
 Backend Development
Python Tutorial
pandas tutorial: Detailed explanation of how to use this library to read Excel files
Backend Development
Python Tutorial
pandas tutorial: Detailed explanation of how to use this library to read Excel files
pandas tutorial: Detailed explanation of how to use this library to read Excel files


Pandas Tutorial: Detailed explanation of how to use this library to read Excel files, specific code examples are required
Pandas is a commonly used data processing library with many powerful functions , especially very convenient in data processing. In the actual data processing process, it is often necessary to read Excel files. This article will explain in detail how to use the Pandas library to read Excel files and provide specific code examples.
- Import Pandas library
To use the Pandas library, you need to import the library first:
import pandas as pd
Among them, pd is the alias of the Pandas library, which is more convenient Use Pandas related methods appropriately.
- Reading Excel files
It is very convenient to use Pandas to read Excel files. It only requires one line of code to achieve:
data = pd.read_excel('file_name.xlsx')Among them, file_name. xlsx is the name of the Excel file, which is in the same directory as the Python script.
If the Excel file is not in the same directory, you need to specify the complete path, for example:
data = pd.read_excel('C:/Users/username/Desktop/file_name.xlsx')After reading the Excel file, you can view the data in the file in the following way:
Theprint(data.head())
head() method can view the first 5 rows of data in the Excel file. If you need to view more rows, you can change the number in brackets to the number of rows you need to view, for example:
print(data.head(10))
- Specify the Excel table that needs to be read
When When the Excel file contains multiple tables, you need to specify the table that needs to be read, for example:
data = pd.read_excel('file_name.xlsx', sheet_name='Sheet1')Among them, sheet_name is used to specify the name of the table that needs to be read. If you need to read multiple sheets, you can change sheet_name to a list, for example:
data = pd.read_excel('file_name.xlsx', sheet_name=['Sheet1', 'Sheet2'])In this way, the data of Sheet1 and Sheet2 can be read out at one time and stored in a dictionary.
- Read specific rows or columns
When there is a lot of data in the Excel table, we sometimes only need to read some of the rows or columns. You can use Pandas' loc and iloc method implementation:
loc method can read specified row or column data, the example is as follows:
data = pd.read_excel('file_name.xlsx') # 读取第 3 行数据 print(data.loc[2]) # 读取名称为 'column_name' 的列数据 print(data.loc[:, 'column_name']) # 读取第 3 行、名称为 'column_name' 的数据 print(data.loc[2, 'column_name'])Copy after loginiloc method can read Specified row or column data, but you need to use an integer position index. The example is as follows:
data = pd.read_excel('file_name.xlsx') # 读取第 3 行数据 print(data.iloc[2]) # 读取第 3 行、第 4 列数据 print(data.iloc[2, 3]) # 读取第 2-4 行、第 1-3 列的数据 print(data.iloc[1:4, 0:3])Copy after login
- Read the column names in the Excel file
In the process of reading Excel files, sometimes you need to get the column names in the Excel file. You can use the following method:
data = pd.read_excel('file_name.xlsx')
# 读取所有列名
print(data.columns.values)
# 读取第 3 列的列名
print(data.columns.values[2])Among them, columns.values is used to return the column name list. In Python, list indexes start from 0.
- Write data to Excel files
In addition to reading Excel files, Pandas also provides methods for writing data to Excel files. The example is as follows:
data = pd.DataFrame({'姓名': ['张三', '李四', '王五'], '年龄': [18, 22, 25]})
# 将数据写入名为 'MySheet' 的表格中
data.to_excel('file_name.xlsx', sheet_name='MySheet', index=False)Among them, the to_excel() method is used to write data to an Excel file. The first parameter is the Excel file name, and the second parameter is the name of the table to be written. Index=False means No need to write to index columns.
- Conclusion
This article mainly introduces how to use the Pandas library to read Excel files and provides specific code examples. Of course, Pandas has many other functions, which can be further understood in daily data processing.
The above is the detailed content of pandas tutorial: Detailed explanation of how to use this library to read Excel files. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1390
1390
 52
52

 What should I do if the frame line disappears when printing in Excel?
Mar 21, 2024 am 09:50 AM
What should I do if the frame line disappears when printing in Excel?
Mar 21, 2024 am 09:50 AM
If when opening a file that needs to be printed, we will find that the table frame line has disappeared for some reason in the print preview. When encountering such a situation, we must deal with it in time. If this also appears in your print file If you have questions like this, then join the editor to learn the following course: What should I do if the frame line disappears when printing a table in Excel? 1. Open a file that needs to be printed, as shown in the figure below. 2. Select all required content areas, as shown in the figure below. 3. Right-click the mouse and select the "Format Cells" option, as shown in the figure below. 4. Click the “Border” option at the top of the window, as shown in the figure below. 5. Select the thin solid line pattern in the line style on the left, as shown in the figure below. 6. Select "Outer Border"
 How to filter more than 3 keywords at the same time in excel
Mar 21, 2024 pm 03:16 PM
How to filter more than 3 keywords at the same time in excel
Mar 21, 2024 pm 03:16 PM
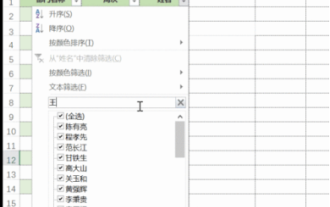
Excel is often used to process data in daily office work, and it is often necessary to use the "filter" function. When we choose to perform "filtering" in Excel, we can only filter up to two conditions for the same column. So, do you know how to filter more than 3 keywords at the same time in Excel? Next, let me demonstrate it to you. The first method is to gradually add the conditions to the filter. If you want to filter out three qualifying details at the same time, you first need to filter out one of them step by step. At the beginning, you can first filter out employees with the surname "Wang" based on the conditions. Then click [OK], and then check [Add current selection to filter] in the filter results. The steps are as follows. Similarly, perform filtering separately again
 How to change excel table compatibility mode to normal mode
Mar 20, 2024 pm 08:01 PM
How to change excel table compatibility mode to normal mode
Mar 20, 2024 pm 08:01 PM
In our daily work and study, we copy Excel files from others, open them to add content or re-edit them, and then save them. Sometimes a compatibility check dialog box will appear, which is very troublesome. I don’t know Excel software. , can it be changed to normal mode? So below, the editor will bring you detailed steps to solve this problem, let us learn together. Finally, be sure to remember to save it. 1. Open a worksheet and display an additional compatibility mode in the name of the worksheet, as shown in the figure. 2. In this worksheet, after modifying the content and saving it, the dialog box of the compatibility checker always pops up. It is very troublesome to see this page, as shown in the figure. 3. Click the Office button, click Save As, and then
 How to type subscript in excel
Mar 20, 2024 am 11:31 AM
How to type subscript in excel
Mar 20, 2024 am 11:31 AM
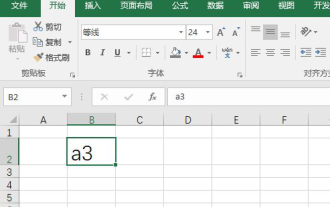
eWe often use Excel to make some data tables and the like. Sometimes when entering parameter values, we need to superscript or subscript a certain number. For example, mathematical formulas are often used. So how do you type the subscript in Excel? ?Let’s take a look at the detailed steps: 1. Superscript method: 1. First, enter a3 (3 is superscript) in Excel. 2. Select the number "3", right-click and select "Format Cells". 3. Click "Superscript" and then "OK". 4. Look, the effect is like this. 2. Subscript method: 1. Similar to the superscript setting method, enter "ln310" (3 is the subscript) in the cell, select the number "3", right-click and select "Format Cells". 2. Check "Subscript" and click "OK"
 How to use the iif function in excel
Mar 20, 2024 pm 06:10 PM
How to use the iif function in excel
Mar 20, 2024 pm 06:10 PM
Most users use Excel to process table data. In fact, Excel also has a VBA program. Apart from experts, not many users have used this function. The iif function is often used when writing in VBA. It is actually the same as if The functions of the functions are similar. Let me introduce to you the usage of the iif function. There are iif functions in SQL statements and VBA code in Excel. The iif function is similar to the IF function in the excel worksheet. It performs true and false value judgment and returns different results based on the logically calculated true and false values. IF function usage is (condition, yes, no). IF statement and IIF function in VBA. The former IF statement is a control statement that can execute different statements according to conditions. The latter
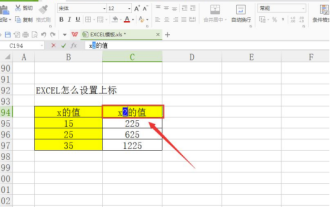 How to set superscript in excel
Mar 20, 2024 pm 04:30 PM
How to set superscript in excel
Mar 20, 2024 pm 04:30 PM
When processing data, sometimes we encounter data that contains various symbols such as multiples, temperatures, etc. Do you know how to set superscripts in Excel? When we use Excel to process data, if we do not set superscripts, it will make it more troublesome to enter a lot of our data. Today, the editor will bring you the specific setting method of excel superscript. 1. First, let us open the Microsoft Office Excel document on the desktop and select the text that needs to be modified into superscript, as shown in the figure. 2. Then, right-click and select the "Format Cells" option in the menu that appears after clicking, as shown in the figure. 3. Next, in the “Format Cells” dialog box that pops up automatically
 Where to set excel reading mode
Mar 21, 2024 am 08:40 AM
Where to set excel reading mode
Mar 21, 2024 am 08:40 AM
In the study of software, we are accustomed to using excel, not only because it is convenient, but also because it can meet a variety of formats needed in actual work, and excel is very flexible to use, and there is a mode that is convenient for reading. Today I brought For everyone: where to set the excel reading mode. 1. Turn on the computer, then open the Excel application and find the target data. 2. There are two ways to set the reading mode in Excel. The first one: In Excel, there are a large number of convenient processing methods distributed in the Excel layout. In the lower right corner of Excel, there is a shortcut to set the reading mode. Find the pattern of the cross mark and click it to enter the reading mode. There is a small three-dimensional mark on the right side of the cross mark.
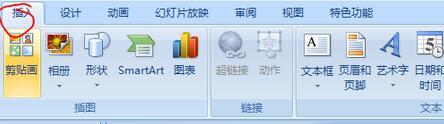 How to insert excel icons into PPT slides
Mar 26, 2024 pm 05:40 PM
How to insert excel icons into PPT slides
Mar 26, 2024 pm 05:40 PM
1. Open the PPT and turn the page to the page where you need to insert the excel icon. Click the Insert tab. 2. Click [Object]. 3. The following dialog box will pop up. 4. Click [Create from file] and click [Browse]. 5. Select the excel table to be inserted. 6. Click OK and the following page will pop up. 7. Check [Show as icon]. 8. Click OK.
