
 Technology peripherals
AI
Using dimensionality reduction algorithms to achieve target detection: tips and steps
Technology peripherals
AI
Using dimensionality reduction algorithms to achieve target detection: tips and steps
Using dimensionality reduction algorithms to achieve target detection: tips and steps


Object detection is a key task in computer vision, where the goal is to identify and locate objects of interest in images or videos. Dimensionality reduction algorithm is a method commonly used for target detection by converting high-dimensional image data into low-dimensional feature representation. These features can effectively express the key information of the target, thereby supporting the accuracy and efficiency of target detection.
Step 1: Prepare the data set
First, prepare a labeled data set containing the original image and the corresponding region of interest . These regions can be manually annotated or generated using existing object detection algorithms. Each region needs to be annotated with bounding box and category information.
Step 2: Build the model
#In order to achieve the target detection task, it is usually necessary to build a deep learning model that can receive the original image as Inputs and outputs the bounding box coordinates of the region of interest. A common approach is to use regression models based on convolutional neural networks (CNN). By training this model, the mapping from images to bounding box coordinates can be learned to detect regions of interest. This dimensionality reduction algorithm can effectively reduce the dimension of input data and extract feature information related to target detection, thereby improving detection performance.
Step 3: Training the model
After preparing the data set and model, you can start training the model. The goal of training is to enable the model to predict the bounding box coordinates of the region of interest as accurately as possible. A common loss function is the mean square error (MSE), which measures the difference between the predicted bounding box coordinates and the true coordinates. Optimization algorithms such as gradient descent can be used to minimize the loss function, thereby updating the weight parameters of the model.
Step 4: Test the model
After the training is completed, you can use the test data set to evaluate the performance of the model. At test time, the model is applied to images in the test dataset and the predicted bounding box coordinates are output. The accuracy of the model is then evaluated by comparing the predicted bounding boxes with the ground-truth annotated bounding boxes. Commonly used evaluation indicators include accuracy, recall, mAP, etc.
Step 5: Apply the model
After passing the test, you can apply the trained model to the actual target detection task . For each input image, the model will output the bounding box coordinates of the area of interest to detect the target object. As needed, the output bounding box can be post-processed, such as non-maximum suppression (NMS), to improve the accuracy of the detection results.
Among them, step 2 of building the model is a critical step, which can be achieved using deep learning technologies such as convolutional neural networks. During the training and testing process, appropriate loss functions and evaluation metrics need to be used to measure the performance of the model. Finally, through practical application, accurate detection of target objects can be achieved.
Examples of using dimensionality reduction algorithms to achieve target detection
After introducing the specific methods and steps, let’s look at the implementation examples. The following is a simple example written in Python that illustrates how to implement object detection using a dimensionality reduction algorithm:
import numpy as np
import cv2
# 准备数据集
image_path = 'example.jpg'
annotation_path = 'example.json'
image = cv2.imread(image_path)
with open(annotation_path, 'r') as f:
annotations = np.array(json.load(f))
# 构建模型
model = cv2.dnn.readNetFromCaffe('deploy.prototxt', 'res101_iter_70000.caffemodel')
blob = cv2.dnn.blobFromImage(image, scalefactor=0.007843, size=(224, 224), mean=(104.0, 117.0, 123.0), swapRB=False, crop=False)
model.setInput(blob)
# 训练模型
output = model.forward()
indices = cv2.dnn.NMSBoxes(output, score_threshold=0.5, nms_threshold=0.4)
# 应用模型
for i in indices[0]:
box = output[i, :4] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
cv2.rectangle(image, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 255, 0), 2)
cv2.imshow('Output', image)
cv2.waitKey(0)This code example uses the OpenCV library to implement object detection. First, a labeled data set needs to be prepared, which contains original images and their corresponding regions of interest. In this example, we assume that we already have a JSON file containing annotation information. Then, build a deep learning model, here using the pre-trained ResNet101 model. Next, the model is applied to the input image to obtain the predicted bounding box coordinates. Finally, the predicted bounding boxes are applied to the image and the output is displayed.
The above is the detailed content of Using dimensionality reduction algorithms to achieve target detection: tips and steps. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 An in-depth analysis of the Gray Wolf Optimization Algorithm (GWO) and its strengths and weaknesses
Jan 19, 2024 pm 07:48 PM
An in-depth analysis of the Gray Wolf Optimization Algorithm (GWO) and its strengths and weaknesses
Jan 19, 2024 pm 07:48 PM
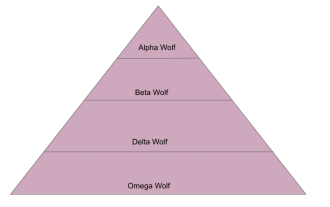
The Gray Wolf Optimization Algorithm (GWO) is a population-based metaheuristic algorithm that simulates the leadership hierarchy and hunting mechanism of gray wolves in nature. Gray Wolf Algorithm Inspiration 1. Gray wolves are considered to be apex predators and are at the top of the food chain. 2. Gray wolves like to live in groups (living in groups), with an average of 5-12 wolves in each pack. 3. Gray wolves have a very strict social dominance hierarchy, as shown below: Alpha wolf: Alpha wolf occupies a dominant position in the entire gray wolf group and has the right to command the entire gray wolf group. In the application of algorithms, Alpha Wolf is one of the best solutions, the optimal solution produced by the optimization algorithm. Beta wolf: Beta wolf reports to Alpha wolf regularly and helps Alpha wolf make the best decisions. In algorithm applications, Beta Wolf can
 The difference between single-stage and dual-stage target detection algorithms
Jan 23, 2024 pm 01:48 PM
The difference between single-stage and dual-stage target detection algorithms
Jan 23, 2024 pm 01:48 PM
Object detection is an important task in the field of computer vision, used to identify objects in images or videos and locate their locations. This task is usually divided into two categories of algorithms, single-stage and two-stage, which differ in terms of accuracy and robustness. Single-stage target detection algorithm The single-stage target detection algorithm converts target detection into a classification problem. Its advantage is that it is fast and can complete the detection in just one step. However, due to oversimplification, the accuracy is usually not as good as the two-stage object detection algorithm. Common single-stage target detection algorithms include YOLO, SSD and FasterR-CNN. These algorithms generally take the entire image as input and run a classifier to identify the target object. Unlike traditional two-stage target detection algorithms, they do not need to define areas in advance, but directly predict
 Explore the basic principles and implementation process of nested sampling algorithms
Jan 22, 2024 pm 09:51 PM
Explore the basic principles and implementation process of nested sampling algorithms
Jan 22, 2024 pm 09:51 PM
The nested sampling algorithm is an efficient Bayesian statistical inference algorithm used to calculate the integral or summation under complex probability distributions. It works by decomposing the parameter space into multiple hypercubes of equal volume, and gradually and iteratively "pushing out" one of the smallest volume hypercubes, and then filling the hypercube with random samples to better estimate the integral value of the probability distribution. . Through continuous iteration, the nested sampling algorithm can obtain high-precision integral values and boundaries of parameter space, which can be applied to statistical problems such as model comparison, parameter estimation, and model selection. The core idea of this algorithm is to transform complex integration problems into a series of simple integration problems, and approach the real integral value by gradually reducing the volume of the parameter space. Each iteration step randomly samples from the parameter space
 How to use AI technology to restore old photos (with examples and code analysis)
Jan 24, 2024 pm 09:57 PM
How to use AI technology to restore old photos (with examples and code analysis)
Jan 24, 2024 pm 09:57 PM
Old photo restoration is a method of using artificial intelligence technology to repair, enhance and improve old photos. Using computer vision and machine learning algorithms, the technology can automatically identify and repair damage and flaws in old photos, making them look clearer, more natural and more realistic. The technical principles of old photo restoration mainly include the following aspects: 1. Image denoising and enhancement. When restoring old photos, they need to be denoised and enhanced first. Image processing algorithms and filters, such as mean filtering, Gaussian filtering, bilateral filtering, etc., can be used to solve noise and color spots problems, thereby improving the quality of photos. 2. Image restoration and repair In old photos, there may be some defects and damage, such as scratches, cracks, fading, etc. These problems can be solved by image restoration and repair algorithms
 Application of AI technology in image super-resolution reconstruction
Jan 23, 2024 am 08:06 AM
Application of AI technology in image super-resolution reconstruction
Jan 23, 2024 am 08:06 AM
Super-resolution image reconstruction is the process of generating high-resolution images from low-resolution images using deep learning techniques, such as convolutional neural networks (CNN) and generative adversarial networks (GAN). The goal of this method is to improve the quality and detail of images by converting low-resolution images into high-resolution images. This technology has wide applications in many fields, such as medical imaging, surveillance cameras, satellite images, etc. Through super-resolution image reconstruction, we can obtain clearer and more detailed images, which helps to more accurately analyze and identify targets and features in images. Reconstruction methods Super-resolution image reconstruction methods can generally be divided into two categories: interpolation-based methods and deep learning-based methods. 1) Interpolation-based method Super-resolution image reconstruction based on interpolation
 Analyze the principles, models and composition of the Sparrow Search Algorithm (SSA)
Jan 19, 2024 pm 10:27 PM
Analyze the principles, models and composition of the Sparrow Search Algorithm (SSA)
Jan 19, 2024 pm 10:27 PM
The Sparrow Search Algorithm (SSA) is a meta-heuristic optimization algorithm based on the anti-predation and foraging behavior of sparrows. The foraging behavior of sparrows can be divided into two main types: producers and scavengers. Producers actively search for food, while scavengers compete for food from producers. Principle of Sparrow Search Algorithm (SSA) In Sparrow Search Algorithm (SSA), each sparrow pays close attention to the behavior of its neighbors. By employing different foraging strategies, individuals are able to efficiently use retained energy to pursue more food. Additionally, birds are more vulnerable to predators in their search space, so they need to find safer locations. Birds at the center of a colony can minimize their own range of danger by staying close to their neighbors. When a bird spots a predator, it makes an alarm call to
 Detailed explanation of Bellman Ford algorithm and implementation in Python
Jan 22, 2024 pm 07:39 PM
Detailed explanation of Bellman Ford algorithm and implementation in Python
Jan 22, 2024 pm 07:39 PM
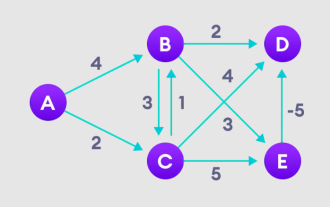
Bellman Ford algorithm can find the shortest path from the target node to other nodes in the weighted graph. This is very similar to the Dijkstra algorithm. The Bellman-Ford algorithm can handle graphs with negative weights and is relatively simple in terms of implementation. Detailed explanation of the principle of Bellman Ford algorithm The Bellman Ford algorithm iteratively finds new paths shorter than the overestimated paths by overestimating the path lengths from the starting vertex to all other vertices. Because we want to record the path distance of each node, we can store it in an array of size n, where n also represents the number of nodes. Example Figure 1. Select the starting node, assign it to all other vertices infinitely, and record the path value. 2. Visit each edge and perform relaxation operations to continuously update the shortest path. 3. We need
 Numerical optimization principles and analysis of the Whale Optimization Algorithm (WOA)
Jan 19, 2024 pm 07:27 PM
Numerical optimization principles and analysis of the Whale Optimization Algorithm (WOA)
Jan 19, 2024 pm 07:27 PM
The Whale Optimization Algorithm (WOA) is a nature-inspired metaheuristic optimization algorithm that simulates the hunting behavior of humpback whales and is used for the optimization of numerical problems. The Whale Optimization Algorithm (WOA) starts with a set of random solutions and optimizes based on a randomly selected search agent or the best solution so far through position updates of the search agent in each iteration. Whale Optimization Algorithm Inspiration The Whale Optimization Algorithm is inspired by the hunting behavior of humpback whales. Humpback whales prefer food found near the surface, such as krill and schools of fish. Therefore, humpback whales gather food together to form a bubble network by blowing bubbles in a bottom-up spiral when hunting. In an "upward spiral" maneuver, the humpback whale dives about 12m, then begins to form a spiral bubble around its prey and swims upward
