
 Technology peripherals
AI
Optimization of LLM using SPIN technology for self-game fine-tuning training
Technology peripherals
AI
Optimization of LLM using SPIN technology for self-game fine-tuning training
Optimization of LLM using SPIN technology for self-game fine-tuning training

2024 is a year of rapid development for large language models (LLM). In the training of LLM, alignment methods are an important technical means, including supervised fine-tuning (SFT) and reinforcement learning with human feedback that relies on human preferences (RLHF). These methods have played a crucial role in the development of LLM, but alignment methods require a large amount of manually annotated data. Faced with this challenge, fine-tuning has become a vibrant area of research, with researchers actively working to develop methods that can effectively exploit human data. Therefore, the development of alignment methods will promote further breakthroughs in LLM technology.
The University of California recently conducted a study and introduced a new technology called SPIN (Self Play fIne tuNing). SPIN draws on the successful self-playing mechanism in games such as AlphaGo Zero and AlphaZero to enable LLM (Language Learning Model) to participate in self-playing. This technology eliminates the need for professional annotators, whether humans or more advanced models (such as GPT-4). SPIN's training process involves training a new language model and, through a series of iterations, distinguishing between its own-generated responses and human-generated responses. The ultimate goal is to develop a language model that generates responses that are indistinguishable from human responses. The purpose of this research is to further improve the self-learning ability of the language model and make it closer to human expression and thinking. The results of this research are expected to bring new breakthroughs to the development of natural language processing.
Self-Game
Self-game is a learning technique that increases the challenge and complexity of the learning environment by playing against copies of oneself. This approach allows an agent to interact with different versions of itself, thereby improving its capabilities. AlphaGo Zero is a successful case of self-game.

#Self-game has been proven to be an effective method in multi-agent reinforcement learning (MARL). However, applying it to the augmentation of large language models (LLMs) is a new approach. By applying self-game to large language models, their ability to generate more coherent and information-rich text can be further improved. This method is expected to promote the further development and improvement of language models.
Self-play can be applied in competitive or cooperative settings. In competition, copies of the algorithm compete with each other to achieve a goal; in cooperation, copies work together to achieve a common goal. It can be combined with supervised learning, reinforcement learning and other technologies to improve performance.
SPIN
SPIN is like a two player game. In this game:
The role of the master model (the new LLM) is to learn to distinguish between responses generated by a language model (LLM) and responses created by humans. In each iteration, the master model is actively training the LLM to improve its ability to recognize and distinguish responses.
The adversary model (old LLM) is tasked with generating responses similar to those produced by humans. It is generated through the LLM of the previous iteration, using a self-game mechanism to generate output based on past knowledge. The goal of the adversary model is to create a response so realistic that the new LLM cannot be sure it was machine-generated.
Is this process very similar to GAN, but it is still different
The dynamics of SPIN involve the use of a supervised fine-tuning (SFT) data set, which consists of input (x) and output (y ) pair composition. These examples are annotated by humans and serve as the basis for training the main model to recognize human-like responses. Some public SFT datasets include Dolly15K, Baize, Ultrachat, etc.
Training of the main model
In order to train the main model to distinguish between language models (LLM) and human responses, SPIN uses an objective function. This function measures the expected value gap between the real data and the response produced by the adversary model. The goal of the main model is to maximize this expected value gap. This involves assigning high values to cues paired with responses from real data, and assigning low values to response pairs generated by the adversary model. This objective function is formulated as a minimization problem.
The master model's job is to minimize the loss function, which measures the difference between the pairwise assignment values from the real data and the pairwise assignment values from the opponent model's responses. Throughout the training process, the master model adjusts its parameters to minimize this loss function. This iterative process continues until the master model is proficient in effectively distinguishing LLM responses from human responses.
Update of the adversary model
Updating the adversary model involves improving the ability of the master model, which has learned to distinguish between real data and language model responses during training. As the master model improves and its understanding of specific function classes is improved, we also need to update parameters such as the adversary model. When the master player is faced with the same prompts, it uses its learned discrimination to evaluate their value.
The goal of the opponent model player is to enhance the language model so that its responses are indistinguishable from the master player's real data. This requires setting up a process to adjust the parameters of the language model. The goal is to maximize the master model's evaluation of the language model's response while maintaining stability. This involves a balancing act, ensuring that improvements don't stray too far from the original language model.
It sounds a bit confusing, let’s briefly summarize:
There is only one model during training, but the model is divided into the previous round of models (old LLM/opponent model) and the main model (being trained), use the output of the model being trained and the output of the previous round of models as a comparison to optimize the training of the current model. But here we are required to have a trained model as the opponent model, so the SPIN algorithm is only suitable for fine-tuning the training results.
SPIN algorithm
SPIN generates synthetic data from pre-trained models. This synthetic data is then used to fine-tune the model on new tasks.

The above is the pseudocode of the Spin algorithm in the original paper. It seems a bit difficult to understand. We reproduce it in Python to better explain how it works.
1. Initialization parameters and SFT data set
The original paper uses Zephyr-7B-SFT-Full as the basic model. For the dataset, they used a subset of the larger Ultrachat200k corpus, which consists of approximately 1.4 million conversations generated using OpenAI’s Turbo API. They randomly sampled 50k cues and used a base model to generate synthetic responses.
# Import necessary libraries from datasets import load_dataset import pandas as pd # Load the Ultrachat 200k dataset ultrachat_dataset = load_dataset("HuggingFaceH4/ultrachat_200k") # Initialize an empty DataFrame combined_df = pd.DataFrame() # Loop through all the keys in the Ultrachat dataset for key in ultrachat_dataset.keys():# Convert each dataset key to a pandas DataFrame and concatenate it with the existing DataFramecombined_df = pd.concat([combined_df, pd.DataFrame(ultrachat_dataset[key])]) # Shuffle the combined DataFrame and reset the index combined_df = combined_df.sample(frac=1, random_state=123).reset_index(drop=True) # Select the first 50,000 rows from the shuffled DataFrame ultrachat_50k_sample = combined_df.head(50000)The author's prompt template "
Instruction: {prompt}\n\nResponse:"
# for storing each template in a list templates_data = [] for index, row in ultrachat_50k_sample.iterrows():messages = row['messages'] # Check if there are at least two messages (user and assistant)if len(messages) >= 2:user_message = messages[0]['content']assistant_message = messages[1]['content'] # Create the templateinstruction_response_template = f"### Instruction: {user_message}\n\n### Response: {assistant_message}" # Append the template to the listtemplates_data.append({'Template': instruction_response_template}) # Create a new DataFrame with the generated templates (ground truth) ground_truth_df = pd.DataFrame(templates_data)Then I got data similar to the following: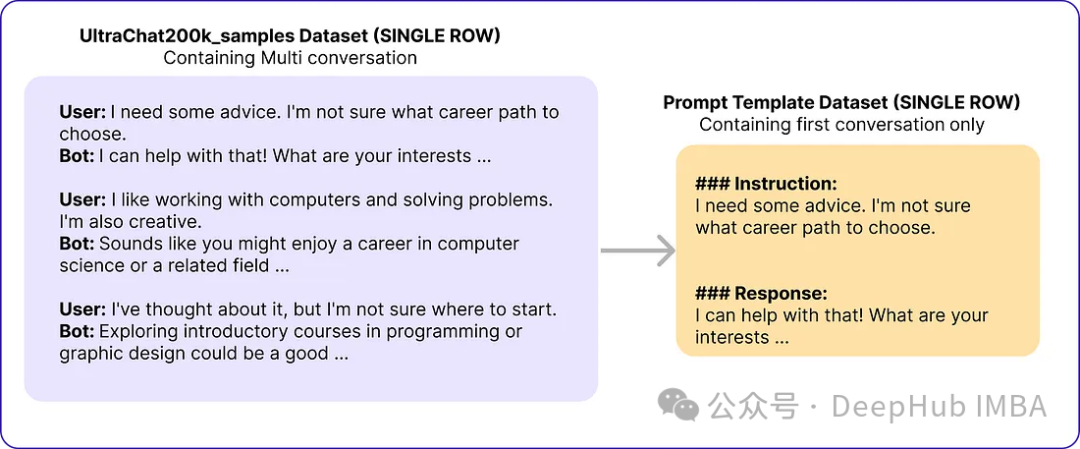
The SPIN algorithm iteratively updates the parameters of a language model (LLM) to make it consistent with the ground-truth response. This process continues until it is difficult to distinguish the generated response from the ground truth, thus achieving a high level of similarity (reduced loss).
The SPIN algorithm has two cycles. The inner loop was run based on the number of samples we were using, and the outer loop was run for a total of 3 iterations, as the authors found that the model's performance did not change after this. The Alignment Handbook library is used as the code library for fine-tuning methods, combined with the DeepSpeed module, to reduce training costs. They trained Zephyr-7B-SFT-Full with the RMSProp optimizer, without weight decay for all iterations, as is typically used to fine-tune llm. The global batch size is set to 64, using bfloat16 precision. The peak learning rate for iterations 0 and 1 is set to 5e-7, and the peak learning rate for iterations 2 and 3 decays to 1e-7 as the loop approaches the end of self-playing fine-tuning. Finally β = 0.1 is chosen and the maximum sequence length is set to 2048 tokens. The following are these parameters
# Importing the PyTorch library import torch # Importing the neural network module from PyTorch import torch.nn as nn # Importing the DeepSpeed library for distributed training import deepspeed # Importing the AutoTokenizer and AutoModelForCausalLM classes from the transformers library from transformers import AutoTokenizer, AutoModelForCausalLM # Loading the zephyr-7b-sft-full model from HuggingFace tokenizer = AutoTokenizer.from_pretrained("alignment-handbook/zephyr-7b-sft-full") model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Initializing DeepSpeed Zero with specific configuration settings deepspeed_config = deepspeed.config.Config(train_batch_size=64, train_micro_batch_size_per_gpu=4) model, optimizer, _, _ = deepspeed.initialize(model=model, config=deepspeed_config, model_parameters=model.parameters()) # Defining the optimizer and setting the learning rate using RMSprop optimizer = deepspeed.optim.RMSprop(optimizer, lr=5e-7) # Setting up a learning rate scheduler using LambdaLR from PyTorch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda epoch: 0.2 ** epoch) # Setting hyperparameters for training num_epochs = 3 max_seq_length = 2048 beta = 0.12. Generate synthetic data (SPIN algorithm inner loop)
This inner loop is responsible for generating responses that need to be consistent with real data, which is the code of a training batch
# zephyr-sft-dataframe (that contains output that will be improved while training) zephyr_sft_output = pd.DataFrame(columns=['prompt', 'generated_output']) # Looping through each row in the 'ultrachat_50k_sample' dataframe for index, row in ultrachat_50k_sample.iterrows():# Extracting the 'prompt' column value from the current rowprompt = row['prompt'] # Generating output for the current prompt using the Zephyr modelinput_ids = tokenizer(prompt, return_tensors="pt").input_idsoutput = model.generate(input_ids, max_length=200, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95) # Decoding the generated output to human-readable textgenerated_text = tokenizer.decode(output[0], skip_special_tokens=True) # Appending the current prompt and its generated output to the new dataframe 'zephyr_sft_output'zephyr_sft_output = zephyr_sft_output.append({'prompt': prompt, 'generated_output': generated_text}, ignore_index=True)This is an example of the true value of a hint and the model output. 
New df zephyr_sft_output containing hints and their corresponding outputs generated by the base model Zephyr-7B-SFT-Full.
3. Update Rules
Before coding the minimization problem, it is crucial to understand how to calculate the conditional probability distribution of the output generated by llm. The original paper uses a Markov process, where the conditional probability distribution pθ (y∣x) can be expressed by decomposition as: 
This decomposition means the output of a given input sequence The probability of a sequence can be calculated by multiplying each output token of a given input sequence by the probability of the previous output token. For example, the output sequence is "I enjoy reading books" and the input sequence is "I enjoy". Given the input sequence, the conditional probability of the output sequence can be calculated as: 
Markov process conditional probability will be used to calculate the probability distribution of the true value and Zephyr LLM response, which is then used to calculate the loss function. But first we need to encode the conditional probability function.
# Conditional Probability Function of input text def compute_conditional_probability(tokenizer, model, input_text):# Tokenize the input text and convert it to PyTorch tensorsinputs = tokenizer([input_text], return_tensors="pt") # Generate text using the model, specifying additional parametersoutputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True) # Assuming 'transition_scores' is the logits for the generated tokenstransition_scores = model.compute_transition_scores(outputs.sequences, outputs.scores, normalize_logits=True) # Get the length of the input sequenceinput_length = inputs.input_ids.shape[1] # Assuming 'transition_scores' is the logits for the generated tokenslogits = torch.tensor(transition_scores) # Apply softmax to obtain probabilitiesprobs = torch.nn.functional.softmax(logits, dim=-1) # Extract the generated tokens from the outputgenerated_tokens = outputs.sequences[:, input_length:] # Compute conditional probabilityconditional_probability = 1.0for prob in probs[0]:token_probability = prob.item()conditional_probability *= token_probability return conditional_probability
The loss function contains four important conditional probability variables. Each of these variables depends on underlying real data or previously created synthetic data. 
而lambda是一个正则化参数,用于控制偏差。在KL正则化项中使用它来惩罚对手模型的分布与目标数据分布之间的差异。论文中没有明确提到lambda的具体值,因为它可能会根据所使用的特定任务和数据集进行调优。
def LSPIN_loss(model, updated_model, tokenizer, input_text, lambda_val=0.01):# Initialize conditional probability using the original model and input textcp = compute_conditional_probability(tokenizer, model, input_text) # Update conditional probability using the updated model and input textcp_updated = compute_conditional_probability(tokenizer, updated_model, input_text) # Calculate conditional probabilities for ground truth datap_theta_ground_truth = cp(tokenizer, model, input_text)p_theta_t_ground_truth = cp(tokenizer, model, input_text) # Calculate conditional probabilities for synthetic datap_theta_synthetic = cp_updated(tokenizer, updated_model, input_text)p_theta_t_synthetic = cp_updated(tokenizer, updated_model, input_text) # Calculate likelihood ratioslr_ground_truth = p_theta_ground_truth / p_theta_t_ground_truthlr_synthetic = p_theta_synthetic / p_theta_t_synthetic # Compute the LSPIN lossloss = lambda_val * torch.log(lr_ground_truth) - lambda_val * torch.log(lr_synthetic) return loss
如果你有一个大的数据集,可以使用一个较小的lambda值,或者如果你有一个小的数据集,则可能需要使用一个较大的lambda值来防止过拟合。由于我们数据集大小为50k,所以可以使用0.01作为lambda的值。
4、训练(SPIN算法外循环)
这就是Pytorch训练的一个基本流程,就不详细解释了:
# Training loop for epoch in range(num_epochs): # Model with initial parametersinitial_model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Update the learning ratescheduler.step() # Initialize total loss for the epochtotal_loss = 0.0 # Generating Synthetic Data (Inner loop)for index, row in ultrachat_50k_sample.iterrows(): # Rest of the code ... # Output == prompt response dataframezephyr_sft_output # Computing loss using LSPIN functionfor (index1, row1), (index2, row2) in zip(ultrachat_50k_sample.iterrows(), zephyr_sft_output.iterrows()):# Assuming 'prompt' and 'generated_output' are the relevant columns in zephyr_sft_outputprompt = row1['prompt']generated_output = row2['generated_output'] # Compute LSPIN lossupdated_model = model # It will be replacing with updated modelloss = LSPIN_loss(initial_model, updated_model, tokenizer, prompt) # Accumulate the losstotal_loss += loss.item() # Backward passloss.backward() # Update the parametersoptimizer.step() # Update the value of betaif epoch == 2:beta = 5.0我们运行3个epoch,它将进行训练并生成最终的Zephyr SFT LLM版本。官方实现还没有在GitHub上开源,这个版本将能够在某种程度上产生类似于人类反应的输出。我们看看他的运行流程
表现及结果
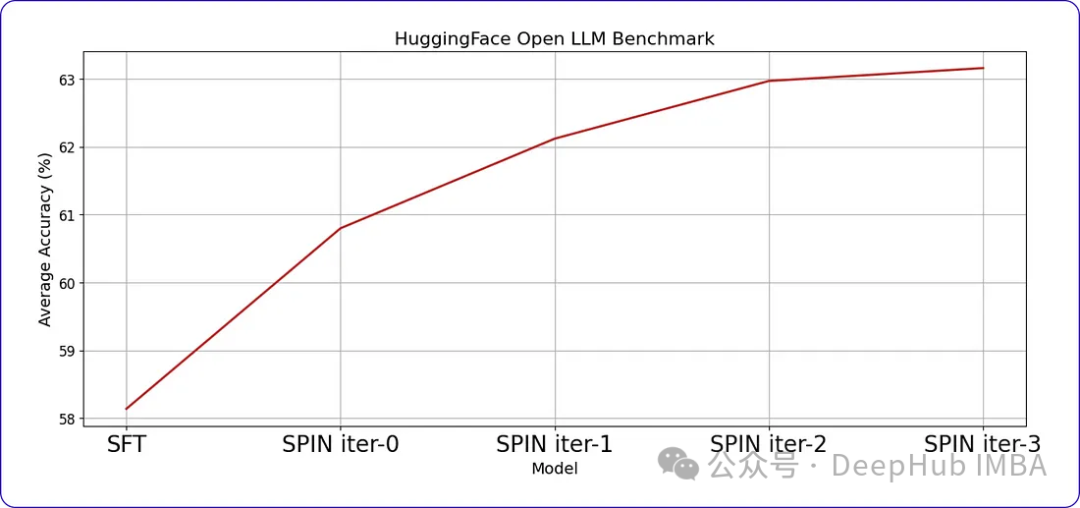
SPIN可以显著提高LLM在各种基准测试中的性能,甚至超过通过直接偏好优化(DPO)补充额外的GPT-4偏好数据训练的模型。
当我们继续训练时,随着时间的推移,进步会变得越来越小。这表明模型达到了一个阈值,进一步的迭代不会带来显著的收益。这是我们训练数据中样本提示符每次迭代后的响应。

The above is the detailed content of Optimization of LLM using SPIN technology for self-game fine-tuning training. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
