
 Technology peripherals
AI
Google launches BIG-Bench Mistake data set to help AI improve error correction capabilities
Technology peripherals
AI
Google launches BIG-Bench Mistake data set to help AI improve error correction capabilities
Google launches BIG-Bench Mistake data set to help AI improve error correction capabilities

Google Research recently conducted an evaluation study on popular language models, using its own BIG-Bench benchmark and the newly established "BIG-Bench Mistake" data set. They mainly focused on the error probability and error correction ability of the language model. This study provides valuable data to better understand the performance of language models on the market.
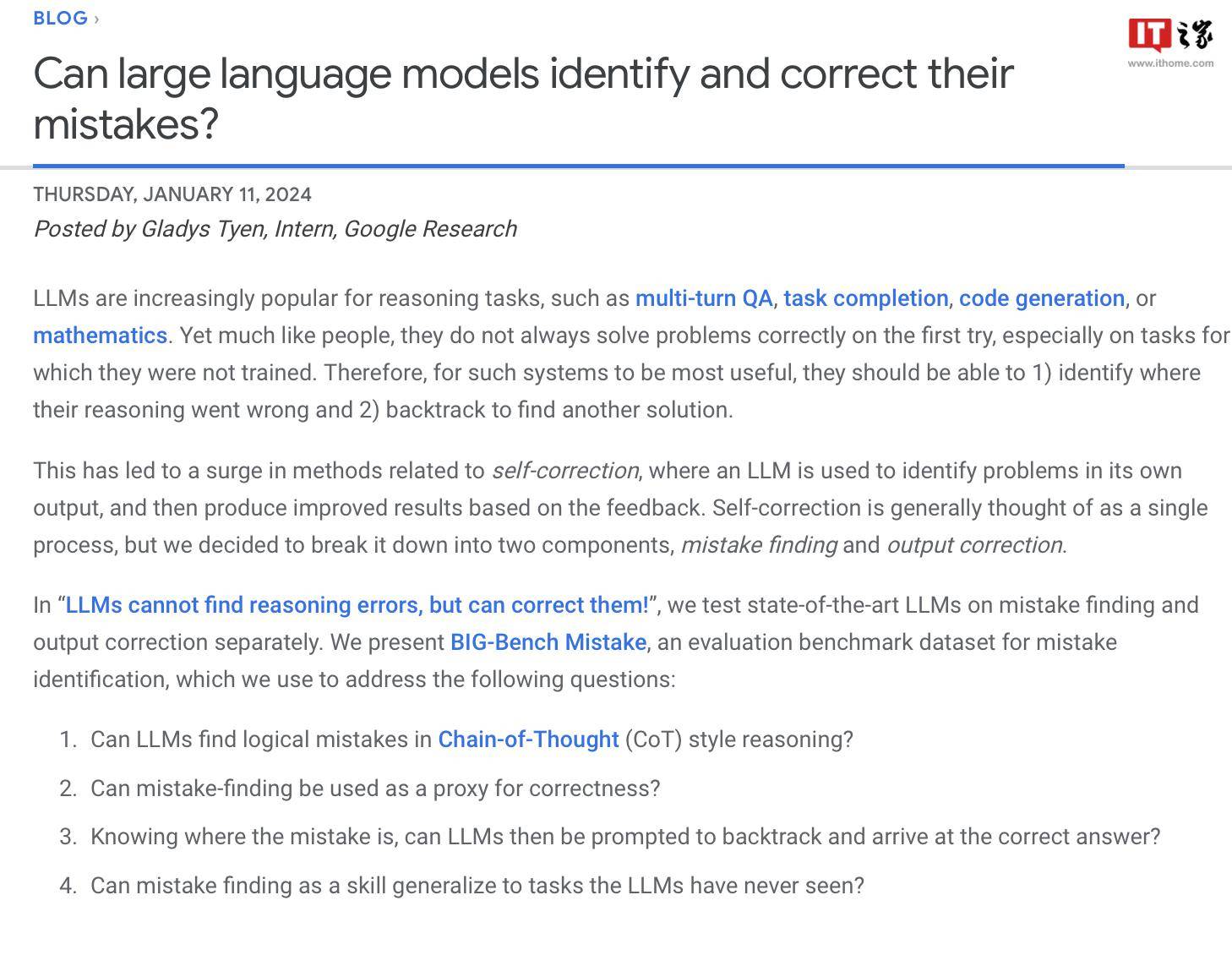
Google researchers said they created a special benchmark data set called "BIG-Bench Mistake" to evaluate the "error probability" and "self-correction ability" of large language models. This is due to the lack of corresponding data sets in the past to effectively evaluate and test these key indicators.
The researchers used the PaLM language model to run 5 tasks in their own BIG-Bench benchmark task, and added the generated "Chain-of-Thought" trajectory to the "Logic Error" part. Retest model accuracy.
In order to improve the accuracy of the data set, Google researchers repeatedly performed the above process and finally created a benchmark data set specifically for evaluation, which contains 255 logical errors, called "BIG-Bench Mistake" .
The researchers pointed out that the logical errors in the "BIG-Bench Mistake" data set are very obvious and therefore can be used as a good standard for language model testing. This dataset helps the model learn from simple errors and gradually improve its ability to identify errors.
The researchers used this data set to test models on the market and found that although most language models can identify logical errors in the reasoning process and correct themselves, this process is not very ideal. Often, human intervention is also required to correct what the model outputs.
▲ Picture source Google Research Press Release
According to the report, Google claims that it is considered the most advanced large language model currently, but its self-correction ability is relatively limited. In tests, the best-performing model found only 52.9% of logical errors.

Google researchers also claimed that this BIG-Bench Mistake data set is conducive to improving the self-correction ability of the model. After fine-tuning the model on relevant test tasks, "even small model performance is usually better than that of large models with zero sample prompts." better".
According to this, Google believes that in terms of model error correction, proprietary small models can be used to "supervise" large models. Instead of letting large language models learn to "correct self-errors", deploying small dedicated models dedicated to supervising large models has the advantage of This will help improve efficiency, reduce related AI deployment costs, and make fine-tuning easier.
The above is the detailed content of Google launches BIG-Bench Mistake data set to help AI improve error correction capabilities. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What is Model Context Protocol (MCP)?
Mar 03, 2025 pm 07:09 PM
What is Model Context Protocol (MCP)?
Mar 03, 2025 pm 07:09 PM
The Model Context Protocol (MCP): A Universal Connector for AI and Data We're all familiar with AI's role in daily coding. Replit, GitHub Copilot, Black Box AI, and Cursor IDE are just a few examples of how AI streamlines our workflows. But imagine
 Building a Local Vision Agent using OmniParser V2 and OmniTool
Mar 03, 2025 pm 07:08 PM
Building a Local Vision Agent using OmniParser V2 and OmniTool
Mar 03, 2025 pm 07:08 PM
Microsoft's OmniParser V2 and OmniTool: Revolutionizing GUI Automation with AI Imagine AI that not only understands but also interacts with your Windows 11 interface like a seasoned professional. Microsoft's OmniParser V2 and OmniTool make this a re
 Runway Act-One Guide: I Filmed Myself to Test It
Mar 03, 2025 am 09:42 AM
Runway Act-One Guide: I Filmed Myself to Test It
Mar 03, 2025 am 09:42 AM
This blog post shares my experience testing Runway ML's new Act-One animation tool, covering both its web interface and Python API. While promising, my results were less impressive than expected. Want to explore Generative AI? Learn to use LLMs in P
 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Replit Agent: A Guide With Practical Examples
Mar 04, 2025 am 10:52 AM
Replit Agent: A Guide With Practical Examples
Mar 04, 2025 am 10:52 AM
Revolutionizing App Development: A Deep Dive into Replit Agent Tired of wrestling with complex development environments and obscure configuration files? Replit Agent aims to simplify the process of transforming ideas into functional apps. This AI-p
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 How to Use DALL-E 3: Tips, Examples, and Features
Mar 09, 2025 pm 01:00 PM
How to Use DALL-E 3: Tips, Examples, and Features
Mar 09, 2025 pm 01:00 PM
DALL-E 3: A Generative AI Image Creation Tool Generative AI is revolutionizing content creation, and DALL-E 3, OpenAI's latest image generation model, is at the forefront. Released in October 2023, it builds upon its predecessors, DALL-E and DALL-E 2
