
 Backend Development
Python Tutorial
Data processing tool: efficient techniques for reading Excel files with pandas
Backend Development
Python Tutorial
Data processing tool: efficient techniques for reading Excel files with pandas
Data processing tool: efficient techniques for reading Excel files with pandas


With the increasing popularity of data processing, more and more people are paying attention to how to use data efficiently and make the data work for themselves. In daily data processing, Excel tables are undoubtedly the most common data format. However, when a large amount of data needs to be processed, manually operating Excel will obviously become very time-consuming and laborious. Therefore, this article will introduce an efficient data processing tool - pandas, and how to use this tool to quickly read Excel files and perform data processing.
1. Introduction to pandas
pandas is a powerful Python data analysis tool that provides a wide range of data reading, data processing and data analysis functions. The main data structures of pandas are DataFrame and Series, which can directly read files in common formats such as Excel and CSV and perform various data processing operations. Therefore, pandas is widely used in the field of data processing and is known as one of the mainstream tools for Python data analysis.
2. The basic method of reading Excel files in pandas
In pandas, the main function for reading Excel files is read_excel, which can read the data in the Excel table and convert it into a DataFrame object. The code is as follows:
import pandas as pd
data = pd.read_excel('test.xlsx', sheet_name='Sheet1')In the above code, test.xlsx is the name of the Excel file to be read, and Sheet1 is the name of the Sheet to be read. In this way, data is a DataFrame object, which contains the data in the Excel table.
3. Efficient techniques for reading Excel files with pandas
Although the basic reading method of pandas has saved a lot of time compared to manual operation of Excel, when processing large amounts of data, we can go further Optimize the process of reading Excel files.
1. Use skiprows and nrows parameters
We can use skiprows and nrows parameters to skip rows in the table and read a specified number of rows. For example, the following code can read the data from row 2 to row 1001 in the table:
data = pd.read_excel('test.xlsx', sheet_name='Sheet1', skiprows=1, nrows=1000)In this way, we can only read part of the data, thereby saving reading time and memory consumption.
2. Use the usecols parameter
If we only need certain columns of data in the table, we can use the usecols parameter to read only the specified columns. For example, the following code only reads columns A and B in the table:
data = pd.read_excel('test.xlsx', sheet_name='Sheet1', usecols=['A', 'B'])In this way, we can focus on the data columns that need to be processed and avoid reading unnecessary data.
3. Use chunksize and iterator parameters
When the Excel file read is large, we can use chunksize and iterator parameters to read data in blocks. For example, the following code can read 1000 rows of data at a time:
for i in pd.read_excel('test.xlsx', sheet_name='Sheet1', chunksize=1000):
# 处理代码In this way, we can read data block by block and process it in batches to improve data processing efficiency.
4. Complete Example
The following is a complete sample code for pandas to read an Excel file. This code can read all the data in Sheet1 in test.xlsx, and then calculate column A. and the sum of columns B, and output the result:
import pandas as pd
data = pd.read_excel('test.xlsx', sheet_name='Sheet1')
result = pd.DataFrame([{'sum_A': data['A'].sum(), 'sum_B': data['B'].sum()}])
result.to_excel('result.xlsx', index=False)In the above code, we first read Sheet1 of the entire test.xlsx file, and then used the sum function to calculate the sum of columns A and B, and combined the results Store in a DataFrame object. Finally, we write the results into a new Excel file result.xlsx, which contains only one row of data, with the first column being the sum of column A and the second column being the sum of column B.
Summary
Through the above introduction, we can see that using pandas to read Excel files can greatly improve the efficiency of data processing, and can be further optimized with the help of various advanced parameters and methods provided by pandas Data reading and processing process. Therefore, in the field of data analysis and processing, using pandas is a very efficient and practical tool.
The above is the detailed content of Data processing tool: efficient techniques for reading Excel files with pandas. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 What should I do if the frame line disappears when printing in Excel?
Mar 21, 2024 am 09:50 AM
What should I do if the frame line disappears when printing in Excel?
Mar 21, 2024 am 09:50 AM
If when opening a file that needs to be printed, we will find that the table frame line has disappeared for some reason in the print preview. When encountering such a situation, we must deal with it in time. If this also appears in your print file If you have questions like this, then join the editor to learn the following course: What should I do if the frame line disappears when printing a table in Excel? 1. Open a file that needs to be printed, as shown in the figure below. 2. Select all required content areas, as shown in the figure below. 3. Right-click the mouse and select the "Format Cells" option, as shown in the figure below. 4. Click the “Border” option at the top of the window, as shown in the figure below. 5. Select the thin solid line pattern in the line style on the left, as shown in the figure below. 6. Select "Outer Border"
 How to filter more than 3 keywords at the same time in excel
Mar 21, 2024 pm 03:16 PM
How to filter more than 3 keywords at the same time in excel
Mar 21, 2024 pm 03:16 PM
Excel is often used to process data in daily office work, and it is often necessary to use the "filter" function. When we choose to perform "filtering" in Excel, we can only filter up to two conditions for the same column. So, do you know how to filter more than 3 keywords at the same time in Excel? Next, let me demonstrate it to you. The first method is to gradually add the conditions to the filter. If you want to filter out three qualifying details at the same time, you first need to filter out one of them step by step. At the beginning, you can first filter out employees with the surname "Wang" based on the conditions. Then click [OK], and then check [Add current selection to filter] in the filter results. The steps are as follows. Similarly, perform filtering separately again
 How to change excel table compatibility mode to normal mode
Mar 20, 2024 pm 08:01 PM
How to change excel table compatibility mode to normal mode
Mar 20, 2024 pm 08:01 PM
In our daily work and study, we copy Excel files from others, open them to add content or re-edit them, and then save them. Sometimes a compatibility check dialog box will appear, which is very troublesome. I don’t know Excel software. , can it be changed to normal mode? So below, the editor will bring you detailed steps to solve this problem, let us learn together. Finally, be sure to remember to save it. 1. Open a worksheet and display an additional compatibility mode in the name of the worksheet, as shown in the figure. 2. In this worksheet, after modifying the content and saving it, the dialog box of the compatibility checker always pops up. It is very troublesome to see this page, as shown in the figure. 3. Click the Office button, click Save As, and then
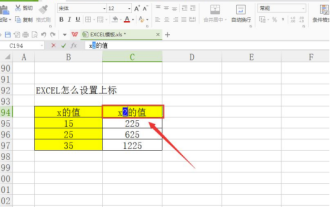 How to set superscript in excel
Mar 20, 2024 pm 04:30 PM
How to set superscript in excel
Mar 20, 2024 pm 04:30 PM
When processing data, sometimes we encounter data that contains various symbols such as multiples, temperatures, etc. Do you know how to set superscripts in Excel? When we use Excel to process data, if we do not set superscripts, it will make it more troublesome to enter a lot of our data. Today, the editor will bring you the specific setting method of excel superscript. 1. First, let us open the Microsoft Office Excel document on the desktop and select the text that needs to be modified into superscript, as shown in the figure. 2. Then, right-click and select the "Format Cells" option in the menu that appears after clicking, as shown in the figure. 3. Next, in the “Format Cells” dialog box that pops up automatically
 How to use the iif function in excel
Mar 20, 2024 pm 06:10 PM
How to use the iif function in excel
Mar 20, 2024 pm 06:10 PM
Most users use Excel to process table data. In fact, Excel also has a VBA program. Apart from experts, not many users have used this function. The iif function is often used when writing in VBA. It is actually the same as if The functions of the functions are similar. Let me introduce to you the usage of the iif function. There are iif functions in SQL statements and VBA code in Excel. The iif function is similar to the IF function in the excel worksheet. It performs true and false value judgment and returns different results based on the logically calculated true and false values. IF function usage is (condition, yes, no). IF statement and IIF function in VBA. The former IF statement is a control statement that can execute different statements according to conditions. The latter
 Where to set excel reading mode
Mar 21, 2024 am 08:40 AM
Where to set excel reading mode
Mar 21, 2024 am 08:40 AM
In the study of software, we are accustomed to using excel, not only because it is convenient, but also because it can meet a variety of formats needed in actual work, and excel is very flexible to use, and there is a mode that is convenient for reading. Today I brought For everyone: where to set the excel reading mode. 1. Turn on the computer, then open the Excel application and find the target data. 2. There are two ways to set the reading mode in Excel. The first one: In Excel, there are a large number of convenient processing methods distributed in the Excel layout. In the lower right corner of Excel, there is a shortcut to set the reading mode. Find the pattern of the cross mark and click it to enter the reading mode. There is a small three-dimensional mark on the right side of the cross mark.
 How to insert excel icons into PPT slides
Mar 26, 2024 pm 05:40 PM
How to insert excel icons into PPT slides
Mar 26, 2024 pm 05:40 PM
1. Open the PPT and turn the page to the page where you need to insert the excel icon. Click the Insert tab. 2. Click [Object]. 3. The following dialog box will pop up. 4. Click [Create from file] and click [Browse]. 5. Select the excel table to be inserted. 6. Click OK and the following page will pop up. 7. Check [Show as icon]. 8. Click OK.
 How to read excel data in html
Mar 27, 2024 pm 05:11 PM
How to read excel data in html
Mar 27, 2024 pm 05:11 PM
How to read excel data in html: 1. Use JavaScript library to read Excel data; 2. Use server-side programming language to read Excel data.
