

| Introduction | The database is the core of all application systems, so ensuring the stable, efficient and safe operation of the database is the top priority of all enterprises' daily work. Once a problem occurs in the database system and it cannot provide services, it may cause the entire system to be unable to continue working. Therefore, a successful database architecture also needs to fully consider high-availability design. Below I will introduce to you how to build a highly available MySQL database system. |
The database is the core of all application systems, so ensuring the stable, efficient and safe operation of the database is the top priority of all enterprises' daily work. Once a problem occurs in the database system and it cannot provide services, it may cause the entire system to be unable to continue working. Therefore, a successful database architecture also needs to fully consider high-availability design. Below I will introduce to you how to build a highly available MySQL database system.
Students who have been a DBA or an operation and maintenance student should know that the existence of a single point for any device or service will bring huge risks, because once the physical machine goes down or the service module crashes, if it cannot be restored in a short period of time, Finding replacement equipment will inevitably affect the entire application system. Therefore, how to ensure that there is no single point is our important task. Using MySQL high availability solutions can solve this problem well. Generally, there are the following types:
1. Use MySQL’s own Replication to achieve high availabilityThe Replication that comes with MySQL is what we often call master-slave replication (AB replication). By making a slave machine for the master server, when the master server is down, the business can be quickly switched to the slave machine to ensure application reliability. Normal use. High-availability solutions using AB replication are also divided into several different architectures:
1. Conventional MASTER---SLAVE solutionOrdinary MASTER---SLAVE is currently the most commonly used architectural solution by most small and medium-sized companies at home and abroad. The main advantages are simplicity, less equipment (lower cost), and easy maintenance. This architecture can solve single-point problems and solve system performance problems to a large extent. A MASTER can be followed by one or more SLAVEs (master-slave cascade replication). However, this architecture requires that a MASTER must be able to satisfy all write requests of the system. Otherwise, horizontal splitting is required to share the reading pressure.
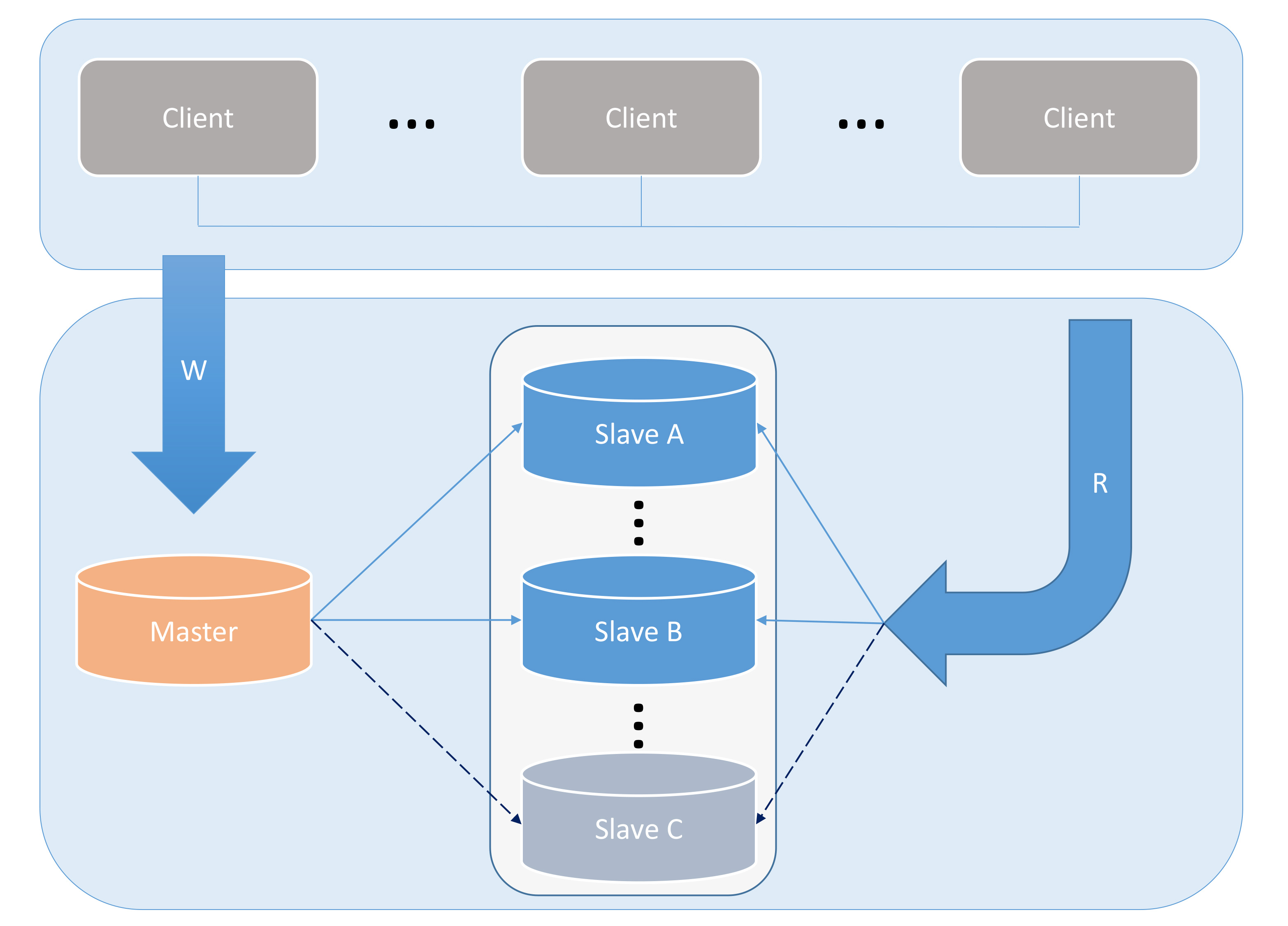
Figure 1
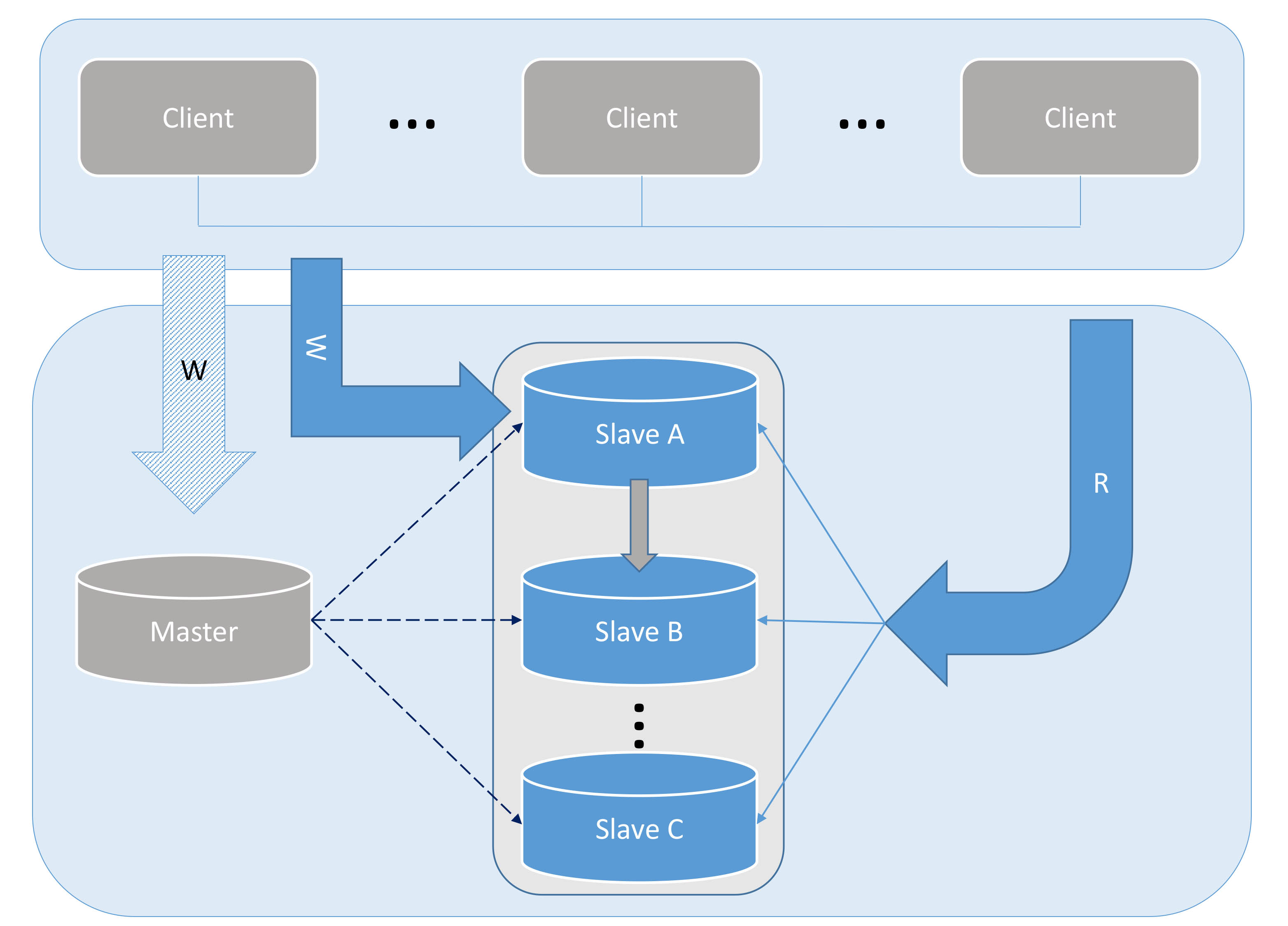
Figure II
Figures 1 to 2 show the process of solving single point problems and using read and write separation to improve performance.
2. Combination of DUAL MASTER and cascade replication
Dual master and multiple slaves is a more reasonable solution derived from the above solution. The advantage of this solution is that when either of the two main servers fails, the entire architecture does not require major adjustments.
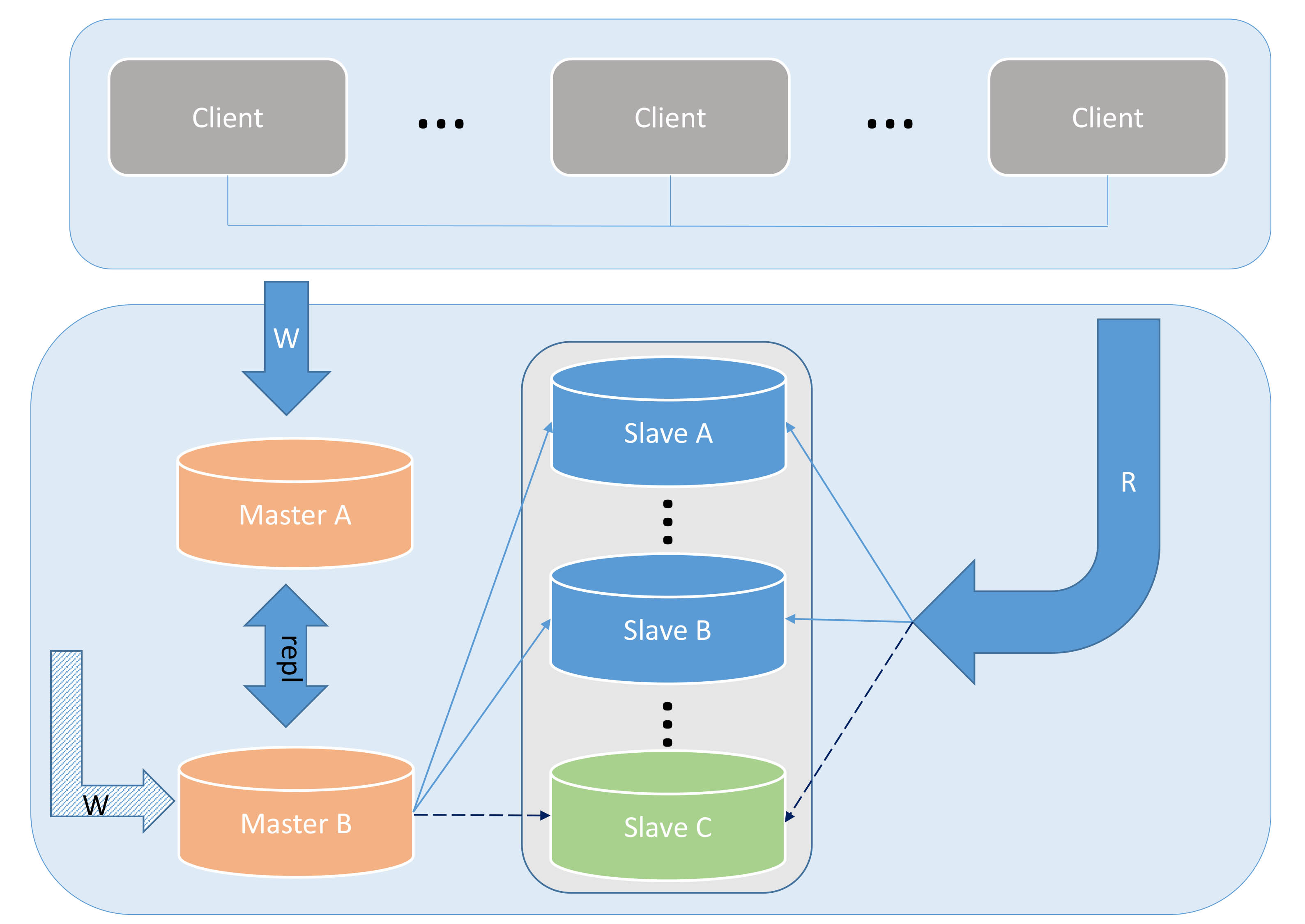
Figure 3
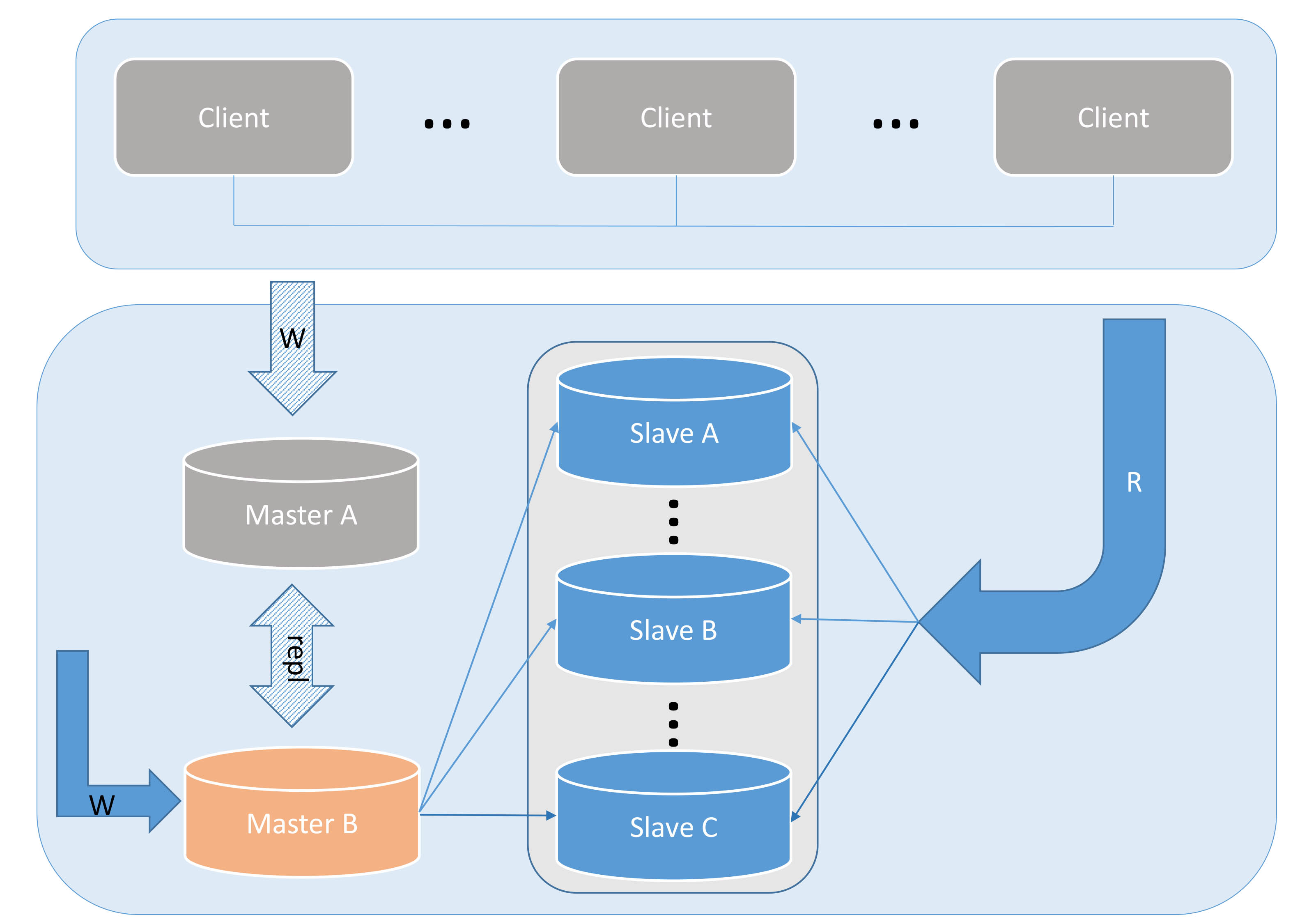
Figure 4
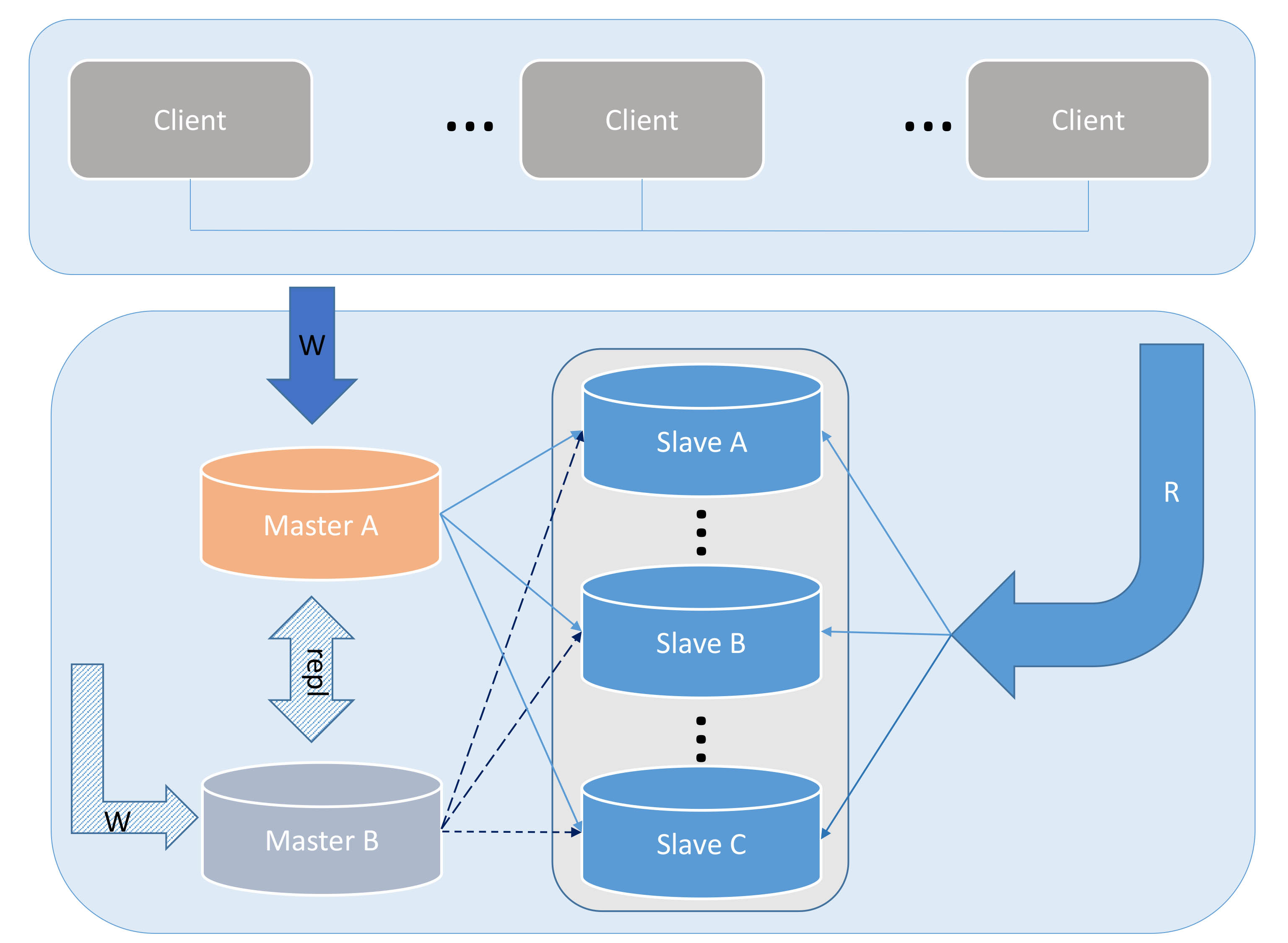
Figure 5
This process is shown in the picture above. But the situation in Figure 5 is quite special, that is, what should we do if MASTER-B goes down? The first thing that can be determined is that all our Write requests will not be affected in any way, and all Read requests can be accessed normally; but all Slave replication will be interrupted, and the data on the Slave will begin to lag. What we need to do at this time is to perform a CHANGE MASTER TO operation on all Slaves and copy them from Master A instead. Since all Slave replications cannot advance ahead of the original data source, the exact replication starting point can be found by comparing the timestamp information in the Relay Log on the Slave with the timestamp information in Master A to avoid data corruption. of loss.
2. Use MYSQL CLUSTER to achieve overall high availabilityFor now, the solution of using MYSQL CLUSTER to achieve overall high availability (that is, NDB CLUSTER) is not very popular among domestic companies. The NDB CLUSTER node is actually a multi-node MySQL server, but it does not contain data, so it can be used on any machine as long as it is installed. When a SQL node in the cluster crashes, the data will not be lost because the node does not store specific data. As shown in Figure 6:
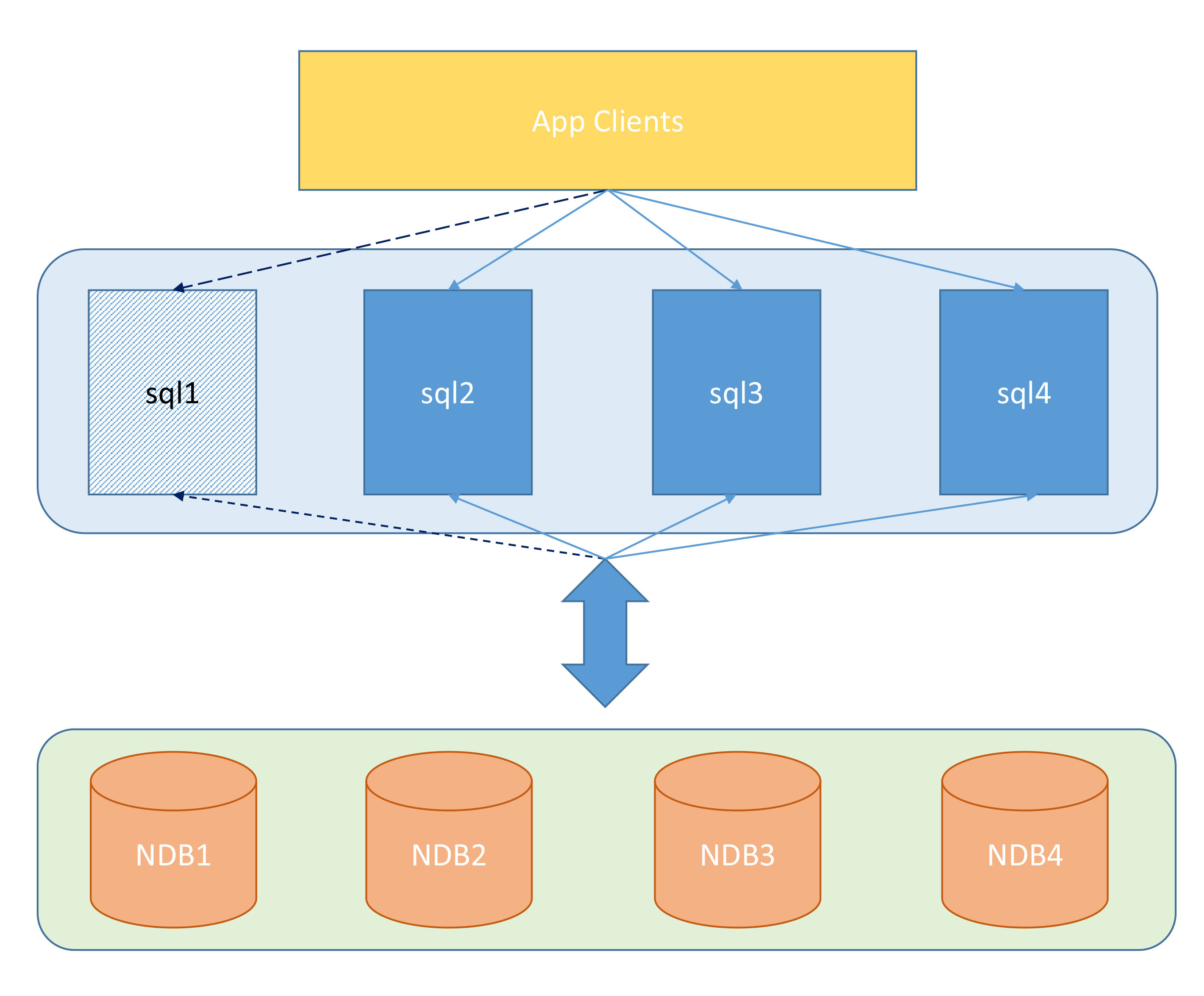
Figure 6
Among the current MySQL derivatives that achieve high availability, the most well-known and popular are GALERA CLUSTER and PERCONA XTRDB CLUSTER (PXC). The relevant content will not be described in this article for the time being. Interested students can check the relevant information to learn more. The implementation methods of these two clusters are similar, as shown in Figure 7 and Figure 8:
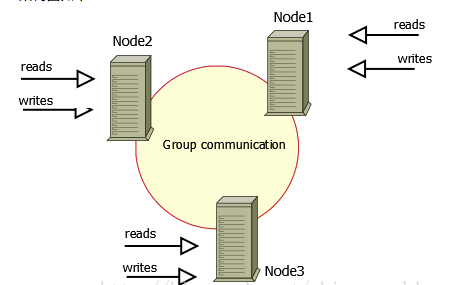
Figure 7
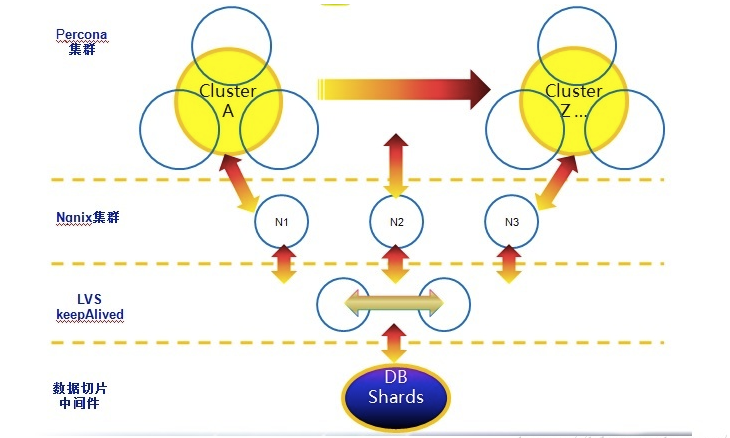
Figure 8
In the previous introduction to various high-availability design solutions, readers may have discovered that no matter which solution is used, it has its own unique advantages, but there are also more or less limitations. This section will conduct an analysis of the pros and cons of the above main options for your reference in the selection process.
1、MySQL ReplicationAdvantages: Simple deployment, easy implementation, and uncomplicated maintenance. It is a function that MySQL inherently supports. And it is easy to switch between the active and standby machines. The active and standby switching can be automatically completed through third-party software or self-written scripts.
Disadvantages: If the Master host hardware fails and cannot be restored, some data that has not been transmitted to the Slave may be lost.
2. MySQL Cluster (NDB)Advantages: Very high availability and very good performance. Each piece of data has at least one copy on different hosts, and redundant data copies are synchronized in real time.
Disadvantages: The maintenance is more complicated, the product is newer, there are some bugs, and it may not be suitable for core online systems at present.
3, GALERA CLUSTER and PERCONA XTRDB CLUSTER (PXC)Advantages: The reliability is very high. All nodes can read and write every piece of data at the same time. There is at least one copy on different hosts, and redundant data copies are synchronized in real time.
Disadvantages: As the scale of the cluster expands, the performance will become worse and worse.
4. The DRBD disk network mirroring solution that must be mentioned Architecturally, it is somewhat similar to Replication, except that it implements the data synchronization process through third-party software. The reliability is higher than Replication, but it also sacrifices performance.
Advantages: The software is powerful, data is mirrored across physical hosts at the underlying block device level, and different levels of synchronization can be configured based on performance and reliability requirements. IO operations maintain order, which can meet the stringent requirements of the database for data consistency.
Disadvantages: Non-distributed file system environments cannot support mirror data being visible at the same time, that is, performance and reliability are conflicting with each other, and cannot be applied to environments that have strict requirements for both. Maintenance costs are higher than MySQL Replication.
After talking about the advantages and disadvantages of various commonly used architectures, the remaining question is how to choose the appropriate architecture to use in a real production environment. Everyone has their own ideas and experiences in this regard, and which solution is the best is a matter of opinion. In daily work, the improvement of the architecture is not achieved overnight, but a process of continuous evolution, optimization and improvement.
In terms of database, Getui has also experienced the process from single point to master-slave to master-slave high availability. It has also experienced from a single MySQL redis to MySQL redis es, and finally to the current MySQL redis es codis, etc. Evolution. Every evolution is to solve practical problems and pain points in the production environment. From the perspective of MySQL alone, no architecture can solve all problems (pain points), and a suitable architecture needs to be selected based on the actual situation. The solution implemented by MySQL cluster is very flexible and changeable. It is also a challenge for MySQL workers to choose a suitable architecture. It is also the motivation for us to continue to study and learn MySQL.
The above is the detailed content of A brief analysis of MySQL architecture. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



