
 Backend Development
Python Tutorial
Detailed explanation of the principle of t-SNE algorithm and Python code implementation
Backend Development
Python Tutorial
Detailed explanation of the principle of t-SNE algorithm and Python code implementation
Detailed explanation of the principle of t-SNE algorithm and Python code implementation


T-distributed stochastic neighbor embedding (t-SNE) is an unsupervised machine learning algorithm for visualization. It uses nonlinear dimensionality reduction technology and based on the relationship between data points and features. Similarity attempts to minimize the difference between these conditional probabilities (or similarities) in high- and low-dimensional spaces to perfectly represent the data points in the low-dimensional space.
Therefore, t-SNE is good at embedding high-dimensional data in a two-dimensional or three-dimensional low-dimensional space for visualization. It should be noted that t-SNE uses a heavy-tailed distribution to calculate the similarity between two points in a low-dimensional space instead of a Gaussian distribution, which helps solve crowding and optimization problems. And outliers do not affect t-SNE.
t-SNE algorithm steps
#1. Find the pairwise similarity between adjacent points in high-dimensional space.
2. Based on the pairwise similarity of the points in the high-dimensional space, map each point in the high-dimensional space to a low-dimensional map.
3. Use gradient descent based on Kullback-Leibler divergence (KL divergence) to find a low-dimensional data representation that minimizes the mismatch between conditional probability distributions.
4. Use Student-t distribution to calculate the similarity between two points in low-dimensional space.
Python code to implement t-SNE on the MNIST data set
Import module
# Importing Necessary Modules. import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.manifold import TSNE from sklearn.preprocessing import StandardScaler
Read data
# Reading the data using pandas
df = pd.read_csv('mnist_train.csv')
# print first five rows of df
print(df.head(4))
# save the labels into a variable l.
l = df['label']
# Drop the label feature and store the pixel data in d.
d = df.drop("label", axis = 1)Data pre- Processing
# Data-preprocessing: Standardizing the data from sklearn.preprocessing import StandardScaler standardized_data = StandardScaler().fit_transform(data) print(standardized_data.shape)
Output
# TSNE
# Picking the top 1000 points as TSNE
# takes a lot of time for 15K points
data_1000 = standardized_data[0:1000, :]
labels_1000 = labels[0:1000]
model = TSNE(n_components = 2, random_state = 0)
# configuring the parameters
# the number of components = 2
# default perplexity = 30
# default learning rate = 200
# default Maximum number of iterations
# for the optimization = 1000
tsne_data = model.fit_transform(data_1000)
# creating a new data frame which
# help us in plotting the result data
tsne_data = np.vstack((tsne_data.T, labels_1000)).T
tsne_df = pd.DataFrame(data = tsne_data,
columns =("Dim_1", "Dim_2", "label"))
# Plotting the result of tsne
sn.FacetGrid(tsne_df, hue ="label", size = 6).map(
plt.scatter, 'Dim_1', 'Dim_2').add_legend()
plt.show()The above is the detailed content of Detailed explanation of the principle of t-SNE algorithm and Python code implementation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



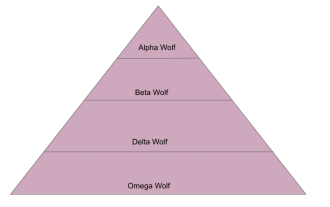 An in-depth analysis of the Gray Wolf Optimization Algorithm (GWO) and its strengths and weaknesses
Jan 19, 2024 pm 07:48 PM
An in-depth analysis of the Gray Wolf Optimization Algorithm (GWO) and its strengths and weaknesses
Jan 19, 2024 pm 07:48 PM
The Gray Wolf Optimization Algorithm (GWO) is a population-based metaheuristic algorithm that simulates the leadership hierarchy and hunting mechanism of gray wolves in nature. Gray Wolf Algorithm Inspiration 1. Gray wolves are considered to be apex predators and are at the top of the food chain. 2. Gray wolves like to live in groups (living in groups), with an average of 5-12 wolves in each pack. 3. Gray wolves have a very strict social dominance hierarchy, as shown below: Alpha wolf: Alpha wolf occupies a dominant position in the entire gray wolf group and has the right to command the entire gray wolf group. In the application of algorithms, Alpha Wolf is one of the best solutions, the optimal solution produced by the optimization algorithm. Beta wolf: Beta wolf reports to Alpha wolf regularly and helps Alpha wolf make the best decisions. In algorithm applications, Beta Wolf can
 Explore the basic principles and implementation process of nested sampling algorithms
Jan 22, 2024 pm 09:51 PM
Explore the basic principles and implementation process of nested sampling algorithms
Jan 22, 2024 pm 09:51 PM
The nested sampling algorithm is an efficient Bayesian statistical inference algorithm used to calculate the integral or summation under complex probability distributions. It works by decomposing the parameter space into multiple hypercubes of equal volume, and gradually and iteratively "pushing out" one of the smallest volume hypercubes, and then filling the hypercube with random samples to better estimate the integral value of the probability distribution. . Through continuous iteration, the nested sampling algorithm can obtain high-precision integral values and boundaries of parameter space, which can be applied to statistical problems such as model comparison, parameter estimation, and model selection. The core idea of this algorithm is to transform complex integration problems into a series of simple integration problems, and approach the real integral value by gradually reducing the volume of the parameter space. Each iteration step randomly samples from the parameter space
 Analyze the principles, models and composition of the Sparrow Search Algorithm (SSA)
Jan 19, 2024 pm 10:27 PM
Analyze the principles, models and composition of the Sparrow Search Algorithm (SSA)
Jan 19, 2024 pm 10:27 PM
The Sparrow Search Algorithm (SSA) is a meta-heuristic optimization algorithm based on the anti-predation and foraging behavior of sparrows. The foraging behavior of sparrows can be divided into two main types: producers and scavengers. Producers actively search for food, while scavengers compete for food from producers. Principle of Sparrow Search Algorithm (SSA) In Sparrow Search Algorithm (SSA), each sparrow pays close attention to the behavior of its neighbors. By employing different foraging strategies, individuals are able to efficiently use retained energy to pursue more food. Additionally, birds are more vulnerable to predators in their search space, so they need to find safer locations. Birds at the center of a colony can minimize their own range of danger by staying close to their neighbors. When a bird spots a predator, it makes an alarm call to
 What is the role of information gain in the id3 algorithm?
Jan 23, 2024 pm 11:27 PM
What is the role of information gain in the id3 algorithm?
Jan 23, 2024 pm 11:27 PM
The ID3 algorithm is one of the basic algorithms in decision tree learning. It selects the best split point by calculating the information gain of each feature to generate a decision tree. Information gain is an important concept in the ID3 algorithm, which is used to measure the contribution of features to the classification task. This article will introduce in detail the concept, calculation method and application of information gain in the ID3 algorithm. 1. The concept of information entropy Information entropy is a concept in information theory, which measures the uncertainty of random variables. For a discrete random variable number, and p(x_i) represents the probability that the random variable X takes the value x_i. letter
 Introduction to Wu-Manber algorithm and Python implementation instructions
Jan 23, 2024 pm 07:03 PM
Introduction to Wu-Manber algorithm and Python implementation instructions
Jan 23, 2024 pm 07:03 PM
The Wu-Manber algorithm is a string matching algorithm used to search strings efficiently. It is a hybrid algorithm that combines the advantages of Boyer-Moore and Knuth-Morris-Pratt algorithms to provide fast and accurate pattern matching. Wu-Manber algorithm step 1. Create a hash table that maps each possible substring of the pattern to the pattern position where that substring occurs. 2. This hash table is used to quickly identify potential starting locations of patterns in text. 3. Iterate through the text and compare each character to the corresponding character in the pattern. 4. If the characters match, you can move to the next character and continue the comparison. 5. If the characters do not match, you can use a hash table to determine the next potential character in the pattern.
 Numerical optimization principles and analysis of the Whale Optimization Algorithm (WOA)
Jan 19, 2024 pm 07:27 PM
Numerical optimization principles and analysis of the Whale Optimization Algorithm (WOA)
Jan 19, 2024 pm 07:27 PM
The Whale Optimization Algorithm (WOA) is a nature-inspired metaheuristic optimization algorithm that simulates the hunting behavior of humpback whales and is used for the optimization of numerical problems. The Whale Optimization Algorithm (WOA) starts with a set of random solutions and optimizes based on a randomly selected search agent or the best solution so far through position updates of the search agent in each iteration. Whale Optimization Algorithm Inspiration The Whale Optimization Algorithm is inspired by the hunting behavior of humpback whales. Humpback whales prefer food found near the surface, such as krill and schools of fish. Therefore, humpback whales gather food together to form a bubble network by blowing bubbles in a bottom-up spiral when hunting. In an "upward spiral" maneuver, the humpback whale dives about 12m, then begins to form a spiral bubble around its prey and swims upward
 Scale Invariant Features (SIFT) algorithm
Jan 22, 2024 pm 05:09 PM
Scale Invariant Features (SIFT) algorithm
Jan 22, 2024 pm 05:09 PM
The Scale Invariant Feature Transform (SIFT) algorithm is a feature extraction algorithm used in the fields of image processing and computer vision. This algorithm was proposed in 1999 to improve object recognition and matching performance in computer vision systems. The SIFT algorithm is robust and accurate and is widely used in image recognition, three-dimensional reconstruction, target detection, video tracking and other fields. It achieves scale invariance by detecting key points in multiple scale spaces and extracting local feature descriptors around the key points. The main steps of the SIFT algorithm include scale space construction, key point detection, key point positioning, direction assignment and feature descriptor generation. Through these steps, the SIFT algorithm can extract robust and unique features, thereby achieving efficient image processing.
 Explore the concepts of Bayesian methods and Bayesian networks in depth
Jan 24, 2024 pm 01:06 PM
Explore the concepts of Bayesian methods and Bayesian networks in depth
Jan 24, 2024 pm 01:06 PM
The concept of Bayesian method Bayesian method is a statistical inference theorem mainly used in the field of machine learning. It performs tasks such as parameter estimation, model selection, model averaging and prediction by combining prior knowledge with observation data. Bayesian methods are unique in their ability to flexibly handle uncertainty and improve the learning process by continuously updating prior knowledge. This method is particularly effective when dealing with small sample problems and complex models, and can provide more accurate and robust inference results. Bayesian methods are based on Bayes' theorem, which states that the probability of a hypothesis given some evidence is equal to the probability of the evidence multiplied by the prior probability. This can be written as: P(H|E)=P(E|H)P(H) where P(H|E) is the posterior probability of hypothesis H given evidence E, P(
