
 Technology peripherals
AI
Netizens praised: Transformer leads the simplified version of the annual paper is here
Technology peripherals
AI
Netizens praised: Transformer leads the simplified version of the annual paper is here
Netizens praised: Transformer leads the simplified version of the annual paper is here

Optimize from the root of the large model.
Transformer architecture can be said to be the main force behind many recent success stories in the field of deep learning. A simple way to build a deep Transformer architecture is to stack multiple identical Transformer "blocks" one after another, but each "block" is more complex and consists of many different components that require a specific arrangement and combination. achieve good performance.
Since the birth of the Transformer architecture in 2017, researchers have launched a large number of derivative studies based on it, but almost no changes have been made to the Transformer "block".
So the question is, can the standard Transformer block be simplified?
In a recent paper, researchers from ETH Zurich discuss how to simplify the standard Transformer block necessary for LLM without affecting convergence properties and downstream task performance. Based on signal propagation theory and empirical evidence, they found that some parts can be removed, such as residual connections, normalization layers (LayerNorm), projection and value parameters, and MLP serialization sub-blocks (favoring parallel layout ) to simplify GPT-like decoder architecture and encoder-style BERT models.
The researchers explored whether the components involved could be removed without affecting the training speed, and what architectural modifications should be made to the Transformer block.

Paper link: https://arxiv.org/pdf/2311.01906.pdf
Lightning AI Founder, Machine Learning Researcher Sebastian Raschka calls this study "one of his favorite papers of the year":
But some researchers question: "It's hard to comment unless I've seen the complete training process. Without a normalization layer and no residual connections, how can it be scaled in a network with >100 million parameters?』
Sebastian Raschka agreed: "Yes, the architecture they experimented with is relatively small. Can this be generalized to a Transformer with billions of parameters? That remains to be seen." But he still says the work is impressive and thinks the successful removal of residual connections is entirely reasonable (given its initialization scheme).
In this regard, Turing Award winner Yann LeCun commented: "We have only touched the surface of the field of deep learning architecture. This is a high-dimensional space, so the volume is almost completely contained in the surface. But we've only scratched the surface.

Why do we need to simplify the Transformer block?
The researchers said that simplifying the Transformer block without affecting the training speed is an interesting research problem. First of all, modern neural network architectures are complex in design and contain many components. The role that these different components play in the dynamics of neural network training and how they interact with each other is still unclear. This question relates to the gap between deep learning theory and practice, and is therefore very important. Signal propagation theory has proven influential in that it motivates practical design choices in deep neural network architectures. Signal propagation studies the evolution of geometric information in neural networks upon initialization, captured by the inner product of hierarchical representations across inputs, and has led to many impressive results in training deep neural networks. However, currently this theory only considers the model during initialization, and often only considers the initial forward pass, so it cannot reveal many complex issues in the training dynamics of deep neural networks, such as the contribution of residual connections to training speed. . While signal propagation is critical to modification motivation, the researchers say they couldn't derive a simplified Transformer module from theory alone and had to rely on empirical insights. In terms of practical applications, given the current high cost of training and deploying large Transformer models, any efficiency improvements in the Transformer architecture’s training and inference pipelines represent huge potential savings. If the Transformer module can be simplified by removing unnecessary components, it can both reduce the number of parameters and improve the throughput of the model. This paper also mentioned that after removing the residual connection, value parameters, projection parameters and serialization sub-blocks, it can be matched with the standard Transformer in terms of training speed and downstream task performance. Ultimately, the researchers reduced the number of parameters by 16% and observed a 16% increase in throughput in training and inference time.How to simplify the Transformer block?
Объединив теорию распространения сигналов и эмпирические наблюдения, исследователь представил, как создать простейший блок трансформатора, начиная с модуля Pre-LN (как показано ниже).
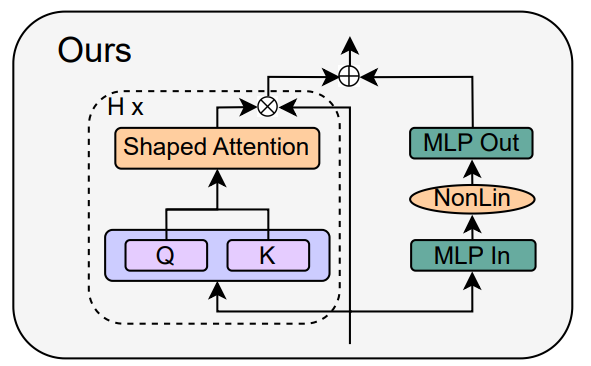
В каждом разделе главы 4 статьи автор рассказывает, как удалять по одному компоненту блока за раз, не влияя на скорость обучения.
Во всех экспериментах в этой части используется 18-блочная модель GPT, подобная декодеру шириной 768 пикселей, в наборе данных CodeParrot. Этот набор данных достаточно велик, поэтому, когда автор Когда в В режиме одной эпохи обучения разрыв в обобщении очень мал (см. рисунок 2), что позволяет им сосредоточиться на скорости обучения.
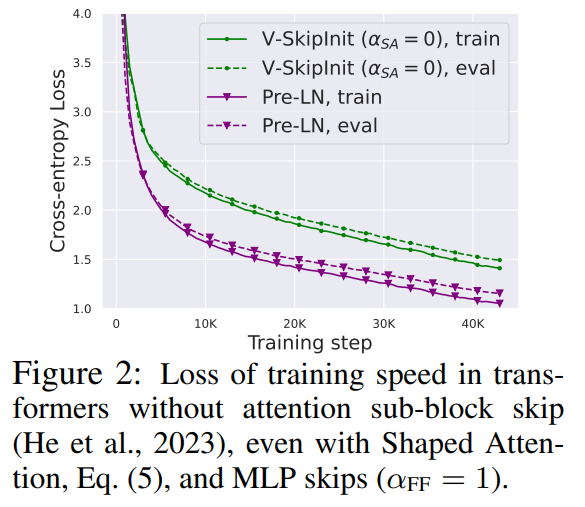
Удалить остаточное соединение
#Исследователь сначала рассмотрел возможность удаления остаточного соединения в подблоке внимания. В обозначениях уравнения (1) это эквивалентно фиксированию α_SA равным 0. Простое удаление остаточных связей внимания может привести к ухудшению сигнала, то есть коллапсу рангов, что приведет к плохой обучаемости. В разделе 4.1 статьи исследователи подробно объясняют свой метод. 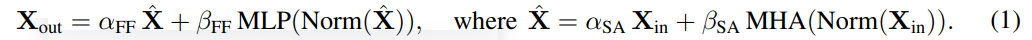
Удалить параметры проекции/значения
Из рисунка 3 можно сделать вывод, что значение и параметры проекции W^ полностью удалены V, W^P возможны с минимальной потерей скорости обучения на каждое обновление. То есть, когда β_V = β_P = 0 и инициализирован идентификатор 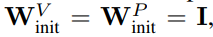
Удалить остаточное соединение субблока MLP
По сравнению с вышеуказанными модулями, удаление остаточного соединения субблока MLP требует Более сложной. Как и в предыдущем исследовании, авторы обнаружили, что при использовании Адама без остаточных связей MLP создание более линейных активаций за счет распространения сигнала все равно приводило к значительному снижению скорости обучения на каждое обновление, как показано на рисунке 22. 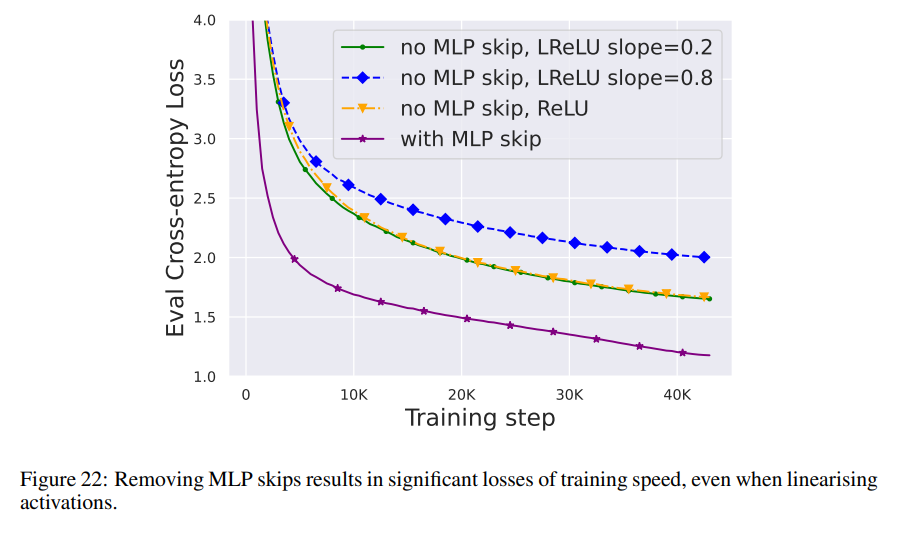
Они также пробовали различные варианты инициализации Looks Linear, включая гауссовы веса, ортогональные веса или тождественные веса, но безрезультатно. Поэтому они используют стандартные активации (например, ReLU) на протяжении всей своей работы и инициализации в подблоках MLP.
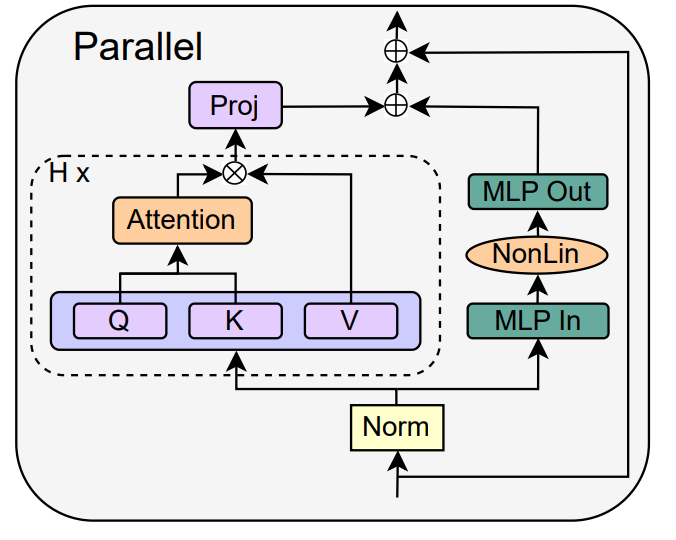
Автор подробно описывает конкретную операцию удаления остаточных соединений субблока MLP в разделе 4.3 статьи.
Удалить слой нормализацииПоследнее, что нужно удалить, это слой нормализации, чтобы получился простейший блок в правом верхнем углу рисунка 1. С точки зрения инициализации распространения сигнала авторы могут удалить уровень нормализации на любом этапе упрощения в этом разделе. Их идея состоит в том, что нормализация в блоке Pre-LN неявно уменьшает вес остаточных ветвей, и этот полезный эффект можно воспроизвести без слоя нормализации с помощью другого механизма: либо в При использовании остаточных соединений явно уменьшить вес остаточной ветви или сместить матрицу внимания в сторону идентичности/преобразовать нелинейность MLP в «большую» линейность.
Поскольку автор учел эти механизмы в процессе модификации (например, уменьшение веса MLP β_FF и Shaped Attention), в нормализации нет необходимости. Более подробную информацию авторы представляют в разделе 4.4.
Результаты экспериментовРасширение по глубине
Учитывая, что теория распространения сигнала обычно фокусируется на больших глубинах, в данном случае ухудшение сигнала обычно происходит. Поэтому возникает естественный вопрос: может ли улучшенная скорость обучения, достигнутая с помощью нашего упрощенного трансформаторного блока, масштабироваться и на большую глубину?
###Из рисунка 6 видно, что после увеличения глубины с 18 блоков до 72 блоков производительность как модели, так и преобразователя Pre-LN в этом исследовании улучшается, что указывает на упрощение в этом исследовании. Модели не только тренируются быстрее, но и используют дополнительную мощность, обеспечиваемую большей глубиной. Фактически, когда используется нормализация, траектории упрощенного блока и Pre-LN за каждое обновление в этом исследовании почти неразличимы на разных глубинах. ###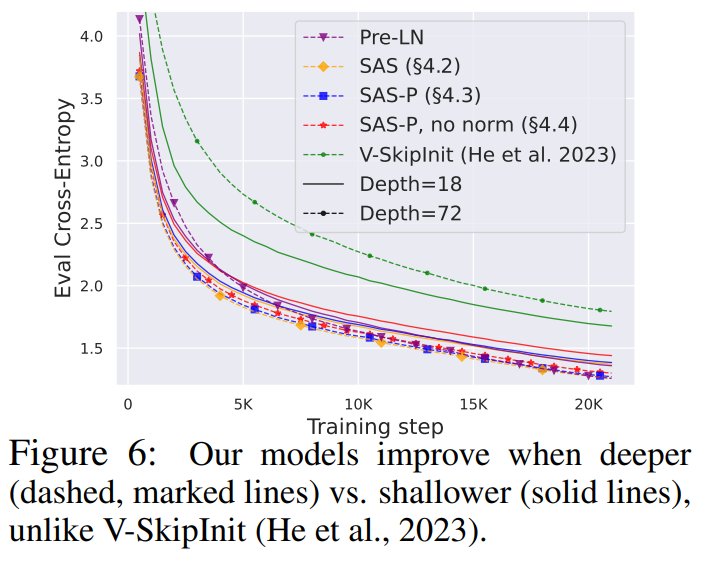
BERT
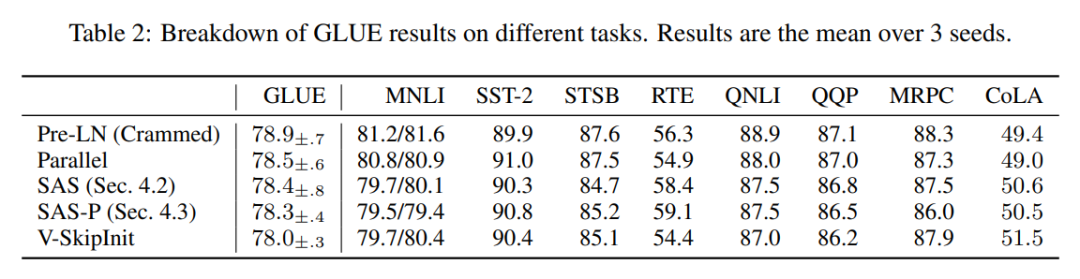
Далее авторы показывают, что их упрощенная производительность блоков применима к различным наборам данных и архитектурам, а также к последующим задачам. Они выбрали популярную настройку модели BERT только для двунаправленного кодировщика для моделирования языка в масках и использовали нисходящий тест GLUE.
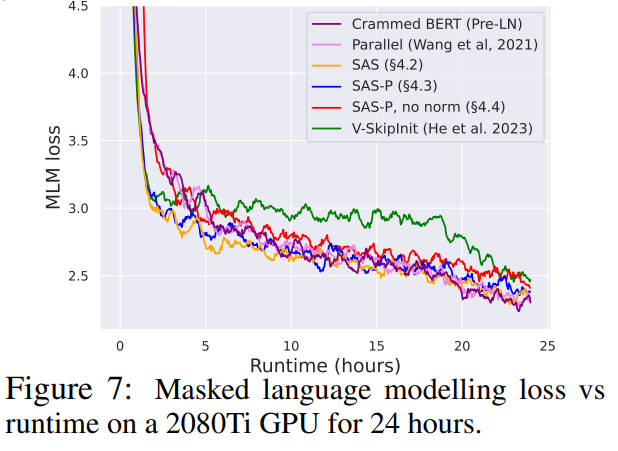
Как показано на рисунке 7, в течение 24 часов выполнения упрощенные блоки этого исследования сопоставимы со скоростью предварительного обучения задачи моделирования языка в масках по сравнению с базовым уровнем (набором) Pre-LN. С другой стороны, удаление остаточных связей без изменения значений и проекций снова приводит к значительному снижению скорости обучения. На рисунке 24 авторы представляют эквивалентную схему микросерийного этапа.
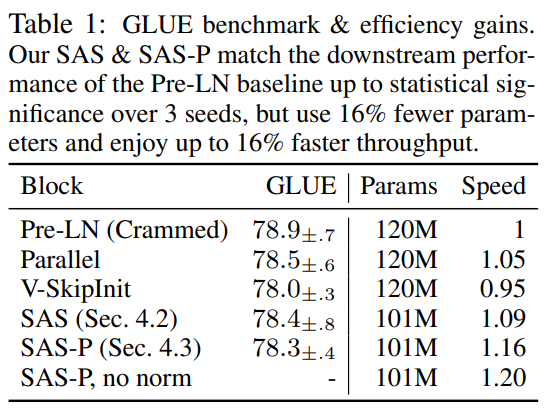
Повышение эффективности
#В Таблице 1 исследователь также подробно описывает использование различных блоков Transformer в языке маскировки Количество параметров и скорость обучения в задаче моделирования. Они рассчитали скорость как отношение количества микропакетных шагов, выполненных в течение 24 часов предварительной тренировки, к базовому уровню BERT Pre-LN Crammed. Вывод таков: модель использует на 16 % меньше параметров, а SAS-P и SAS работают на итерацию на 16 % и 9 % быстрее, чем блок Pre-LN соответственно. Можно отметить, что в данной реализации параллельный блок всего на 5% быстрее, чем блок Pre-LN, тогда как скорость обучения, наблюдаемая Чоудхери и др. (2022), на 15% быстрее, что указывает на то, что благодаря реализации оптимизации общая скорость обучения может быть дополнительно улучшена. Как и Geiping & Goldstein (2023), в этой реализации также используется технология автоматического объединения операторов в PyTorch (Sarofeen et al., 2022).Длительное обучение
Наконец, учитывая текущую тенденцию обучения меньших моделей на большем количестве данных в течение более длительных периодов времени, исследователи обсудили упрощение блоков в течение более длительных периодов времени. Можно ли достичь скорости обучения блока Pre-LN после тренировки. Для этого они используют модель на рисунке 5 на CodeParrot и тренируются с токенами 3x. Если быть точным, обучение занимает около 120 тыс. шагов (вместо 40 тыс. шагов) с размером пакета 128 и длиной последовательности 128, в результате чего получается около 2 млрд токенов. Как видно на рисунке 8, когда для обучения используется больше токенов, скорость обучения упрощенных кодовых блоков SAS и SAS-P по-прежнему сравнима или даже лучше, чем у кодовых блоков PreLN.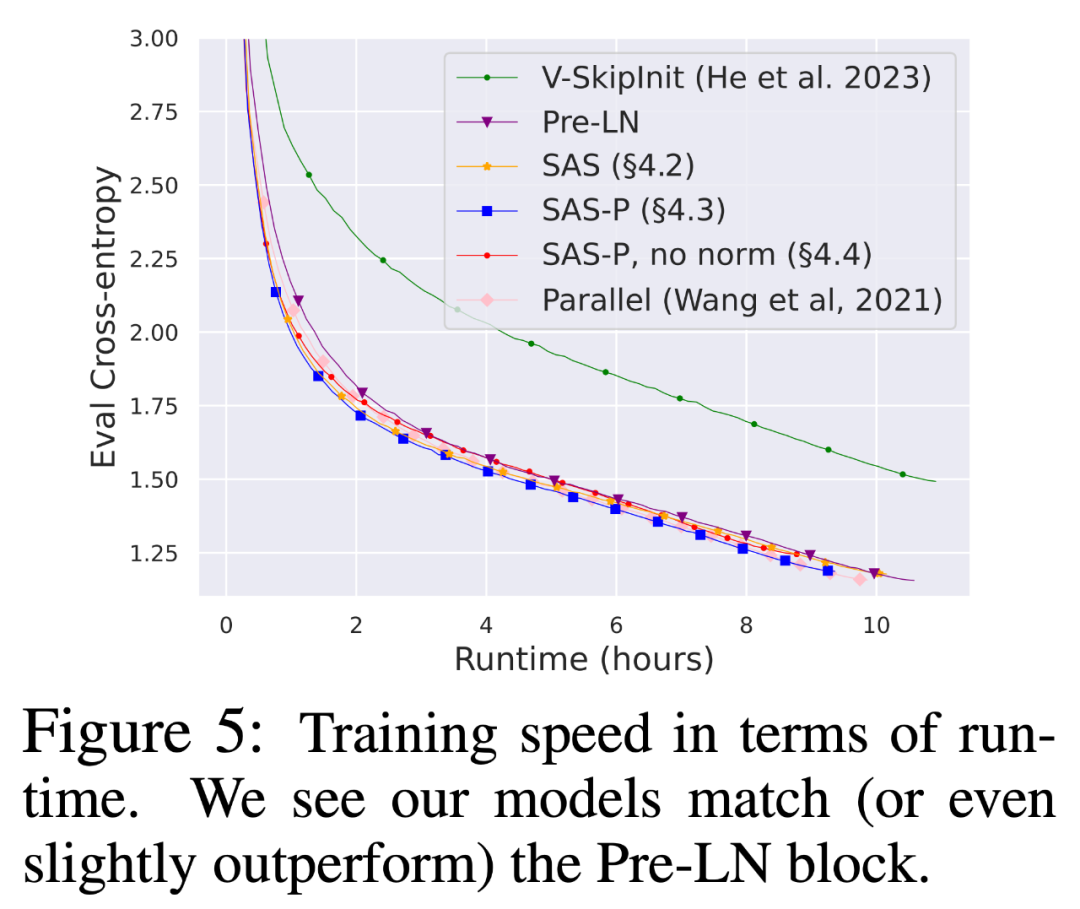
The above is the detailed content of Netizens praised: Transformer leads the simplified version of the annual paper is here. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
It is also a Tusheng video, but PaintsUndo has taken a different route. ControlNet author LvminZhang started to live again! This time I aim at the field of painting. The new project PaintsUndo has received 1.4kstar (still rising crazily) not long after it was launched. Project address: https://github.com/lllyasviel/Paints-UNDO Through this project, the user inputs a static image, and PaintsUndo can automatically help you generate a video of the entire painting process, from line draft to finished product. follow. During the drawing process, the line changes are amazing. The final video result is very similar to the original image: Let’s take a look at a complete drawing.
 Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com The authors of this paper are all from the team of teacher Zhang Lingming at the University of Illinois at Urbana-Champaign (UIUC), including: Steven Code repair; Deng Yinlin, fourth-year doctoral student, researcher
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com In the development process of artificial intelligence, the control and guidance of large language models (LLM) has always been one of the core challenges, aiming to ensure that these models are both powerful and safe serve human society. Early efforts focused on reinforcement learning methods through human feedback (RL
 arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
cheers! What is it like when a paper discussion is down to words? Recently, students at Stanford University created alphaXiv, an open discussion forum for arXiv papers that allows questions and comments to be posted directly on any arXiv paper. Website link: https://alphaxiv.org/ In fact, there is no need to visit this website specifically. Just change arXiv in any URL to alphaXiv to directly open the corresponding paper on the alphaXiv forum: you can accurately locate the paragraphs in the paper, Sentence: In the discussion area on the right, users can post questions to ask the author about the ideas and details of the paper. For example, they can also comment on the content of the paper, such as: "Given to
 A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
Recently, the Riemann Hypothesis, known as one of the seven major problems of the millennium, has achieved a new breakthrough. The Riemann Hypothesis is a very important unsolved problem in mathematics, related to the precise properties of the distribution of prime numbers (primes are those numbers that are only divisible by 1 and themselves, and they play a fundamental role in number theory). In today's mathematical literature, there are more than a thousand mathematical propositions based on the establishment of the Riemann Hypothesis (or its generalized form). In other words, once the Riemann Hypothesis and its generalized form are proven, these more than a thousand propositions will be established as theorems, which will have a profound impact on the field of mathematics; and if the Riemann Hypothesis is proven wrong, then among these propositions part of it will also lose its effectiveness. New breakthrough comes from MIT mathematics professor Larry Guth and Oxford University
 The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Introduction In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the basic model for many downstream tasks, current MLLM consists of the well-known Transformer network, which
 Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Show the causal chain to LLM and it learns the axioms. AI is already helping mathematicians and scientists conduct research. For example, the famous mathematician Terence Tao has repeatedly shared his research and exploration experience with the help of AI tools such as GPT. For AI to compete in these fields, strong and reliable causal reasoning capabilities are essential. The research to be introduced in this article found that a Transformer model trained on the demonstration of the causal transitivity axiom on small graphs can generalize to the transitive axiom on large graphs. In other words, if the Transformer learns to perform simple causal reasoning, it may be used for more complex causal reasoning. The axiomatic training framework proposed by the team is a new paradigm for learning causal reasoning based on passive data, with only demonstrations
