
 Technology peripherals
AI
TimePillars: Where can the pure LiDAR 3D detection route be extended? Direct coverage of 200m!
Technology peripherals
AI
TimePillars: Where can the pure LiDAR 3D detection route be extended? Direct coverage of 200m!
TimePillars: Where can the pure LiDAR 3D detection route be extended? Direct coverage of 200m!

Based on LiDAR point cloud point 3D Object Detection is a very classic problem. Both academia and industry have proposed various models to improve accuracy, speed and robustness. However, due to the complex outdoor environment, the performance of Object Detection for outdoor point clouds is not very good. Lidar point clouds are sparse in nature. How to solve this problem in a targeted manner? The paper gives its own answer: extract information based on the aggregation of time series information.
Written before

This paper mainly discusses an important challenge facing autonomous driving: how to accurately establish the surrounding environment three-dimensional representation. This is critical to ensuring the reliability and safety of autonomous vehicles. In particular, autonomous vehicles need to be able to recognize surrounding objects, such as vehicles and pedestrians, and accurately determine their location, size, and orientation. Typically, people use deep neural networks to process LiDAR data to accomplish this task.
Current research mainly focuses on single-frame methods, which use data from one sensor scan at a time. This method performs well on classic benchmarks, detecting objects at distances up to 75 meters. However, the sparseness of lidar point clouds is particularly evident at long ranges. Therefore, the researchers believe that relying solely on a single scan for long-distance detection is not enough, for example, up to a distance of 200 meters. Therefore, future research needs to focus on addressing this challenge.
To solve this problem, one method is to use point cloud aggregation, which is to concatenate a series of lidar scan data to obtain a denser input. However, this approach is computationally expensive and does not take full advantage of aggregation within the network. To reduce computational costs and better utilize information, consider using recursive methods. Recursive methods accumulate information over time and produce more accurate outputs by iteratively fusing the current input with previous aggregated results. This method can not only improve calculation efficiency, but also effectively utilize historical information to improve prediction accuracy. Recursive methods have wide applications in point cloud aggregation problems and have achieved satisfactory results.
The article also mentioned that in order to increase the detection range, some advanced operations can be adopted, such as sparse convolution, attention module and 3D convolution. However, these operations usually ignore the compatibility issues of the target hardware. When deploying and training neural networks, the hardware used often differs significantly in supported operations and latency. For example, target hardware such as Nvidia Orin DLA often does not support operations such as sparse convolution or attention. Additionally, using layers such as 3D convolutions is often not feasible due to real-time latency requirements. This emphasizes the need to use simple operations such as 2D convolution.
The paper proposes a new temporal recursive model, TimePillars, which respects the set of operations supported on common target hardware, relies on 2D convolution, is based on point-pillar (Pillar) input representation and a convolution recursion unit. Self-motion compensation is applied to the hidden state of the recurrent unit with the help of a single convolution and auxiliary learning. The use of auxiliary tasks to ensure the correctness of this manipulation has been shown to be appropriate through ablation studies. The paper also investigates the optimal placement of the recursive module in the pipeline and clearly shows that placing it between the backbone of the network and the detection head results in the best performance. On the newly released Zenseact Open Dataset (ZOD), the paper demonstrates the effectiveness of the TimePillars method. Compared to single-frame and multi-frame point-and-pillar baselines, TimePillars achieves significant evaluation performance improvements, especially at long-range (up to 200 meters) detection in the important cyclist and pedestrian categories. Finally, TimePillars have significantly lower latency than multi-frame point pillars, making them suitable for real-time systems.
This paper proposes a new temporal recursive model called TimePillars to solve the 3D lidar object detection task and considers the set of operations supported by common target hardware. Experiments have proven that TimePillars achieves significantly better performance than single-frame and multi-frame point-pillar baselines in long-distance detection. In addition, the paper also benchmarks a 3D lidar object detection model on the Zenseact open dataset for the first time. However, limitations of the paper are that it only focuses on lidar data, does not consider other sensor inputs, and bases its approach on a single state-of-the-art baseline. Nonetheless, the authors believe that their framework is general, i.e., future improvements to the baseline will translate into overall performance improvements.
Detailed explanation of TimePillars
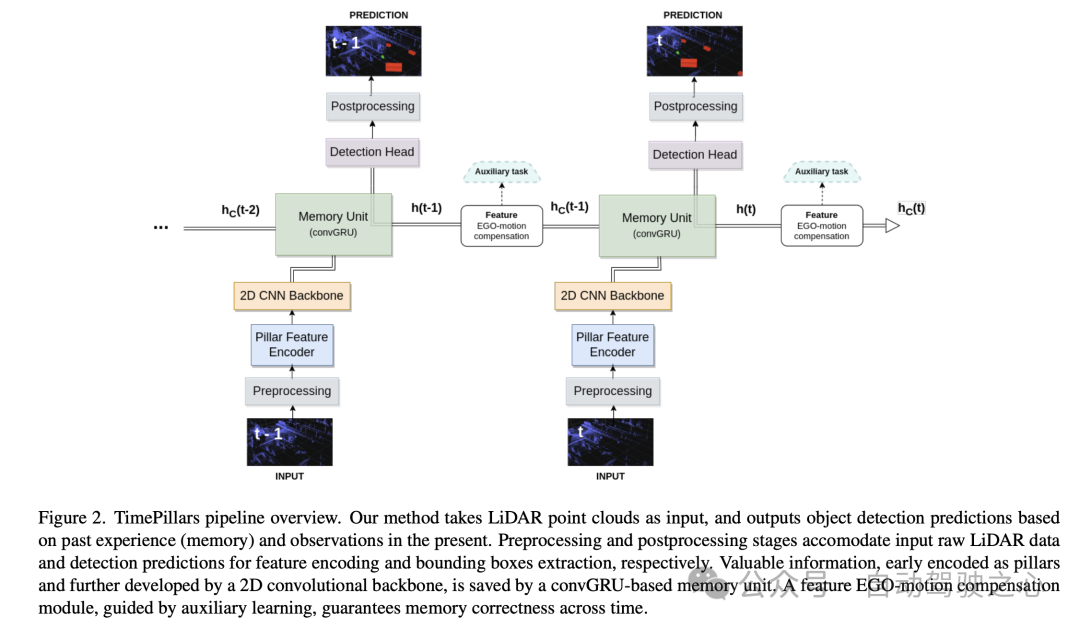
Input preprocessing
In the "Input Preprocessing" section of this paper, the author uses a technique called "pillarization" to process the input points Cloud data. Different from conventional voxelization, this method segments the point cloud into vertical columnar structures, segmenting only in the horizontal direction (x and y axes) while maintaining a fixed height in the vertical direction (z axis). The advantage of this processing method is that it can maintain the consistency of the network input size and can use 2D convolution for efficient processing. In this way, point cloud data can be processed efficiently, providing more accurate and reliable input for subsequent tasks.
However, one problem with Pillarisation is that it produces many empty columns, resulting in very sparse data. To solve this problem, the paper proposes the use of dynamic voxelization technology. This technique avoids the need to have a predefined number of points for each column, thereby eliminating the need for truncation or filling operations on each column. Instead, the entire point cloud data is processed as a whole to match the required total number of points, here set to 200,000 points. The benefit of this preprocessing method is that it minimizes the loss of information and makes the generated data representation more stable and consistent.
Model architecture
Then for the Model architecture, the author introduced in detail a pillar feature encoder (Pillar Feature Encoder), 2D convolutional neural network (CNN) backbone and a neural network architecture composed of detection heads.
- Pillar Feature Encoder: This part maps the preprocessed input tensor into a Bird's Eye View (BEV) pseudo image. After using dynamic voxelization, the simplified PointNet is adjusted accordingly. The input is processed by 1D convolution, batch normalization and ReLU activation function to obtain a tensor with shape , where represents the number of channels. Before the final scatter max layer, max pooling is applied to the channels, forming a latent space of shape . Since the initial tensor is encoded as , which becomes after the previous layer, the max pooling operation is removed.
- Backbone: Using the 2D CNN backbone architecture proposed in the original columnar paper due to its superior depth efficiency. The latent space is reduced using three downsampling blocks (Conv2D-BN-ReLU) and restored using three upsampling blocks and transposed convolution. The output shape is .
- Memory Unit: Model the memory of the system as a recurrent neural network (RNN), specifically using convolutional GRU (convGRU), which is the convolutional version of Gated Recurrent Unit. The advantage of convolutional GRU is that it avoids the vanishing gradient problem and improves efficiency while maintaining spatial data characteristics. Compared to other options such as LSTM, GRU has fewer trainable parameters due to its smaller number of gates and can be considered a memory regularization technique (reducing the complexity of the hidden states). By merging operations of similar nature, the number of required convolutional layers is reduced, making the unit more efficient.
- Detection Head: A simple modification to SSD (Single Shot MultiBox Detector). The core concept of SSD is retained, that is, single pass without region proposal, but the use of anchor boxes is eliminated. Directly outputting predictions for each cell in the grid, although losing the cell multi-object detection capability, avoids tedious and often imprecise anchor box parameter adjustments and simplifies the inference process. The linear layer handles the respective outputs of classification and localization (position, size, and angle) regression. Only the size uses an activation function (ReLU) to prevent taking negative values. In addition, unlike related literature, this paper avoids the problem of direct angle regression by independently predicting the sine and cosine components of the vehicle's driving direction and extracting angles from them.
Feature Ego-Motion Compensation
In this part of the paper, the author discusses how to process the hidden state features output by the convolutional GRU, which are previously Represented by the coordinate system of a frame. If stored directly and used to calculate the next prediction, a spatial mismatch will occur due to ego-motion.
In order to perform the conversion, different techniques can be applied. Ideally, the corrected data would be fed into the network rather than transformed within the network. However, this is not the method proposed in the paper, as it requires resetting the hidden states at each step in the inference process, transforming the previous point clouds, and propagating them throughout the network. Not only is this inefficient, it defeats the purpose of using RNNs. Therefore, in a loop context, compensation needs to be done at the feature level. This makes the hypothetical solution more efficient, but also makes the problem more complex. Traditional interpolation methods can be used to obtain features in transformed coordinate systems.
In contrast, the paper, inspired by the work of Chen et al., proposes to use convolution operations and auxiliary tasks to perform transformations. Considering the limited details of the aforementioned work, the paper proposes a customized solution to this problem.
The approach taken by the paper is to provide the network with the information needed to perform feature transformation through an additional convolutional layer. The relative transformation matrix between two consecutive frames is first calculated, i.e. the operations required to successfully transform features. Then, extract the 2D information (rotation and translation part) from it:
This simplification avoids the main matrix constants and works in the 2D (pseudo-image) domain, reducing 16 values to 6. The matrix is then flattened and expanded to match the shape of the hidden features to be compensated . The first dimension represents the number of frames that need to be converted. This representation makes it suitable for concatenating each potential pillar in the channel dimension of the hidden feature.
Finally, the hidden state features are fed into a 2D convolutional layer, which is adapted to the transformation process. A key aspect to note is that performing a convolution does not guarantee that the transformation will take place. Channel concatenation simply provides the network with additional information about how the transformation might be performed. In this case, the use of assisted learning is appropriate. During training, an additional learning objective (coordinate transformation) is added in parallel with the main objective (object detection). An auxiliary task is designed whose purpose is to guide the network through the transformation process under supervision to ensure the correctness of the compensation. The auxiliary task is limited to the training process. Once the network learns to transform features correctly, it loses its applicability. Therefore, this task is not considered during inference. In the next section further experiments will be conducted to compare the impact.
Experiment
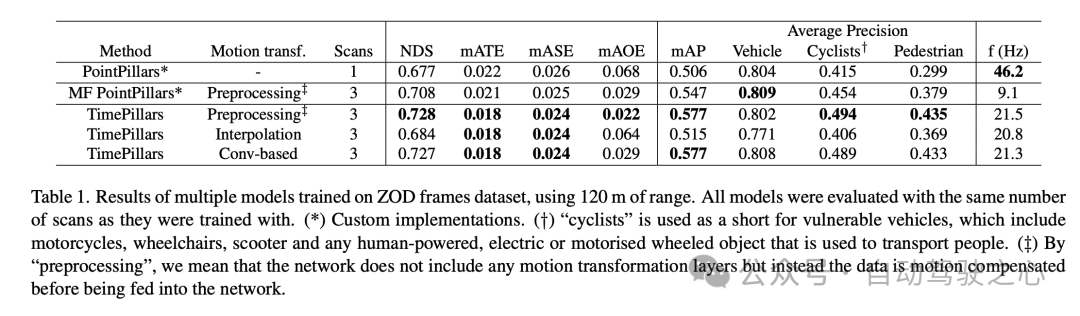
The experimental results show that the TimePillars model performs well when processing the Zenseact Open Dataset (ZOD) frame data set, especially This is when dealing with ranges up to 120 meters. These results highlight the performance differences of TimePillars under different motion transformation methods and compare with other methods.
After comparing the benchmark model PointPillars and multi-frame (MF) PointPillars, it can be seen that TimePillars has achieved significant improvements in multiple key performance indicators. Especially on NuScenes Detection Score (NDS), TimePillars demonstrates a higher overall score, reflecting its advantages in detection performance and positioning accuracy. In addition, TimePillars also achieved lower values in average conversion error (mATE), average scale error (mASE) and average orientation error (mAOE), indicating that it is more precise in positioning accuracy and orientation estimation. Of particular note is that the different implementations of TimePillars in terms of motion conversion have a significant impact on performance. When using convolution-based motion transformation (Conv-based), TimePillars performs particularly well on NDS, mATE, mASE, and mAOE, proving the effectiveness of this method in motion compensation and improving detection accuracy. In contrast, TimePillars using the interpolation method also outperforms the baseline model, but is inferior to the convolution method in some indicators. The average precision (mAP) results show that TimePillars performs well in the detection of vehicles, cyclists and pedestrian categories, especially when dealing with more challenging categories such as cyclists and pedestrians, its performance improvement is more significant. From the perspective of processing frequency (f (Hz)), although TimePillars are not as fast as single-frame PointPillars, they are faster than multi-frame PointPillars while maintaining high detection performance. This shows that TimePillars can effectively perform long-distance detection and motion compensation while maintaining real-time processing. In other words, the TimePillars model shows significant advantages in long-distance detection, motion compensation, and processing speed, especially when processing multi-frame data and using convolution-based motion conversion technology. These results highlight the application potential of TimePillars in the field of 3D lidar object detection for autonomous vehicles.

The above experimental results show that the TimePillars model performs excellently in object detection performance in different distance ranges, especially compared with the benchmark model PointPillars. These results are divided into three main detection ranges: 0 to 50 meters, 50 to 100 meters and above 100 meters.
First of all, NuScenes Detection Score (NDS) and average precision (mAP) are the overall performance indicators. TimePillars outperforms PointPillars on both metrics, showing overall higher detection capabilities and positioning accuracy. Specifically, TimePillars' NDS is 0.723, which is much higher than PointPillars' 0.657; in terms of mAP, TimePillars also significantly surpasses PointPillars' 0.475 with 0.570.
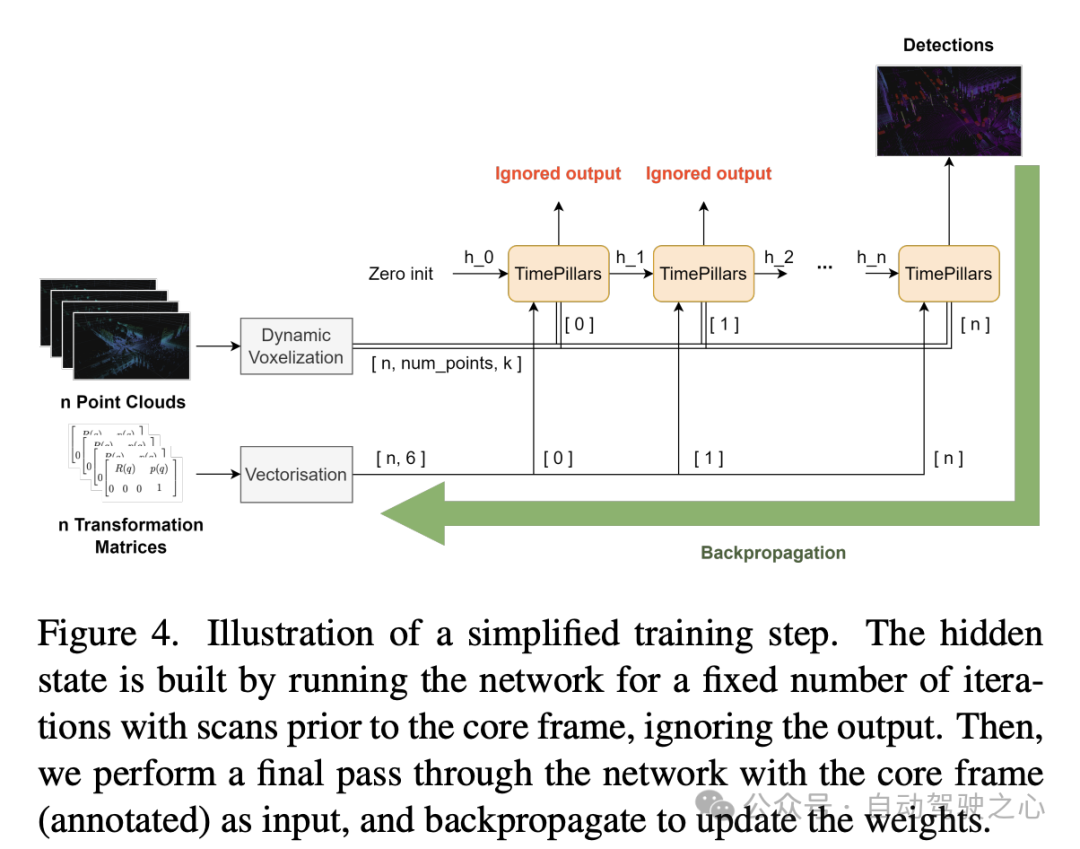
In the performance comparison within different distance ranges, it can be seen that TimePillars performs better in each range. For the vehicle category, the detection accuracy of TimePillars in the ranges of 0 to 50 meters, 50 to 100 meters and more than 100 meters is 0.884, 0.776 and 0.591 respectively, which are all higher than the performance of PointPillars in the same range. This shows that TimePillars has higher accuracy in vehicle detection, both at close and far distances. TimePillars also demonstrated better detection performance when dealing with vulnerable vehicles (such as motorcycles, wheelchairs, electric scooters, etc.). Especially in the range of more than 100 meters, the detection accuracy of TimePillars is 0.178, while PointPillars is only 0.036, showing significant advantages in long-distance detection. For pedestrian detection, TimePillars also showed better performance, especially in the range of 50 to 100 meters, with a detection accuracy of 0.350, while PointPillars was only 0.211. Even at longer distances (more than 100 meters), TimePillars still achieves a certain level of detection (accuracy of 0.032), while PointPillars perform zero at this range.
These experimental results highlight the superior performance of TimePillars in handling object detection tasks in different distance ranges. Whether at close range or at the more challenging long range, TimePillars provide more accurate and reliable detection results, which are critical to the safety and efficiency of autonomous vehicles.
Discussion

First of all, the main advantage of the TimePillars model is its effectiveness for long-distance object detection. By adopting dynamic voxelization and convolutional GRU structure, the model is better able to handle sparse lidar data, especially in long-distance object detection. This is critical for the safe operation of autonomous vehicles in complex and changing road environments. In addition, the model also shows good performance in terms of processing speed, which is essential for real-time applications. On the other hand, TimePillars adopts a convolution-based method for Motion Compensation, which is a major improvement over traditional methods. This approach ensures the correctness of the transformation through auxiliary tasks during training, improving the accuracy of the model when handling moving objects.
However, the research of the paper also has some limitations. First, while TimePillars performs well at handling distant object detection, this performance increase may come at the expense of some processing speed. While the speed of the model is still suitable for real-time applications, it is still a decrease compared to single-frame methods. In addition, the paper mainly focuses on LiDAR data and does not consider other sensor inputs, such as cameras or radars, which may limit the application of the model in more complex multi-sensor environments.
That is to say, TimePillars has shown significant advantages in 3D lidar object detection for autonomous vehicles, especially in long-distance detection and Motion Compensation. Despite the slight trade-off in processing speed and limitations in processing multi-sensor data, TimePillars still represents an important advance in this field.
Conclusion
This work demonstrates that considering past sensor data is superior to utilizing only current information. Accessing previous driving environment information can cope with the sparse nature of lidar point clouds and lead to more accurate predictions. We demonstrate that recurrent networks are suitable as a means to achieve the latter. Giving the system memory leads to a more robust solution compared to point cloud aggregation methods that create denser data representations through extensive processing. The method we proposed, TimePillars, implements a way to solve the recursive problem. By simply adding three additional convolutional layers to the inference process, we demonstrate that basic network building blocks are sufficient to achieve significant results and ensure that existing efficiency and hardware integration specifications are met. To the best of our knowledge, this work provides the first benchmark results for the 3D object detection task on the newly introduced Zenseact open dataset. We hope our work can contribute to safer, more sustainable roads in the future.
The above is the detailed content of TimePillars: Where can the pure LiDAR 3D detection route be extended? Direct coverage of 200m!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
A purely visual annotation solution mainly uses vision plus some data from GPS, IMU and wheel speed sensors for dynamic annotation. Of course, for mass production scenarios, it doesn’t have to be pure vision. Some mass-produced vehicles will have sensors like solid-state radar (AT128). If we create a data closed loop from the perspective of mass production and use all these sensors, we can effectively solve the problem of labeling dynamic objects. But there is no solid-state radar in our plan. Therefore, we will introduce this most common mass production labeling solution. The core of a purely visual annotation solution lies in high-precision pose reconstruction. We use the pose reconstruction scheme of Structure from Motion (SFM) to ensure reconstruction accuracy. But pass
 Take a look at the past and present of Occ and autonomous driving! The first review comprehensively summarizes the three major themes of feature enhancement/mass production deployment/efficient annotation.
May 08, 2024 am 11:40 AM
Take a look at the past and present of Occ and autonomous driving! The first review comprehensively summarizes the three major themes of feature enhancement/mass production deployment/efficient annotation.
May 08, 2024 am 11:40 AM
Written above & The author’s personal understanding In recent years, autonomous driving has received increasing attention due to its potential in reducing driver burden and improving driving safety. Vision-based three-dimensional occupancy prediction is an emerging perception task suitable for cost-effective and comprehensive investigation of autonomous driving safety. Although many studies have demonstrated the superiority of 3D occupancy prediction tools compared to object-centered perception tasks, there are still reviews dedicated to this rapidly developing field. This paper first introduces the background of vision-based 3D occupancy prediction and discusses the challenges encountered in this task. Next, we comprehensively discuss the current status and development trends of current 3D occupancy prediction methods from three aspects: feature enhancement, deployment friendliness, and labeling efficiency. at last
 LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
Written above & the author’s personal understanding: This paper is dedicated to solving the key challenges of current multi-modal large language models (MLLMs) in autonomous driving applications, that is, the problem of extending MLLMs from 2D understanding to 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment. Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (e.g.) due to resolution limitations of the visual encoder, limitations of LLM sequence length. However, autonomous driving applications require
 Towards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!
Jun 08, 2024 pm 09:30 PM
Towards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!
Jun 08, 2024 pm 09:30 PM
The deep reinforcement learning team of the Institute of Automation, Chinese Academy of Sciences, together with Li Auto and others, proposed a new closed-loop planning framework for autonomous driving based on the multi-modal large language model MLLM - PlanAgent. This method takes a bird's-eye view of the scene and graph-based text prompts as input, and uses the multi-modal understanding and common sense reasoning capabilities of the multi-modal large language model to perform hierarchical reasoning from scene understanding to the generation of horizontal and vertical movement instructions, and Further generate the instructions required by the planner. The method is tested on the large-scale and challenging nuPlan benchmark, and experiments show that PlanAgent achieves state-of-the-art (SOTA) performance on both regular and long-tail scenarios. Compared with conventional large language model (LLM) methods, PlanAgent
 Beyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA)
Apr 22, 2024 pm 05:49 PM
Beyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA)
Apr 22, 2024 pm 05:49 PM
Written above & the author’s personal understanding At present, as autonomous driving technology becomes more mature and the demand for autonomous driving perception tasks increases, the industry and academia very much hope for an ideal perception algorithm model that can simultaneously complete three-dimensional target detection and based on Semantic segmentation task in BEV space. For a vehicle capable of autonomous driving, it is usually equipped with surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect data in different modalities. This makes full use of the complementary advantages between different modal data, making the data complementary advantages between different modalities. For example, 3D point cloud data can provide information for 3D target detection tasks, while color image data can provide more information for semantic segmentation tasks. accurate information. Needle
