
 Technology peripherals
AI
Sun Yat-sen University's new spatiotemporal knowledge embedding framework drives the latest progress in video scene graph generation tasks, published in TIP '24
Technology peripherals
AI
Sun Yat-sen University's new spatiotemporal knowledge embedding framework drives the latest progress in video scene graph generation tasks, published in TIP '24
Sun Yat-sen University's new spatiotemporal knowledge embedding framework drives the latest progress in video scene graph generation tasks, published in TIP '24

Video Scene Graph Generation (VidSGG) aims to identify objects in visual scenes and infer visual relationships between them.
The task requires not only a comprehensive understanding of each object scattered throughout the scene, but also an in-depth study of their movement and interaction over time.
Recently, researchers from Sun Yat-sen University published a paper in the top artificial intelligence journal IEEE T-IP. They explored related tasks and found that: each pair of object combinations and The relationship between them has spatial co-occurrence correlation within each image, and temporal consistency/translation correlation between different images.

Paper link: https://arxiv.org/abs/2309.13237
Based on these first Based on prior knowledge, the researchers proposed a Transformer (STKET) based on spatiotemporal knowledge embedding to incorporate prior spatiotemporal knowledge into the multi-head cross attention mechanism to learn more representative visual relationship representations.
Specifically, spatial co-occurrence and temporal transformation correlation are first statistically learned; then, a spatiotemporal knowledge embedding layer is designed to fully explore the interaction between visual representation and knowledge. , respectively generate spatial and temporal knowledge-embedded visual relation representations; finally, the authors aggregate these features to predict the final semantic labels and their visual relations.
Extensive experiments show that the framework proposed in this article is significantly better than the current competing algorithms. Currently, the paper has been accepted.
Paper Overview
With the rapid development of the field of scene understanding, many researchers have begun to try to use various frameworks to solve scene graph generation ( Scene Graph Generation (SGG) task and has made considerable progress.
However, these methods often only consider the situation of a single image and ignore the large amount of contextual information existing in the time series, resulting in the inability of most existing scene graph generation algorithms to accurately Identify dynamic visual relationships contained in a given video.
Therefore, many researchers are committed to developing Video Scene Graph Generation (VidSGG) algorithms to solve this problem.
Current work focuses on aggregating object-level visual information from spatial and temporal perspectives to learn corresponding visual relationship representations.
However, due to the large variance in the visual appearance of various objects and interactive actions and the significant long-tail distribution of visual relationships caused by video collection, simply using visual information alone can easily lead to model predictions Wrong visual relationship.
In response to the above problems, researchers have done the following two aspects of work:
Firstly, it is proposed to mine the prior space-time contained in the training samples. Knowledge is used to advance the field of video scene graph generation. Among them, prior spatiotemporal knowledge includes:
1) Spatial co-occurrence correlation: The relationship between certain object categories tends to specific interactions.
2) Temporal consistency/transition correlation: A given pair of relationships tends to be consistent across consecutive video clips, or has a high probability of transitioning to another specific relationship.
Secondly, a novel Transformer (Spatial-Temporal Knowledge-Embedded Transformer, STKET) framework based on spatial-temporal knowledge embedding is proposed.
This framework incorporates prior spatiotemporal knowledge into the multi-head cross-attention mechanism to learn more representative visual relationship representations. According to the comparison results obtained on the test benchmark, it can be found that the STKET framework proposed by the researchers outperforms the previous state-of-the-art methods.

Figure 1: Due to the variable visual appearance and the long-tail distribution of visual relationships, video scene graph generation is full of challenges
Transformer based on spatiotemporal knowledge embedding
Spatial and temporal knowledge representation
When inferring visual relationships, humans not only use visual clues, but also use accumulated prior knowledge empirical knowledge [1, 2]. Inspired by this, researchers propose to extract prior spatiotemporal knowledge directly from the training set to facilitate the video scene graph generation task.
Among them, the spatial co-occurrence correlation is specifically manifested in that when a given object is combined, its visual relationship distribution will be highly skewed (for example, the distribution of the visual relationship between "person" and "cup" is obviously different from " The distribution between "dog" and "toy") and time transfer correlation are specifically manifested in that the transition probability of each visual relationship will change significantly when the visual relationship at the previous moment is given (for example, when the visual relationship at the previous moment is known When it is "eating", the probability of the visual relationship shifting to "writing" at the next moment is greatly reduced).
As shown in Figure 2, after you can intuitively feel the given object combination or previous visual relationship, the prediction space can be greatly reduced.
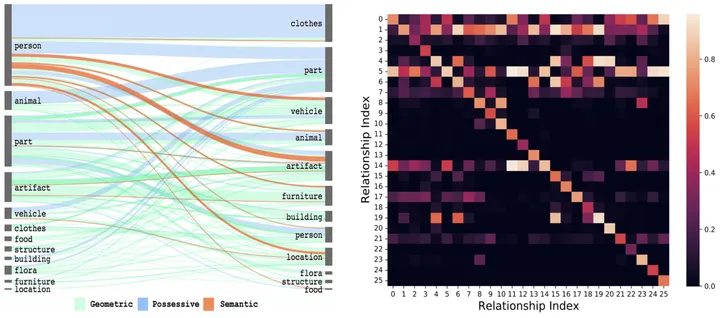
Figure 2: Spatial co-occurrence probability [3] and temporal transition probability of visual relationships
Specifically, for the combination of the i-th type object and the j-th type object, and the relationship between the i-th type object and the j-th type object at the previous moment, the corresponding spatial co-occurrence probability matrix E^{i,j is first obtained statistically } and the time transition probability matrix Ex^{i,j}.
Then, input it into the fully connected layer to obtain the corresponding feature representation, and use the corresponding objective function to ensure that the knowledge representation learned by the model contains the corresponding prior spatiotemporal knowledge. .
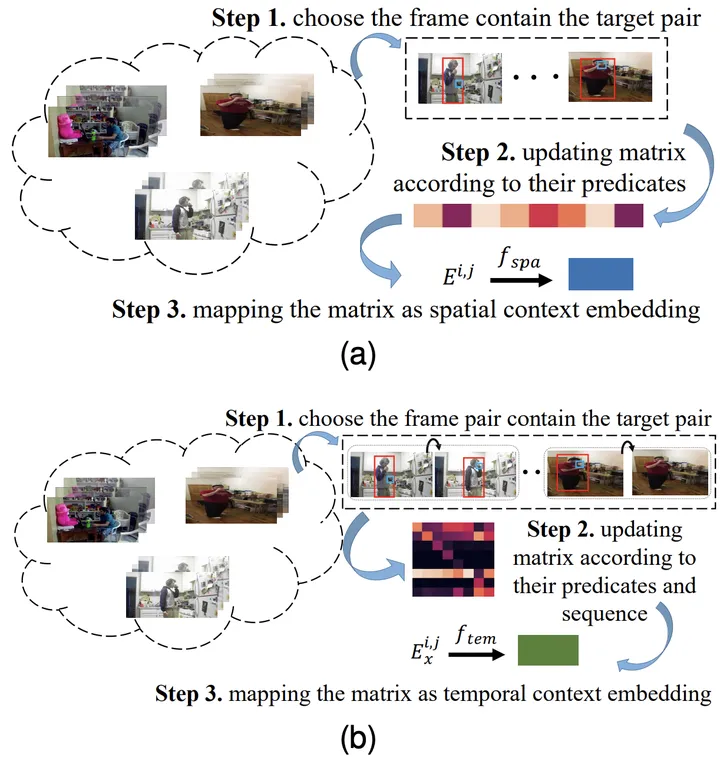
Figure 3: The process of learning spatial (a) and temporal (b) knowledge representation
Knowledge Embedding Note Force layer
Spatial knowledge usually contains information about the positions, distances and relationships between entities. Temporal knowledge, on the other hand, involves the sequence, duration, and intervals between actions.
Given their unique properties, treating them individually can allow specialized modeling to more accurately capture inherent patterns.
Therefore, the researchers designed a spatiotemporal knowledge embedding layer to thoroughly explore the interaction between visual representation and spatiotemporal knowledge.
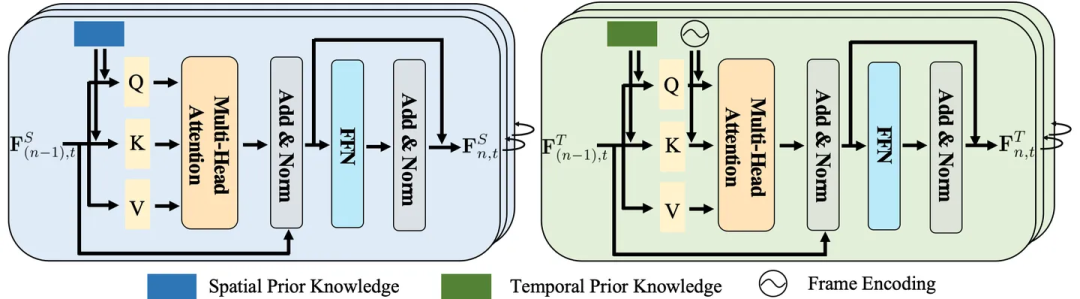
Figure 4: Space (left) and time (right) knowledge embedding layer
Spatial-temporal aggregation module
As mentioned above, the spatial knowledge embedding layer explores the spatial co-occurrence correlation within each image, and the temporal knowledge embedding layer explores the temporal transfer correlation between different images, thereby fully exploring Interactions between visual representations and spatiotemporal knowledge.
Nevertheless, these two layers ignore long-term contextual information, which is helpful for identifying most dynamically changing visual relationships.
To this end, the researchers further designed a spatiotemporal aggregation (STA) module to aggregate these representations of each object pair to predict the final semantic labels and their relationships. It takes as input spatial and temporal embedded relationship representations of the same subject-object pairs in different frames.
Specifically, the researchers concatenated these representations of the same object pairs to generate contextual representations.
Then, to find the same subject-object pairs in different frames, the predicted object labels and IoU (i.e. Intersection of Unions) are adopted to match the same subject-object pairs detected in the frames .
Finally, considering that the relationship in the frame has different representations in different batches, the earliest representation in the sliding window is selected.
Experimental results
In order to comprehensively evaluate the performance of the proposed framework, the researchers compared the existing video scene graph generation method (STTran , TPI, APT), advanced image scene graph generation methods (KERN, VCTREE, ReIDN, GPS-Net) were also selected for comparison.
Among them, in order to ensure fair comparison, the image scene graph generation method achieves the goal of generating a corresponding scene graph for a given video by identifying each frame of image.
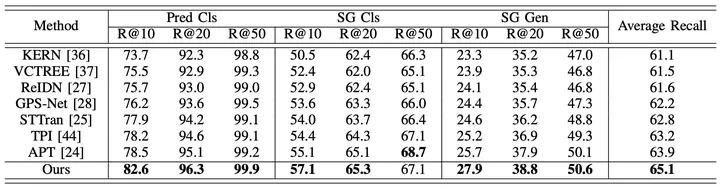
Figure 5: Experimental results using Recall as the evaluation index on the Action Genome data set

Figure 6: Experimental results using mean Recall as the evaluation index on the Action Genome data set
The above is the detailed content of Sun Yat-sen University's new spatiotemporal knowledge embedding framework drives the latest progress in video scene graph generation tasks, published in TIP '24. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to get logged in user information in WordPress for personalized results
Apr 19, 2025 pm 11:57 PM
How to get logged in user information in WordPress for personalized results
Apr 19, 2025 pm 11:57 PM
Recently, we showed you how to create a personalized experience for users by allowing users to save their favorite posts in a personalized library. You can take personalized results to another level by using their names in some places (i.e., welcome screens). Fortunately, WordPress makes it very easy to get information about logged in users. In this article, we will show you how to retrieve information related to the currently logged in user. We will use the get_currentuserinfo(); function. This can be used anywhere in the theme (header, footer, sidebar, page template, etc.). In order for it to work, the user must be logged in. So we need to use
 How to elegantly obtain entity class variable names to build database query conditions?
Apr 19, 2025 pm 11:42 PM
How to elegantly obtain entity class variable names to build database query conditions?
Apr 19, 2025 pm 11:42 PM
When using MyBatis-Plus or other ORM frameworks for database operations, it is often necessary to construct query conditions based on the attribute name of the entity class. If you manually every time...
 Java BigDecimal operation: How to accurately control the accuracy of calculation results?
Apr 19, 2025 pm 11:39 PM
Java BigDecimal operation: How to accurately control the accuracy of calculation results?
Apr 19, 2025 pm 11:39 PM
Java...
 How to solve the problem of username and password authentication failure when connecting to local EMQX using Eclipse Paho?
Apr 19, 2025 pm 04:54 PM
How to solve the problem of username and password authentication failure when connecting to local EMQX using Eclipse Paho?
Apr 19, 2025 pm 04:54 PM
How to solve the problem of username and password authentication failure when connecting to local EMQX using EclipsePaho's MqttAsyncClient? Using Java and Eclipse...
 How to properly configure apple-app-site-association file in pagoda nginx to avoid 404 errors?
Apr 19, 2025 pm 07:03 PM
How to properly configure apple-app-site-association file in pagoda nginx to avoid 404 errors?
Apr 19, 2025 pm 07:03 PM
How to correctly configure apple-app-site-association file in Baota nginx? Recently, the company's iOS department sent an apple-app-site-association file and...
 How to package in IntelliJ IDEA for specific Git versions to avoid including unfinished code?
Apr 19, 2025 pm 08:18 PM
How to package in IntelliJ IDEA for specific Git versions to avoid including unfinished code?
Apr 19, 2025 pm 08:18 PM
In IntelliJ...
 How to efficiently query large amounts of personnel data through natural language processing?
Apr 19, 2025 pm 09:45 PM
How to efficiently query large amounts of personnel data through natural language processing?
Apr 19, 2025 pm 09:45 PM
Effective method of querying personnel data through natural language processing How to efficiently use natural language processing (NLP) technology when processing large amounts of personnel data...
 How to process and display percentage numbers in Java?
Apr 19, 2025 pm 10:48 PM
How to process and display percentage numbers in Java?
Apr 19, 2025 pm 10:48 PM
Display and processing of percentage numbers in Java In Java programming, the need to process and display percentage numbers is very common, for example, when processing Excel tables...
