

Two great tips to improve the efficiency of your Pandas code

If you have ever used Pandas with tabular data, you may be familiar with the process of importing the data, cleaning and transforming it, and then using it as input to the model. However, when you need to scale and put your code into production, your Pandas pipeline will most likely start to crash and run slowly. In this article, I will share 2 tips to help you speed up Pandas code execution, improve data processing efficiency, and avoid common pitfalls.

Tip 1: Vectorization operation
In Pandas, vectorization operation is an efficient tool that can process the entire data in a more concise way columns of boxes without looping row by row.
How does it work?
Broadcasting is a key element of vectorization operations, which allows you to intuitively manipulate objects with different shapes.
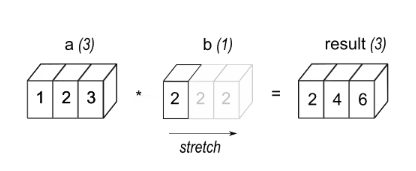
eg1: Array a with 3 elements is multiplied by scalar b, resulting in an array with the same shape as Source.
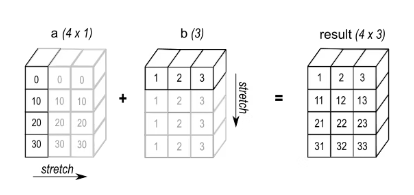
eg2: When performing addition operation, add array a with shape (4,1) and array b with shape (3,), and the result will be An array of shape (4,3).
There have been many articles discussing this, especially in deep learning where large-scale matrix multiplications are common. This article will discuss two brief examples.
First, let's say you want to count the number of times a given integer appears in a column. Here are 2 possible methods.
"""计算DataFrame X 中 "column_1" 列中等于目标值 target 的元素个数。参数:X: DataFrame,包含要计算的列 "column_1"。target: int,目标值。返回值:int,等于目标值 target 的元素个数。"""# 使用循环计数def count_loop(X, target: int) -> int:return sum(x == target for x in X["column_1"])# 使用矢量化操作计数def count_vectorized(X, target: int) -> int:return (X["column_1"] == target).sum()
Now suppose you have a DataFrame with a date column and want to offset it by a given number of days. The calculation using vectorized operations is as follows:
def offset_loop(X, days: int) -> pd.DataFrame:d = pd.Timedelta(days=days)X["column_const"] = [x + d for x in X["column_10"]]return Xdef offset_vectorized(X, days: int) -> pd.DataFrame:X["column_const"] = X["column_10"] + pd.Timedelta(days=days)return X
Tip 2: Iteration
「for loop」
The first and most intuitive way to iterate is to use the Python for loop.
def loop(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:res = []i_remove_col = df.columns.get_loc(remove_col)i_words_to_remove_col = df.columns.get_loc(words_to_remove_col)for i_row in range(df.shape[0]):res.append(remove_words(df.iat[i_row, i_remove_col], df.iat[i_row, i_words_to_remove_col]))return result
「apply」
def apply(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df.apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1).tolist()
On each iteration of df.apply, the provided callable function obtains a Series whose index is df.columns and whose values are rows. This means pandas has to generate the sequence in every loop, which is expensive. To reduce costs, it's best to call apply on the subset of df that you know you will use, like this:
def apply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
「List combination itertuples」
Iteration using itertuples combined with lists will definitely work better. itertuples generates (named) tuples with row data.
def itertuples_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x[0], x[1])for x in df[[remove_col, words_to_remove_col]].itertuples(index=False, name=None)]
「List combination zip」
zip accepts an iterable object and generates a tuple, where the i-th tuple contains all i-th elements of the given iterable object in order.
def zip_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
「List combination to_dict」
def to_dict_only_used_columns(df: pd.DataFrame) -> list[str]:return [remove_words(row[remove_col], row[words_to_remove_col])for row in df[[remove_col, words_to_remove_col]].to_dict(orient="records")]
「Caching」
In addition to the iteration techniques we discussed, two other methods can help improve the performance of the code: caching and Parallelization. Caching is particularly useful if you call a pandas function multiple times with the same parameters. For example, if remove_words is applied to a dataset with many duplicate values, you can use functools.lru_cache to store the results of the function and avoid recalculating them each time. To use lru_cache, simply add the @lru_cache decorator to the declaration of remove_words and then apply the function to your dataset using your preferred iteration method. This can significantly improve the speed and efficiency of your code. Take the following code as an example:
@lru_cachedef remove_words(...):... # Same implementation as beforedef zip_only_used_cols_cached(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
Adding this decorator generates a function that "remembers" the output of previously encountered input, eliminating the need to run all the code again.
「Parallelization」
The final trump card is to use pandarallel to parallelize our function calls across multiple independent df blocks. The tool is easy to use: you just import and initialize it, then change all .applys to .parallel_applys.
from pandarallel import pandarallelpandarallel.initialize(nb_workers=min(os.cpu_count(), 12))def parapply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].parallel_apply(lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
The above is the detailed content of Two great tips to improve the efficiency of your Pandas code. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What to do if the blue screen code 0x0000001 occurs
Feb 23, 2024 am 08:09 AM
What to do if the blue screen code 0x0000001 occurs
Feb 23, 2024 am 08:09 AM
What to do with blue screen code 0x0000001? The blue screen error is a warning mechanism when there is a problem with the computer system or hardware. Code 0x0000001 usually indicates a hardware or driver failure. When users suddenly encounter a blue screen error while using their computer, they may feel panicked and at a loss. Fortunately, most blue screen errors can be troubleshooted and dealt with with a few simple steps. This article will introduce readers to some methods to solve the blue screen error code 0x0000001. First, when encountering a blue screen error, we can try to restart
 Solving common pandas installation problems: interpretation and solutions to installation errors
Feb 19, 2024 am 09:19 AM
Solving common pandas installation problems: interpretation and solutions to installation errors
Feb 19, 2024 am 09:19 AM
Pandas installation tutorial: Analysis of common installation errors and their solutions, specific code examples are required Introduction: Pandas is a powerful data analysis tool that is widely used in data cleaning, data processing, and data visualization, so it is highly respected in the field of data science . However, due to environment configuration and dependency issues, you may encounter some difficulties and errors when installing pandas. This article will provide you with a pandas installation tutorial and analyze some common installation errors and their solutions. 1. Install pandas
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Resolve code 0xc000007b error
Feb 18, 2024 pm 07:34 PM
Resolve code 0xc000007b error
Feb 18, 2024 pm 07:34 PM
Termination Code 0xc000007b While using your computer, you sometimes encounter various problems and error codes. Among them, the termination code is the most disturbing, especially the termination code 0xc000007b. This code indicates that an application cannot start properly, causing inconvenience to the user. First, let’s understand the meaning of termination code 0xc000007b. This code is a Windows operating system error code that usually occurs when a 32-bit application tries to run on a 64-bit operating system. It means it should
 GE universal remote codes program on any device
Mar 02, 2024 pm 01:58 PM
GE universal remote codes program on any device
Mar 02, 2024 pm 01:58 PM
If you need to program any device remotely, this article will help you. We will share the top GE universal remote codes for programming any device. What is a GE remote control? GEUniversalRemote is a remote control that can be used to control multiple devices such as smart TVs, LG, Vizio, Sony, Blu-ray, DVD, DVR, Roku, AppleTV, streaming media players and more. GEUniversal remote controls come in various models with different features and functions. GEUniversalRemote can control up to four devices. Top Universal Remote Codes to Program on Any Device GE remotes come with a set of codes that allow them to work with different devices. you may
 What does the blue screen code 0x000000d1 represent?
Feb 18, 2024 pm 01:35 PM
What does the blue screen code 0x000000d1 represent?
Feb 18, 2024 pm 01:35 PM
What does the 0x000000d1 blue screen code mean? In recent years, with the popularization of computers and the rapid development of the Internet, the stability and security issues of the operating system have become increasingly prominent. A common problem is blue screen errors, code 0x000000d1 is one of them. A blue screen error, or "Blue Screen of Death," is a condition that occurs when a computer experiences a severe system failure. When the system cannot recover from the error, the Windows operating system displays a blue screen with the error code on the screen. These error codes
 Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
In today's wave of rapid technological changes, Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL) are like bright stars, leading the new wave of information technology. These three words frequently appear in various cutting-edge discussions and practical applications, but for many explorers who are new to this field, their specific meanings and their internal connections may still be shrouded in mystery. So let's take a look at this picture first. It can be seen that there is a close correlation and progressive relationship between deep learning, machine learning and artificial intelligence. Deep learning is a specific field of machine learning, and machine learning
 Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Almost 20 years have passed since the concept of deep learning was proposed in 2006. Deep learning, as a revolution in the field of artificial intelligence, has spawned many influential algorithms. So, what do you think are the top 10 algorithms for deep learning? The following are the top algorithms for deep learning in my opinion. They all occupy an important position in terms of innovation, application value and influence. 1. Deep neural network (DNN) background: Deep neural network (DNN), also called multi-layer perceptron, is the most common deep learning algorithm. When it was first invented, it was questioned due to the computing power bottleneck. Until recent years, computing power, The breakthrough came with the explosion of data. DNN is a neural network model that contains multiple hidden layers. In this model, each layer passes input to the next layer and
