
 Technology peripherals
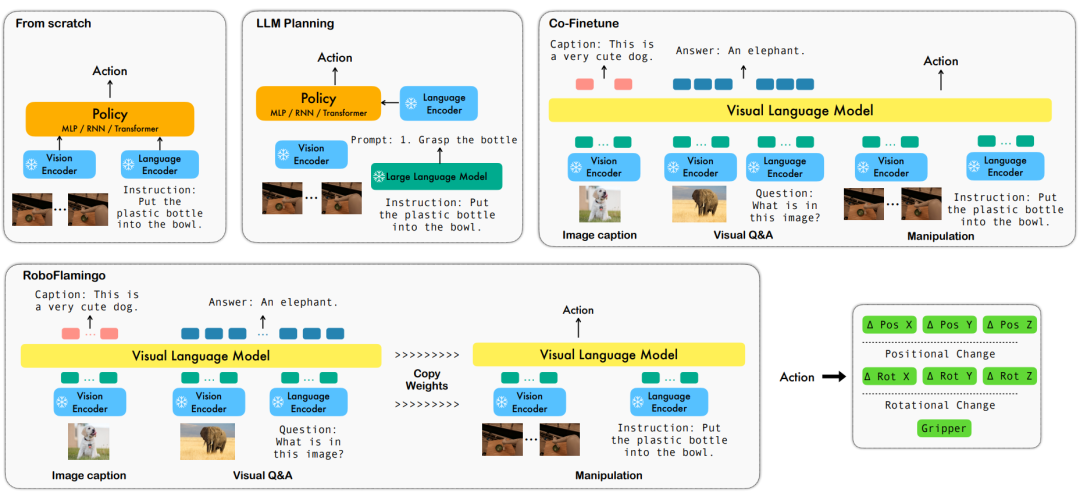
AI
The potential of open source VLMs is unleashed by the RoboFlamingo framework
Technology peripherals
AI
The potential of open source VLMs is unleashed by the RoboFlamingo framework
The potential of open source VLMs is unleashed by the RoboFlamingo framework

In recent years, research on large models has been accelerating, and it has gradually demonstrated multi-modal understanding and temporal and spatial reasoning capabilities in various tasks. Various embodied operation tasks of robots naturally have high requirements for language command understanding, scene perception, and spatio-temporal planning. This naturally leads to a question: Can the capabilities of large models be fully utilized and migrated to the field of robotics? What about directly planning the underlying action sequence?
ByteDance Research uses the open source multi-modal language vision large model OpenFlamingo to develop an easy-to-use RoboFlamingo robot operation model that requires only stand-alone training. VLM can be turned into Robotics VLM through simple fine-tuning, which is suitable for language interaction robot operation tasks.
Verified by OpenFlamingo on the robot operation data set CALVIN. Experimental results show that RoboFlamingo uses only 1% of the data with language annotation and achieves SOTA performance in a series of robot operation tasks. With the opening of the RT-X data set, RoboFlamingo, which is pre-trained on open source data, and fine-tuned for different robot platforms, is expected to become a simple and effective large-scale robot model process. The paper also tested the fine-tuning performance of VLM with different strategy heads, different training paradigms and different Flamingo structures on robot tasks, and came to some interesting conclusions.

- ## Project homepage: https://roboflamingo.github.io
- Code address: https://github.com/RoboFlamingo/RoboFlamingo
- Paper address: https://arxiv.org/ abs/2311.01378
Research background
Language-based robot operation is an important application in the field of embodied intelligence, involving the understanding and processing of multi-modal data, including vision, language and control. In recent years, visual language-based models (VLMs) have made significant progress in areas such as image description, visual question answering, and image generation. However, applying these models to robot operations still faces challenges, such as how to integrate visual and language information and how to handle the temporal sequence of robot operations. Solving these challenges requires improvements in multiple aspects, such as improving the multi-modal representation capabilities of the model, designing a more effective model fusion mechanism, and introducing model structures and algorithms that adapt to the sequential nature of robot operations. Additionally, there is a need to develop richer robotics datasets to train and evaluate these models. Through continuous research and innovation, language-based robot operations are expected to play a greater role in practical applications and provide more intelligent and convenient services to humans.
In order to solve these problems, ByteDance Research's robotics research team fine-tuned the existing open source VLM (Visual Language Model) - OpenFlamingo, and designed a new visual language Operational framework, called RoboFlamingo. The characteristic of this framework is that it uses VLM to achieve single-step visual language understanding and processes historical information through an additional policy head module. Through simple fine-tuning methods, RoboFlamingo can be adapted to language-based robot operation tasks. The introduction of this framework is expected to solve a series of problems existing in current robot operations.
RoboFlamingo was verified on the language-based robot operation data set CALVIN. The experimental results show that RoboFlamingo only utilizes 1% of the language-annotated data, that is, in a series of robot operation tasks The performance of SOTA has been achieved (the task sequence success rate of multi-task learning is 66%, the average number of task completions is 4.09, the baseline method is 38%, the average number of task completions is 3.06; the success rate of the zero-shot task is 24%, The average number of task completions is 2.48 (the baseline method is 1%, the average number of task completions is 0.67), and it can achieve real-time response through open-loop control and can be flexibly deployed on lower-performance platforms. These results demonstrate that RoboFlamingo is an effective robot manipulation method and can provide a useful reference for future robotic applications.
method
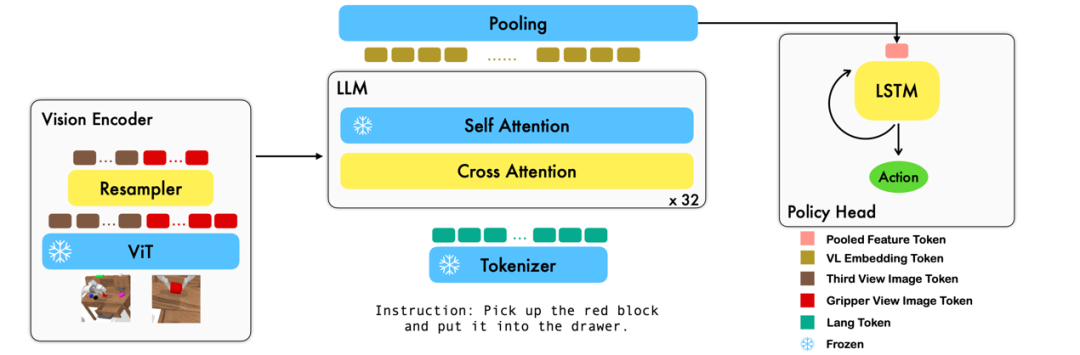
This work uses the existing visual language basic model based on image-text pairs to generate the relative actions of each step of the robot through training in an end-to-end manner. The model consists of three main modules: Vision encoder, Feature fusion decoder and Policy head. In the Vision encoder module, the current visual observation is first input into ViT, and then the token output by ViT is down sampled through the resampler. This step helps reduce the input dimension of the model, thereby improving training efficiency. The Feature fusion decoder module takes text tokens as input and uses the output of the visual encoder as a query through a cross-attention mechanism, achieving the fusion of visual and language features. In each layer, the feature fusion decoder first performs the cross-attention operation and then performs the self-attention operation. These operations help extract correlations between language and visual features to better generate robot actions. Based on the current and historical token sequences output by the Feature fusion decoder, the Policy head directly outputs the current 7 DoF relative actions, including the 6-dim robot arm end pose and the 1-dim gripper open/close. Finally, perform max pooling on the feature fusion decoder and send it to the Policy head to generate relative actions. In this way, our model is able to effectively fuse visual and linguistic information together to generate accurate robot movements. This has broad application prospects in fields such as robot control and autonomous navigation.
During the training process, RoboFlamingo utilizes the pre-trained ViT, LLM and Cross Attention parameters and only fine-tunes the parameters of resampler, cross attention and policy head.
Experimental results
Data set:
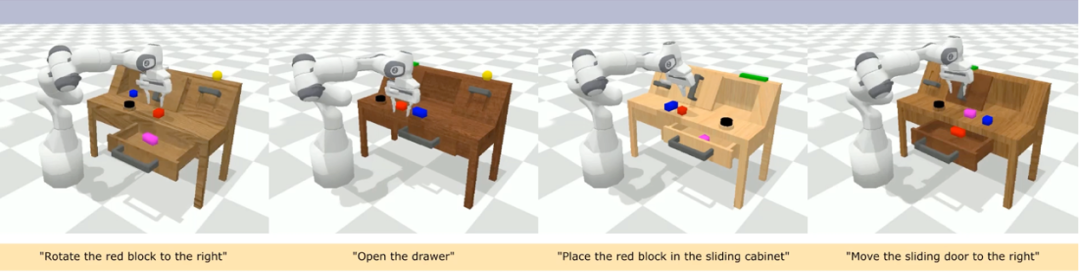
CALVIN (Composing Actions from Language and Vision) is an open source simulation benchmark for learning language-based long-horizon operation tasks. Compared with existing visual-linguistic task datasets, CALVIN's tasks are more complex in terms of sequence length, action space, and language, and support flexible specification of sensor inputs. CALVIN is divided into four splits ABCD, each split corresponds to a different context and layout.
Quantitative analysis:
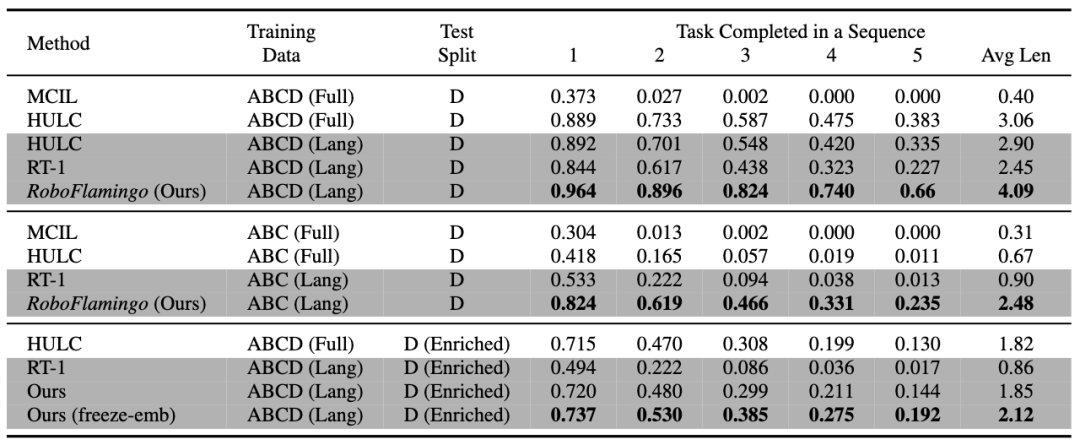
RoboFlamingo has the best performance in every setting and indicator. It shows that it has strong imitation ability, visual generalization ability and language generalization ability. Full and Lang indicate whether the model was trained using unpaired visual data (i.e. visual data without language pairing); Freeze-emb refers to freezing the embedding layer of the fused decoder; Enriched indicates using GPT-4 enhanced instructions.
Ablation experiment:
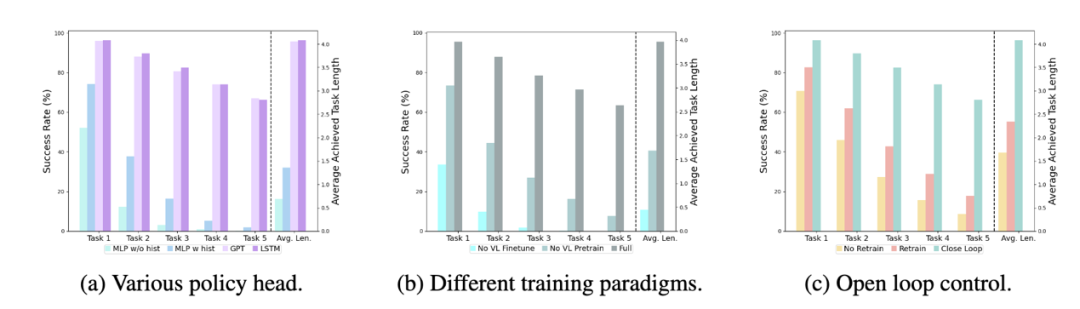
##Different policy heads:
The experiment examined four different policy heads: MLP w/o hist, MLP w hist, GPT and LSTM. Among them, MLP w/o hist directly predicts history based on current observations, and its performance is the worst. MLP w hist fuses historical observations at the vision encoder end and predicts actions, and the performance is improved; GPT and LSTM are explicitly stated at the policy head. , implicitly maintains historical information, and its performance is the best, which illustrates the effectiveness of historical information fusion through policy head.
The impact of visual-language pre-training:
Pre-training plays a key role in improving the performance of RoboFlamingo. Experiments show that RoboFlamingo performs better on robotic tasks by pre-training on a large visual-linguistic dataset.
Model size and performance:
While generally larger models lead to better performance, experimental results show that even Smaller models can also compete with larger models on some tasks.
The impact of instruction fine-tuning:
Instruction fine-tuning is a powerful technique, and experimental results show that it can further improve the performance of the model.
Qualitative results
Compared with the baseline method, RoboFlamingo not only completely executed 5 consecutive subtasks, but also successfully executed the first two subtasks on the baseline page. RoboFlamingo also takes significantly fewer steps.
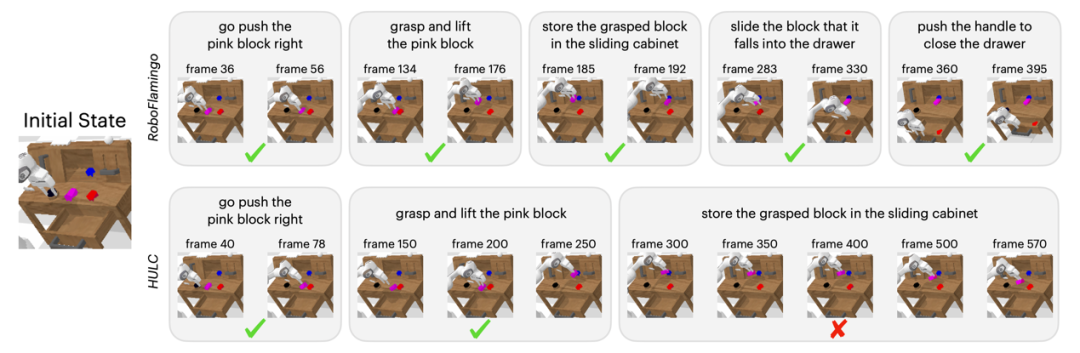
Summary
This work provides a novel reality-based robot operation strategy for language interaction. There are open source VLMs frameworks that can achieve excellent results with simple fine-tuning. RoboFlamingo provides robotics researchers with a powerful open source framework that can more easily realize the potential of open source VLMs. The rich experimental results in the work may provide valuable experience and data for the practical application of robotics and contribute to future research and technology development.
The above is the detailed content of The potential of open source VLMs is unleashed by the RoboFlamingo framework. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 How to change the size of a Bootstrap list?
Apr 07, 2025 am 10:45 AM
How to change the size of a Bootstrap list?
Apr 07, 2025 am 10:45 AM
The size of a Bootstrap list depends on the size of the container that contains the list, not the list itself. Using Bootstrap's grid system or Flexbox can control the size of the container, thereby indirectly resizing the list items.
 How to implement nesting of Bootstrap lists?
Apr 07, 2025 am 10:27 AM
How to implement nesting of Bootstrap lists?
Apr 07, 2025 am 10:27 AM
Nested lists in Bootstrap require the use of Bootstrap's grid system to control the style. First, use the outer layer <ul> and <li> to create a list, then wrap the inner layer list in <div class="row> and add <div class="col-md-6"> to the inner layer list to specify that the inner layer list occupies half the width of a row. In this way, the inner list can have the right one
 How to add icons to Bootstrap list?
Apr 07, 2025 am 10:42 AM
How to add icons to Bootstrap list?
Apr 07, 2025 am 10:42 AM
How to add icons to the Bootstrap list: directly stuff the icon into the list item <li>, using the class name provided by the icon library (such as Font Awesome). Use the Bootstrap class to align icons and text (for example, d-flex, justify-content-between, align-items-center). Use the Bootstrap tag component (badge) to display numbers or status. Adjust the icon position (flex-direction: row-reverse;), control the style (CSS style). Common error: The icon does not display (not
 What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
When converting strings to objects in Vue.js, JSON.parse() is preferred for standard JSON strings. For non-standard JSON strings, the string can be processed by using regular expressions and reduce methods according to the format or decoded URL-encoded. Select the appropriate method according to the string format and pay attention to security and encoding issues to avoid bugs.
 How to view Bootstrap's grid system
Apr 07, 2025 am 09:48 AM
How to view Bootstrap's grid system
Apr 07, 2025 am 09:48 AM
Bootstrap's mesh system is a rule for quickly building responsive layouts, consisting of three main classes: container (container), row (row), and col (column). By default, 12-column grids are provided, and the width of each column can be adjusted through auxiliary classes such as col-md-, thereby achieving layout optimization for different screen sizes. By using offset classes and nested meshes, layout flexibility can be extended. When using a grid system, make sure that each element has the correct nesting structure and consider performance optimization to improve page loading speed. Only by in-depth understanding and practice can we master the Bootstrap grid system proficiently.
 What changes have been made with the list style of Bootstrap 5?
Apr 07, 2025 am 11:09 AM
What changes have been made with the list style of Bootstrap 5?
Apr 07, 2025 am 11:09 AM
Bootstrap 5 list style changes are mainly due to detail optimization and semantic improvement, including: the default margins of unordered lists are simplified, and the visual effects are cleaner and neat; the list style emphasizes semantics, enhancing accessibility and maintainability.
 How to register components exported by export default in Vue
Apr 07, 2025 pm 06:24 PM
How to register components exported by export default in Vue
Apr 07, 2025 pm 06:24 PM
Question: How to register a Vue component exported through export default? Answer: There are three registration methods: Global registration: Use the Vue.component() method to register as a global component. Local Registration: Register in the components option, available only in the current component and its subcomponents. Dynamic registration: Use the Vue.component() method to register after the component is loaded.
 How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
MySQL performance optimization needs to start from three aspects: installation configuration, indexing and query optimization, monitoring and tuning. 1. After installation, you need to adjust the my.cnf file according to the server configuration, such as the innodb_buffer_pool_size parameter, and close query_cache_size; 2. Create a suitable index to avoid excessive indexes, and optimize query statements, such as using the EXPLAIN command to analyze the execution plan; 3. Use MySQL's own monitoring tool (SHOWPROCESSLIST, SHOWSTATUS) to monitor the database health, and regularly back up and organize the database. Only by continuously optimizing these steps can the performance of MySQL database be improved.
