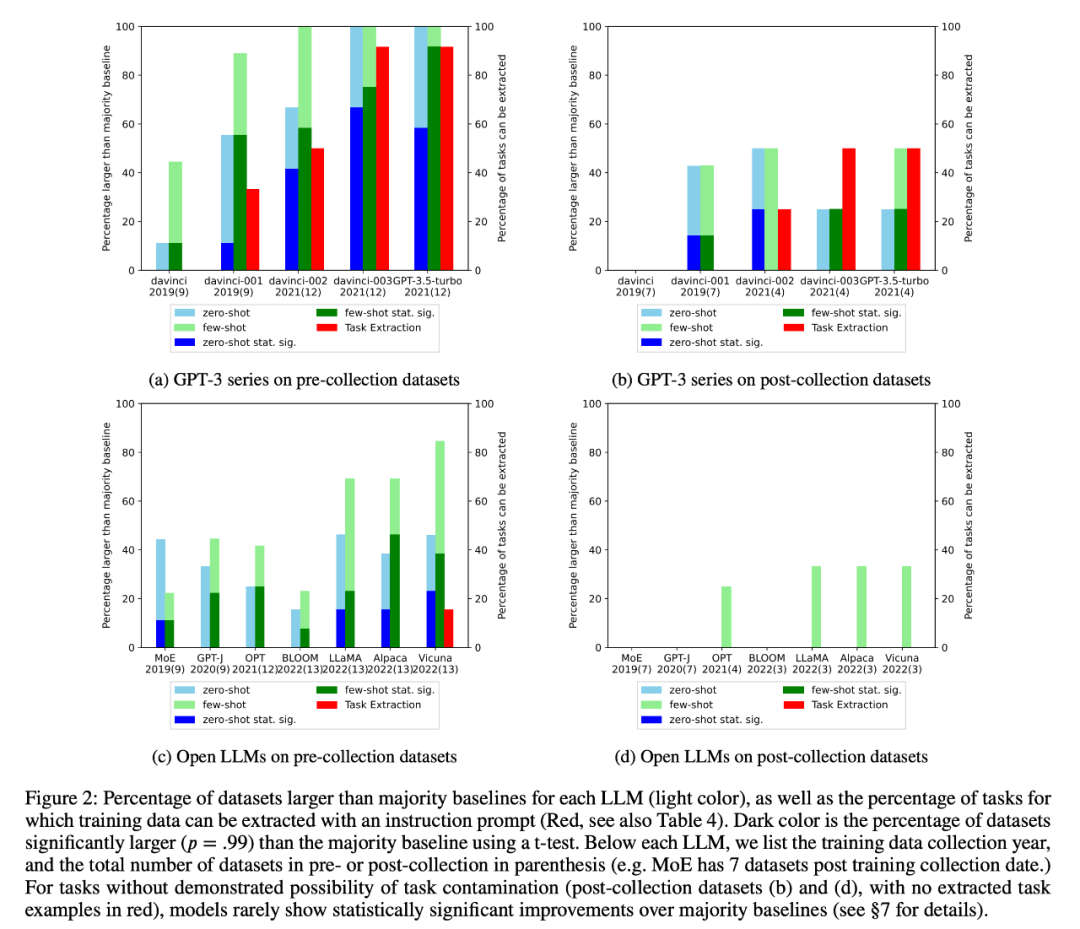
#2. The researcher conducted training data inspection and task example extraction to find possible task contamination. It was found that for classification tasks where task contamination is unlikely, models rarely achieve statistically significant improvements over simple majority baselines across a range of tasks, whether zero- or few-shot (Figure 2).
The researchers also examined the changes in the average performance of the GPT-3 series and open LLM over time, as shown in Figure 3 :
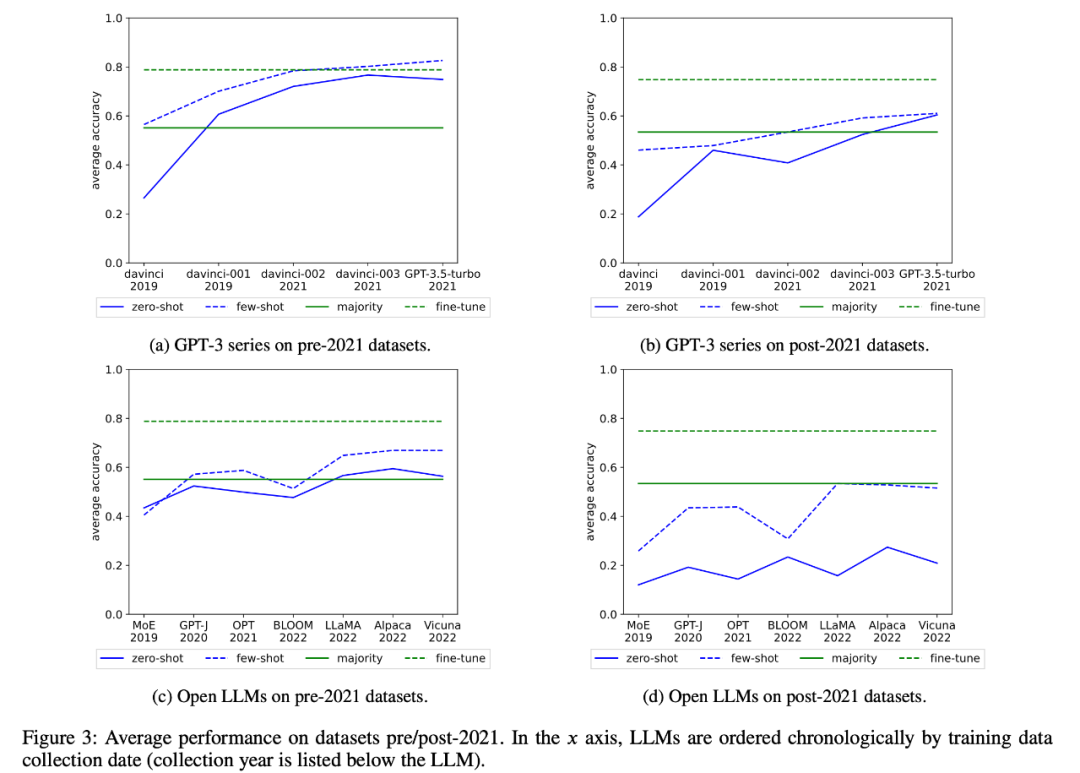
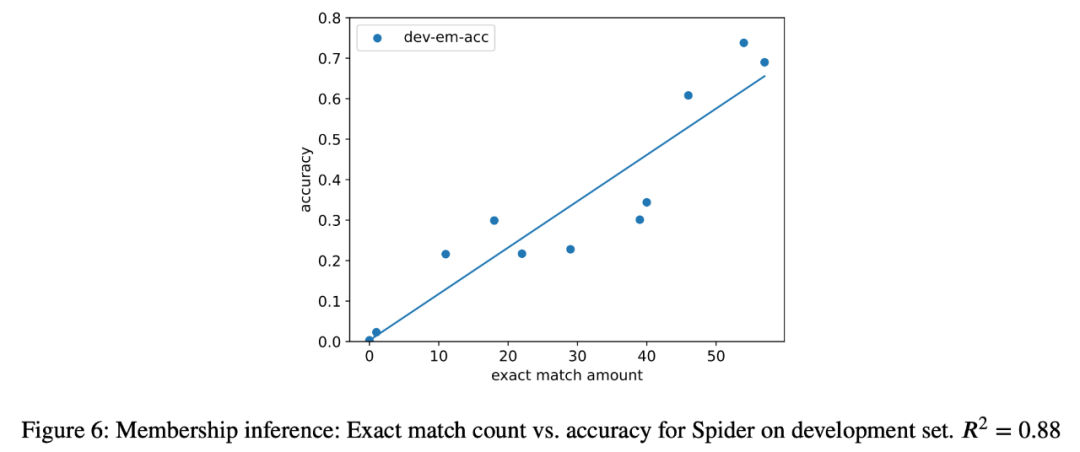
3. As a case study, the researcher also tried to perform semantic parsing tasks on all models in the analysis. Inference attack, found a strong correlation (R=.88) between the number of extracted instances and the accuracy of the model in the final task (Figure 6). This strongly proves that the improvement in zero-shot performance in this task is due to task contamination.
4. The researchers also carefully studied the GPT-3 series models and found that training examples can be extracted from the GPT-3 model, and in each version from davinci to GPT-3.5-turbo, the training examples that can be extracted The number is increasing, which is closely related to the improvement of the zero-sample performance of the GPT-3 model on this task (Figure 2). This strongly proves that the performance improvement of GPT-3 models from davinci to GPT-3.5-turbo on these tasks is due to task contamination.
The above is the detailed content of A new interpretation of the declining intelligence level of GPT-4. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 A new programming paradigm, when Spring Boot meets OpenAI
Feb 01, 2024 pm 09:18 PM
A new programming paradigm, when Spring Boot meets OpenAI
Feb 01, 2024 pm 09:18 PM
In 2023, AI technology has become a hot topic and has a huge impact on various industries, especially in the programming field. People are increasingly aware of the importance of AI technology, and the Spring community is no exception. With the continuous advancement of GenAI (General Artificial Intelligence) technology, it has become crucial and urgent to simplify the creation of applications with AI functions. Against this background, "SpringAI" emerged, aiming to simplify the process of developing AI functional applications, making it simple and intuitive and avoiding unnecessary complexity. Through "SpringAI", developers can more easily build applications with AI functions, making them easier to use and operate.
 Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings
Feb 26, 2024 pm 06:10 PM
Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings
Feb 26, 2024 pm 06:10 PM
OpenAI recently announced the launch of their latest generation embedding model embeddingv3, which they claim is the most performant embedding model with higher multi-language performance. This batch of models is divided into two types: the smaller text-embeddings-3-small and the more powerful and larger text-embeddings-3-large. Little information is disclosed about how these models are designed and trained, and the models are only accessible through paid APIs. So there have been many open source embedding models. But how do these open source models compare with the OpenAI closed source model? This article will empirically compare the performance of these new models with open source models. We plan to create a data
 The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The humanoid robot Ameca has been upgraded to the second generation! Recently, at the World Mobile Communications Conference MWC2024, the world's most advanced robot Ameca appeared again. Around the venue, Ameca attracted a large number of spectators. With the blessing of GPT-4, Ameca can respond to various problems in real time. "Let's have a dance." When asked if she had emotions, Ameca responded with a series of facial expressions that looked very lifelike. Just a few days ago, EngineeredArts, the British robotics company behind Ameca, just demonstrated the team’s latest development results. In the video, the robot Ameca has visual capabilities and can see and describe the entire room and specific objects. The most amazing thing is that she can also
 750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
Regarding Llama3, new test results have been released - the large model evaluation community LMSYS released a large model ranking list. Llama3 ranked fifth, and tied for first place with GPT-4 in the English category. The picture is different from other benchmarks. This list is based on one-on-one battles between models, and the evaluators from all over the network make their own propositions and scores. In the end, Llama3 ranked fifth on the list, followed by three different versions of GPT-4 and Claude3 Super Cup Opus. In the English single list, Llama3 overtook Claude and tied with GPT-4. Regarding this result, Meta’s chief scientist LeCun was very happy and forwarded the tweet and
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 Rust-based Zed editor has been open sourced, with built-in support for OpenAI and GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Rust-based Zed editor has been open sourced, with built-in support for OpenAI and GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Author丨Compiled by TimAnderson丨Produced by Noah|51CTO Technology Stack (WeChat ID: blog51cto) The Zed editor project is still in the pre-release stage and has been open sourced under AGPL, GPL and Apache licenses. The editor features high performance and multiple AI-assisted options, but is currently only available on the Mac platform. Nathan Sobo explained in a post that in the Zed project's code base on GitHub, the editor part is licensed under the GPL, the server-side components are licensed under the AGPL, and the GPUI (GPU Accelerated User) The interface) part adopts the Apache2.0 license. GPUI is a product developed by the Zed team
 The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The volume is crazy, the volume is crazy, and the big model has changed again. Just now, the world's most powerful AI model changed hands overnight, and GPT-4 was pulled from the altar. Anthropic released the latest Claude3 series of models. One sentence evaluation: It really crushes GPT-4! In terms of multi-modal and language ability indicators, Claude3 wins. In Anthropic’s words, the Claude3 series models have set new industry benchmarks in reasoning, mathematics, coding, multi-language understanding and vision! Anthropic is a startup company formed by employees who "defected" from OpenAI due to different security concepts. Their products have repeatedly hit OpenAI hard. This time, Claude3 even had a big surgery.
