

The random forest algorithm is an ensemble technique capable of performing regression and classification tasks using multiple decision trees and a technique called Bootstrap and aggregation. The basic idea behind this is to combine multiple decision trees to determine the final output, rather than relying on a single decision tree.
Random forest produces a large number of classification trees. Place the input vector under each tree in the forest to classify new objects based on the input vector. Each tree is assigned a class, which we can call a "vote", and the class with the highest number of votes is ultimately chosen.
The following stages will help us understand how the random forest algorithm works.
Step 1: First select a random sample from the data set.
Step 2: For each sample, the algorithm will create a decision tree. Then the prediction results of each decision tree will be obtained.
Step 3: Each expected outcome in this step will be voted on.
Step 4: Finally, select the prediction result with the most votes as the final prediction result.
The following are the main characteristics of the random forest algorithm:
Random forest has multiple decision trees as the basic learning model. We randomly perform row sampling and feature sampling from the dataset to form a sample dataset for each model. This part is called the bootstrap.
Step 1: Import the required libraries.
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Step 2: Import and print the dataset
ata=pd.read_csv('Salaries.csv') print(data)
Step 3: Select all rows and column 1 from the dataset as x, select all rows and column 2 as y
x=df.iloc[:,:-1]#":" means all rows will be selected, ":-1" means the last column will be ignored
y=df.iloc[: ,-1:]#":" means it will select all rows, "-1:" means it will ignore all columns except the last one
#The "iloc()" function enables us to select A specific cell of a data set, that is, it helps us select the value belonging to a specific row or column from a set of values in the data frame or data set.
Step 4: Fit a random forest regressor to the data set
from sklearn.ensemble import RandomForestRegressor regressor=RandomForestRegressor(n_estimators=100,random_state=0) regressor.fit(x,y)
Step 5: Predict new results
Y_pred=regressor.predict(np.array([6.5]).reshape(1,1))
Step 6: Visualize the results
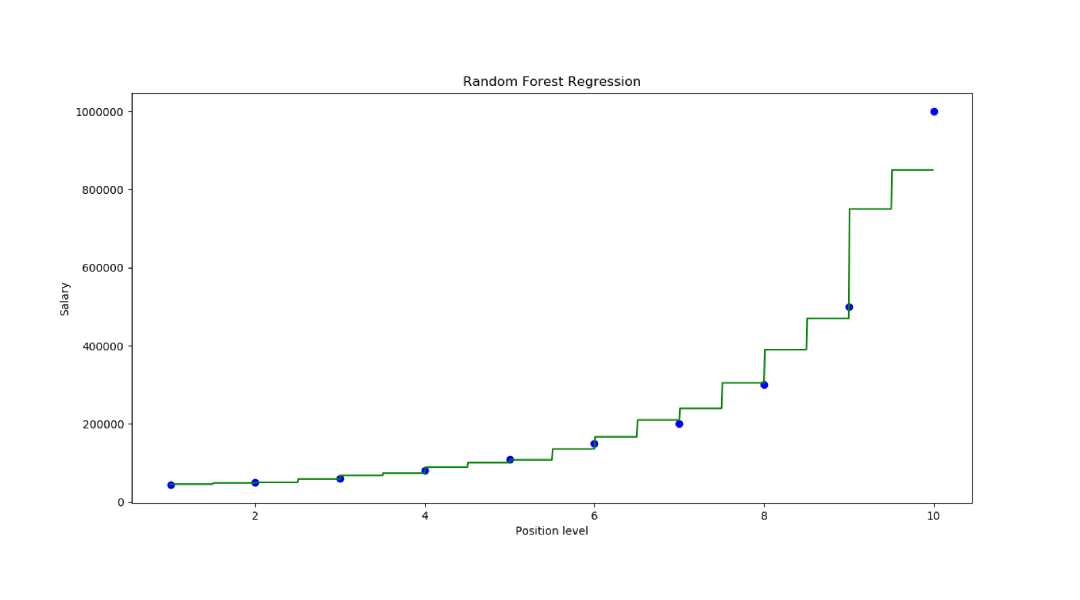
X_grid=np.arrange(min(x),max(x),0.01) X_grid=X_grid.reshape((len(X_grid),1)) plt.scatter(x,y,color='blue') plt.plot(X_grid,regressor.predict(X_grid), color='green') plt.title('Random Forest Regression') plt.xlabel('Position level') plt.ylabel('Salary') plt.show()
The above is the detailed content of Python examples of random forest algorithm principles and practical applications (with complete code). For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



