

Text-to-image (T2I) diffusion model excels in generating high-definition images thanks to its pre-training on large-scale image-text pairs.
This raises a natural question: Can diffusion models be used to solve visual perception tasks?
Recently, teams from ByteDance and Fudan University proposed a diffusion model to handle visual tasks.

Paper address: https://arxiv.org/abs/2312.14733
Open source project: https://github.com/fudan-zvg/meta-prompts
The team’s key insight is to introduce learnable meta-prompts into the pre-trained diffusion model to extract suitable Characteristics of specific perceptual tasks.
The team applies the text-to-image diffusion model as a feature extractor to visual perception tasks.
First, the input image is compressed by the VQVAE encoder, the resolution is reduced to 1/8 of the original size, and a latent space feature representation is generated. It is worth noting that the VQVAE encoder parameters are fixed and do not participate in subsequent training.
Next step, send the data without noise to UNet for feature extraction. To better adapt to different tasks, UNet receives modulated time-step embeddings and multiple meta-cues simultaneously to generate shape-consistent features.
During the entire process, in order to enhance feature expression, this method performs repeated refinement. This enables better interactive fusion of features from different layers within UNet. In the second cycle, the parameters of UNet are adjusted by specific learnable temporal modulation features.
Finally, the multi-scale features generated by UNet are input into a decoder specifically designed for the target vision task.
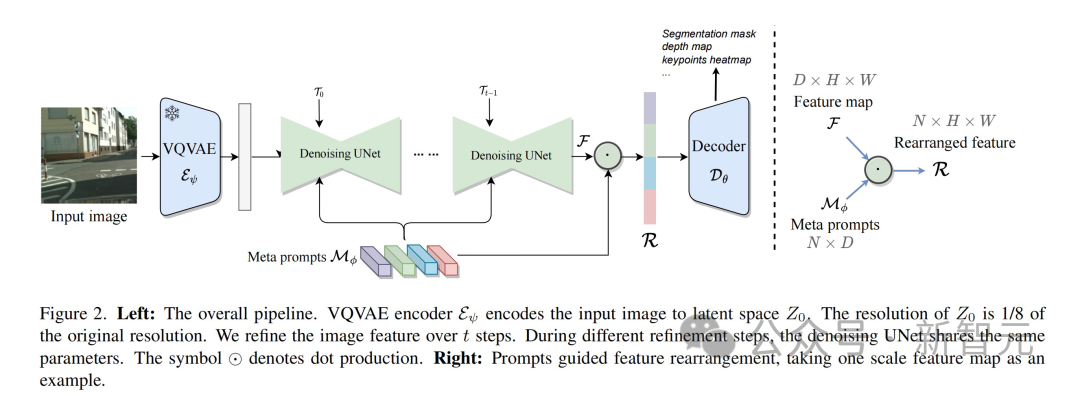
Learnable meta prompts design
Stable The diffusion model adopts the UNet architecture and integrates text cues into image features through cross-attention to achieve a Vincentian graph. This integration ensures that image generation is contextually and semantically accurate.
However, the diversity of visual perception tasks goes beyond this scope, as image understanding faces different challenges and often lacks textual information as guidance, making text-driven methods sometimes unrealistic.
To address this challenge, the technical team’s approach adopts a more diverse strategy—rather than relying on external text cues, we design an internal learnable meta-cue. Known as meta prompts, these meta prompts are integrated into diffusion models to adapt to perceptual tasks.
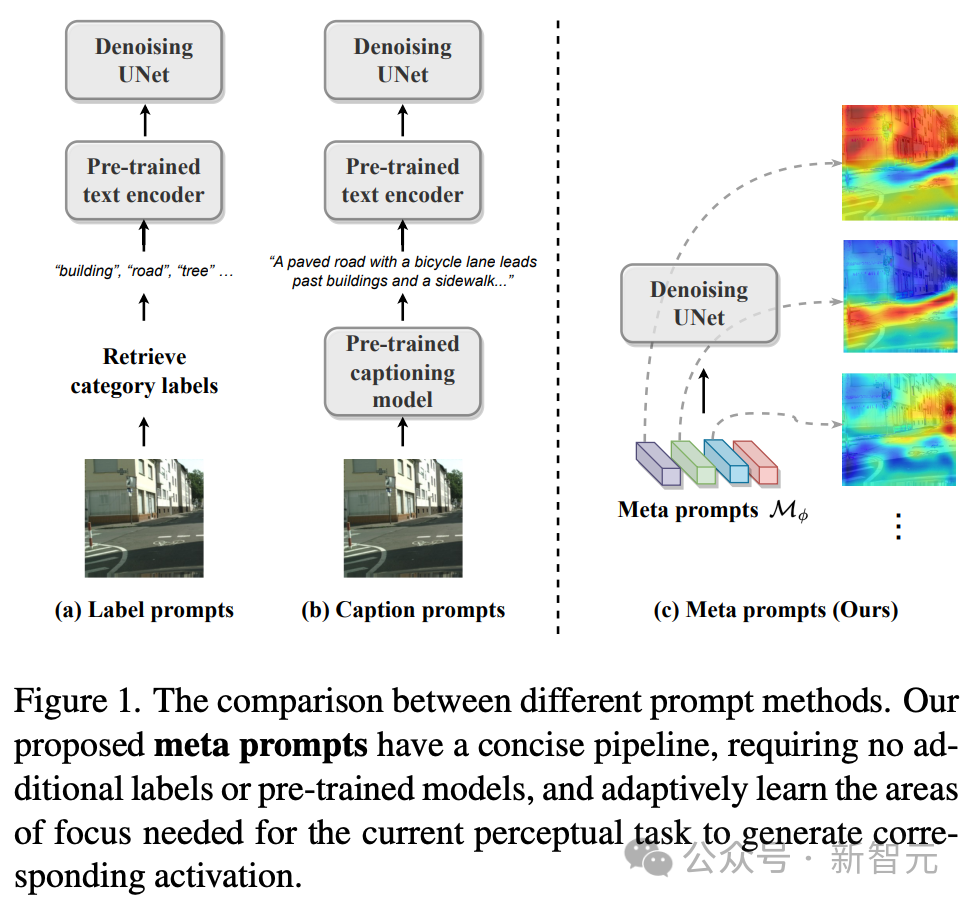
Meta prompts are expressed in the form of a matrix, which represents the number of meta prompts and represents the dimension. Perceptual diffusion models with meta prompts avoid the need for external text prompts, such as dataset category labels or image titles, and do not require a pre-trained text encoder to generate the final text prompts.
Meta prompts can be trained end-to-end according to the target task and data set, thereby establishing specially customized adaptation conditions for denoising UNet. These meta prompts contain rich semantic information adapted to specific tasks. For example:
- In the semantic segmentation task, meta prompts effectively demonstrate the ability to identify categories, and the same meta prompts tend to activate features of the same category .

- In the depth estimation task, meta prompts show the ability to perceive depth, and the activation value changes with depth. Enables prompts to focus on objects at a consistent distance.

- In pose estimation, meta prompts exhibit a different set of capabilities, especially the perception of key points, which facilitates human pose detection.
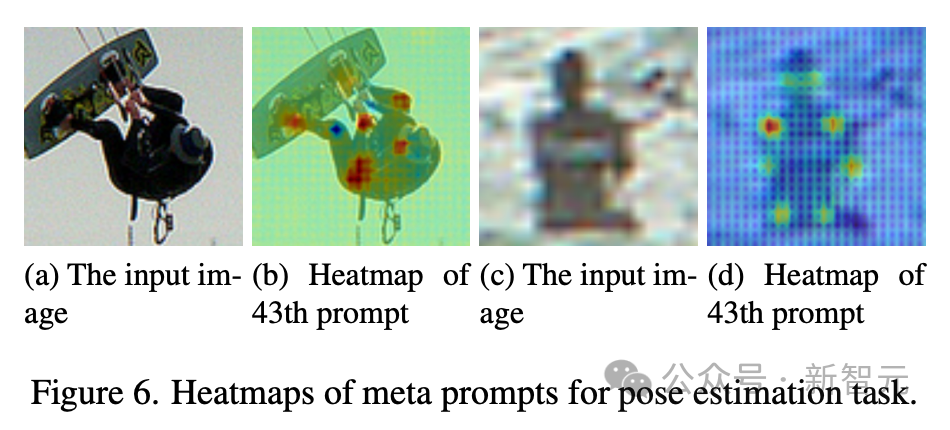
#These qualitative results together highlight the effectiveness of the meta prompts proposed by the technical team in activating task-related abilities in various tasks.
As an alternative to text prompts, meta prompts well fill the gap between text-to-image diffusion models and visual perception tasks.
Feature reorganization based on meta-cues
The diffusion model is generated in denoising UNet through its inherent design Multi-scale features that focus on finer, lower-level details closer to the output layer.
While this low-level detail is sufficient for tasks that emphasize texture and fine-grainedness, visual perception tasks often require understanding content that includes both low-level detail and high-level semantic interpretation.
Therefore, not only does it need to generate rich features, it is also very important to determine which combination of these multi-scale features can provide the best representation for the current task.
This is where meta prompts come in -
These prompts hold context during training that is specific to the dataset used Knowledge. This contextual knowledge enables meta prompts to act as filters for feature recombination, guiding the feature selection process and filtering out the most relevant features for the task from the many features generated by UNet.
The team uses a dot product approach to combine the richness of multi-scale features of UNet with the task adaptability of meta prompts.
Consider multi-scale features, each of which. and represent the height and width of the feature map. Meta prompts. The rearranged features at each scale are calculated as:
Finally, these features filtered by meta prompts are then input into a task-specific decoder.
Recurrent refinement based on learnable temporal modulation features
In the diffusion model, add noise and then multi-step The iterative process of denoising forms the framework for image generation.
Inspired by this mechanism, the technical team designed a simple recurrent refinement process for visual perception tasks—without adding noise to the output features, but directly adding the output features of UNet Loop input into UNet.
At the same time, in order to solve the inconsistency problem that as the model passes through the loop, the distribution of input features changes but the parameters of UNet remain unchanged, the technical team introduced learnable for each loop Unique timestep embeddings to modulate UNet's parameters.
This ensures that the network remains adaptable and responsive to the variability of input features in different steps, optimizing the feature extraction process and enhancing the model's performance in visual recognition tasks.
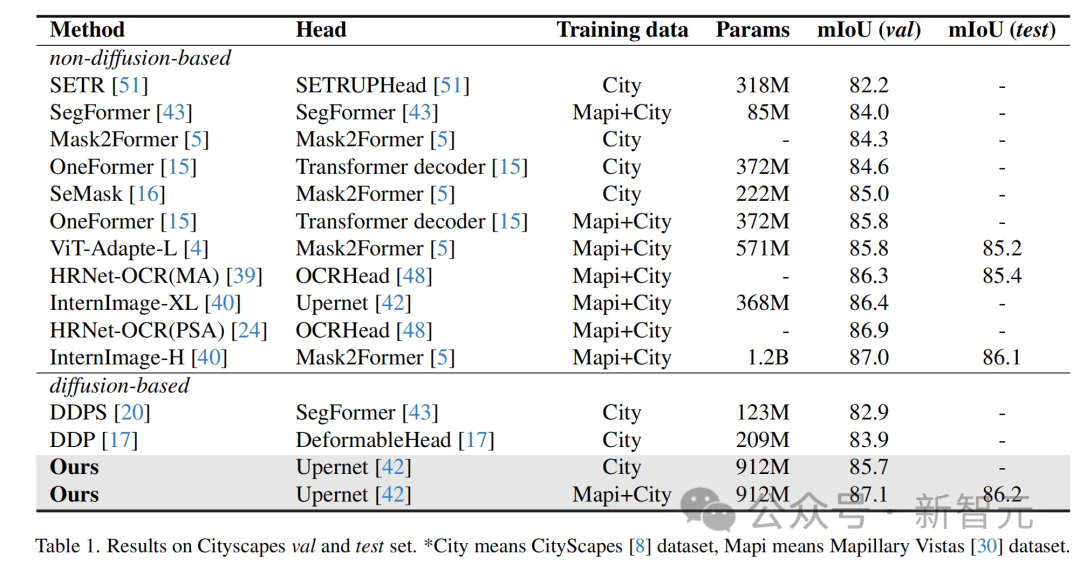
The results show that this method has achieved optimal results on multiple perception task data sets.
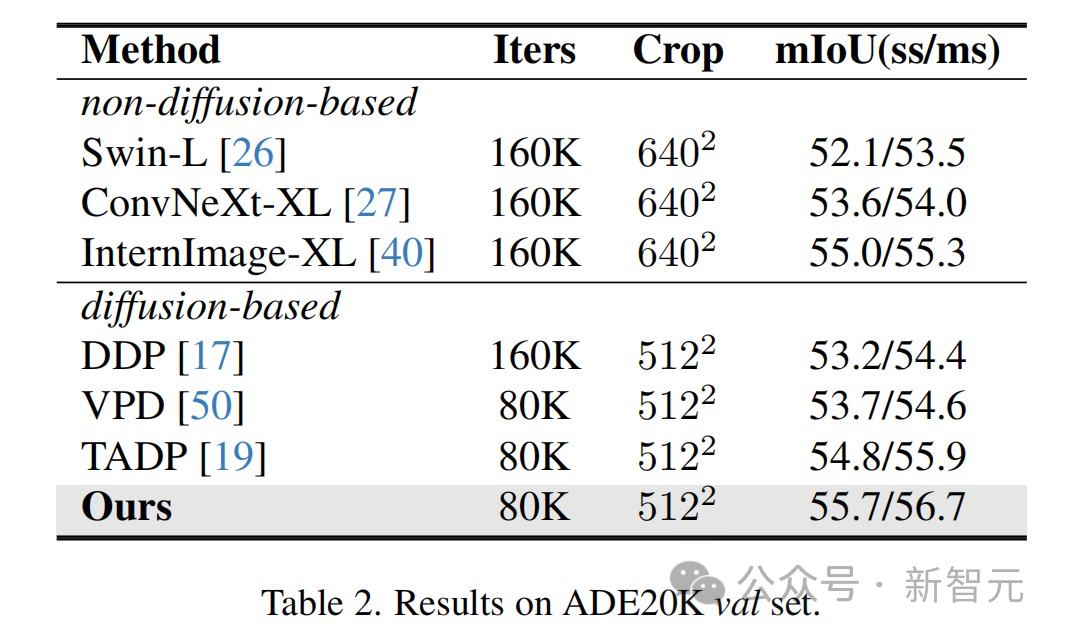
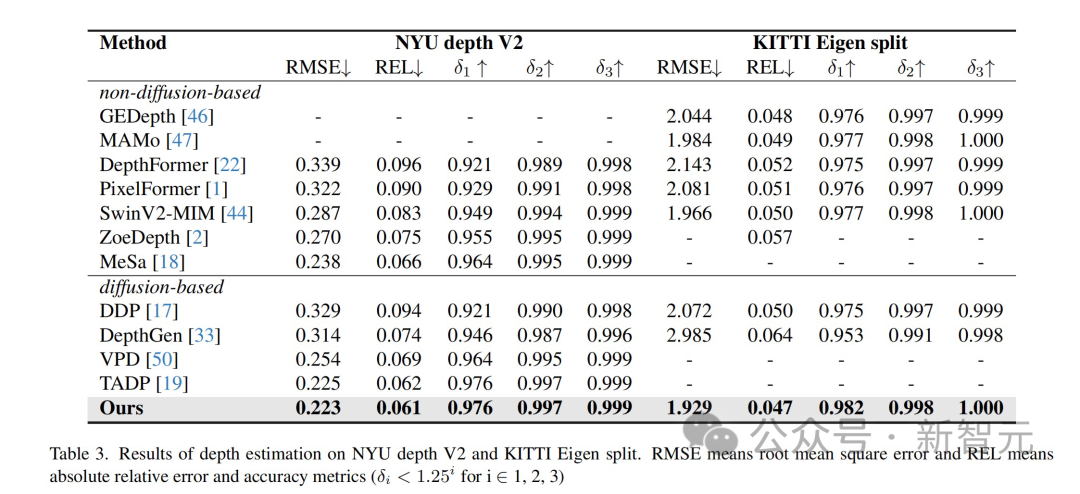
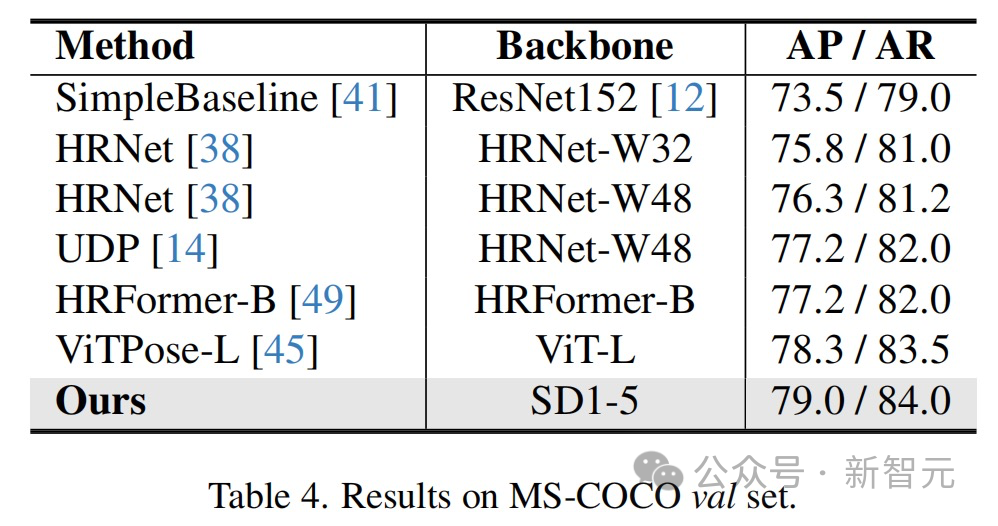
The methods and technologies proposed in this article have broad application prospects and can promote technological development and innovation in multiple fields:
The intelligent creation team is ByteDance’s AI & multimedia technology center, covering computer vision, audio and video editing, special effects processing and other technical fields , with the help of the company's rich business scenarios, infrastructure resources and technical collaboration atmosphere, it has realized a closed loop of cutting-edge algorithms-engineering systems-products, aiming to provide the company's internal businesses with cutting-edge content understanding and content in various forms. Capabilities and industry solutions for creation, interactive experience and consumption.
Currently, the intelligent creation team has opened its technical capabilities and services to enterprises through Volcano Engine, a cloud service platform owned by ByteDance. More positions related to large model algorithms are open, please click 「Read the original text」 to view.
The above is the detailed content of The innovative 'meta-tip' strategy of the Byte Fudan team has improved the performance of diffusion model image understanding, reaching an unprecedented level!. For more information, please follow other related articles on the PHP Chinese website!
 How to flash Xiaomi phone
How to flash Xiaomi phone
 How to center div in css
How to center div in css
 How to open rar file
How to open rar file
 Methods for reading and writing java dbf files
Methods for reading and writing java dbf files
 How to solve the problem that the msxml6.dll file is missing
How to solve the problem that the msxml6.dll file is missing
 Commonly used permutation and combination formulas
Commonly used permutation and combination formulas
 Virtual mobile phone number to receive verification code
Virtual mobile phone number to receive verification code
 dynamic photo album
dynamic photo album








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



