
 Technology peripherals
AI
AI video generation framework test competition: Pika, Gen-2, ModelScope, SEINE, who can win?
Technology peripherals
AI
AI video generation framework test competition: Pika, Gen-2, ModelScope, SEINE, who can win?
AI video generation framework test competition: Pika, Gen-2, ModelScope, SEINE, who can win?

AI video generation is one of the hottest fields recently. Various university laboratories, Internet giant AI Labs, and start-up companies have joined the AI video generation track. The release of video generation models such as Pika, Gen-2, Show-1, VideoCrafter, ModelScope, SEINE, LaVie, and VideoLDM is even more eye-catching. v⁽ⁱ⁾
Everyone must be curious about the following questions:
- Which video generation model is the best?
- What are the specialties of each model?
- What are the issues worthy of attention that need to be solved in the field of AI video generation?
To this end, we have launched VBench, a comprehensive "evaluation framework for video generation models", designed to provide users with information about the advantages, disadvantages and characteristics of various video models . Through VBench, users can understand the strengths and advantages of different video models.

- ##Paper: https://arxiv.org/abs /2311.17982
- Code: https://github.com/Vchitect/VBench ##Webpage: https://vchitect.github.io /VBench-project/
- Paper title: VBench: Comprehensive Benchmark Suite for Video Generative Models
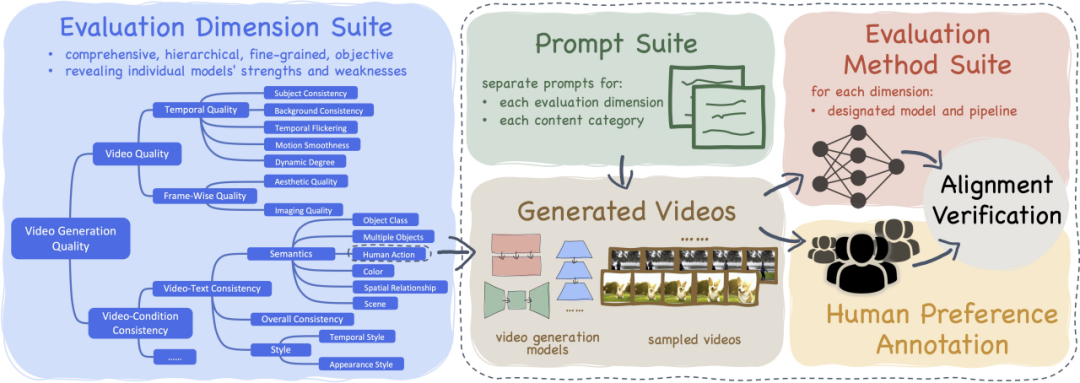
- VBench has open sourced the Prompt List system for Wensheng video generation and evaluation
- VBench’s evaluation plan for each dimension is aligned with human perception and evaluation
- VBench provides multi-perspective insights to facilitate future exploration of AI video generation
"VBench" - "Video Generation Model 》Comprehensive benchmark suite
 AI video generation model - evaluation results
AI video generation model - evaluation results
Open source AI Video generation model
#The performance of various open source AI video generation models on VBench is as follows.
#The performance of various open source AI video generation models on VBench. In the radar chart, we normalized the results for each dimension to be between 0.3 and 0.8 to visualize the comparison more clearly. 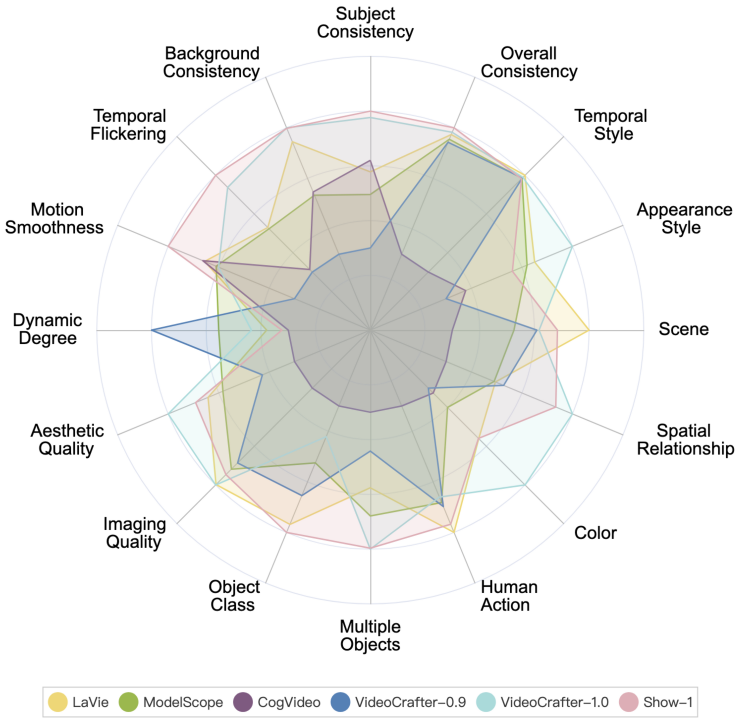
#The performance of various open source AI video generation models on VBench. 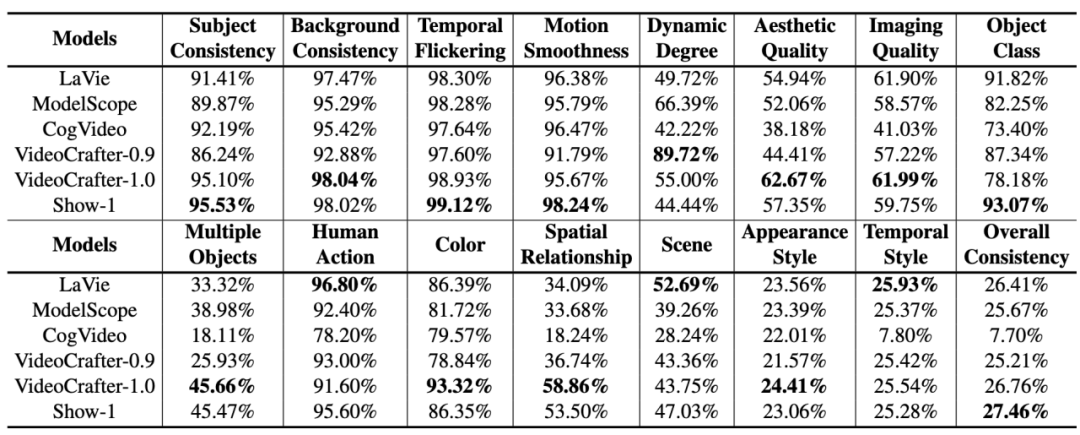
Among the above 6 models, it can be seen that VideoCrafter-1.0 and Show-1 have relative advantages in most dimensions.
Video generation model of startups
VBench currently provides two startups: Gen-2 and Pika Evaluation results of company models.
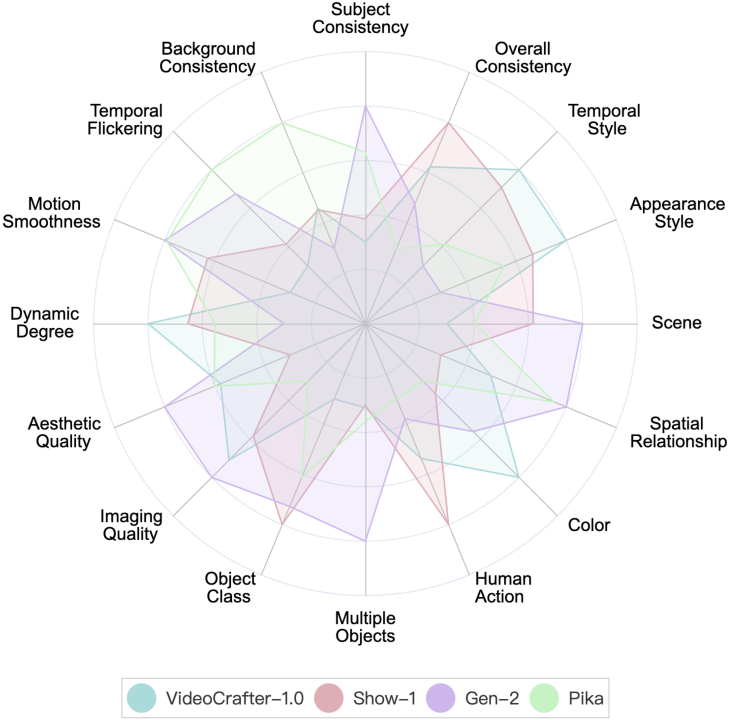 Performance of Gen-2 and Pika on VBench. In the radar chart, in order to visualize the comparison more clearly, we added VideoCrafter-1.0 and Show-1 as references, and normalized the evaluation results of each dimension to be between 0.3 and 0.8.
Performance of Gen-2 and Pika on VBench. In the radar chart, in order to visualize the comparison more clearly, we added VideoCrafter-1.0 and Show-1 as references, and normalized the evaluation results of each dimension to be between 0.3 and 0.8.
Производительность Gen-2 и Pika на VBench. Мы включили численные результаты VideoCrafter-1.0 и Show-1 в качестве ссылки.
Можно заметить, что Gen-2 и Pika имеют очевидные преимущества в качестве видео (качество видео), такие как согласованность времени (временная согласованность) и качество одного кадра (эстетическое качество и качество изображения). Качество), связанные с аспектами. С точки зрения семантической согласованности с подсказками пользовательского ввода (такими как действия человека и стиль внешнего вида), частичномерные модели с открытым исходным кодом будут лучше.
Модель генерации видео VS Модель генерации изображения
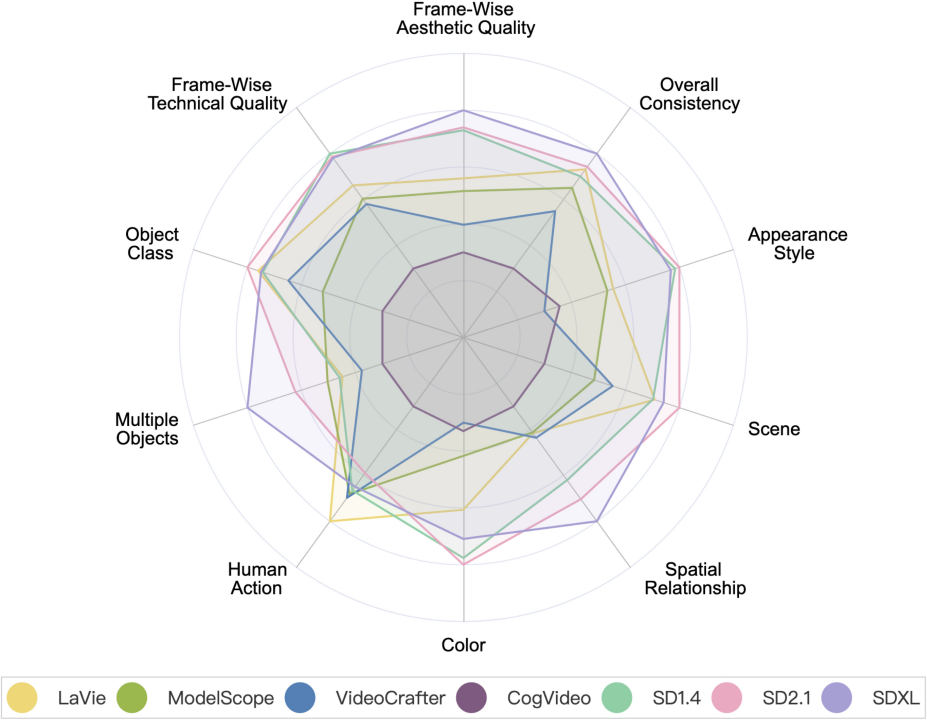
##Модель генерации видео VS Модель генерации изображения. Среди них SD1.4, SD2.1 и SDXL — модели генерации изображений.
Производительность модели генерации видео в 8 основных категориях сцен
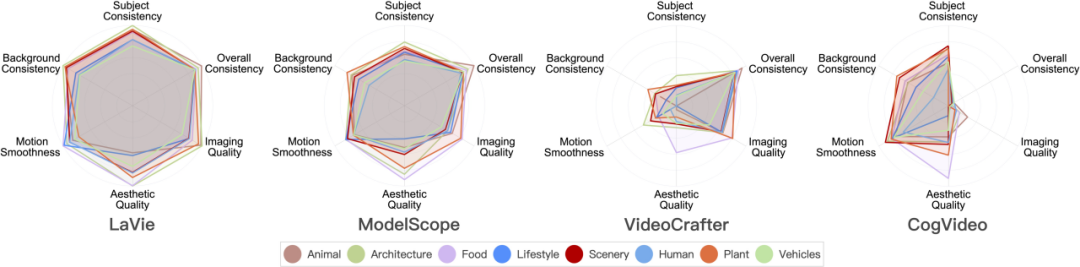



в 8 основных категориях сцен в 8 различных категориях результаты оценки.
##VBench теперь имеет открытый исходный код и может быть установлен одним щелчком мыши
В настоящее время VBench полностью открытый исходный код и поддерживает установку в один клик. Приглашаем всех желающих поиграть, протестировать интересующие вас модели и вместе способствовать развитию сообщества производителей видео.
##Адрес открытого исходного кода: https://github.com/Vchitect/VBench
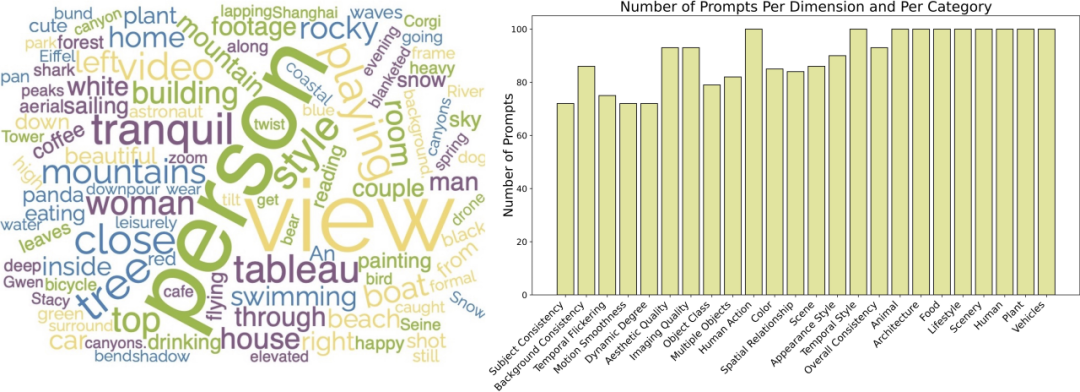
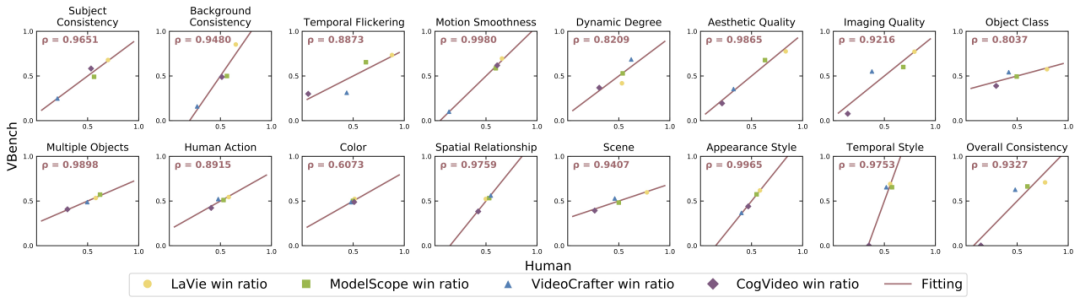
####################Мы также открыли исходный код серии подсказок Списки: https://github.com/Vchitect/VBench/tree/master/prompts, включая тесты для оценки в различных измерениях возможностей, а также тесты для оценки различного содержимого сценариев. #####################Облако слов слева показывает распределение высокочастотных слов в наших наборах подсказок, а на рисунке справа показана статистика количество подсказок в разных измерениях и категориях. ############Является ли VBench точным? ############Для каждого измерения мы рассчитали корреляцию между результатами оценки VBench и результатами ручной оценки, чтобы проверить соответствие нашего метода человеческому восприятию. На рисунке ниже горизонтальная ось представляет результаты ручной оценки в различных измерениях, а вертикальная ось показывает результаты автоматической оценки метода VBench. Видно, что наш метод полностью соответствует человеческому восприятию во всех измерениях. #####################VBench привносит мышление в создание видео с помощью искусственного интеллекта#############VBench может не только оценивать существующие модели, что еще более важно , также могут быть обнаружены различные проблемы, которые могут существовать в разных моделях, что дает ценную информацию для будущего развития генерации видео с помощью искусственного интеллекта. ###############«Временная непрерывность» и «динамический уровень видео»: не выбирайте один или другой, а улучшайте оба############ # ##Мы обнаружили, что существует определенное компромиссное соотношение между временной согласованностью (например, согласованностью объекта, согласованностью фона, плавностью движения) и амплитудой движения в видео (динамическая степень). Например, Show-1 и VideoCrafter-1.0 показали себя очень хорошо с точки зрения согласованности фона и плавности действий, но получили более низкую оценку с точки зрения динамики; это может быть связано с тем, что сгенерированные «недвижущиеся» изображения с большей вероятностью появляются «во времени». «Очень связно». VideoCrafter-0.9, с другой стороны, слабее по параметру, связанному с согласованностью времени, но имеет высокие показатели по динамической степени. ######Это показывает, что действительно трудно одновременно достичь «временной согласованности» и «более высокого динамического уровня»; в будущем нам следует сосредоточиться не только на улучшении одного аспекта, но также улучшить «временной уровень» связность» И «динамический уровень видео», это имеет смысл.
Оценивайте по содержимому сцены, чтобы изучить потенциал каждой модели
##Некоторые модели хорошо себя зарекомендовали в разных категориях. большие различия в производительности. Например, с точки зрения эстетического качества CogVideo хорошо работает в категории «Еда», но получает более низкие оценки в категории «Стиль жизни». Если данные обучения скорректированы, можно ли улучшить эстетическое качество CogVideo в категориях «LifeStyle», тем самым улучшив общее эстетическое качество видео модели?
Это также говорит нам о том, что при оценке моделей генерации видео нам необходимо учитывать производительность модели в различных категориях или темах, исследовать верхний предел модели в определенном измерении возможностей. , а затем выберите «Улучшить категорию сценария «сдерживание».
Категории со сложным движением: плохие пространственно-временные характеристики
#Категории с высокой пространственной сложностью, баллы по измерению эстетического качества являются относительно низкими. Например, категория «Стиль жизни» предъявляет относительно высокие требования к расположению сложных элементов в пространстве, а категория «Человек» предъявляет проблемы из-за генерации навесных конструкций.
Для категорий со сложным расчетом времени, таких как категория «Человек», которая обычно включает в себя сложные движения, и категория «Транспортное средство», которая часто движется быстрее, они получают одинаковые баллы по всем тестируемым параметрам. низкий. Это показывает, что текущая модель все еще имеет определенные недостатки в обработке временного моделирования.Ограничения временного моделирования могут привести к пространственному размытию и искажению, что приводит к неудовлетворительному качеству видео как во времени, так и в пространстве.
Сложно генерировать категории: мало пользы от увеличения объема данных
#Мы используем широко используемый набор видеоданных WebVid - Компания 10M провела статистику и обнаружила, что около 26% данных относятся к категории «Человек», что составляет самую высокую долю среди восьми посчитанных нами категорий. Однако по результатам оценки категория «Человек» оказалась одной из худших среди восьми категорий.
Это показывает, что для такой сложной категории, как «Человек», простое увеличение объема данных может не привести к значительному повышению производительности. Одним из потенциальных методов является управление изучением модели путем введения предшествующих знаний или средств контроля, связанных с «человеком», таких как скелеты и т. д.
Миллионы наборов данных: улучшение качества данных имеет приоритет над количеством данных
Хотя категория «Продовольствие» Занимает всего 11% от WebVid-10M, он почти всегда имеет высшую оценку эстетического качества в обзоре. Поэтому мы дополнительно проанализировали показатели эстетического качества различных категорий контента в наборе данных WebVid-10M и обнаружили, что категория «Еда» также имела самый высокий эстетический балл в WebVid-10M.
Это означает, что на основе миллионов данных фильтрация/улучшение качества данных более полезно, чем увеличение объема данных.
Возможность улучшить: Точно генерировать несколько объектов и взаимосвязь между объектами
Текущее создание видео Модель все еще не может догнать модель генерации изображений (особенно SDXL) с точки зрения «множественных объектов» и «пространственных отношений», что подчеркивает важность улучшения возможностей комбинирования. Так называемая способность комбинирования означает, может ли модель точно отображать несколько объектов при создании видео, а также пространственные и интерактивные отношения между ними.
Потенциальные решения этой проблемы могут включать в себя:
- Маркировка данных: создание набора видеоданных для предоставления четкого описания нескольких объектов. , а также описание пространственно-позиционных отношений и взаимодействий между объектами.
- Добавляйте промежуточные режимы/модули в процессе создания видео, чтобы помочь контролировать комбинацию и пространственное положение объектов.
- #Использование более качественного кодировщика текста (Text Encoder) также окажет большее влияние на способность комбинированной генерации модели.
- Кривая, чтобы спасти страну: передайте проблему «комбинации объектов», с которой T2V не может справиться, T2I, и сгенерируйте видео через T2I I2V. Этот подход также может быть эффективен для решения многих других задач генерации видео.
The above is the detailed content of AI video generation framework test competition: Pika, Gen-2, ModelScope, SEINE, who can win?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Detailed explanation of database ACID attributes ACID attributes are a set of rules to ensure the reliability and consistency of database transactions. They define how database systems handle transactions, and ensure data integrity and accuracy even in case of system crashes, power interruptions, or multiple users concurrent access. ACID Attribute Overview Atomicity: A transaction is regarded as an indivisible unit. Any part fails, the entire transaction is rolled back, and the database does not retain any changes. For example, if a bank transfer is deducted from one account but not increased to another, the entire operation is revoked. begintransaction; updateaccountssetbalance=balance-100wh
 Can mysql return json
Apr 08, 2025 pm 03:09 PM
Can mysql return json
Apr 08, 2025 pm 03:09 PM
MySQL can return JSON data. The JSON_EXTRACT function extracts field values. For complex queries, you can consider using the WHERE clause to filter JSON data, but pay attention to its performance impact. MySQL's support for JSON is constantly increasing, and it is recommended to pay attention to the latest version and features.
 Master SQL LIMIT clause: Control the number of rows in a query
Apr 08, 2025 pm 07:00 PM
Master SQL LIMIT clause: Control the number of rows in a query
Apr 08, 2025 pm 07:00 PM
SQLLIMIT clause: Control the number of rows in query results. The LIMIT clause in SQL is used to limit the number of rows returned by the query. This is very useful when processing large data sets, paginated displays and test data, and can effectively improve query efficiency. Basic syntax of syntax: SELECTcolumn1,column2,...FROMtable_nameLIMITnumber_of_rows;number_of_rows: Specify the number of rows returned. Syntax with offset: SELECTcolumn1,column2,...FROMtable_nameLIMIToffset,number_of_rows;offset: Skip
 How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
MySQL database performance optimization guide In resource-intensive applications, MySQL database plays a crucial role and is responsible for managing massive transactions. However, as the scale of application expands, database performance bottlenecks often become a constraint. This article will explore a series of effective MySQL performance optimization strategies to ensure that your application remains efficient and responsive under high loads. We will combine actual cases to explain in-depth key technologies such as indexing, query optimization, database design and caching. 1. Database architecture design and optimized database architecture is the cornerstone of MySQL performance optimization. Here are some core principles: Selecting the right data type and selecting the smallest data type that meets the needs can not only save storage space, but also improve data processing speed.
 Monitor MySQL and MariaDB Droplets with Prometheus MySQL Exporter
Apr 08, 2025 pm 02:42 PM
Monitor MySQL and MariaDB Droplets with Prometheus MySQL Exporter
Apr 08, 2025 pm 02:42 PM
Effective monitoring of MySQL and MariaDB databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Prometheus MySQL Exporter is a powerful tool that provides detailed insights into database metrics that are critical for proactive management and troubleshooting.
 The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The MySQL primary key cannot be empty because the primary key is a key attribute that uniquely identifies each row in the database. If the primary key can be empty, the record cannot be uniquely identifies, which will lead to data confusion. When using self-incremental integer columns or UUIDs as primary keys, you should consider factors such as efficiency and space occupancy and choose an appropriate solution.
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
It is impossible to view MongoDB password directly through Navicat because it is stored as hash values. How to retrieve lost passwords: 1. Reset passwords; 2. Check configuration files (may contain hash values); 3. Check codes (may hardcode passwords).
