

Pika Peking University and Stanford team up, Open sourceThe latest text-image generation/editing framework!
Without additional training, the diffusion model can have stronger prompt word understanding capabilities.
Faced with super long and complex prompt words, the accuracy is higher, the details are better controlled, and the generated pictures are more natural.
The effect surpasses the strongest image generation models Dall·E 3 and SDXL.
For example, it is required that the picture has two layers of ice and fire on the left and right, with icebergs on the left and volcanoes on the right.
SDXL did not meet the prompt word requirements at all, and Dall·E 3 did not generate the detail of a volcano.

can also generate secondary editing of images through prompt word pairs.
This is the text-image generation/editing framework RPG (Recaption, Plan and Generate), which has caused heated discussions on the Internet.

It was jointly developed by Peking University, Stanford and Pika. The authors include Professor Cui Bin from the School of Computer Science at Peking University, Chenlin Meng, co-founder and CTO of Pika, etc.
The current framework code is open source and is compatible with various multi-modal large models (such as MiniGPT-4) and diffusion model backbone networks (such as ControlNet).
For a long time, diffusion models have been relatively weak in understanding complex prompt words.
Some existing improvement methods either have insufficient final results or require additional training.
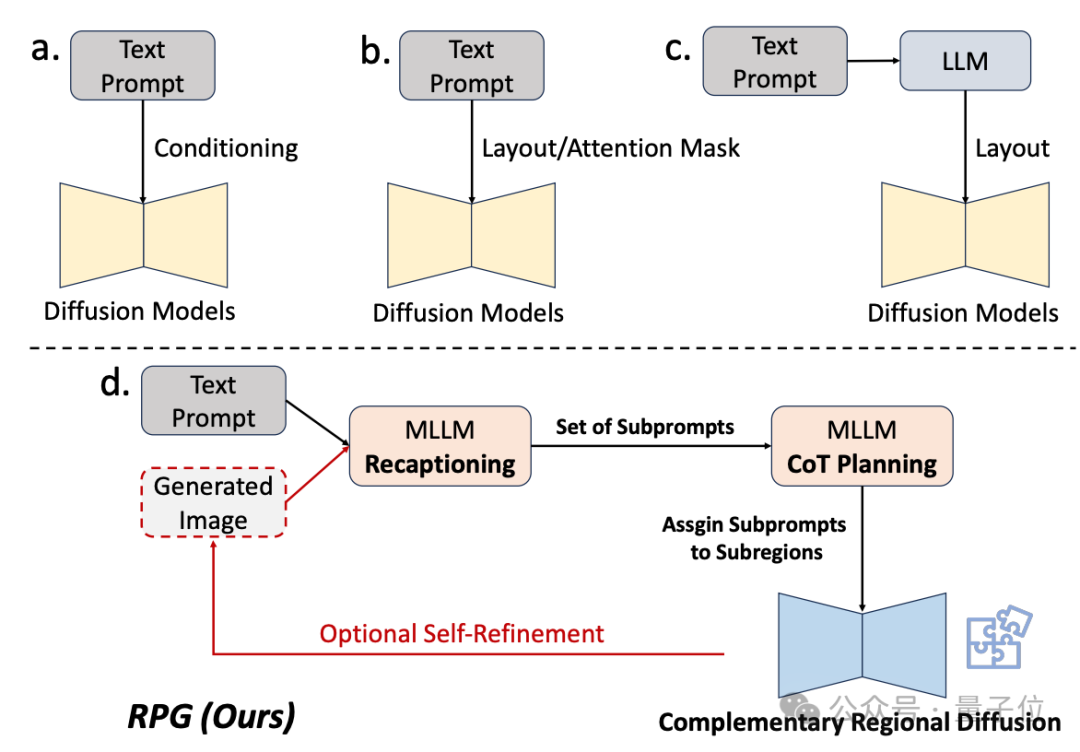
Therefore, the research team uses the understanding ability of multi-modal large models to enhance the combination and controllability of the diffusion model.
As can be seen from the name of the framework, it allows the model to "redescribe, plan and generate".
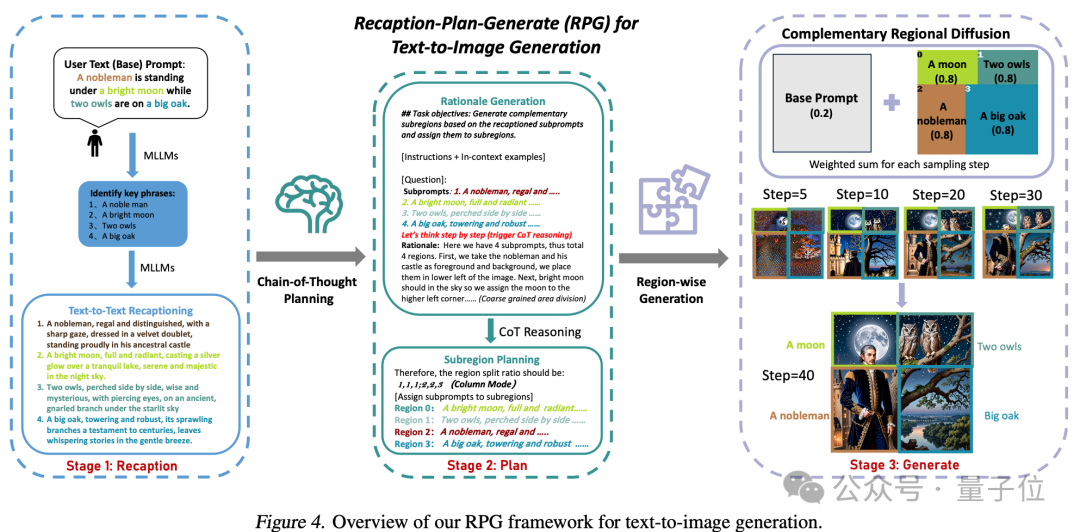
The core strategy of this method has three aspects:
1. Multimodal Recaptioning: Using large models Decompose complex text prompts into multiple sub-prompts and re-describe each sub-prompt in more detail to improve the diffusion model's ability to understand prompt words.
2. Chain-of-Thought Planning (Chain-of-Thought Planning): Using the chain-of-thought reasoning capabilities of multi-modal large models, the image space is divided into complementary sub-regions, and Each sub-region matches a different sub-cue, breaking down complex generation tasks into multiple simpler generation tasks.

3. Complementary Regional Diffusion: After dividing the space, non-overlapping areas generate images based on sub-prompts, and then Perform splicing.
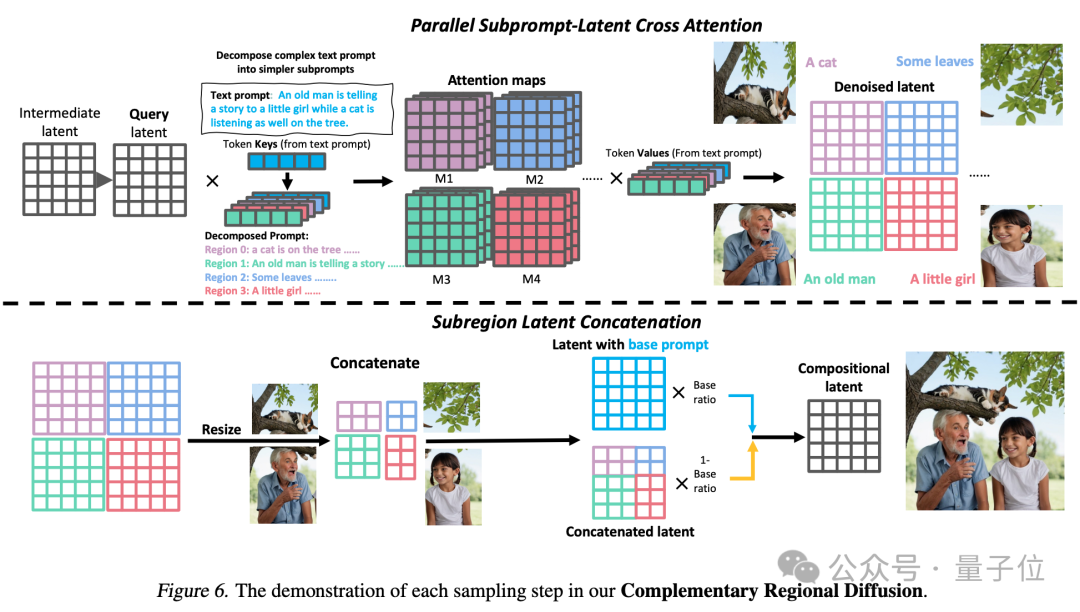


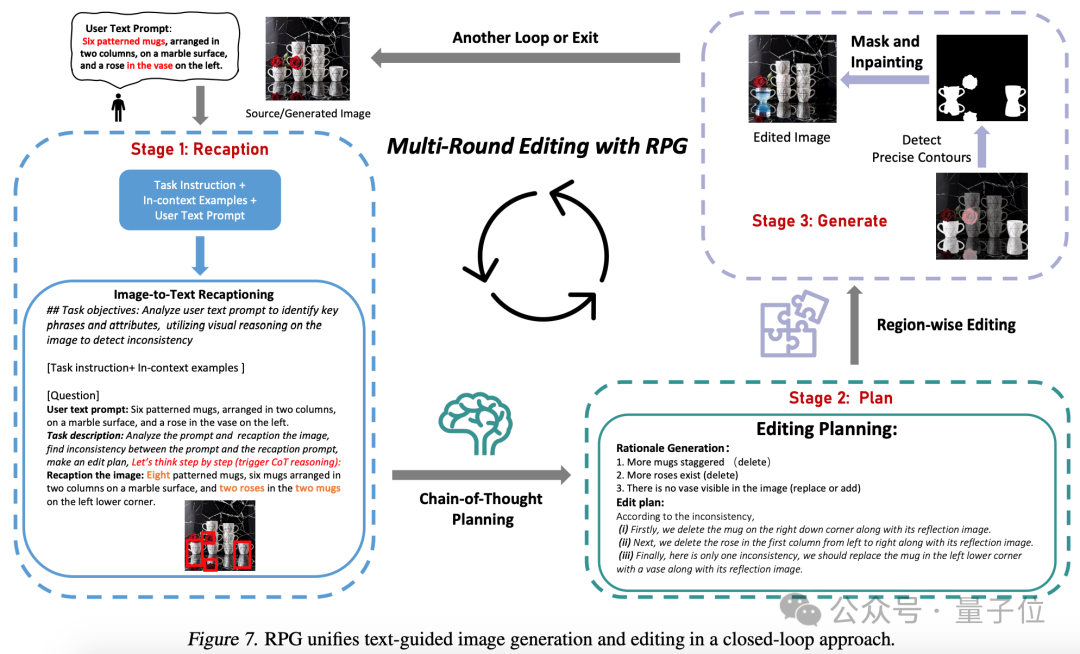
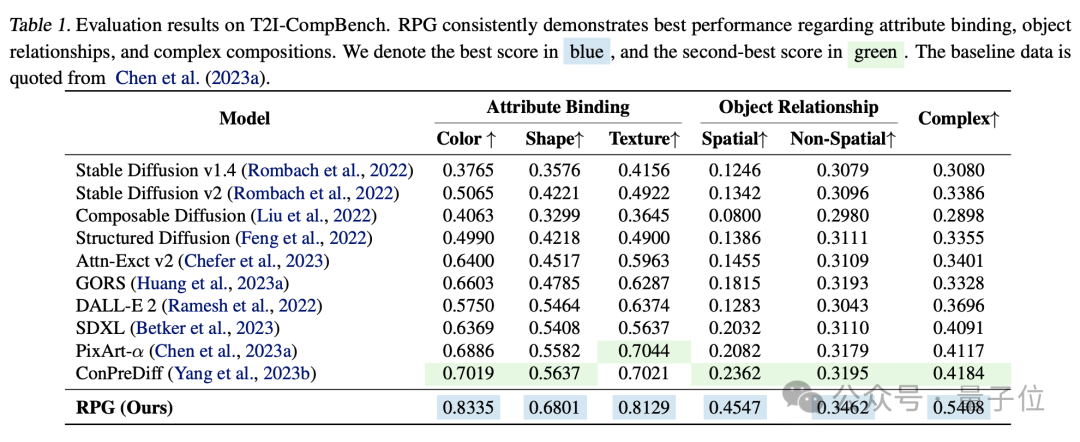
Based on experimental comparison, RPG surpasses other image generation models in dimensions such as color, shape, space, and text accuracy.
This study has two co-authors, Ling Yang and Zhaochen Yu, both from Peking University.
Participating authors include Chenlin Meng, co-founder and CTO of AI startup Pika.
She has a PhD in computer science from Stanford and has rich academic experience in computer vision and 3D vision. She participated in the Denoising Diffusion Implicit Model (DDIM) paper, which has now received 1,700 citations. A number of generative AI-related research articles have been published at top conferences such as ICLR, NeurIPS, CVPR, and ICML, and many of them have been selected into Oral.
Last year, Pika became an instant hit with its AI video generation product Pika 1.0. The background of its founding by two Chinese female PhDs from Stanford made it even more eye-catching.

△On the left is Guo Wenjing (Pika CEO), on the right is Chenlin Meng
Also participating in the research was Vice Dean of the School of Computer Science at Peking University Cui Bin Professor, he is also the director of the Institute of Data Science and Engineering.

In addition, Dr. Minkai Xu from the Stanford AI Laboratory and Stefano Ermon, an assistant professor at Stanford, jointly participated in this research.
Paper address: https://arxiv.org/abs/2401.11708
Code address: https://github.com/YangLing0818/RPG- DiffusionMaster
The above is the detailed content of Using LLM to improve understanding, Pika, a new open source framework from Peking University and Stanford, provides a deeper understanding of the diffusion model of complex prompt words.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



