

Updated Point Transformer: more efficient, faster and more powerful!

Original title: Point Transformer V3: Simpler, Faster, Stronger
Paper link: https://arxiv.org/pdf/2312.10035.pdf
Code link: https:// github.com/Pointcept/PointTransformerV3
Author affiliation: HKU SH AI Lab MPI PKU MIT
Thesis idea:
This article is not intended to focus on the attention mechanism Seek innovation within. Instead, it focuses on leveraging the power of scale to overcome existing trade-offs between accuracy and efficiency in the context of point cloud processing. Drawing inspiration from recent advances in 3D large-scale representation learning, this paper recognizes that model performance is affected more by scale than by complexity of design. Therefore, this paper proposes Point Transformer V3 (PTv3), which prioritizes simplicity and efficiency over the accuracy of certain mechanisms that have less impact on the overall performance after scaling, such as point clouds organized in specific patterns. Efficient serialized neighborhood mapping to replace KNN's exact neighborhood search. This principle enables significant scaling, extending the receptive field from 16 to 1024 points, while remaining efficient (3x faster processing and 10x more memory efficient compared to its predecessor PTv2). PTv3 achieves state-of-the-art results on more than 20 downstream tasks covering indoor and outdoor scenarios. PTv3 takes these results to the next level with further enhancements through multi-dataset joint training.
Network Design:
Recent advances in 3D representation learning [85] overcome the limitations in point cloud processing by introducing collaborative training methods across multiple 3D datasets. Progress has been made on data size limits. Combined with this strategy, an efficient convolutional backbone [12] effectively bridges the accuracy gap typically associated with point cloud transformers [38, 84]. However, point cloud transformers themselves have not yet fully benefited from this scale advantage due to the efficiency gap of point cloud transformers compared to sparse convolutions. This discovery shaped the original motivation for this work: to re-weigh the design choices of point transformers from the perspective of the scaling principle. This paper believes that model performance is more significantly affected by scale than by complex design.
Therefore, this article introduces Point Transformer V3 (PTv3), which prioritizes simplicity and efficiency over the accuracy of certain mechanisms to achieve scalability. Such adjustments have negligible impact on the overall performance after scaling. Specifically, PTv3 makes the following adjustments to achieve superior efficiency and scalability:
- Inspired by two recent advances [48, 77] and recognizing the advantages of structured unstructured point clouds Scalability advantage, PTv3 changes the traditional spatial proximity defined by K-Nearest Neighbors (KNN) query, accounting for 28% of the forward time. Instead, it explores the potential of serialized neighborhoods in point clouds organized according to specific patterns.
- PTv3 adopts a simplified approach tailored for serialized point clouds, replacing more complex attention patch interaction mechanisms such as shift-window (which hinders the fusion of attention operators) and neighborhood mechanisms ( resulting in high memory consumption).
- PTv3 eliminates the dependence on relative position encoding, which accounts for 26% of forward time, in favor of simpler front-end sparse convolutional layers.
This article considers these designs to be intuitive choices driven by scaling principles and advances in existing point cloud transformers. Importantly, this article highlights the critical importance of understanding how scalability affects backbone design, rather than detailed module design.
This principle significantly enhances scalability, overcoming the traditional trade-off between accuracy and efficiency (see Figure 1). PTv3 offers 3.3x faster inference and 10.2x lower memory usage than its predecessor. More importantly, PTv3 leverages its inherent ability to scale sensing range, extending its receptive field from 16 to 1024 points while maintaining efficiency. This scalability underpins its superior performance in real-world perception tasks, with PTv3 achieving state-of-the-art results on more than 20 downstream tasks in indoor and outdoor scenarios. PTv3 further improves these results by further increasing its data size through multi-dataset training [85]. It is hoped that the insights of this article will inspire future research in this direction.
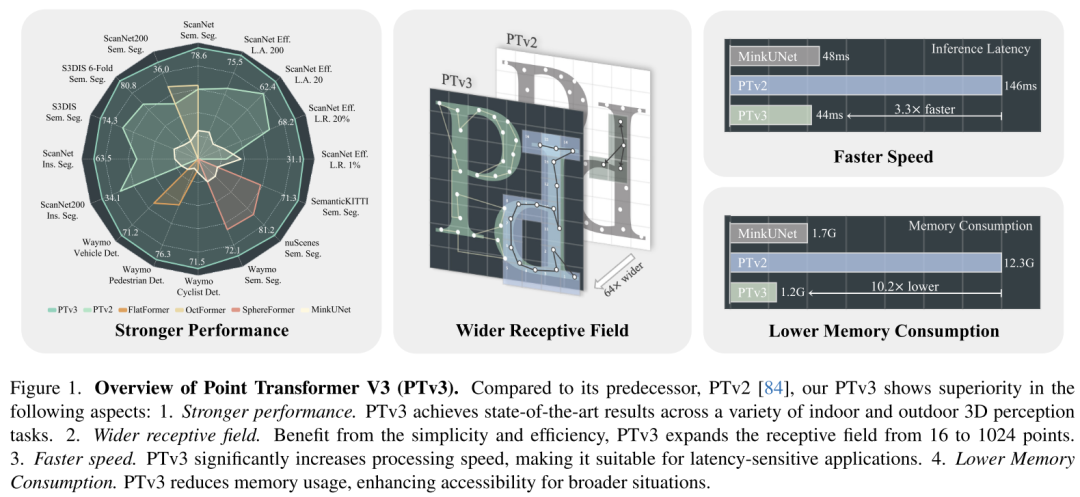
Figure 1. Point Transformer V3 (PTv3) overview. Compared with its predecessor PTv2 [84], PTv3 in this paper shows superiority in the following aspects: 1. Stronger performance. PTv3 achieves state-of-the-art results on a variety of indoor and outdoor 3D perception tasks. 2. Wider receptive field. Benefiting from simplicity and efficiency, PTv3 expands the receptive field from 16 to 1024 points. 3. Faster. PTv3 significantly increases processing speed, making it suitable for latency-sensitive applications. 4. Reduce memory consumption. PTv3 reduces memory usage and enhances accessibility in a wider range of situations.
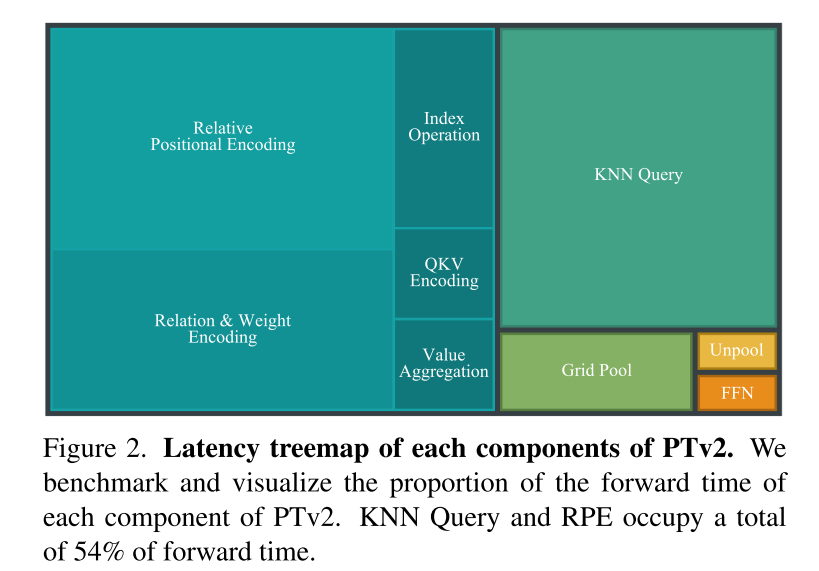
Figure 2. Delay tree diagram of each component of PTv2. This article benchmarks and visualizes the forward time ratio of each component of PTv2. KNN Query and RPE take up 54% of the forward time in total.

Figure 3. Point cloud serialization. This article demonstrates four serialization patterns through triplet visualization. For each triplet, the space-filling curve for serialization (left), the point cloud serialization variable sorting order within the space-filling curve (middle), and the grouped patches of the serialized point cloud for local attention are shown (right). The transformation of the four serialization modes allows the attention mechanism to capture various spatial relationships and contexts, thereby improving model accuracy and generalization ability.
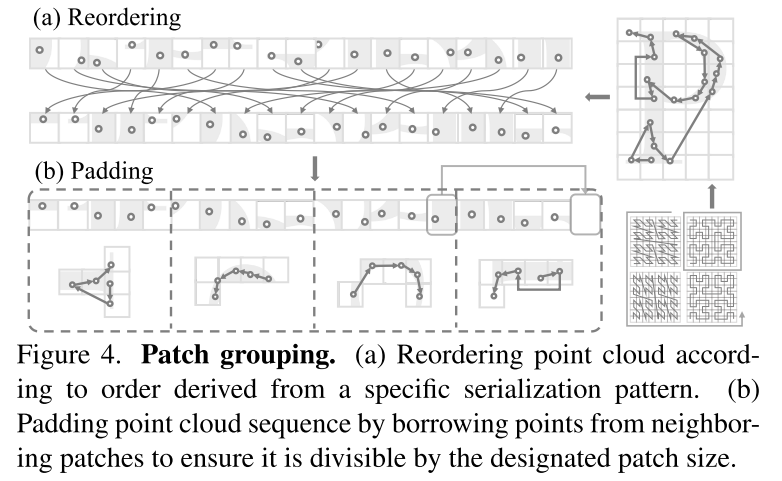
Figure 4. Patch grouping. (a) Reordering of point clouds according to an order derived from a specific serialization schema. (b) Fill the point cloud sequence by borrowing points from adjacent patches to ensure that it is divisible by the specified patch size.
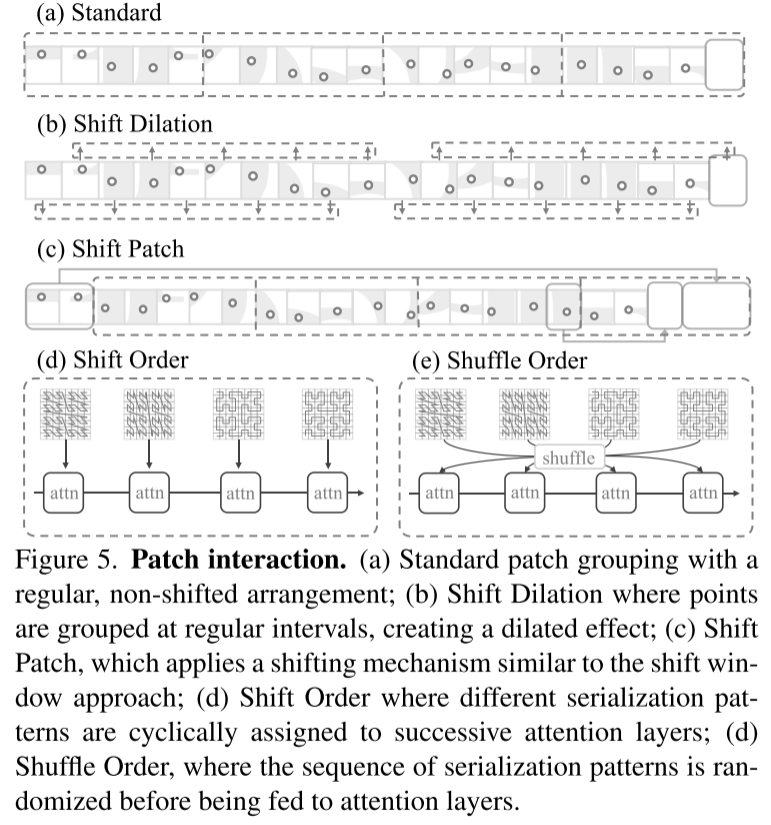
Figure 5. Patch interaction. (a) Standard patch grouping, with a regular, non-shifted arrangement; (b) Translational expansion, in which points are aggregated at regular intervals to produce an expansion effect; (c) Shift Patch, which uses a shifting mechanism similar to the shift window method ; (d) Shift Order, in which different serialization patterns are cyclically assigned to successive attention layers; (d) Shuffle Order, in which the sequence of serialization patterns is randomized before being input to the attention layer.
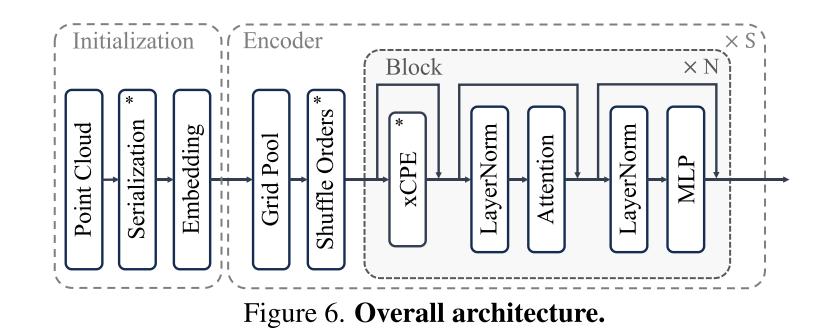
Figure 6. Overall architecture.
Experimental results:
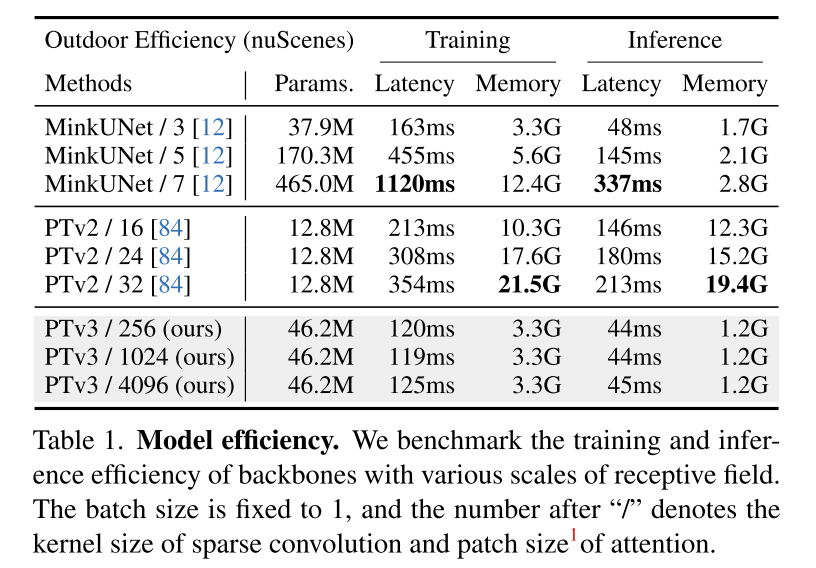
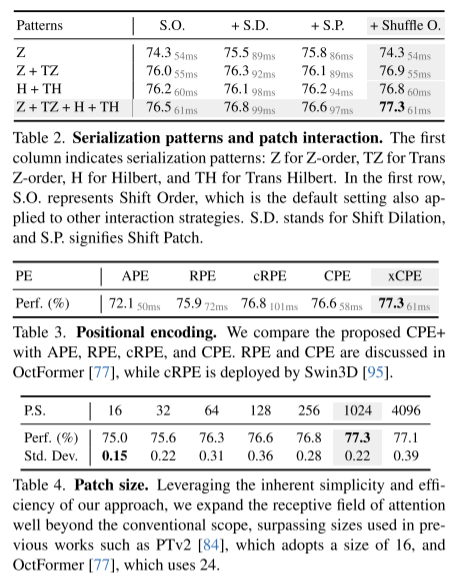
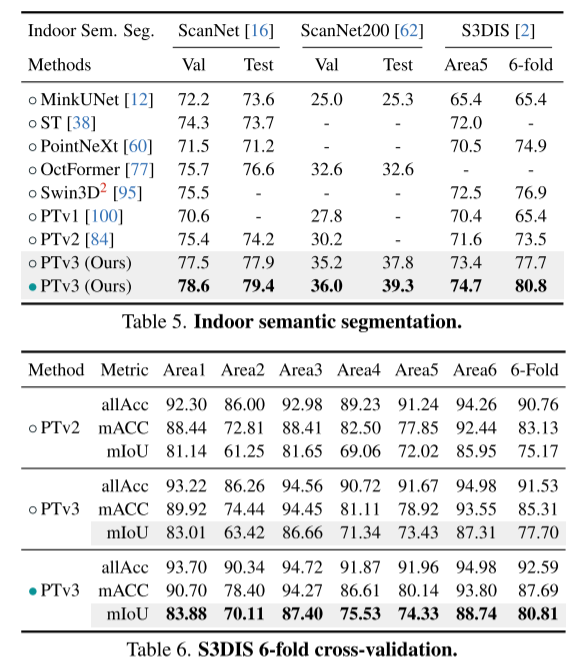
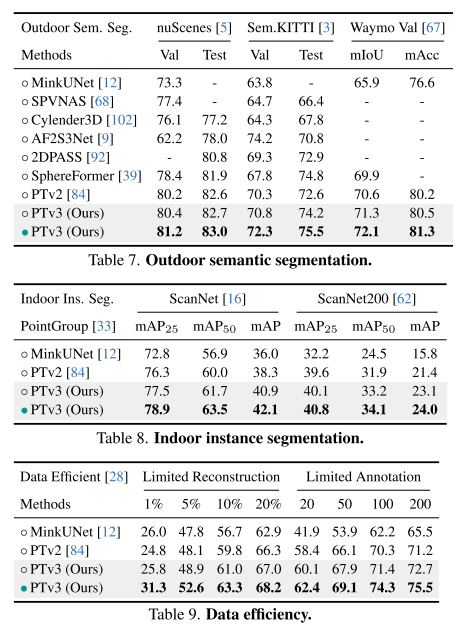
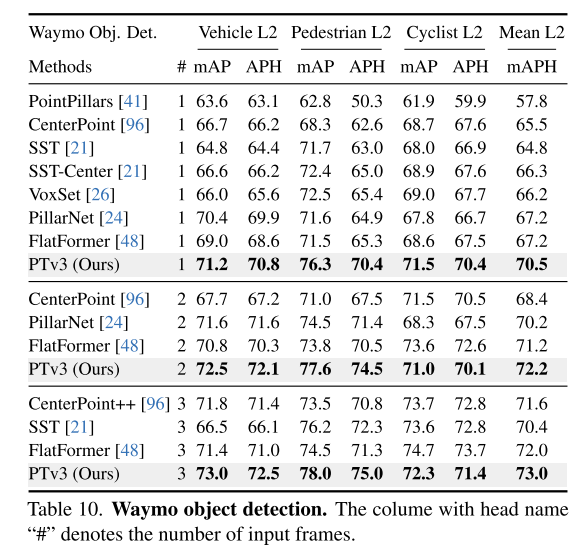
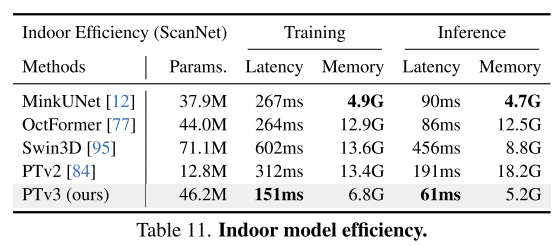
##Summary:
This article introduces Point Transformer V3, which works towards overcoming The traditional trade-off between accuracy and efficiency in point cloud processing takes a big step forward. Guided by a novel interpretation of the scaling principle in backbone design, this paper argues that model performance is more profoundly affected by scale than by complexity of design. By prioritizing efficiency over the accuracy of smaller impact mechanisms, this paper leverages the power of scale, thereby improving performance. In short, this article can make a model more powerful by making it simpler and faster.Citation:
Wu, X., Jiang, L., Wang, P., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T., & Zhao, H. (2023). Point Transformer V3: Simpler, Faster, Stronger.ArXiv. /abs/2312.10035

The above is the detailed content of Updated Point Transformer: more efficient, faster and more powerful!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Abandon the encoder-decoder architecture and use the diffusion model for edge detection, which is more effective. The National University of Defense Technology proposed DiffusionEdge
Feb 07, 2024 pm 10:12 PM
Abandon the encoder-decoder architecture and use the diffusion model for edge detection, which is more effective. The National University of Defense Technology proposed DiffusionEdge
Feb 07, 2024 pm 10:12 PM
Current deep edge detection networks usually adopt an encoder-decoder architecture, which contains up and down sampling modules to better extract multi-level features. However, this structure limits the network to output accurate and detailed edge detection results. In response to this problem, a paper on AAAI2024 provides a new solution. Thesis title: DiffusionEdge:DiffusionProbabilisticModelforCrispEdgeDetection Authors: Ye Yunfan (National University of Defense Technology), Xu Kai (National University of Defense Technology), Huang Yuxing (National University of Defense Technology), Yi Renjiao (National University of Defense Technology), Cai Zhiping (National University of Defense Technology) Paper link: https ://ar
 Tongyi Qianwen is open source again, Qwen1.5 brings six volume models, and its performance exceeds GPT3.5
Feb 07, 2024 pm 10:15 PM
Tongyi Qianwen is open source again, Qwen1.5 brings six volume models, and its performance exceeds GPT3.5
Feb 07, 2024 pm 10:15 PM
In time for the Spring Festival, version 1.5 of Tongyi Qianwen Model (Qwen) is online. This morning, the news of the new version attracted the attention of the AI community. The new version of the large model includes six model sizes: 0.5B, 1.8B, 4B, 7B, 14B and 72B. Among them, the performance of the strongest version surpasses GPT3.5 and Mistral-Medium. This version includes Base model and Chat model, and provides multi-language support. Alibaba’s Tongyi Qianwen team stated that the relevant technology has also been launched on the Tongyi Qianwen official website and Tongyi Qianwen App. In addition, today's release of Qwen 1.5 also has the following highlights: supports 32K context length; opens the checkpoint of the Base+Chat model;
 Large models can also be sliced, and Microsoft SliceGPT greatly increases the computational efficiency of LLAMA-2
Jan 31, 2024 am 11:39 AM
Large models can also be sliced, and Microsoft SliceGPT greatly increases the computational efficiency of LLAMA-2
Jan 31, 2024 am 11:39 AM
Large language models (LLMs) typically have billions of parameters and are trained on trillions of tokens. However, such models are very expensive to train and deploy. In order to reduce computational requirements, various model compression techniques are often used. These model compression techniques can generally be divided into four categories: distillation, tensor decomposition (including low-rank factorization), pruning, and quantization. Pruning methods have been around for some time, but many require recovery fine-tuning (RFT) after pruning to maintain performance, making the entire process costly and difficult to scale. Researchers from ETH Zurich and Microsoft have proposed a solution to this problem called SliceGPT. The core idea of this method is to reduce the embedding of the network by deleting rows and columns in the weight matrix.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Updated Point Transformer: more efficient, faster and more powerful!
Jan 17, 2024 am 08:27 AM
Updated Point Transformer: more efficient, faster and more powerful!
Jan 17, 2024 am 08:27 AM
Original title: PointTransformerV3: Simpler, Faster, Stronger Paper link: https://arxiv.org/pdf/2312.10035.pdf Code link: https://github.com/Pointcept/PointTransformerV3 Author unit: HKUSHAILabMPIPKUMIT Paper idea: This article is not intended to be published in Seeking innovation within the attention mechanism. Instead, it focuses on leveraging the power of scale to overcome existing trade-offs between accuracy and efficiency in the context of point cloud processing. Draw inspiration from recent advances in 3D large-scale representation learning,
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 LLaVA-1.6, which catches up with Gemini Pro and improves reasoning and OCR capabilities, is too powerful
Feb 01, 2024 pm 04:51 PM
LLaVA-1.6, which catches up with Gemini Pro and improves reasoning and OCR capabilities, is too powerful
Feb 01, 2024 pm 04:51 PM
In April last year, researchers from the University of Wisconsin-Madison, Microsoft Research, and Columbia University jointly released LLaVA (Large Language and Vision Assistant). Although LLaVA is only trained with a small multi-modal instruction data set, it shows very similar inference results to GPT-4 on some samples. Then in October, they launched LLaVA-1.5, which refreshed the SOTA in 11 benchmarks with simple modifications to the original LLaVA. The results of this upgrade are very exciting, bringing new breakthroughs to the field of multi-modal AI assistants. The research team announced the launch of LLaVA-1.6 version, targeting reasoning, OCR and
