
 System Tutorial
LINUX
Optimize HDFS data access efficiency: use data heat and coldness to manage
System Tutorial
LINUX
Optimize HDFS data access efficiency: use data heat and coldness to manage
Optimize HDFS data access efficiency: use data heat and coldness to manage

Theme introduction:
- HDFS optimized storage function explanation
- SSM system architecture design
- SSM system application scenario analysis
With the development and popularization of big data technology-related technologies, more and more companies are beginning to use platform systems based on open source Hadoop. At the same time, more and more businesses and applications are migrating from traditional technical architecture to big data technology. on the data platform. In a typical Hadoop big data platform, people use HDFS as the core of storage services.
At the beginning of the development of big data, the main application scenario was still the offline batch processing scenario, and the demand for storage was the pursuit of throughput. HDFS was designed for such scenarios, and as technology continues to evolve With development, more and more scenarios will put forward new demands for storage, and HDFS is also facing new challenges. It mainly includes several aspects:
1. Data volume problemOn the one hand, with the growth of business and new application access, more data will be brought to HDFS. On the other hand, with the development of deep learning, artificial intelligence and other technologies, users usually hope to save it for a longer period of time. data to improve the effect of deep learning. The rapid increase in the amount of data will cause the cluster to continuously face expansion needs, resulting in increasing storage costs.
2. Small file problemAs we all know, HDFS is designed for offline batch processing of large files. Processing small files is not a scenario that traditional HDFS is good at. The root cause of the HDFS small file problem is that the metadata information of the file is maintained in the memory of a single Namenode, and the memory space of a single machine is always limited. It is estimated that the maximum number of system files that a single namenode cluster can accommodate is about 150 million. In fact, the HDFS platform usually serves as the underlying storage platform to serve multiple upper-layer computing frameworks and multiple business scenarios, so the problem of small files is unavoidable from a business perspective. There are currently solutions such as HDFS-Federation to solve the Namenode single-point scalability problem, but at the same time it will also bring huge difficulties in operation and maintenance management.
3. Hot and cold data issuesAs the amount of data continues to grow and accumulate, the data will also show huge differences in access popularity. For example, a platform will continuously write the latest data, but usually the recently written data will be accessed much more frequently than the data written long ago. If the same storage strategy is used regardless of whether the data is hot or cold, it is a waste of cluster resources. How to optimize the HDFS storage system based on the hotness and coldness of the data is an urgent problem that needs to be solved.
2. Existing HDFS optimization technologyIt has been more than 10 years since the birth of Hadoop. During this period, HDFS technology itself has been continuously optimized and evolved. HDFS has some existing technologies that can solve some of the above problems to a certain extent. Here is a brief introduction to HDFS heterogeneous storage and HDFS erasure coding technology.
HDFS heterogeneous storage:Hadoop supports heterogeneous storage functionality starting from version 2.6.0. We know that the default storage strategy of HDFS uses three copies of each data block and stores them on disks on different nodes. The role of heterogeneous storage is to use different types of storage media on the server (including HDD hard disk, SSD, memory, etc.) to provide more storage strategies (for example, three copies, one is stored in the SSD media, and the remaining two are still stored in the HDD hard disk) , thus making HDFS storage more flexible and efficient in responding to various application scenarios.
Various storages predefined and supported in HDFS include:
-
ARCHIVE: Storage media with high storage density but low power consumption, such as tape, are usually used to store cold data
-
DISK: Disk media, this is the earliest storage medium supported by HDFS
-
SSD: Solid state drive is a new type of storage medium that is currently used by many Internet companies
-
RAM_DISK: The data is written into the memory, and another copy will be written (asynchronously) to the storage medium at the same time
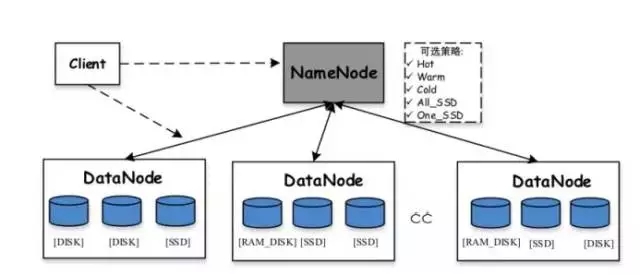
Storage strategies supported in HDFS include:
-
Lazy_persist: One copy is saved in memory RAM_DISK, and the remaining copies are saved on disk
-
ALL_SSD: All copies are saved in SSD
-
One_SSD: One copy is saved in the SSD and the remaining copies are saved on the disk
-
Hot: All copies are saved on disk, which is also the default storage policy
-
Warm: One copy is saved on disk, the remaining copies are saved on archive storage
-
Cold: All copies are kept on archive storage
In general, the value of HDFS heterogeneous storage lies in adopting different strategies according to the popularity of data to improve the overall resource usage efficiency of the cluster. For frequently accessed data, save all or part of it on storage media (memory or SSD) with higher access performance to improve its read and write performance; for data that is rarely accessed, save it on archive storage media to reduce its read and write performance. Storage costs. However, the configuration of HDFS heterogeneous storage requires users to specify corresponding policies for directories, that is, users need to know the access popularity of files in each directory in advance. In actual big data platform applications, this is more difficult.
HDFS erasure coding:Traditional HDFS data uses a three-copy mechanism to ensure data reliability. That is, for every 1TB of data stored, the actual data occupied on each node of the cluster reaches 3TB, with an additional overhead of 200%. This puts great pressure on node disk storage and network transmission.
In Hadoop 3.0, erasure coding was introduced to support HDFS file block level, and the underlying layer uses the Reed-Solomon (k, m) algorithm. RS is a commonly used erasure coding algorithm. Through matrix operations, m-bit check digits can be generated for k-bit data. Depending on the values of k and m, different degrees of fault tolerance can be achieved. It is a relatively flexible method. Erasure coding algorithm.
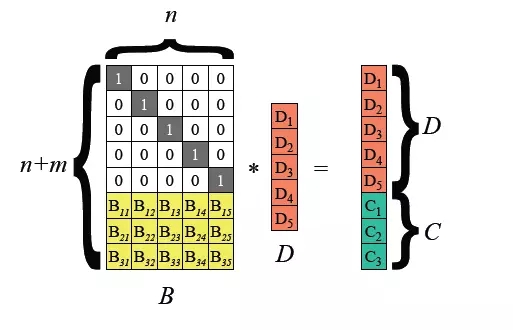
Common algorithms are RS(3,2), RS(6,3), RS(10,4), k file blocks and m check blocks form a group, and any m can be tolerated in this group Loss of data blocks.
HDFS erasure coding technology can reduce the redundancy of data storage. Taking RS(3,2) as an example, its data redundancy is 67%, which is greatly reduced compared to Hadoop's default 200%. However, erasure coding technology requires the consumption of CPU for calculations for data storage and data recovery. It is actually a choice of exchanging time for space, so the more applicable scenario is the storage of cold data. The data stored in cold data is often not accessed for a long time after being written once. In this case, erasure coding technology can be used to reduce the number of copies.
3. Big data storage optimization: SSMRegardless of the HDFS heterogeneous storage or erasure coding technology introduced earlier, the premise is that the user needs to specify the storage behavior for specific data, which means that the user needs to know which data is hot data and which is cold data. So is there a way to automatically optimize storage?
The answer is yes. The SSM (Smart Storage Management) system introduced here obtains metadata information from the underlying storage (usually HDFS), and obtains data heat status through data read and write access information analysis, targeting different heat levels. According to a series of pre-established rules, corresponding storage optimization strategies are adopted to improve the efficiency of the entire storage system. SSM is an open source project led by Intel, and China Mobile also participates in its research and development. The project can be obtained from Github: https://github.com/Intel-bigdata/SSM.
SSM positioning is a storage peripheral optimization system that adopts a Server-Agent-Client architecture as a whole. The Server is responsible for the implementation of the overall logic of SSM, the Agent is used to perform various operations on the storage cluster, and the Client is provided to users. Data access interface, usually including native HDFS interface.
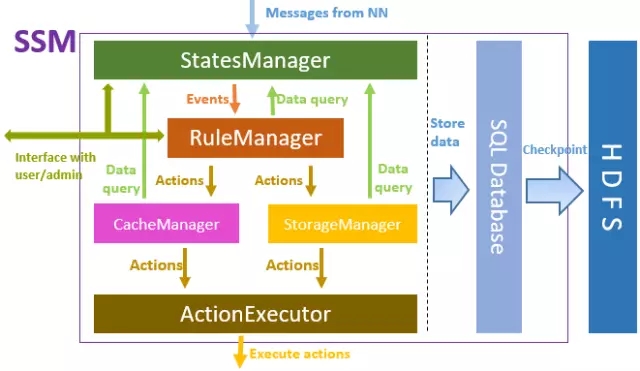
The main framework of SSM-Server is shown in the figure above. From top to bottom, StatesManager interacts with the HDFS cluster to obtain HDFS metadata information and maintain the access popularity information of each file. The information in StatesManager will be persisted to the relational database. TiDB is used as the underlying storage database in SSM. RuleManager maintains and manages rule-related information. Users define a series of storage rules for SSM through the front-end interface, and RuleManger is responsible for parsing and executing the rules. CacheManager/StorageManager generates specific action tasks based on popularity and rules. ActionExecutor is responsible for specific action tasks, assigns tasks to Agents, and executes them on Agent nodes.

The internal logic implementation of SSM-Server relies on the definition of rules, which requires the administrator to formulate a series of rules for the SSM system through the front-end web page. A rule consists of several parts:
- Operation objects usually refer to files that meet specific conditions.
- Trigger refers to the time point when the rule is triggered, such as a scheduled trigger every day.
- Execution conditions, define a series of conditions based on popularity, such as file access count requirements within a period of time.
- Execute operations, perform related operations on data that meets the execution conditions, usually specifying its storage policy, etc.
An actual rule example:
file.path matches ”/foo/*”: accessCount(10min) >= 3 | one-ssd
This rule means that for files in the /foo directory, if they are accessed no less than three times within 10 minutes, the One-SSD storage strategy will be adopted, that is, one copy of the data will be saved on the SSD, and the remaining 2 A copy is saved on a regular disk.
4. SSM application scenariosSSM can use different storage strategies to optimize the hotness and coldness of data. The following are some typical application scenarios:
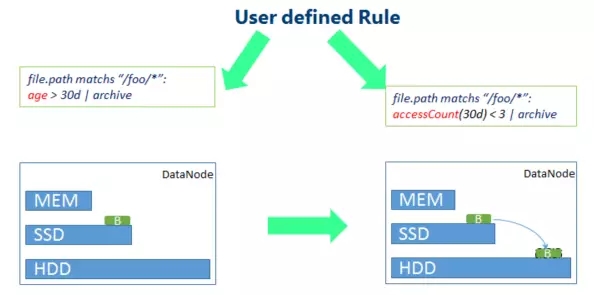
The most typical scenario is for cold data, as shown in the figure above, define relevant rules and use lower-cost storage for data that has not been accessed for a long time. For example, the original data blocks are degraded from SSD storage to HDD storage.
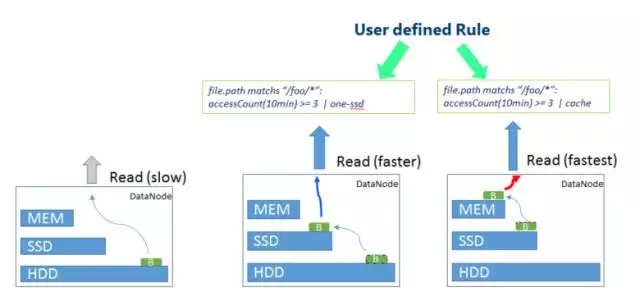
Similarly, for hotspot data, a faster storage strategy can also be adopted according to different rules. As shown in the figure above, accessing more hotspot data here in a short time will increase the storage cost from HDD. For SSD storage, more hot data will use the memory storage strategy.
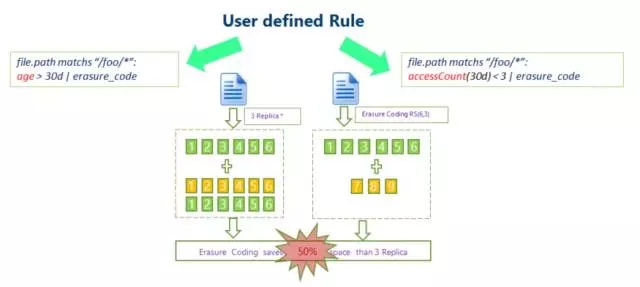
For cold data scenarios, SSM can also use erasure coding optimization. By defining corresponding rules, erasure code operations are performed on cold data with few accesses to reduce data copy redundancy.

It is also worth mentioning that SSM also has corresponding optimization methods for small files. This feature is still in the development process. The general logic is that SSM will merge a series of small files on HDFS into large files. At the same time, the mapping relationship between the original small files and the merged large files and the location of each small file in the large file will be recorded in the metadata of SSM. offset. When the user needs to access a small file, the original small file is obtained from the merged file through the SSM-specific client (SmartClient) based on the small file mapping information in the SSM metadata.
Finally, SSM is an open source project and is still in the process of very rapid iterative evolution. Any interested friends are welcome to contribute to the development of the project.
Q&AQ1: What scale should we start with to build HDFS ourselves?
A1: HDFS supports pseudo-distribution mode. Even if there is only one node, an HDFS system can be built. If you want to better experience and understand the distributed architecture of HDFS, it is recommended to build an environment with 3 to 5 nodes.
Q2: Has Su Yan used SSM in the actual big data platform of each province?
A2: Not yet. This project is still developing rapidly. It will be gradually used in production after testing is stable.
Q3: What is the difference between HDFS and Spark? What are the pros and cons?
A3: HDFS and Spark are not technologies on the same level. HDFS is a storage system, while Spark is a computing engine. What we often compare with Spark is the Mapreduce computing framework in Hadoop rather than the HDFS storage system. In actual project construction, HDFS and Spark usually have a collaborative relationship. HDFS is used for underlying storage and Spark is used for upper-level computing.
The above is the detailed content of Optimize HDFS data access efficiency: use data heat and coldness to manage. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Unable to log in to mysql as root
Apr 08, 2025 pm 04:54 PM
Unable to log in to mysql as root
Apr 08, 2025 pm 04:54 PM
The main reasons why you cannot log in to MySQL as root are permission problems, configuration file errors, password inconsistent, socket file problems, or firewall interception. The solution includes: check whether the bind-address parameter in the configuration file is configured correctly. Check whether the root user permissions have been modified or deleted and reset. Verify that the password is accurate, including case and special characters. Check socket file permission settings and paths. Check that the firewall blocks connections to the MySQL server.
 Can mysql run on android
Apr 08, 2025 pm 05:03 PM
Can mysql run on android
Apr 08, 2025 pm 05:03 PM
MySQL cannot run directly on Android, but it can be implemented indirectly by using the following methods: using the lightweight database SQLite, which is built on the Android system, does not require a separate server, and has a small resource usage, which is very suitable for mobile device applications. Remotely connect to the MySQL server and connect to the MySQL database on the remote server through the network for data reading and writing, but there are disadvantages such as strong network dependencies, security issues and server costs.
 Unable to access mysql from terminal
Apr 08, 2025 pm 04:57 PM
Unable to access mysql from terminal
Apr 08, 2025 pm 04:57 PM
Unable to access MySQL from the terminal may be due to: MySQL service not running; connection command error; insufficient permissions; firewall blocks connection; MySQL configuration file error.
 What is the most use of Linux?
Apr 09, 2025 am 12:02 AM
What is the most use of Linux?
Apr 09, 2025 am 12:02 AM
Linux is widely used in servers, embedded systems and desktop environments. 1) In the server field, Linux has become an ideal choice for hosting websites, databases and applications due to its stability and security. 2) In embedded systems, Linux is popular for its high customization and efficiency. 3) In the desktop environment, Linux provides a variety of desktop environments to meet the needs of different users.
 CentOS Interview Questions: Ace Your Linux System Administrator Interview
Apr 09, 2025 am 12:17 AM
CentOS Interview Questions: Ace Your Linux System Administrator Interview
Apr 09, 2025 am 12:17 AM
Frequently asked questions and answers to CentOS interview include: 1. Use the yum or dnf command to install software packages, such as sudoyumininstallnginx. 2. Manage users and groups through useradd and groupadd commands, such as sudouseradd-m-s/bin/bashnewuser. 3. Use firewalld to configure the firewall, such as sudofirewall-cmd--permanent-add-service=http. 4. Set automatic updates to use yum-cron, such as sudoyumininstallyum-cron and configure apply_updates=yes.
 How to learn Linux basics?
Apr 10, 2025 am 09:32 AM
How to learn Linux basics?
Apr 10, 2025 am 09:32 AM
The methods for basic Linux learning from scratch include: 1. Understand the file system and command line interface, 2. Master basic commands such as ls, cd, mkdir, 3. Learn file operations, such as creating and editing files, 4. Explore advanced usage such as pipelines and grep commands, 5. Master debugging skills and performance optimization, 6. Continuously improve skills through practice and exploration.
 Key Linux Operations: A Beginner's Guide
Apr 09, 2025 pm 04:09 PM
Key Linux Operations: A Beginner's Guide
Apr 09, 2025 pm 04:09 PM
Linux beginners should master basic operations such as file management, user management and network configuration. 1) File management: Use mkdir, touch, ls, rm, mv, and CP commands. 2) User management: Use useradd, passwd, userdel, and usermod commands. 3) Network configuration: Use ifconfig, echo, and ufw commands. These operations are the basis of Linux system management, and mastering them can effectively manage the system.
 How to start the server with redis
Apr 10, 2025 pm 08:12 PM
How to start the server with redis
Apr 10, 2025 pm 08:12 PM
The steps to start a Redis server include: Install Redis according to the operating system. Start the Redis service via redis-server (Linux/macOS) or redis-server.exe (Windows). Use the redis-cli ping (Linux/macOS) or redis-cli.exe ping (Windows) command to check the service status. Use a Redis client, such as redis-cli, Python, or Node.js, to access the server.
