

| Introduction | Understanding the input/output (I/O) model of an application means the difference between its planned processing load and the brutal real-world usage scenarios. If the application is relatively small and does not serve a high load, it may have little impact. But as the load on your application gradually increases, adopting the wrong I/O model may leave you with many pitfalls and scars. |
As with most scenarios where there are multiple solutions, the focus is not on which approach is better, but on understanding how to make the trade-offs. Let's take a tour of the I/O landscape and see what we can steal from it.

In this article, we will compare Node, Java, Go, and PHP respectively with Apache, discuss how these different languages model their I/O, the advantages and disadvantages of each model, and draw conclusions Conclusions on some preliminary benchmarks. If you are concerned about the I/O performance of your next web application, then you have found the right article.
I/O Basics: A Quick ReviewIn order to understand the factors closely related to I/O, we must first review the concepts underlying the operating system. Although you won't deal with most of these concepts directly, you have been dealing with them indirectly through the application's runtime environment. And the devil is in the details.
System callFirst, we have the system call, which can be described like this:
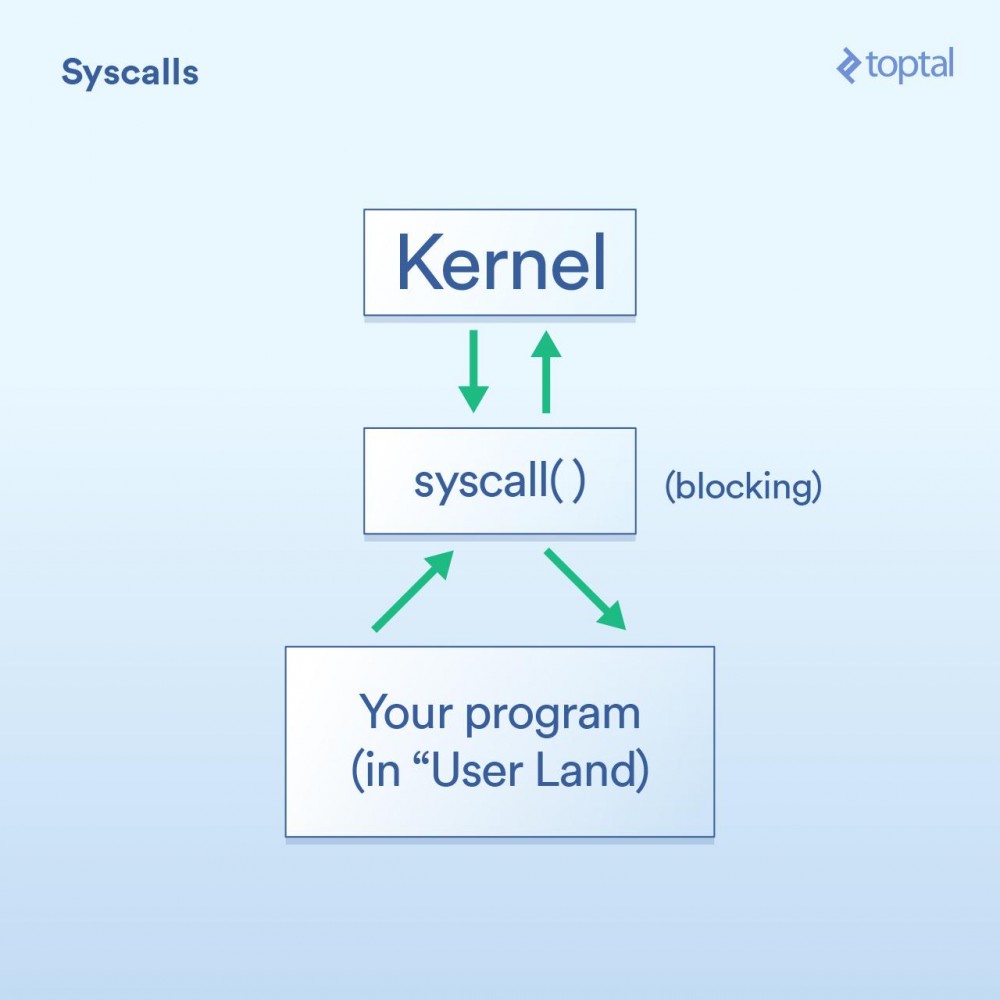
Okay, I just said above that system calls are blocking. Generally speaking, this is correct. However, some calls are classified as "non-blocking", meaning that the kernel receives your request, puts it in a queue or buffer somewhere, and then returns immediately without waiting for the actual I/O call. So it just "blocks" for a very short period of time, just enough to queue your request.
Here are some examples (Linux system calls) to help explain: -read() is a blocking call - you pass it a file handle and a buffer to store the data read , and then this call will return when the data is ready. Note that this approach has the advantage of elegance and simplicity. -epoll_create() , epoll_ctl() , and epoll_wait() These calls, respectively, let you create a set of handles for listening, from the Group add/remove handles, and then block until there is activity. This allows you to efficiently control a series of I/O operations through a thread. This is great if you need these features, but as you can see, it's certainly quite complex to use.
It is important to understand the order of magnitude of the timing difference here. If a CPU core runs at 3GHz, without optimization, it executes 3 billion loops per second (or 3 loops per nanosecond). A non-blocking system call may take a period on the order of 10 nanoseconds to complete - or "relatively few nanoseconds". Blocking calls that are receiving information over the network may take more time - for example 200 milliseconds (0.2 seconds). For example, assuming the non-blocking call took 20 nanoseconds, then the blocking call took 200,000,000 nanoseconds. For blocking calls, your program waits 10 million times longer.

The kernel provides two methods: blocking I/O ("Read from the network connection and give me the data") and non-blocking I/O ("Tell me when these network connections have new data") . Depending on which mechanism is used, the blocking time of the corresponding calling process is obviously different.
SchedulingThe next third key thing is what to do when a large number of threads or processes start to block.
For our purposes, there is not much difference between threads and processes. In fact, the most obvious execution-related difference is that threads share the same memory, while each process has its own memory space, making separate processes often occupy large amounts of memory. But when we talk about scheduling, it ultimately boils down to a list of events (threads and processes alike) where each event needs to get a slice of execution time on an available CPU core. If you have 300 threads running and you're running on 8 cores, you have to spread that time out so that each thread gets something by running each core for a short period of time and then switching to the next thread. Its time sharing. This is achieved by "context switching", which allows the CPU to switch from one thread/process that is running to the next.
These context switches have a cost - they consume some time. When fast, it's probably less than 100 nanoseconds, but it's not uncommon to take 1000 nanoseconds or more depending on implementation details, processor speed/architecture, CPU cache, etc.
The more threads (or processes) there are, the more context switches there are. When we're talking about thousands of threads and each switch takes hundreds of nanoseconds, it's going to be very slow.
However, a non-blocking call essentially tells the kernel "call me only when you have some new data or there is an event on any of these connections." These non-blocking calls are designed to handle large I/O loads efficiently and reduce context switches.
Are you still reading this article so far? Because now comes the fun part: let's take a look at how some fluent languages use these tools and draw some conclusions about the trade-offs between ease of use and performance... and other interesting comments.
Please note that while the examples shown in this post are trivial (and are incomplete, only showing the relevant parts of the code), database access, external caching systems (memcache, etc. all) and require I/ Everything in O ends up performing some underlying I/O operations, which have the same impact as the examples shown. Likewise, for situations where I/O is described as "blocking" (PHP, Java), the reading and writing of HTTP requests and responses are themselves blocking calls: once again, more I/O is hidden in the system O and its accompanying performance issues need to be considered.
There are many factors to consider when choosing a programming language for your project. When you only consider performance, there are even more factors to consider. However, if your concern is that your program is primarily I/O bound, and if I/O performance is critical to your project, then these are the things you need to know. The "keep it simple" approach: PHP.
Back in the 1990s, a lot of people wore Converse shoes and wrote CGI scripts in Perl. Then PHP appeared, and many people liked to use it, which made it easier to create dynamic web pages.
The model used by PHP is quite simple. There are some variations, but basically a PHP server looks like:
The HTTP request comes from the user's browser and accesses your Apache web server. Apache creates a separate process for each request, reusing them with some optimizations to minimize the number of times it needs to execute (creating processes is relatively slow). Apache calls PHP and tells it to run the corresponding .php file on disk. The PHP code executes and makes some blocking I/O calls. If file_get_contents() is called in PHP, it will trigger the read() system call behind the scenes and wait for the result to be returned.
Of course, the actual code is simply embedded in your page, and the operation is blocking:
<?php
// 阻塞的文件I/O
$file_data = file_get_contents('/path/to/file.dat');
// 阻塞的网络I/O
$curl = curl_init('http://example.com/example-microservice');
$result = curl_exec($curl);
// 更多阻塞的网络I/O
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
?>About how it integrates with the system, like this:
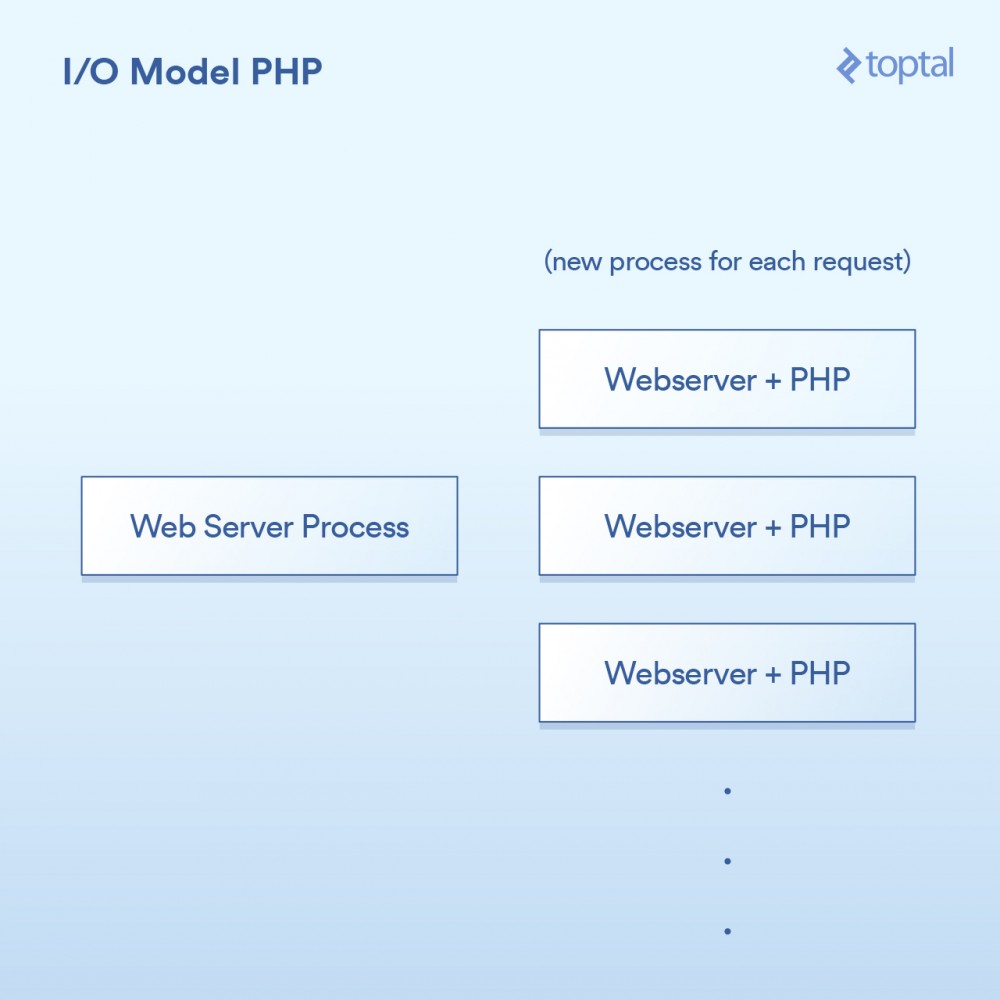
相当简单:一个请求,一个进程。I/O是阻塞的。优点是什么呢?简单,可行。那缺点是什么呢?同时与20,000个客户端连接,你的服务器就挂了。由于内核提供的用于处理大容量I/O(epoll等)的工具没有被使用,所以这种方法不能很好地扩展。更糟糕的是,为每个请求运行一个单独的过程往往会使用大量的系统资源,尤其是内存,这通常是在这样的场景中遇到的第一件事情。
注意:Ruby使用的方法与PHP非常相似,在广泛而普遍的方式下,我们可以将其视为是相同的。
多线程的方式:Java所以就在你买了你的第一个域名的时候,Java来了,并且在一个句子之后随便说一句“dot com”是很酷的。而Java具有语言内置的多线程(特别是在创建时),这一点非常棒。
大多数Java网站服务器通过为每个进来的请求启动一个新的执行线程,然后在该线程中最终调用作为应用程序开发人员的你所编写的函数。
在Java的Servlet中执行I/O操作,往往看起来像是这样:
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// 阻塞的文件I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// 阻塞的网络I/O
URLConnection urlConnection = (new URL("https://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// 更多阻塞的网络I/O
out.println("...");
}由于我们上面的doGet 方法对应于一个请求并且在自己的线程中运行,而不是每次请求都对应需要有自己专属内存的单独进程,所以我们会有一个单独的线程。这样会有一些不错的优点,例如可以在线程之间共享状态、共享缓存的数据等,因为它们可以相互访问各自的内存,但是它如何与调度进行交互的影响,仍然与前面PHP例子中所做的内容几乎一模一样。每个请求都会产生一个新的线程,而在这个线程中的各种I/O操作会一直阻塞,直到这个请求被完全处理为止。为了最小化创建和销毁它们的成本,线程会被汇集在一起,但是依然,有成千上万个连接就意味着成千上万个线程,这对于调度器是不利的。
一个重要的里程碑是,在Java 1.4 版本(和再次显著升级的1.7 版本)中,获得了执行非阻塞I/O调用的能力。大多数应用程序,网站和其他程序,并没有使用它,但至少它是可获得的。一些Java网站服务器尝试以各种方式利用这一点; 然而,绝大多数已经部署的Java应用程序仍然如上所述那样工作。
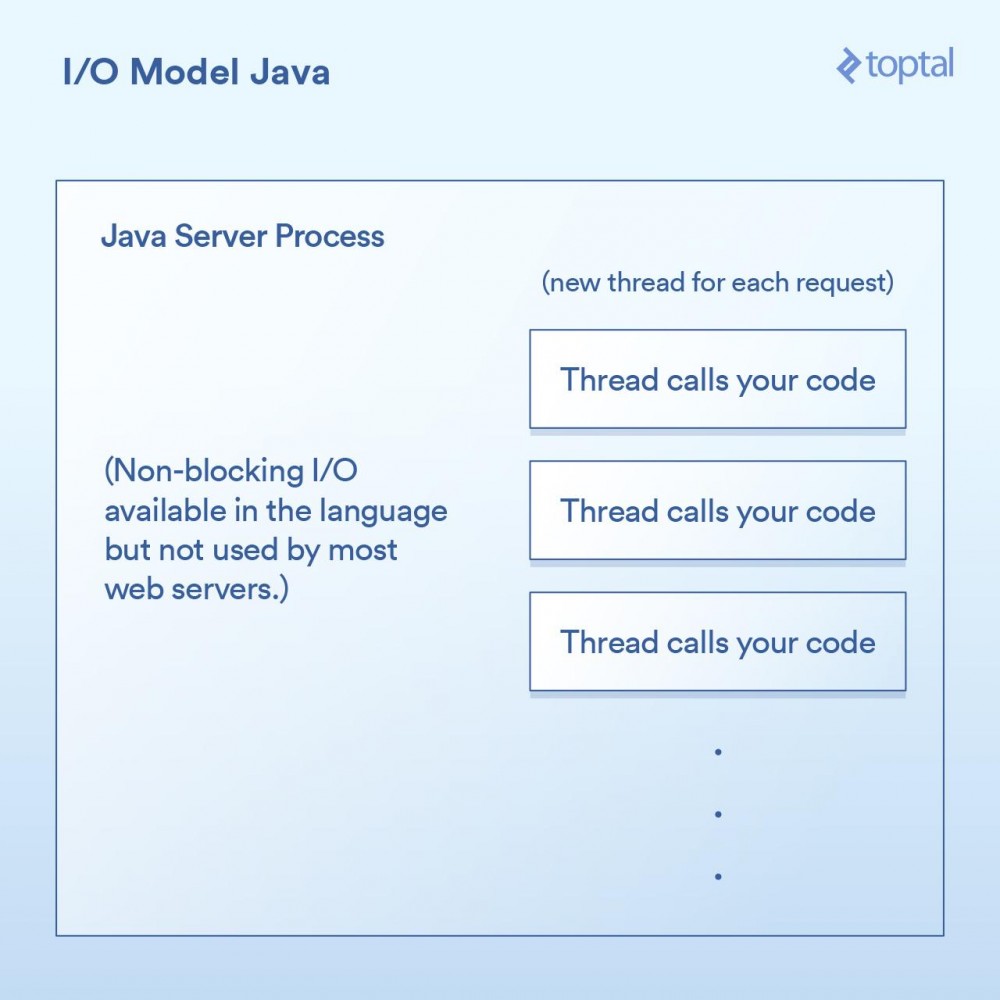
Java让我们更进了一步,当然对于I/O也有一些很好的“开箱即用”的功能,但它仍然没有真正解决问题:当你有一个严重I/O绑定的应用程序正在被数千个阻塞线程狂拽着快要坠落至地面时怎么办。
作为一等公民的非阻塞I/O:Node当谈到更好的I/O时,Node.js无疑是新宠。任何曾经对Node有过最简单了解的人都被告知它是“非阻塞”的,并且它能有效地处理I/O。在一般意义上,这是正确的。但魔鬼藏在细节中,当谈及性能时这个巫术的实现方式至关重要。
本质上,Node实现的范式不是基本上说“在这里编写代码来处理请求”,而是转变成“在这里写代码开始处理请求”。每次你都需要做一些涉及I/O的事情,发出请求或者提供一个当完成时Node会调用的回调函数。
在求中进行I/O操作的典型Node代码,如下所示:
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});可以看到,这里有两个回调函数。第一个会在请求开始时被调用,而第二个会在文件数据可用时被调用。
这样做的基本上给了Node一个在这些回调函数之间有效地处理I/O的机会。一个更加相关的场景是在Node中进行数据库调用,但我不想再列出这个烦人的例子,因为它是完全一样的原则:启动数据库调用,并提供一个回调函数给Node,它使用非阻塞调用单独执行I/O操作,然后在你所要求的数据可用时调用回调函数。这种I/O调用队列,让Node来处理,然后获取回调函数的机制称为“事件循环”。它工作得非常好。
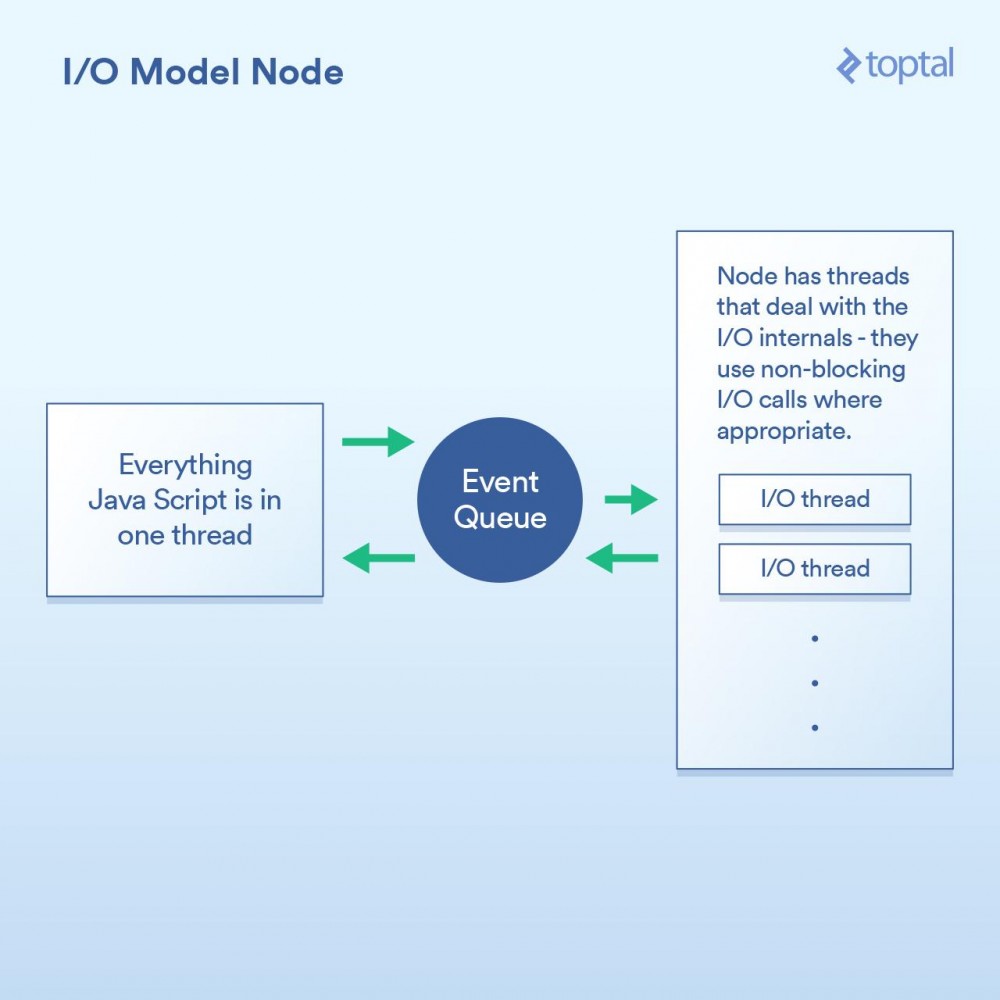
然而,这个模型中有一道关卡。在幕后,究其原因,更多是如何实现JavaScript V8 引擎(Chrome的JS引擎,用于Node)1,而不是其他任何事情。你所编写的JS代码全部都运行在一个线程中。思考一下。这意味着当使用有效的非阻塞技术执行I/O时,正在进行CPU绑定操作的JS可以在运行在单线程中,每个代码块阻塞下一个。 一个常见的例子是循环数据库记录,在输出到客户端前以某种方式处理它们。以下是一个例子,演示了它如何工作:
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// 对每一行纪录进行处理
}
response.end(...); // 输出结果
})
};虽然Node确实可以有效地处理I/O,但上面的例子中的for 循环使用的是在你主线程中的CPU周期。这意味着,如果你有10,000个连接,该循环有可能会让你整个应用程序慢如蜗牛,具体取决于每次循环需要多长时间。每个请求必须分享在主线程中的一段时间,一次一个。
这个整体概念的前提是I/O操作是最慢的部分,因此最重要是有效地处理这些操作,即使意味着串行进行其他处理。这在某些情况下是正确的,但不是全都正确。
另一点是,虽然这只是一个意见,但是写一堆嵌套的回调可能会令人相当讨厌,有些人认为它使得代码明显无章可循。在Node代码的深处,看到嵌套四层、嵌套五层、甚至更多层级的嵌套并不罕见。
我们再次回到了权衡。如果你主要的性能问题在于I/O,那么Node模型能很好地工作。然而,它的阿喀琉斯之踵(
真正的非阻塞:Go在进入Go这一章节之前,我应该披露我是一名Go粉丝。我已经在许多项目中使用Go,是其生产力优势的公开支持者,并且在使用时我在工作中看到了他们。
也就是说,我们来看看它是如何处理I/O的。Go语言的一个关键特性是它包含自己的调度器。并不是每个线程的执行对应于一个单一的OS线程,Go采用的是“goroutines”这一概念。Go运行时可以将一个goroutine分配给一个OS线程并使其执行,或者把它挂起而不与OS线程关联,这取决于goroutine做的是什么。来自Go的HTTP服务器的每个请求都在单独的Goroutine中处理。
此调度器工作的示意图,如下所示:

这是通过在Go运行时的各个点来实现的,通过将请求写入/读取/连接/等实现I/O调用,让当前的goroutine进入睡眠状态,当可采取进一步行动时用信息把goroutine重新唤醒。
实际上,除了回调机制内置到I/O调用的实现中并自动与调度器交互外,Go运行时做的事情与Node做的事情并没有太多不同。它也不受必须把所有的处理程序代码都运行在同一个线程中这一限制,Go将会根据其调度器的逻辑自动将Goroutine映射到其认为合适的OS线程上。最后代码类似这样:
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// 这里底层的网络调用是非阻塞的
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// 处理rows
// 每个请求在它自己的goroutine中
}
w.Write(...) // 输出响应结果,也是非阻塞的
}正如你在上面见到的,我们的基本代码结构像是更简单的方式,并且在背后实现了非阻塞I/O。
在大多数情况下,这最终是“两个世界中最好的”。非阻塞I/O用于全部重要的事情,但是你的代码看起来像是阻塞,因此往往更容易理解和维护。Go调度器和OS调度器之间的交互处理了剩下的部分。这不是完整的魔法,如果你建立的是一个大型的系统,那么花更多的时间去理解它工作原理的更多细节是值得的; 但与此同时,“开箱即用”的环境可以很好地工作和很好地进行扩展。
Go可能有它的缺点,但一般来说,它处理I/O的方式不在其中。
谎言,诅咒的谎言和基准对这些各种模式的上下文切换进行准确的定时是很困难的。也可以说这对你来没有太大作用。所以取而代之,我会给出一些比较这些服务器环境的HTTP服务器性能的基准。请记住,整个端对端的HTTP请求/响应路径的性能与很多因素有关,而这里我放在一起所提供的数据只是一些样本,以便可以进行基本的比较。
对于这些环境中的每一个,我编写了适当的代码以随机字节读取一个64k大小的文件,运行一个SHA-256哈希N次(N在URL的查询字符串中指定,例如.../test.php?n=100 ),并以十六进制形式打印生成的散列。我选择了这个示例,是因为使用一些一致的I/O和一个受控的方式增加CPU使用率来运行相同的基准测试是一个非常简单的方式。
Regarding environment usage, please refer to these benchmark points for more details.
First, let’s look at some low-concurrency examples. Running 2000 iterations, 300 concurrent requests, and only hashing once per request (N = 1), you can get:
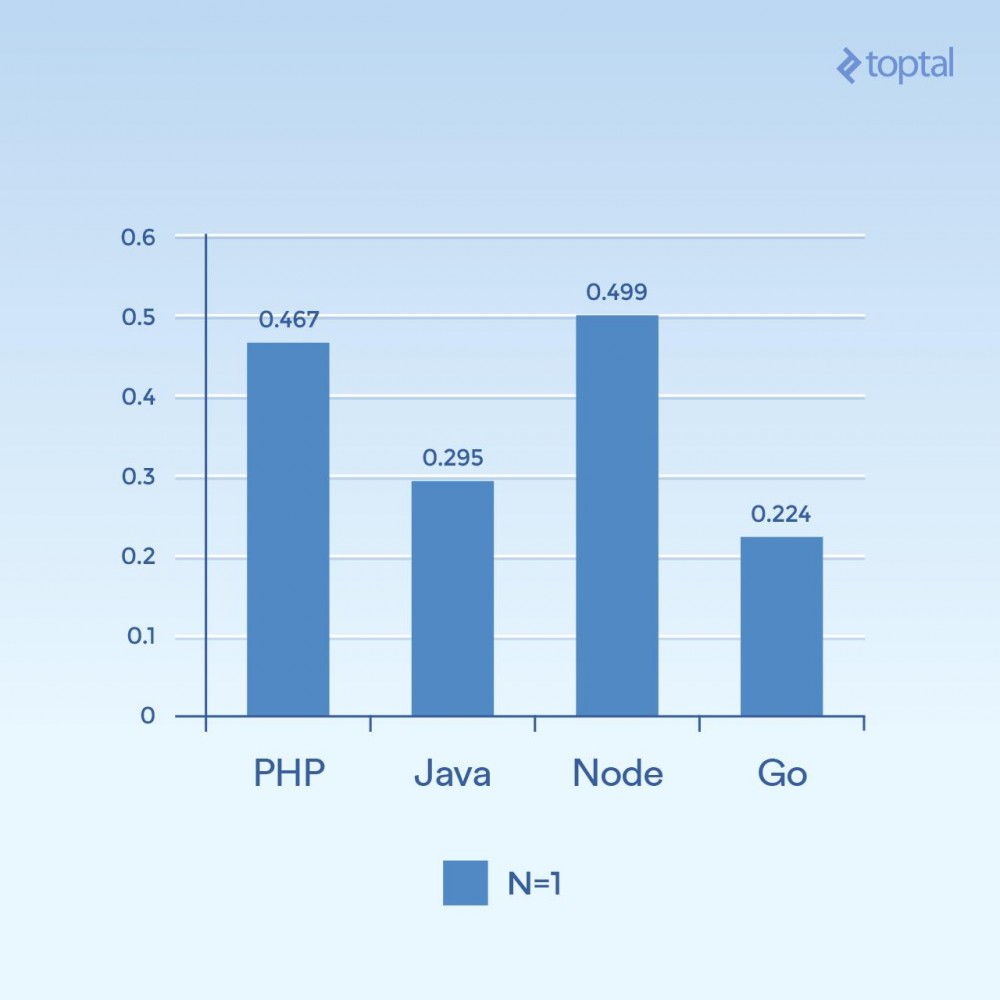
Time is the average number of milliseconds it takes to complete a request among all concurrent requests. The lower the better.
It's hard to draw conclusions from just one graph, but to me it seems that related to aspects like connectivity and computation volume, we see that the time has more to do with the general execution of the language itself, so it's more in I/ O. Note that languages that are considered "scripting languages" (arbitrary input, dynamically interpreted) perform the slowest.
But what happens if you increase N to 1000 and still have 300 requests concurrently - the same load, but the hash iterations are 100 times higher than before (significantly increasing the CPU load):
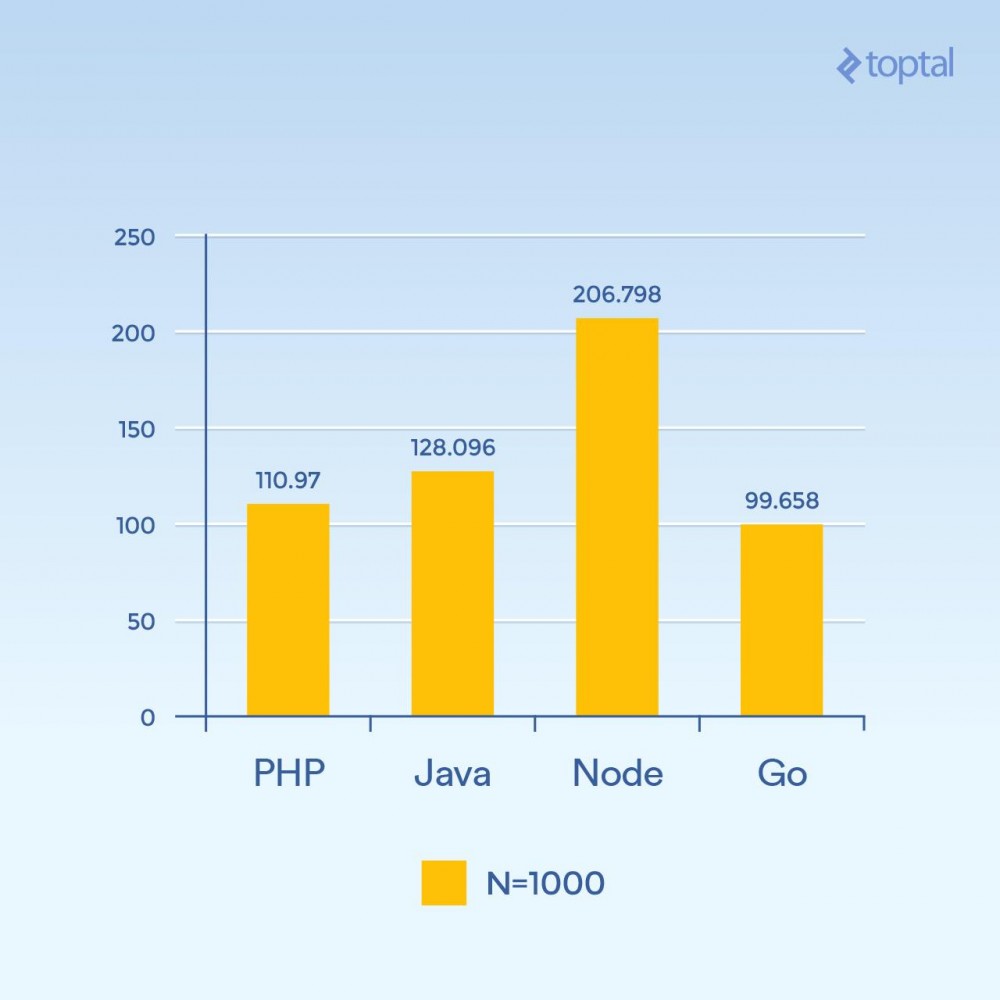
Time is the average number of milliseconds it takes to complete a request among all concurrent requests. The lower the better.
Suddenly, Node's performance dropped significantly because the CPU-intensive operations in each request blocked each other. Interestingly, in this test, PHP performed much better (relative to other languages) and beat Java. (It's worth noting that in PHP, where the SHA-256 implementation is written in C, the execution path takes more time in this loop because this time we do 1000 hash iterations).
Now let's try 5000 concurrent connections (and N = 1) - or close to that. Unfortunately, for most of these environments, the failure rate is not significant. For this chart, we'll focus on the total number of requests per second. The higher the better:
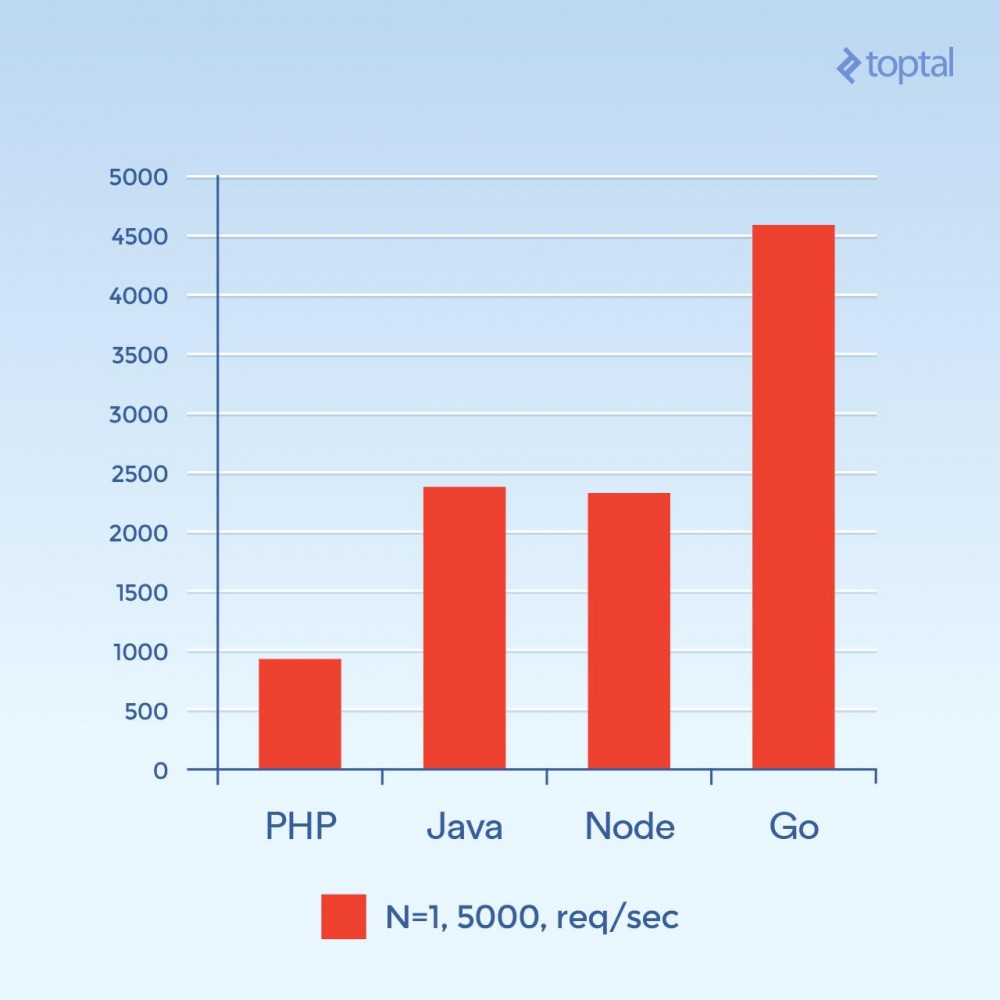
Total number of requests per second. The higher the better.
This photo looks completely different. This is a guess, but it looks like for high connection volume, the overhead associated with spawning a new process per connection, and the extra memory associated with PHP Apache seems to be the major factor and restrict PHP's performance. Clearly, Go is the winner here, followed by Java and Node, and finally PHP.
in conclusionIn summary, it is clear that as languages evolve, so do the solutions for large applications that handle large amounts of I/O.
For the sake of fairness, setting aside the description of this article for the time being, PHP and Java do have implementations of non-blocking I/O that can be used for web applications. But these methods are not as common as the above methods, and the attendant operational overhead of maintaining the server using this method needs to be considered. Not to mention that your code must be structured in a way that is appropriate for these environments; "normal" PHP or Java web applications generally do not undergo significant changes in such environments.
For comparison, if we only consider several important factors that affect performance and ease of use, we can get:
| language | Thread or process | Non-blocking I/O | Ease of use | |
|---|---|---|---|---|
| PHP | process | no | ||
| Java | Thread | Available | Need callback | |
| Node.js | Thread | yes | Need callback | |
| Go | Thread (Goroutine) | yes | No callback required |
Threads are generally more memory efficient than processes because they share the same memory space, while processes do not. Combined with factors related to non-blocking I/O, when we move down the list to general startup as it relates to improving I/O, one can see at least the same factors as those considered above. If I had to pick a winner among the games above, it would definitely be Go.
Even so, in practice, the environment in which you choose to build your application is closely related to your team's familiarity with said environment and the overall productivity that can be achieved. Therefore, it may not make sense for every team to just jump in and start developing web applications and services in Node or Go. In fact, finding familiarity with developers or internal teams is often cited as the main reason not to use a different language and/or a different environment. In other words, times have changed dramatically in the past fifteen years.
Hopefully the above helps you gain a clearer understanding of what's going on behind the scenes and gives you some ideas on how to handle real-world scalability of your application. Happy input, happy output!
The above is the detailed content of Comparing server I/O performance of Node, PHP, Java, and Go. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



