

What is the convolution kernel?


The convolution kernel is a mathematical tool in a convolutional neural network. It is a small matrix used to perform convolution operations on input data. Convolutional neural networks extract features from input data through convolution kernels. By adjusting the parameters of the convolution kernel, the network can gradually learn more abstract and advanced features. The size and shape of the convolution kernel can be adjusted according to the characteristics of the task and input data. The convolution kernel is usually automatically learned by the neural network, but it can also be designed and adjusted manually.
How to determine the convolution kernel
The determination of the convolution kernel is usually achieved through the training of neural networks. During the training process, the network automatically adjusts the weights and biases of the convolution kernel so that the network can better extract features of the input data and classify them. By monitoring the performance indicators of the network, such as accuracy and loss function values, the effect of the convolution kernel can be evaluated and adjusted as needed. This automatic adjustment mechanism enables the neural network to adapt to different tasks and data sets, thereby improving the performance and generalization ability of the model.
In addition to training the neural network, the determination of the convolution kernel can also be manually designed and adjusted. In this case, the size and shape of the convolution kernel need to be chosen based on the specific task and data characteristics. Generally speaking, smaller convolution kernels can extract finer-grained features, but more convolutional layers are needed to extract high-level features. On the contrary, larger convolution kernels can extract high-level features more quickly, but at the expense of certain detailed information. Therefore, choosing the size of the convolution kernel requires a trade-off between the complexity of the task and the characteristics of the data. For example, for image recognition tasks, smaller convolution kernels can capture subtle texture and shape features in the image, while larger convolution kernels can more quickly identify the shape and contour of the overall object. Therefore, when designing a convolutional neural network, it is necessary to select an appropriate convolution kernel size based on specific tasks and data characteristics to extract the most effective features.
Convolution kernel size
The size of the convolution kernel is adjusted according to the task and data characteristics. In convolutional neural networks, the convolution kernel size generally refers to the width and height. The convolution kernel size is important for both network performance and computational efficiency. Smaller convolution kernels can extract fine-grained features, but more convolution layers are needed to extract high-level features; larger convolution kernels can extract high-level features more quickly, but some detailed information will be lost. Therefore, choosing the convolution kernel size requires a trade-off between task and data characteristics.
The relationship between the number of convolution kernels and the number of input and output channels
In the convolutional neural network, the number of output data channels C_out of the convolutional layer can be expressed by the following formula: C_out = C_in * K
C_out=K
The convolution operation needs to ensure that the input data and the number of channels of the convolution kernel match, that is, C_in and K are equal or C_in is an integer multiple of K. This is because the convolution operation is performed on each channel separately, and each convolution kernel can only process the data of one channel. If the number of channels of the input data does not match the number of convolution kernels, the number of channels needs to be adjusted. This can be achieved by adding an appropriate number of extended convolution kernels or adjusting the number of channels. This ensures that each channel can get the correct convolution calculation results.
In the convolution layer, each convolution kernel consists of a set of learnable weight parameters and a bias parameter, which is used to perform convolution calculations on the input data. The number and size of convolution kernels will affect the receptive field and feature extraction capabilities of the convolution layer. Therefore, according to the needs of specific tasks, we can design and adjust the number and size of convolution kernels to improve the performance of the model.
The relationship between the number of convolution kernels and the number of input and output channels needs to be adjusted according to the network structure and task requirements, but they must match.
How do the parameters in the convolution kernel come from?
The parameters in the convolution kernel are obtained through the training of neural networks. In the process of training the neural network, the neural network will automatically learn and adjust the parameters inside the convolution kernel, so that the network can better extract and classify the features of the input data. Specifically, the neural network adjusts the weights and biases inside the convolution kernel based on the error between the input data and the target output data to minimize the error. This process is usually implemented using the backpropagation algorithm.
In a convolutional neural network, the parameters inside the convolution kernel include weights and biases. The weight is used to calculate the output result of the convolution operation, and the bias is used to adjust the offset of the output result. During the training process, the neural network automatically adjusts these parameters to minimize errors and improve the performance of the network. Generally speaking, the more parameters inside the convolution kernel, the stronger the network's expressive ability, but it will also bring greater computing and memory overhead. Therefore, the parameters inside the convolution kernel need to be weighed and selected based on specific tasks and data characteristics.
Are convolution kernels and filters the same concept?
Convolution kernels and filters can be seen as similar concepts to a certain extent, but they specifically refer to different operations and application.
Convolution kernel is a matrix used for convolution operations, usually used in convolutional layers in convolutional neural networks. In the convolution operation, the convolution kernel starts from the upper left corner of the input data, slides in a certain step size and direction, and performs convolution calculations on the data at each position to finally obtain the output data. Convolution kernels can be used to extract different features of the input data, such as edges, texture, etc.
Filter usually refers to the filter in digital signal processing, which is used to filter signals. Filters can filter signals according to frequency characteristics. For example, a low-pass filter can remove high-frequency signals, a high-pass filter can remove low-frequency signals, and a band-pass filter can retain signals within a specific frequency range. Filters can be applied to audio, image, video and other signal processing fields.
In short, convolution kernels and filters both involve matrix operations and feature extraction, but their application scope and specific implementation methods are different.
The above is the detailed content of What is the convolution kernel?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Explore the concepts, differences, advantages and disadvantages of RNN, LSTM and GRU
Jan 22, 2024 pm 07:51 PM
Explore the concepts, differences, advantages and disadvantages of RNN, LSTM and GRU
Jan 22, 2024 pm 07:51 PM
In time series data, there are dependencies between observations, so they are not independent of each other. However, traditional neural networks treat each observation as independent, which limits the model's ability to model time series data. To solve this problem, Recurrent Neural Network (RNN) was introduced, which introduced the concept of memory to capture the dynamic characteristics of time series data by establishing dependencies between data points in the network. Through recurrent connections, RNN can pass previous information into the current observation to better predict future values. This makes RNN a powerful tool for tasks involving time series data. But how does RNN achieve this kind of memory? RNN realizes memory through the feedback loop in the neural network. This is the difference between RNN and traditional neural network.
 Calculating floating point operands (FLOPS) for neural networks
Jan 22, 2024 pm 07:21 PM
Calculating floating point operands (FLOPS) for neural networks
Jan 22, 2024 pm 07:21 PM
FLOPS is one of the standards for computer performance evaluation, used to measure the number of floating point operations per second. In neural networks, FLOPS is often used to evaluate the computational complexity of the model and the utilization of computing resources. It is an important indicator used to measure the computing power and efficiency of a computer. A neural network is a complex model composed of multiple layers of neurons used for tasks such as data classification, regression, and clustering. Training and inference of neural networks requires a large number of matrix multiplications, convolutions and other calculation operations, so the computational complexity is very high. FLOPS (FloatingPointOperationsperSecond) can be used to measure the computational complexity of neural networks to evaluate the computational resource usage efficiency of the model. FLOP
 A case study of using bidirectional LSTM model for text classification
Jan 24, 2024 am 10:36 AM
A case study of using bidirectional LSTM model for text classification
Jan 24, 2024 am 10:36 AM
The bidirectional LSTM model is a neural network used for text classification. Below is a simple example demonstrating how to use bidirectional LSTM for text classification tasks. First, we need to import the required libraries and modules: importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 Definition and structural analysis of fuzzy neural network
Jan 22, 2024 pm 09:09 PM
Definition and structural analysis of fuzzy neural network
Jan 22, 2024 pm 09:09 PM
Fuzzy neural network is a hybrid model that combines fuzzy logic and neural networks to solve fuzzy or uncertain problems that are difficult to handle with traditional neural networks. Its design is inspired by the fuzziness and uncertainty in human cognition, so it is widely used in control systems, pattern recognition, data mining and other fields. The basic architecture of fuzzy neural network consists of fuzzy subsystem and neural subsystem. The fuzzy subsystem uses fuzzy logic to process input data and convert it into fuzzy sets to express the fuzziness and uncertainty of the input data. The neural subsystem uses neural networks to process fuzzy sets for tasks such as classification, regression or clustering. The interaction between the fuzzy subsystem and the neural subsystem makes the fuzzy neural network have more powerful processing capabilities and can
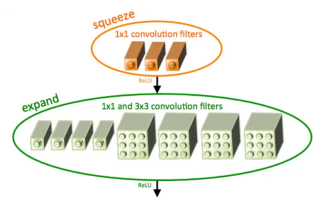 Introduction to SqueezeNet and its characteristics
Jan 22, 2024 pm 07:15 PM
Introduction to SqueezeNet and its characteristics
Jan 22, 2024 pm 07:15 PM
SqueezeNet is a small and precise algorithm that strikes a good balance between high accuracy and low complexity, making it ideal for mobile and embedded systems with limited resources. In 2016, researchers from DeepScale, University of California, Berkeley, and Stanford University proposed SqueezeNet, a compact and efficient convolutional neural network (CNN). In recent years, researchers have made several improvements to SqueezeNet, including SqueezeNetv1.1 and SqueezeNetv2.0. Improvements in both versions not only increase accuracy but also reduce computational costs. Accuracy of SqueezeNetv1.1 on ImageNet dataset
 Image denoising using convolutional neural networks
Jan 23, 2024 pm 11:48 PM
Image denoising using convolutional neural networks
Jan 23, 2024 pm 11:48 PM
Convolutional neural networks perform well in image denoising tasks. It utilizes the learned filters to filter the noise and thereby restore the original image. This article introduces in detail the image denoising method based on convolutional neural network. 1. Overview of Convolutional Neural Network Convolutional neural network is a deep learning algorithm that uses a combination of multiple convolutional layers, pooling layers and fully connected layers to learn and classify image features. In the convolutional layer, the local features of the image are extracted through convolution operations, thereby capturing the spatial correlation in the image. The pooling layer reduces the amount of calculation by reducing the feature dimension and retains the main features. The fully connected layer is responsible for mapping learned features and labels to implement image classification or other tasks. The design of this network structure makes convolutional neural networks useful in image processing and recognition.
 Steps to write a simple neural network using Rust
Jan 23, 2024 am 10:45 AM
Steps to write a simple neural network using Rust
Jan 23, 2024 am 10:45 AM
Rust is a systems-level programming language focused on safety, performance, and concurrency. It aims to provide a safe and reliable programming language suitable for scenarios such as operating systems, network applications, and embedded systems. Rust's security comes primarily from two aspects: the ownership system and the borrow checker. The ownership system enables the compiler to check code for memory errors at compile time, thus avoiding common memory safety issues. By forcing checking of variable ownership transfers at compile time, Rust ensures that memory resources are properly managed and released. The borrow checker analyzes the life cycle of the variable to ensure that the same variable will not be accessed by multiple threads at the same time, thereby avoiding common concurrency security issues. By combining these two mechanisms, Rust is able to provide
 Twin Neural Network: Principle and Application Analysis
Jan 24, 2024 pm 04:18 PM
Twin Neural Network: Principle and Application Analysis
Jan 24, 2024 pm 04:18 PM
Siamese Neural Network is a unique artificial neural network structure. It consists of two identical neural networks that share the same parameters and weights. At the same time, the two networks also share the same input data. This design was inspired by twins, as the two neural networks are structurally identical. The principle of Siamese neural network is to complete specific tasks, such as image matching, text matching and face recognition, by comparing the similarity or distance between two input data. During training, the network attempts to map similar data to adjacent regions and dissimilar data to distant regions. In this way, the network can learn how to classify or match different data to achieve corresponding
