
 Technology peripherals
AI
LeCun's evaluation: Meta evaluation of ConvNet and Transformer, which one is stronger?
Technology peripherals
AI
LeCun's evaluation: Meta evaluation of ConvNet and Transformer, which one is stronger?
LeCun's evaluation: Meta evaluation of ConvNet and Transformer, which one is stronger?

How to choose a visual model based on specific needs?
How do ConvNet/ViT and supervised/CLIP models compare with each other on indicators other than ImageNet?
The latest research published by researchers from MABZUAI and Meta comprehensively compares common visual models on "non-standard" indicators.

Paper address: https://arxiv.org/pdf/2311.09215.pdf
LeCun The study was highly praised and called excellent. The study compares similarly sized ConvNext and VIT architectures, providing a comprehensive comparison of various properties when trained in supervised mode and using CLIP methods.

Beyond ImageNet accuracy
The computer vision model landscape is becoming increasingly diverse and complex.
From early ConvNets to the evolution of Vision Transformers, the types of available models are constantly expanding.
Similarly, the training paradigm has evolved from supervised training on ImageNet to self-supervised learning and image-text pair training like CLIP.

While marking progress, this explosion of options poses a major challenge for practitioners: How to choose the goals that are right for them Model?
ImageNet accuracy has always been the main indicator for evaluating model performance. Since sparking the deep learning revolution, it has driven significant advances in the field of artificial intelligence.
However, it cannot measure the nuances of models resulting from different architectures, training paradigms, and data.
If judged solely by ImageNet accuracy, models with different properties may look similar (Figure 1). This limitation becomes more apparent as the model begins to overfit the features of ImageNet and accuracy reaches saturation.
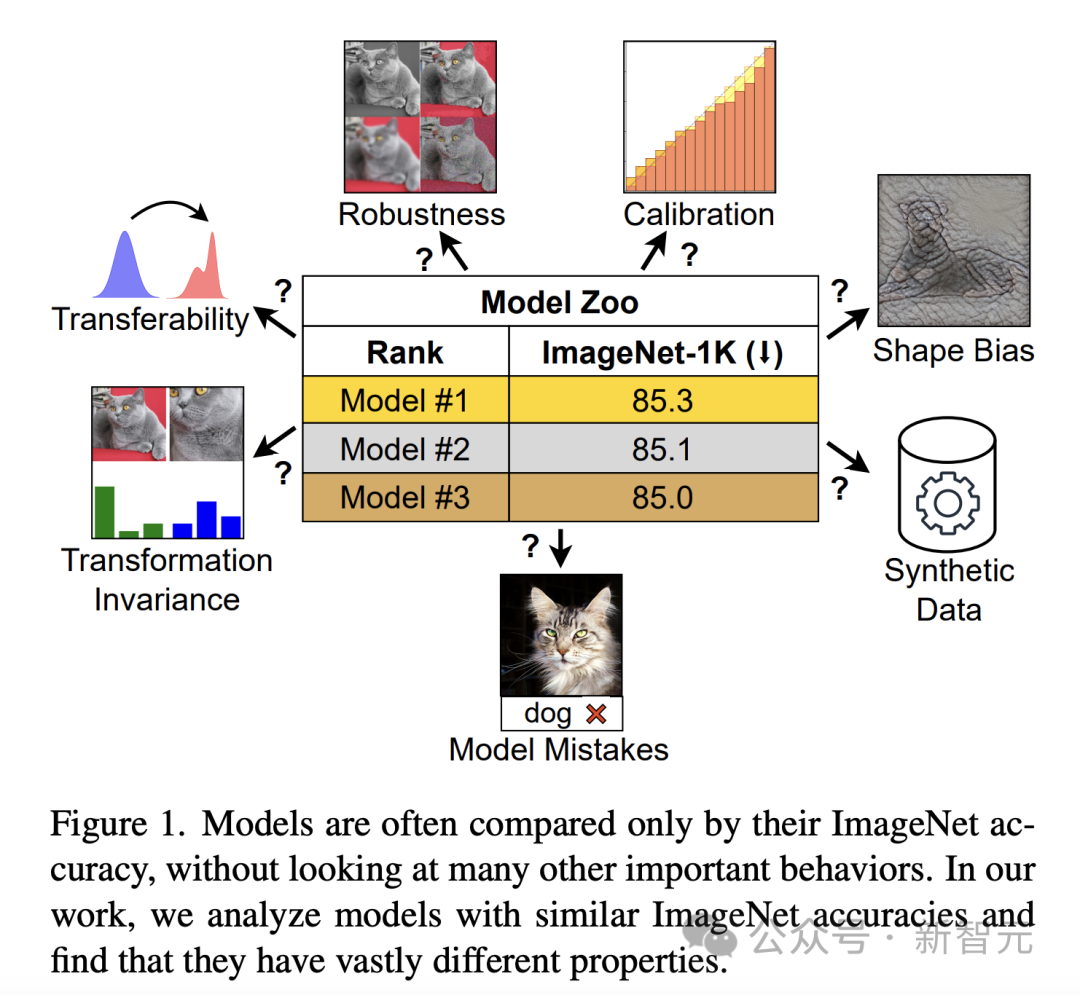
#To bridge the gap, the researchers conducted an in-depth exploration of model behavior beyond ImageNet accuracy.
In order to study the impact of architecture and training objectives on model performance, Vision Transformer (ViT) and ConvNeXt were specifically compared. The ImageNet-1K validation accuracy and computational requirements of these two modern architectures are comparable.
In addition, the study compared supervised models represented by DeiT3-Base/16 and ConvNeXt-Base, as well as OpenCLIP's visual encoder based on the CLIP model.

ANALYSIS OF RESULTS
The researchers' analysis is intended to require no further training or fine-tuning of the study. Evaluated model behavior.
This approach is particularly important for practitioners with limited computing resources, as they often rely on pre-trained models.
In the specific analysis, although the author recognizes the value of downstream tasks such as object detection, the focus is on those features that can provide insights with minimal computational requirements and reflect the application of real-world applications. Very important behavioral properties.
Model Error
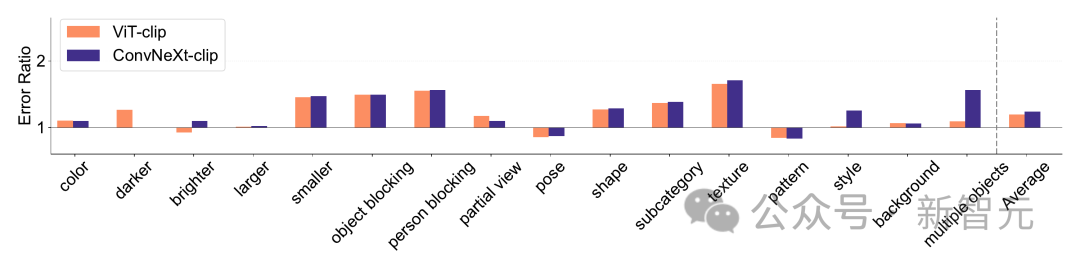
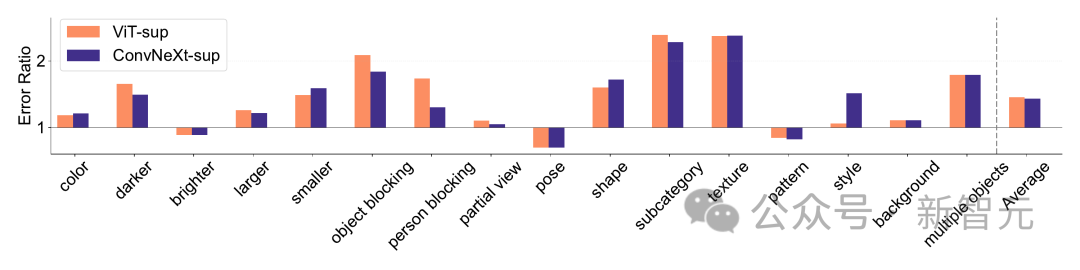
ImageNet-X is a dataset that extends ImageNet-1K and contains Detailed manual annotation of 16 changing factors, enabling in-depth analysis of model errors in image classification.
It uses error rates (lower is better) to quantify the model's performance on specific factors relative to overall accuracy, allowing for a nuanced analysis of model errors. Results on ImageNet-X show:
1. Relative to its ImageNet accuracy, the CLIP model makes fewer errors than the supervised model.
2. All models are mainly affected by complex factors such as occlusion.
3. Texture is the most challenging element of all models.
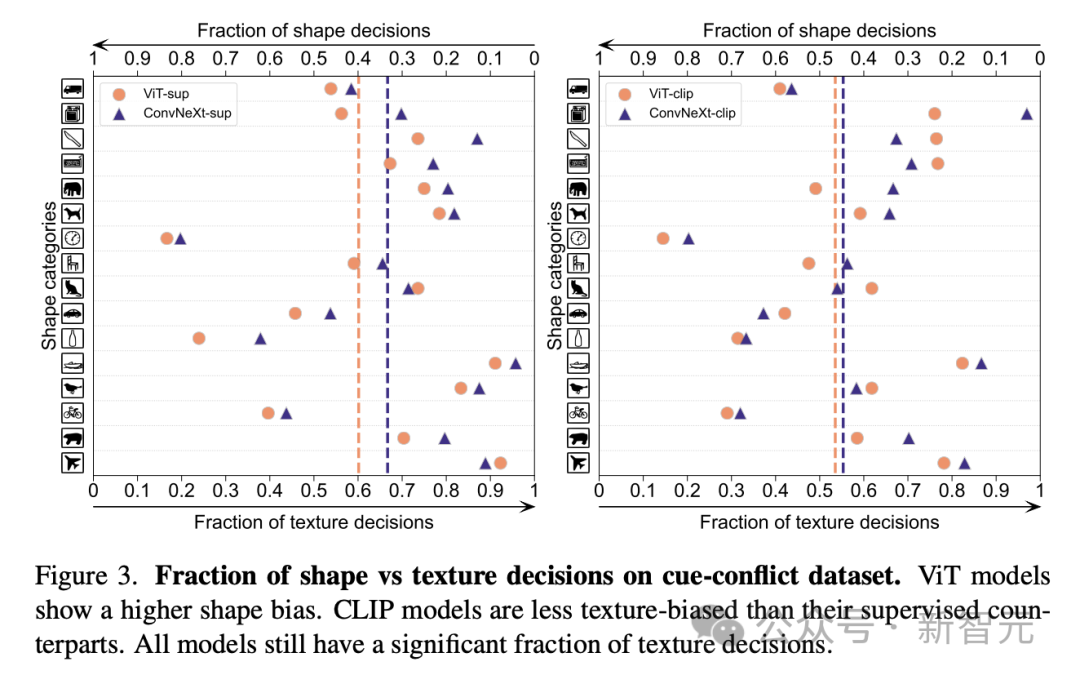
Shape/Texture Deviation
Shape/Texture Deviation checks whether the model relies on texture shortcuts rather than advanced shape hints.
This bias can be studied by combining cue-conflicting images of different categories of shape and texture.
This approach helps to understand to what extent the model's decisions are based on shape compared to texture.
The researchers evaluated the shape-texture bias on the cue conflict dataset and found that the texture bias of the CLIP model was smaller than that of the supervised model, while the shape bias of the ViT model was higher than that of ConvNets.
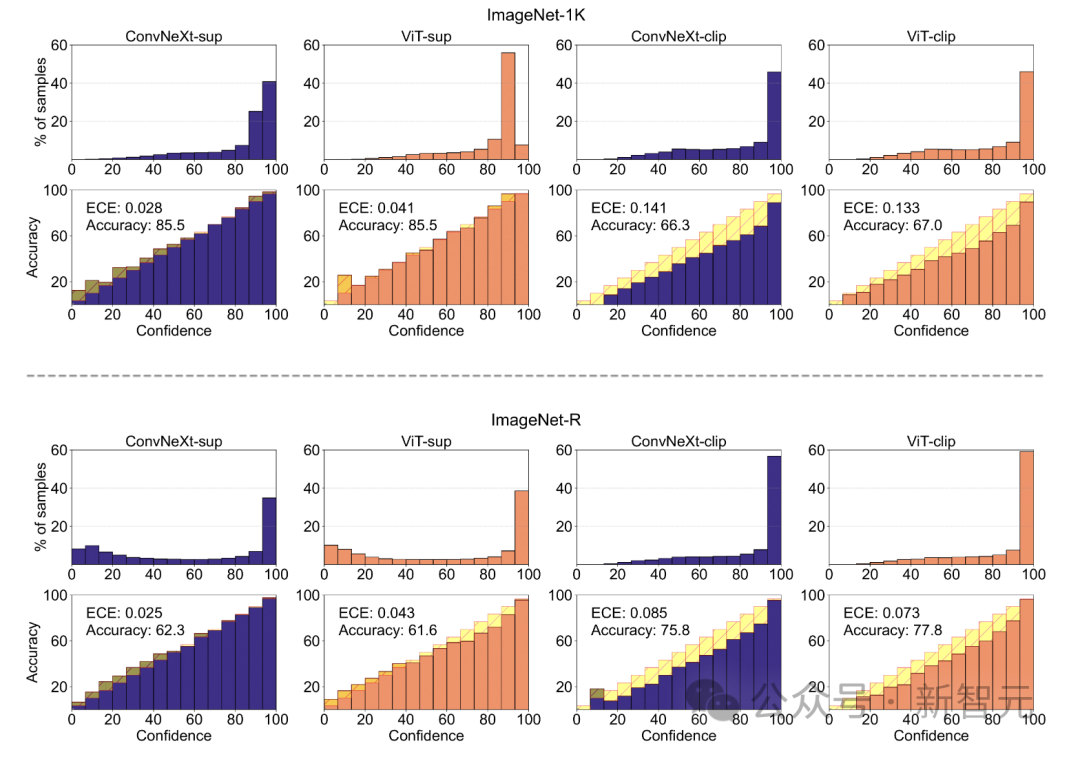
Model Calibration
Calibrate the prediction confidence of the quantifiable model and its Is the actual accuracy consistent?
This can be assessed through metrics such as expected calibration error (ECE), as well as visualization tools such as reliability plots and confidence histograms.
The researchers evaluated the calibration on ImageNet-1K and ImageNet-R, classifying predictions into 15 levels. In the experiment, the following points were observed:
- The CLIP model has high confidence, while the supervised model is slightly less confident.
- Supervised ConvNeXt is better calibrated than supervised ViT.
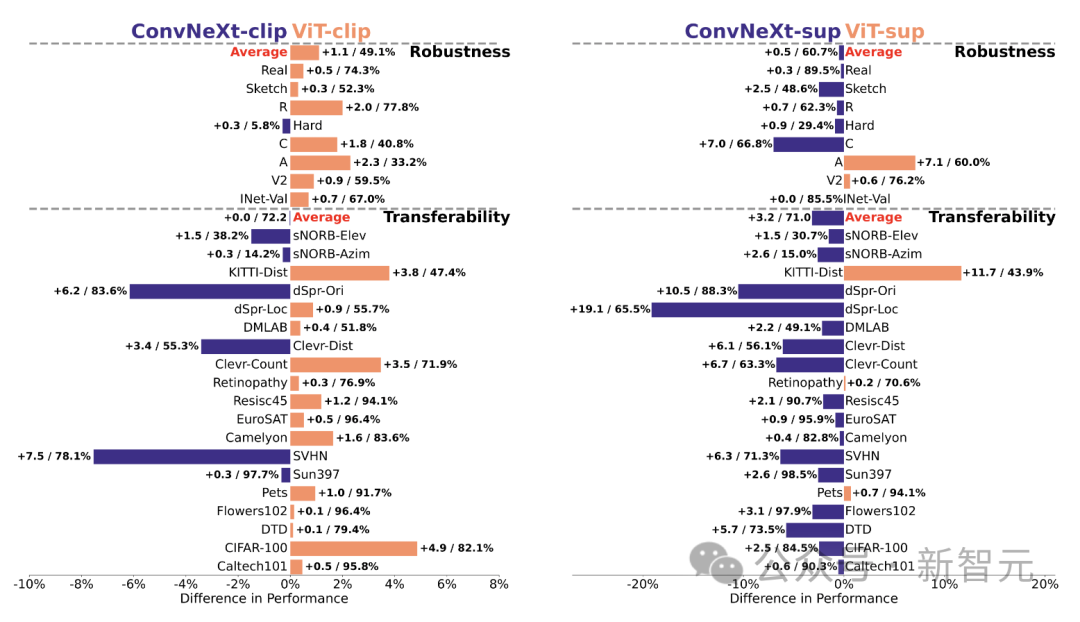
Robustness and portability
The robustness and portability of the model Portability is key to adapting to changes in data distribution and new tasks.
The researchers evaluated the robustness using different ImageNet variants and found that while the ViT and ConvNeXt models had similar average performance, except for ImageNet-R and ImageNet-Sketch, supervision Models generally outperform CLIP in terms of robustness.
In terms of portability, evaluated on 19 datasets using the VTAB benchmark, supervised ConvNeXt outperforms ViT and is almost on par with the performance of the CLIP model.
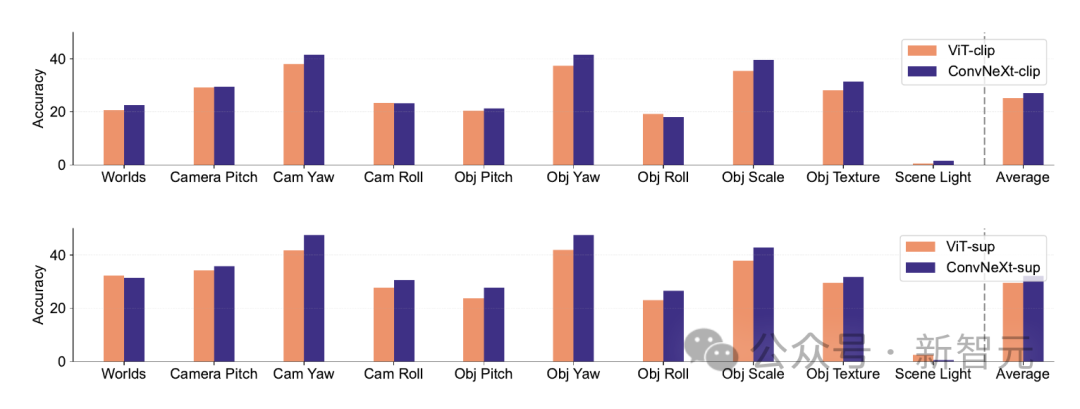
Synthetic data
Synthetic datasets like PUG-ImageNet , which can precisely control factors such as camera angle and texture, has become a promising research avenue, so researchers analyzed the model's performance based on synthetic data.
PUG-ImageNet contains photorealistic ImageNet images with systematic variations in lighting and other factors, with performance measured as the absolute highest accuracy.
The researchers provided results for different factors in PUG-ImageNet and found that ConvNeXt outperformed ViT in almost all factors.
This shows that ConvNeXt outperforms ViT on synthetic data, while the gap is smaller for the CLIP model, because the accuracy of the CLIP model is lower than the supervised model, which may be different from the accuracy of the original ImageNet lower related.
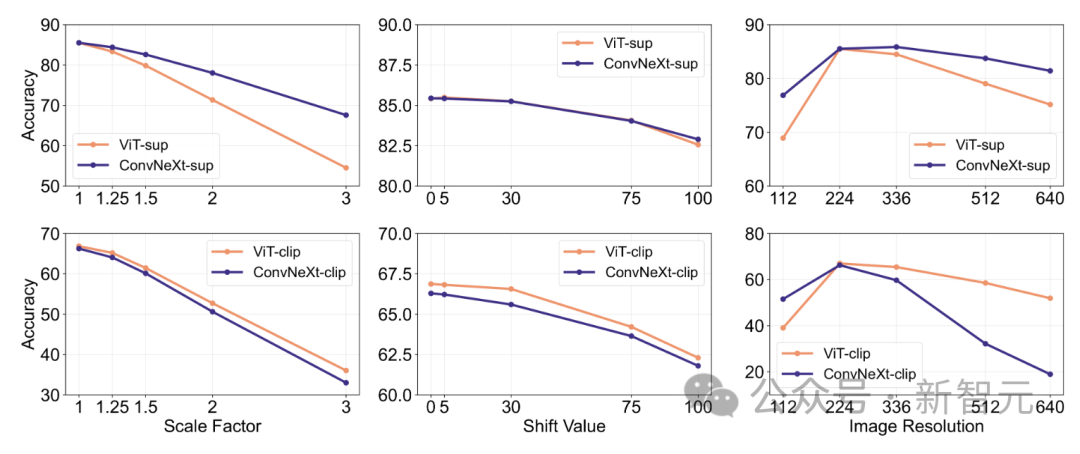
Feature invariance
Feature invariance refers to the ability of the model to produce Consistent representation that is not affected by input transformations, thus preserving semantics such as scaling or moving.
This feature enables the model to generalize well across different but semantically similar inputs.
The researchers’ approach includes resizing images to achieve scale invariance, moving crops to achieve position invariance, and adjusting the resolution of the ViT model using interpolated positional embeddings.
In supervised training, ConvNeXt outperforms ViT.
Overall, the model is more robust to scale/resolution transformations than to movements. For applications that require high robustness to scaling, displacement, and resolution, the results suggest that supervised ConvNeXt may be the best choice.
#The researchers found that each model had its own unique advantages.
This suggests that the choice of model should depend on the target use case, as standard performance metrics may overlook mission-critical nuances.
Furthermore, many existing benchmarks are derived from ImageNet, which biases the evaluation. Developing new benchmarks with different data distributions is crucial to evaluate models in a more realistically representative context.
ConvNet vs Transformer
- In many benchmarks, supervised ConvNeXt has better performance than supervised VIT Better performance: It is better calibrated, invariant to data transformations, exhibits better transferability and robustness.
- ConvNeXt outperforms ViT on synthetic data.
- ViT has a higher shape bias.
Supervised vs CLIP
- Although the CLIP model is better in terms of transferability, supervised ConvNeXt Demonstrated competence in this task. This demonstrates the potential of supervised models.
- Supervised models are better at robustness benchmarks, probably because these models are variants of ImageNet.
- The CLIP model has higher shape bias and fewer classification errors compared to its ImageNet accuracy.
The above is the detailed content of LeCun's evaluation: Meta evaluation of ConvNet and Transformer, which one is stronger?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to output a countdown in C language
Apr 04, 2025 am 08:54 AM
How to output a countdown in C language
Apr 04, 2025 am 08:54 AM
How to output a countdown in C? Answer: Use loop statements. Steps: 1. Define the variable n and store the countdown number to output; 2. Use the while loop to continuously print n until n is less than 1; 3. In the loop body, print out the value of n; 4. At the end of the loop, subtract n by 1 to output the next smaller reciprocal.
 How to play picture sequences smoothly with CSS animation?
Apr 04, 2025 pm 05:57 PM
How to play picture sequences smoothly with CSS animation?
Apr 04, 2025 pm 05:57 PM
How to achieve the playback of pictures like videos? Many times, we need to implement similar video player functions, but the playback content is a sequence of images. direct...
 Zustand asynchronous operation: How to ensure the latest state obtained by useStore?
Apr 04, 2025 pm 02:09 PM
Zustand asynchronous operation: How to ensure the latest state obtained by useStore?
Apr 04, 2025 pm 02:09 PM
Data update problems in zustand asynchronous operations. When using the zustand state management library, you often encounter the problem of data updates that cause asynchronous operations to be untimely. �...
 How to implement nesting effect of text annotations in Quill editor?
Apr 04, 2025 pm 05:21 PM
How to implement nesting effect of text annotations in Quill editor?
Apr 04, 2025 pm 05:21 PM
A solution to implement text annotation nesting in Quill Editor. When using Quill Editor for text annotation, we often need to use the Quill Editor to...
 Electron rendering process and WebView: How to achieve efficient 'synchronous' communication?
Apr 04, 2025 am 11:45 AM
Electron rendering process and WebView: How to achieve efficient 'synchronous' communication?
Apr 04, 2025 am 11:45 AM
Electron rendering process and WebView...
 How to use CSS to achieve smooth playback effect of image sequences?
Apr 04, 2025 pm 04:57 PM
How to use CSS to achieve smooth playback effect of image sequences?
Apr 04, 2025 pm 04:57 PM
How to realize the function of playing pictures like videos? Many times, we need to achieve similar video playback effects in the application, but the playback content is not...
 How to achieve the effect of high input elements but high text at the bottom?
Apr 04, 2025 pm 10:27 PM
How to achieve the effect of high input elements but high text at the bottom?
Apr 04, 2025 pm 10:27 PM
How to achieve the height of the input element is very high but the text is located at the bottom. In front-end development, you often encounter some style adjustment requirements, such as setting a height...
 How to quickly build a foreground page in a React Vite project using AI tools?
Apr 04, 2025 pm 01:45 PM
How to quickly build a foreground page in a React Vite project using AI tools?
Apr 04, 2025 pm 01:45 PM
How to quickly build a front-end page in back-end development? As a backend developer with three or four years of experience, he has mastered the basic JavaScript, CSS and HTML...
