
 Technology peripherals
AI
The University of Science and Technology of China develops the 'State Sequence Frequency Domain Prediction' method, which improves performance by 20% and maximizes sample efficiency.
Technology peripherals
AI
The University of Science and Technology of China develops the 'State Sequence Frequency Domain Prediction' method, which improves performance by 20% and maximizes sample efficiency.
The University of Science and Technology of China develops the 'State Sequence Frequency Domain Prediction' method, which improves performance by 20% and maximizes sample efficiency.

The training process of reinforcement learning algorithm (Reinforcement Learning, RL) usually requires a large amount of sample data interacting with the environment to support it. However, in the real world, it is often very expensive to collect a large number of interaction samples, or the safety of the sampling process cannot be ensured, such as UAV air combat training and autonomous driving training. This problem limits the scope of reinforcement learning in many practical applications. Therefore, researchers have been working hard to explore how to strike a balance between sample efficiency and safety to solve this problem. One possible solution is to use simulators or virtual environments to generate large amounts of sample data, thus avoiding the cost and security risks of real-world situations. In addition, in order to improve the sample efficiency of reinforcement learning algorithms during the training process, some researchers have used representation learning technology to design auxiliary tasks for predicting future state signals. In this way, the algorithm can extract and encode features relevant to future decisions from the original environmental state. The purpose of this approach is to improve the performance of reinforcement learning algorithms by learning more information about the environment and providing a better basis for decision-making. In this way, the algorithm can use sample data more efficiently during the training process, accelerate the learning process, and improve the accuracy and efficiency of decision-making.
Based on this idea, this work designed an auxiliary task to predict the state sequence frequency domain distribution
for multiple steps in the future to capture longer-term future decision-making characteristics. , thereby improving the sample efficiency of the algorithm.This work is titled State Sequences Prediction via Fourier Transform for Representation Learning, published in NeurIPS 2023, and accepted as Spotlight.
Author list: Ye Mingxuan, Kuang Yufei, Wang Jie*, Yang Rui, Zhou Wengang, Li Houqiang, Wu Feng
Paper link: https://openreview.net/forum?id=MvoMDD6emT
Code link: https://github.com/MIRALab-USTC/RL-SPF /
Research background and motivation
Deep reinforcement learning algorithm is used in robot control [1], game intelligence [2], and combinatorial optimization [3 ] and other fields have achieved great success. However, the current reinforcement learning algorithm still suffers from the problem of "low sample efficiency", that is, the robot needs a large amount of data interacting with the environment to train a strategy with excellent performance.
In order to improve sample efficiency, researchers have begun to pay attention to representation learning, hoping that the representations obtained through training can extract rich and useful feature information from the original state of the environment, thereby improving the performance of robots. Exploration efficiency in state space.
Reinforcement learning algorithm framework based on representation learning
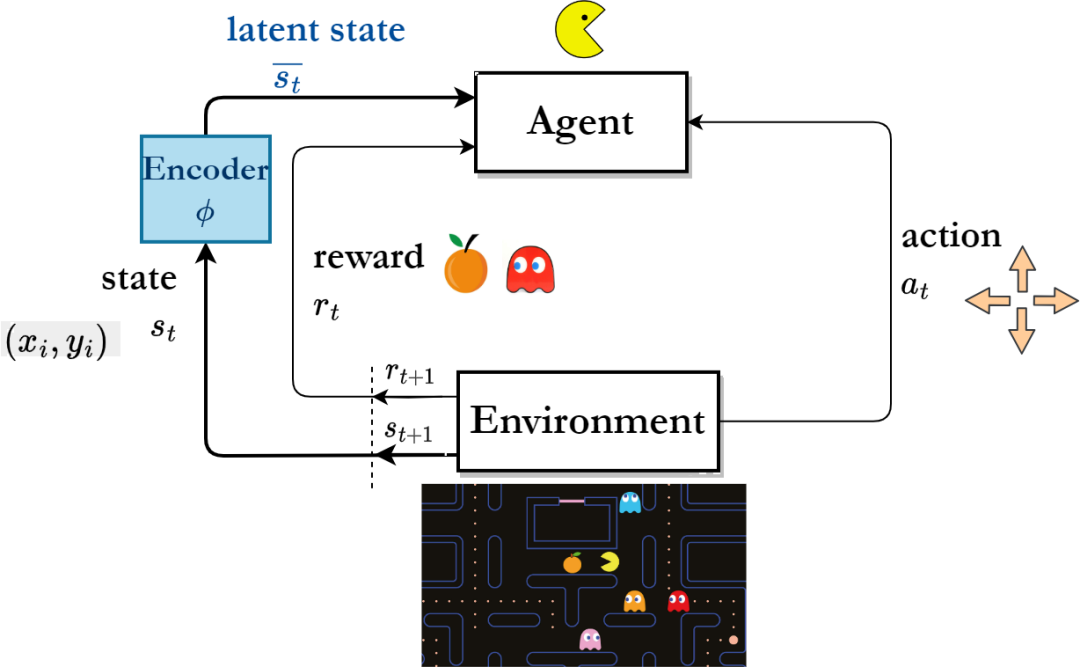
"Long-term sequence signal"Contains more future information that is beneficial to long-term decision-making than single-step signals. Inspired by this point of view, some researchers have proposed to assist representation learning by predicting multi-step state sequence signals in the future [4,5]. However, it is very difficult to directly predict the state sequence to assist representation learning.
Among the two existing methods, one method gradually generates the future state of a single moment by learning the single-step probability transfer model to indirectly predict multiple Step status sequence [6,7]. However, this type of method requires high accuracy of the trained probability transfer model, because the prediction error at each step will accumulate as the length of the prediction sequence increases.
Another type of method assists representation learning [8] by directly predicting the state sequence of multiple steps in the future, but this type of method needs to store the true state of multiple steps Sequences, as labels for prediction tasks, consume a large amount of storage. Therefore, how to effectively extract future information that is beneficial to long-term decision-making from the state sequence of the environment and thereby improve the sample efficiency during continuous control robot training is a problem that needs to be solved.
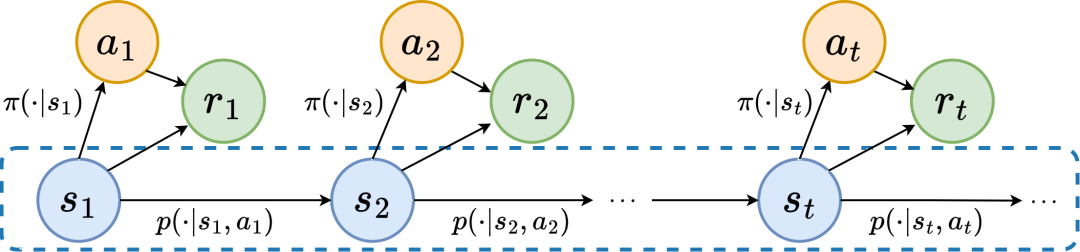
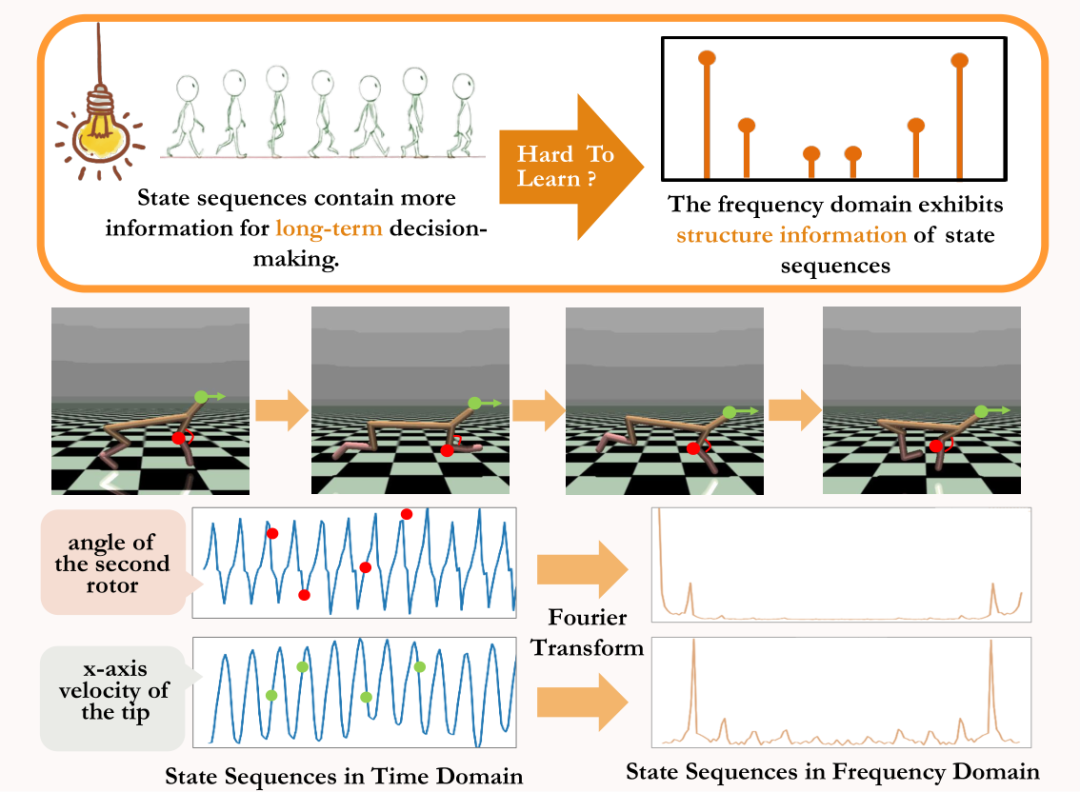
In order to solve the above problems, we propose a representation learning method based on frequency domain prediction of state sequences (State Sequences P
rediction viaFourier Transform, SPF), the idea is to use "frequency domain distribution of state sequence" to explicitly extract trends and patterns in state sequence data information, thereby assisting representation to efficiently extract long-term future information. We have theoretically proven that there are "two kinds of structural information" in state sequence, one One is the trend information related to strategy performance, and the other is the regular information related to state periodicity. Before analyzing the two structural information in detail, we first introduce the Markov decision that generates the state sequence. Related definitions of processes (Markov Decision Processes, MDP). We consider the classic Markov decision process in a continuous control problem, which can be represented by a five-tuple. Among them, is the corresponding state and action space, is the reward function, is the state transition function of the environment, is the initial distribution of the state, and is the discount factor. In addition, we use to represent the action distribution of the policy in the state . We record the state of the agent at time as , and the selected action as . After the agent makes an action, the environment moves to the next state and is fed back to the intelligence Body rewards. We record the trajectory corresponding to the state and action obtained during the interaction between the agent and the environment as , and the trajectory obeys the distribution . The goal of the reinforcement learning algorithm is to maximize the expected cumulative return in the future. We use to represent the average cumulative return under the current strategy and environment model , and abbreviate as , which is defined as follows: Shows the performance of the current strategy. Now we introduce the "first structural characteristic" of the state sequence, which involves The dependence between the state sequence and the corresponding reward sequence can show the performance trend of the current strategy. In reinforcement learning tasks, the future state sequence largely determines the action sequence taken by the agent in the future, and further determines the corresponding reward sequence. Therefore, the future state sequence not only contains information about the probability transition function inherent in the environment, but can also assist in capturing the trend of the current strategy. Inspired by the above structure, we prove the following theorem to further prove the existence of this structural dependency: Theorem 1: If the reward function is only related to the state, then for any two strategies and , their performance difference can be controlled by the difference in the state sequence distribution generated by these two strategies: In the above formula, represents the probability distribution of the state sequence under the specified policy and transition probability function, and represents the norm. The above theorem shows that the greater the performance difference between the two strategies, the greater the distribution difference between the two corresponding state sequences. This means that a good strategy and a bad strategy will produce two quite different state sequences, which further illustrates that the long-term structural information contained in the state sequence can potentially affect the efficiency of the search strategy with excellent performance. On the other hand, under certain conditions, the difference in frequency domain distribution of state sequences can also provide an upper bound for the corresponding policy performance difference, as shown in the following theorem: Theorem 2: If the state space is finite-dimensional and the reward function is an n-degree polynomial related to the state, then for any two strategies and , their performance difference can be expressed by Controlled by the difference in frequency domain distribution of the state sequences generated by the two strategies: In the above formula, represents the Fourier function of the power sequence of the state sequence generated by the strategy, Represents the component of the Fourier function. This theorem shows that the frequency domain distribution of the state sequence still contains features related to the performance of the current strategy. Now we introduce the "second structural characteristic" that exists in the state sequence, It involves the time dependence between state signals, that is, the regular pattern displayed by the state sequence over a long period of time. In many real-scenario tasks, agents will also show periodic behavior because the state transition function of their environment itself is periodic. Take an industrial assembly robot as an example. The robot is trained to assemble parts together to create a final product. When the strategy training reaches stability, it performs a periodic action sequence that enables it to efficiently assemble parts in Together. Inspired by the above example, we provide some theoretical analysis to prove that in the finite state space, when the transition probability matrix satisfies certain assumptions, the corresponding state sequence reaches stability in the agent. The strategy may show "asymptotic periodicity". The specific theorem is as follows: ##Theorem 3: For a finite state transition matrix of Dimensional state space , assuming that there are cycle classes, the corresponding state transition submatrix is . Assume that the number of eigenvalues with modulus 1 of this matrix is , then for the initial distribution of any state , the state distribution shows asymptotic periodicity with period . In the MuJoCo task, when the strategy training reaches stability, the agent will also show periodic movements. The figure below gives an example of the state sequence of the HalfCheetah agent in the MuJoCo task over a period of time, and obvious periodicity can be observed. (For more examples of periodic state sequences in the MuJoCo task, please refer to Section E in the appendix of this paper) HalfCheetah agent in the MuJoCo task The periodicity shown by the state within a period of time The information presented by the time series in the time domain is relatively scattered, but in the frequency domain, the regular information in the sequence is more concentrated. form presentation. By analyzing the frequency components in the frequency domain, we can explicitly capture the periodic characteristics present in the state sequence. In the previous part, we theoretically proved that the frequency domain distribution of the state sequence can reflect the performance of the strategy, and By analyzing the frequency components in the frequency domain we can explicitly capture the periodic features in the state sequence. Inspired by the above analysis, we designed the auxiliary task of "Predicting the Fourier transform of the infinite-step future state sequence" to encourage the representation of the structure in the extracted state sequence sexual information. The following introduces our modeling of this auxiliary task. Given the current state and action, we define the expected future state sequence as follows: Our auxiliary task trains the representation to predict the expected state sequence above Discrete-time Fourier transform (DTFT), that is, The above Fourier transform formula can be rewritten as the following recursion Format:
Inspired by the TD-error loss function [9] that optimizes Q-value networks in Q-learning, we designed the following loss function:
Among them, and are the neural network parameters of the representation encoder (encoder) and Fourier function predictor (predictor) respectively for which the loss function needs to be optimized, and are the experience pool for storing sample data. Further, we can prove that the above recursive formula can be expressed as a compression map: Theorem 4: Let represent the function family , and define the norm on as: ##where represents the row vector of the matrix . If we define the mapping as , we can prove that it is a compression mapping. According to the principle of compression mapping, we can use operators iteratively to approximate the frequency domain distribution of the real state sequence, and have convergence guarantee in tabular setting. In addition, the loss function we designed only depends on the state of the current moment and the next moment, so there is no need to store the state data of multiple steps in the future as prediction labels, which has The advantages of simple implementation and low storage capacity.
Algorithm framework diagram of the representation learning method (SPF) based on state sequence frequency domain prediction We optimize and update the representation encoder and Fourier function predictor by minimizing the loss function, so that the output of the predictor can approximate the Fourier transform of the real state sequence, thus encouraging The representation encoder extracts features that contain structural information about future long-term state sequences. We input the original state and action into the representation encoder, use the obtained features as input to the actor network and critic network in the reinforcement learning algorithm, and optimize the actor network with the classic reinforcement learning algorithm and critic network. Experimental results (Note: This section only selects part of the experimental results. For more detailed results, please refer to Section 6 and the appendix of the original paper. .) Algorithm performance comparison
The above figure shows the performance curves of our proposed SPF method (red line and orange line) and other comparison methods in 6 MuJoCo tasks. The results show that our proposed method can achieve a performance improvement of 19.5% compared to other methods. We conducted an ablation experiment on each module of the SPF method, comparing this method with the one that does not use the projector module (noproj) , compare the performance when not using the target network module (notarg), changing the prediction loss (nofreqloss), and changing the feature encoder network structure (mlp, mlp_cat). Ablation experimental result diagram of the SPF method applied to the SAC algorithm, tested on the HalfCheetah task We use the SPF methodThe trained predictoroutputs the Fourier function of the state sequence, and passes the inverse Fourier transformCompare the restored 200-step status sequence with the real 200-step status sequence. The results show that even if a longer state is used as input, the recovered state sequence is very similar to the real state sequence, which shows that the representation learned by the SPF method can be effectively encoded Structural information contained in the state sequence. Analysis of structural information in state sequence
Markov Decision Process
Trend information
Regular information
Method introduction
SPF method loss function
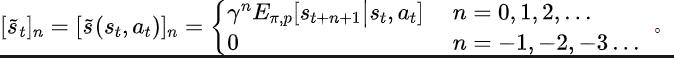
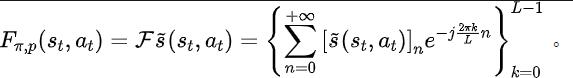
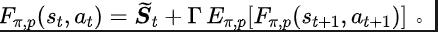
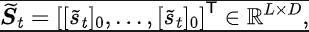
 ## Among them, is the dimension of the state space, and is the number of discretization points of the predicted state sequence Fourier function.
## Among them, is the dimension of the state space, and is the number of discretization points of the predicted state sequence Fourier function. 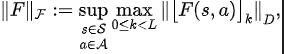
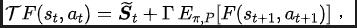
Now we introduce the algorithm framework of this paper’s method (SPF).
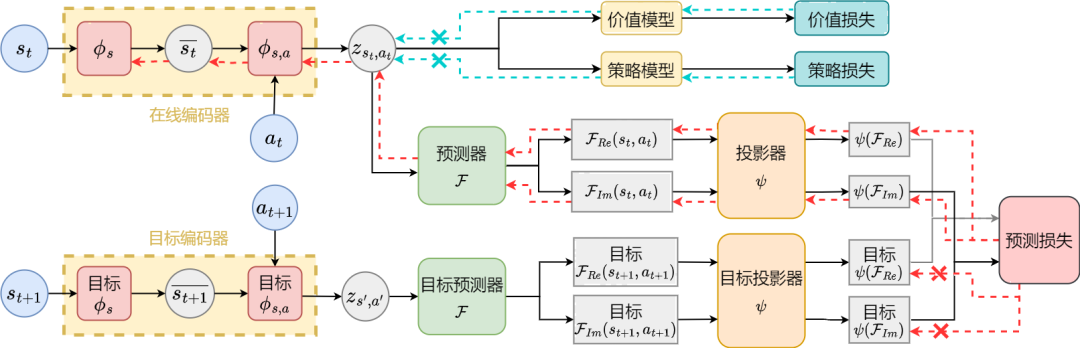
We tested the SPF method on the MuJoCo simulation robot control environment and compared the following 6 methods:
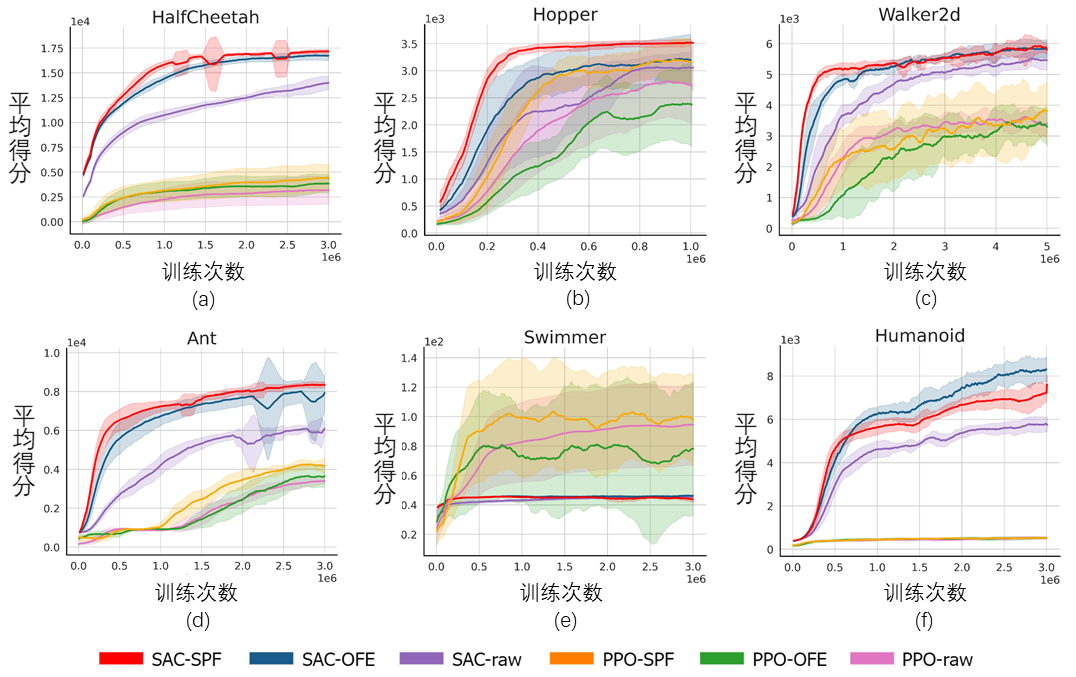
Ablation experiment
Visualization Experiment
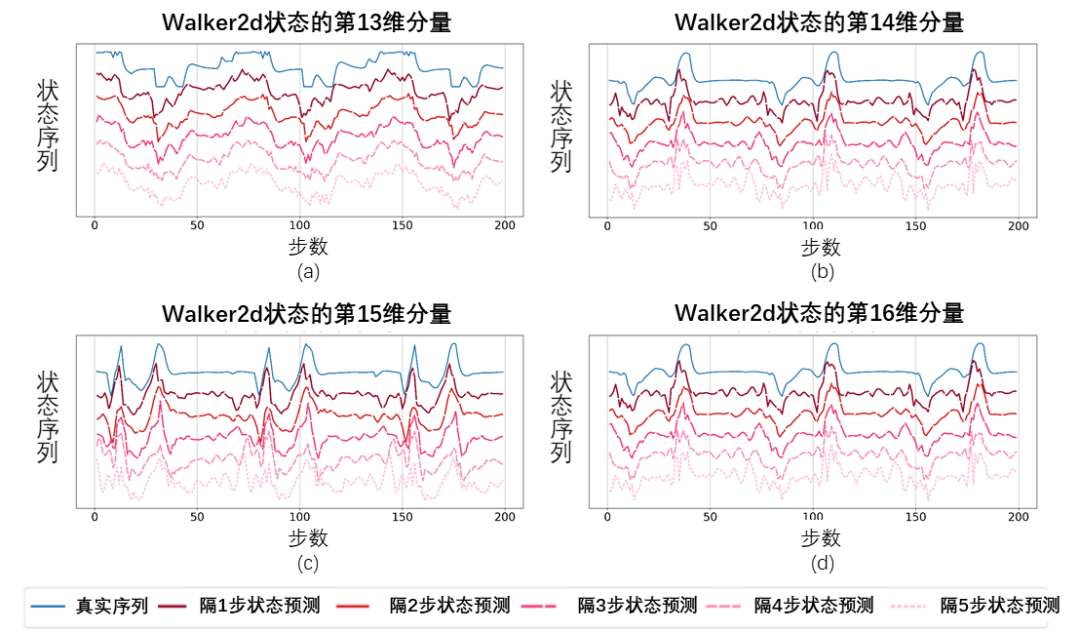 Schematic diagram of the state sequence recovered based on the predicted value of the Fourier function, tested on the Walker2d task. Among them, the blue line is a schematic diagram of the real state sequence, and the five red lines are a schematic diagram of the restored state sequence. The lower and lighter red lines represent the state sequence restored by using the longer historical state.
Schematic diagram of the state sequence recovered based on the predicted value of the Fourier function, tested on the Walker2d task. Among them, the blue line is a schematic diagram of the real state sequence, and the five red lines are a schematic diagram of the restored state sequence. The lower and lighter red lines represent the state sequence restored by using the longer historical state.
The above is the detailed content of The University of Science and Technology of China develops the 'State Sequence Frequency Domain Prediction' method, which improves performance by 20% and maximizes sample efficiency.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
