
 Technology peripherals
AI
Transformer's groundbreaking work was opposed, ICLR review raised questions! The public accuses black-box operations, LeCun reveals similar experience
Technology peripherals
AI
Transformer's groundbreaking work was opposed, ICLR review raised questions! The public accuses black-box operations, LeCun reveals similar experience
Transformer's groundbreaking work was opposed, ICLR review raised questions! The public accuses black-box operations, LeCun reveals similar experience

In December last year, two researchers from CMU and Princeton released the Mamba architecture, which instantly shocked the AI community!
As a result, this paper, which was expected to "subvert Transformer's hegemony" by everyone, was revealed today to be suspected of being rejected? !
This morning, Cornell University associate professor Sasha Rush first discovered that this paper, which is expected to be a foundational work, seems to be rejected by ICLR 2024.
And said, "To be honest, I don't understand. If it is rejected, what chance do we have?"
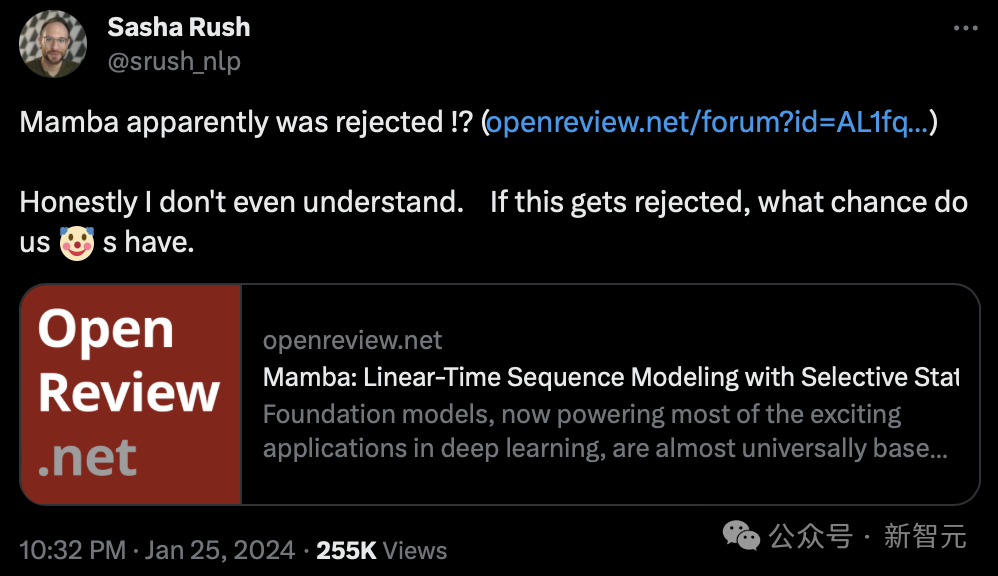
As you can see on OpenReview, the scores given by the four reviewers are 3, 6, 8, and 8.
#Although this score may not cause the paper to be rejected, a score as low as 3 points is outrageous.
Niu Wen scored 3 points, and LeCun even came out to cry out for injustice
This paper was published by two researchers from CMU and Princeton University. A new architecture Mamba is proposed.
This SSM architecture is comparable to Transformers in language modeling, and can also scale linearly, while having 5 times the inference throughput!

Paper address: https://arxiv.org/pdf/2312.00752.pdf
At that time As soon as the paper came out, it immediately shocked the AI community. Many people said that the architecture that overthrew Transformer was finally born.
Now, Mamba’s paper is likely to be rejected, which many people cannot understand.
Even Turing giant LeCun participated in this discussion, saying that he had encountered similar "injustices."
"I think back then, I had the most citations. The papers I submitted on Arxiv alone were cited more than 1,880 times, but they were never accepted."
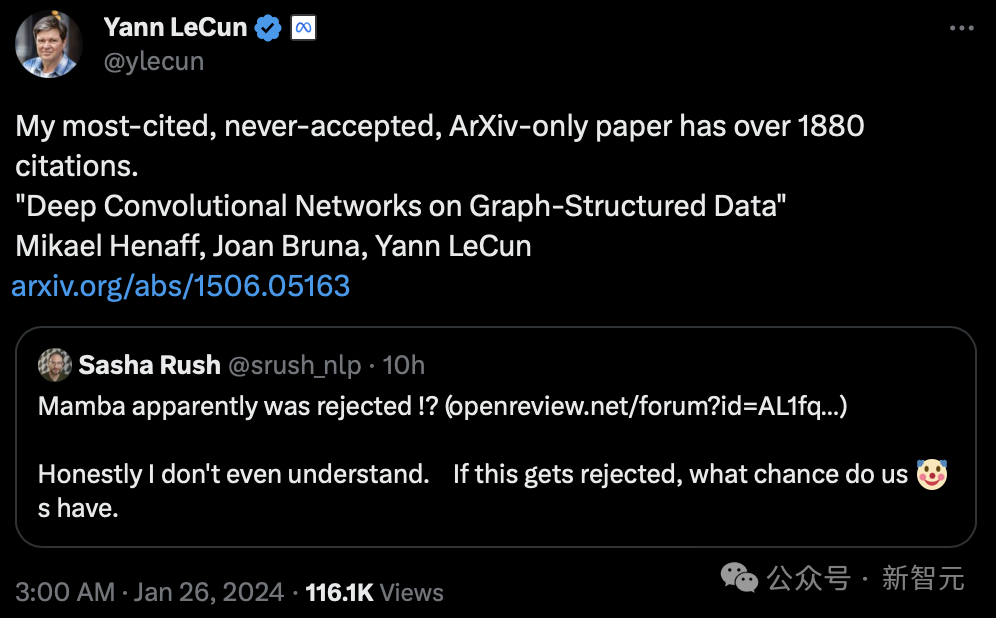
LeCun is famous for his work in optical character recognition and computer vision using convolutional neural networks (CNN), and is therefore famous for his work in optical character recognition and computer vision. Won the Turing Award in 2019.
However, his paper "Deep Convolutional Network Based on Graph Structure Data" published in 2015 has never been accepted by the top conference.

Paper address: https://arxiv.org/pdf/1506.05163.pdf
Depth Learning AI researcher Sebastian Raschka said that despite this, Mamba has had a profound impact on the AI community.
Recently, a large wave of research is based on the Mamba architecture, such as MoE-Mamba and Vision Mamba.

Interestingly, Sasha Rush, who broke the news that Mamba was given a low score, also published a new paper based on such research today—— MambaByte.
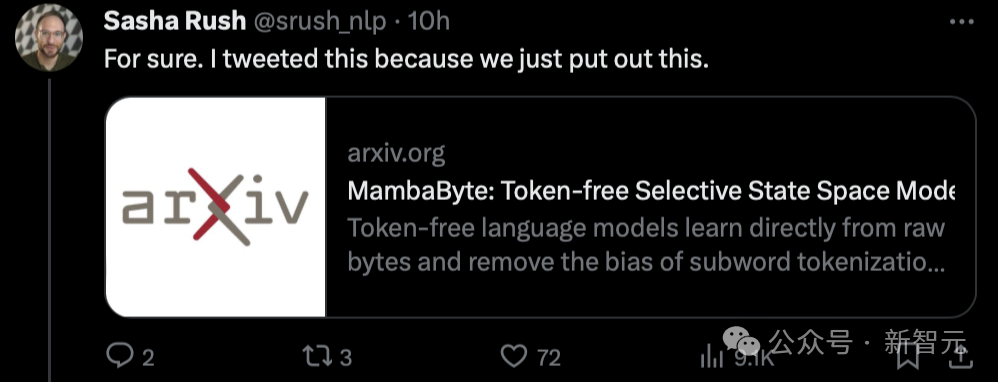

In fact, the Mamba architecture already has the attitude of "a single spark can start a prairie fire". In academic circles, The influence of the circle is getting wider and wider.
Some netizens said that Mamba papers will begin to occupy arXiv.
"For example, I just saw this paper proposing MambaByte, a token-less selective state space model. Basically, it adapts Mamba SSM to directly Learning from original tokens."

Tri Dao of the Mamba paper also forwarded this research today.
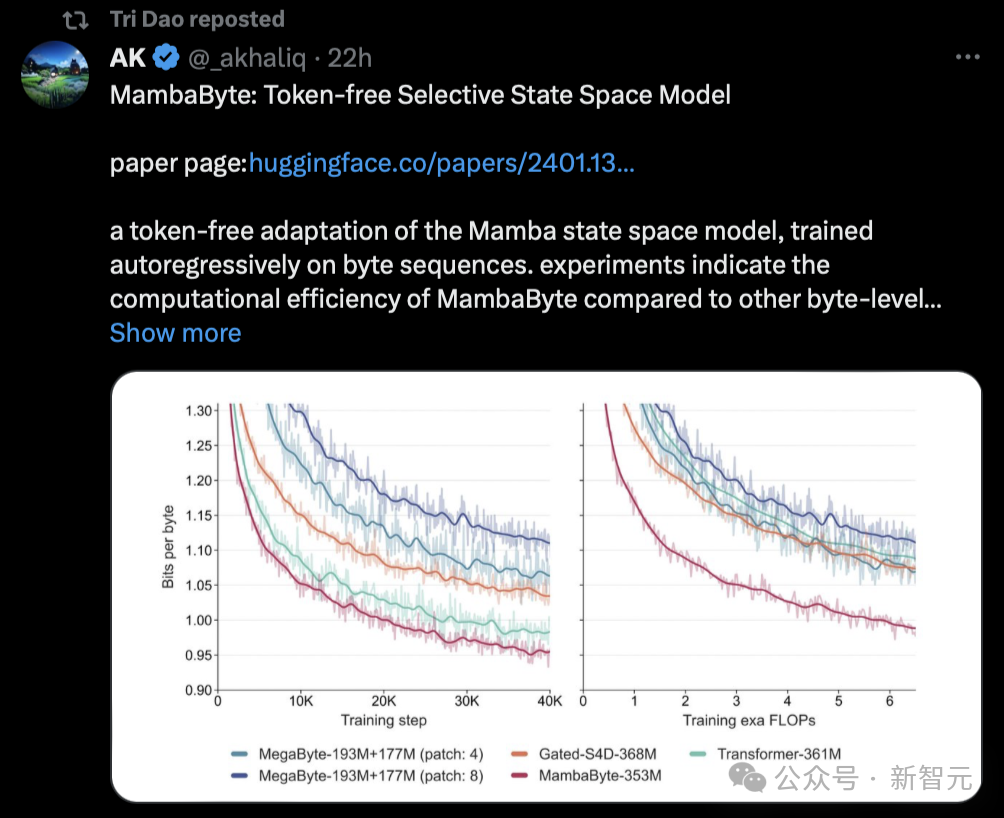
Such a popular paper was given a low score. Some people said that it seems that peer reviewers really don’t pay attention to marketing. How loud is the voice.
The reason why Mamba’s paper was given a low score
The reason why Mamba’s paper was given a low score what is it then?
You can see that the reviewer who gave the review a score of 3 has a confidence level of 5, which means that he is very sure of this score.

In the review, the questions he raised were divided into two parts: one was questioning the model design, and the other was questioning the experiment. .
Model design
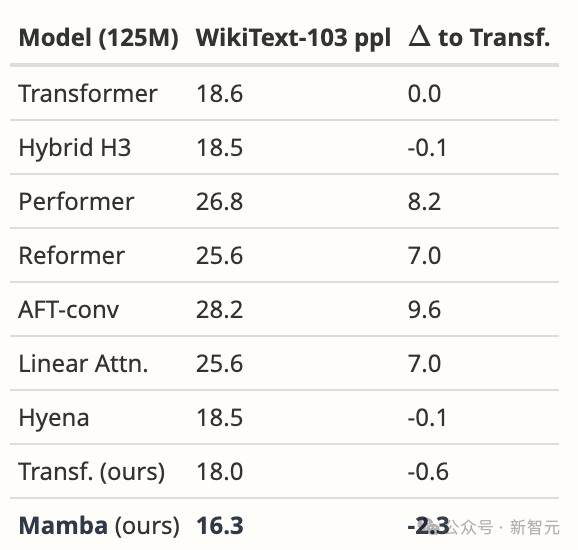
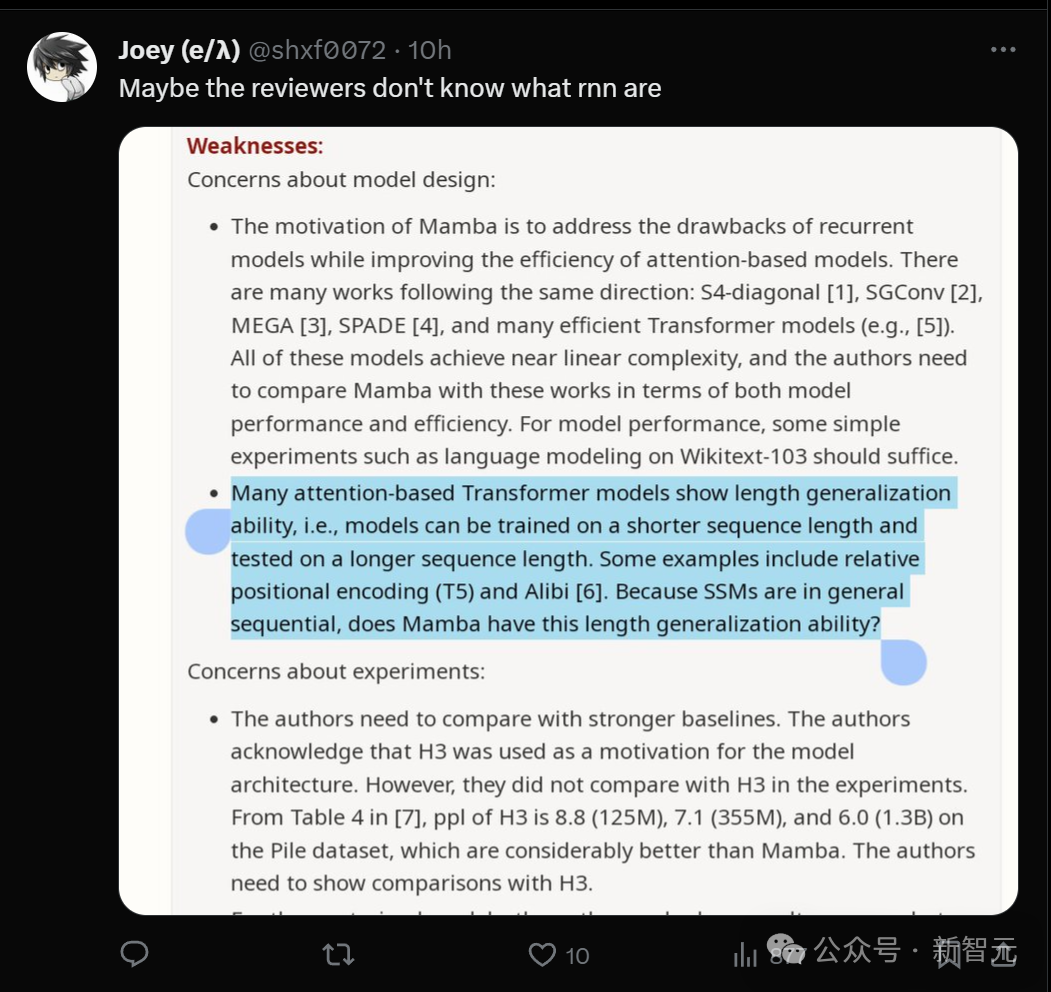
- Mamba’s design motivation is to solve the shortcomings of the loop model while improving the performance of the Transformer model. efficiency. There are many studies along this direction: S4-diagonal [1], SGConv [2], MEGA [3], SPADE [4], and many efficient Transformer models (such as [5]). These models all achieve near-linear complexity, and the authors need to compare Mamba with these works in terms of model performance and efficiency. Regarding model performance, some simple experiments (such as language modeling on Wikitext-103) are enough.
- Many attention-based Transformer models exhibit the ability to length generalize, that is, the model can be trained on shorter sequence lengths and then on longer sequence lengths carry out testing. Some examples include relative position encoding (T5) and Alibi [6]. Since SSM is generally continuous, does Mamba have this length generalization ability?

Experiment
- The authors need to compare to a stronger baseline . The authors acknowledge that H3 was used as motivation for the model architecture. However, they did not compare with H3 experimentally. As can be seen from Table 4 of [7], on the Pile data set, the ppl of H3 are 8.8 (125M), 7.1 (355M) and 6.0 (1.3B) respectively, which are greatly better than Mamba. Authors need to show comparison with H3.
- For the pre-trained model, the author only shows the results of zero-shot inference. This setup is quite limited and the results do not demonstrate Mamba's effectiveness very well. I recommend the authors to conduct more experiments with long sequences, such as document summarization, where the input sequences will naturally be very long (e.g., the average sequence length of the arXiv dataset is greater than 8k).
- The author claims that one of his main contributions is long sequence modeling. The authors should compare with more baselines on LRA (Long Range Arena), which is basically the standard benchmark for long sequence understanding.
- Missing memory benchmark. Although Section 4.5 is titled “Speed and Memory Benchmarks,” it only covers speed comparisons. In addition, the author should provide more detailed settings on the left side of Figure 8, such as model layers, model size, convolution details, etc. Can the authors provide some intuitive explanation as to why FlashAttention is slowest when the sequence length is very large (Figure 8 left)?
Regarding the reviewer’s doubts, the author also went back to do his homework and came up with some experimental data to rebuttal.
For example, regarding the first question about model design, the author stated that the team intentionally focused on the complexity of large-scale pre-training rather than small-scale benchmarks.
Nevertheless, Mamba significantly outperforms all proposed models and more on WikiText-103, which is what we would expect from general results in languages .
First, we compared Mamba in exactly the same environment as the Hyena paper [Poli, Table 4.3]. In addition to their reported data, we also tuned our own strong Transformer baseline.
We then changed the model to Mamba, which improved 1.7 ppl over our Transformer and 2.3 ppl over the original baseline Transformer.
Regarding the "lack of memory benchmark", the author said:
With most depth sequences As with models (including FlashAttention), the memory usage is only the size of the activation tensor. In fact, Mamba is very memory efficient; we additionally measured the training memory requirements of the 125M model on an A100 80GB GPU. Each batch consists of sequences of length 2048. We compared this to the most memory-efficient Transformer implementation we know of (kernel fusion and FlashAttention-2 using torch.compile).

For more rebuttal details, please check https://openreview.net/forum?id=AL1fq05o7H
Overall, the reviewers’ comments have been addressed by the author, but these rebuttals have been completely ignored by the reviewers.
Someone found a "point" in this reviewer's opinion: Maybe he doesn't understand what rnn is?
Netizens who watched the whole process said that the whole process was too painful to read. The author of the paper gave such a thorough response, but the reviewer No wavering, no re-evaluation.

Give a 3 points with a confidence level of 5 and ignore the author’s well-founded rebuttal. This kind of reviewer is too annoying. Bar.
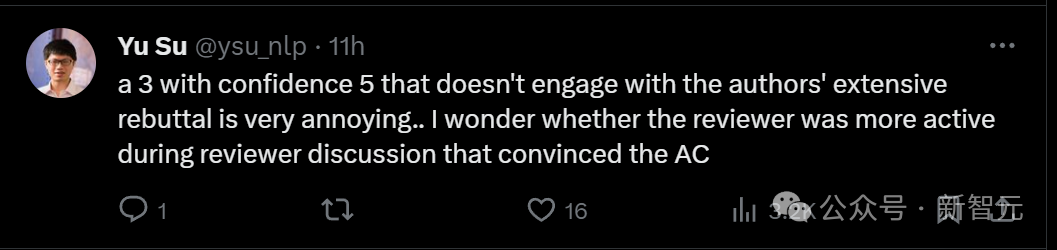
The other three reviewers gave high scores of 6, 8, and 8.
The reviewer who scored 6 points pointed out that weakness is "the model still requires secondary memory like Transformer during training."

#The reviewer who scored 8 points said that the weakness of the article was just "the lack of citations to some related works."
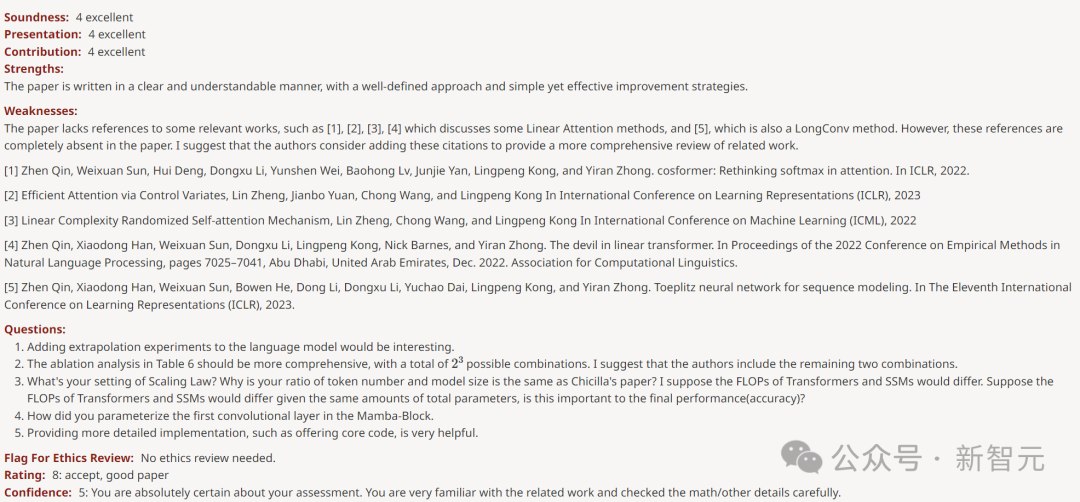
Another reviewer who gave 8 points praised the paper, saying "the empirical part is very thorough and the results are strong."
Not even found any Weakness.


There should be an explanation for such widely divergent classifications. But there are no meta-reviewer comments yet.
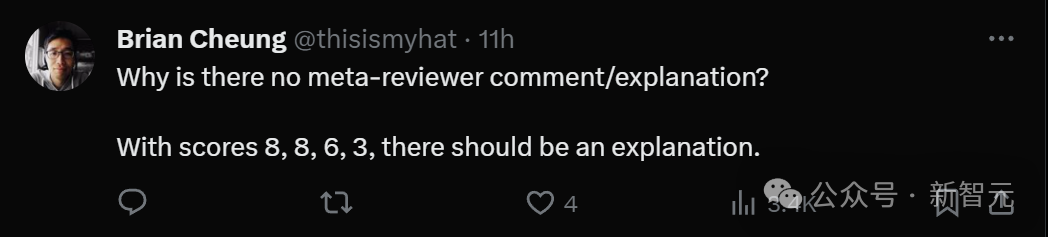
Netizens shouted: The academic world has also declined!
In the comment area, someone asked a soul torture question: Who scored such a low score of 3? ?

Obviously, this paper achieves better results with very low parameters, and the GitHub code is also clear and everyone can test it , so it has won widespread praise, so everyone thinks it is outrageous.
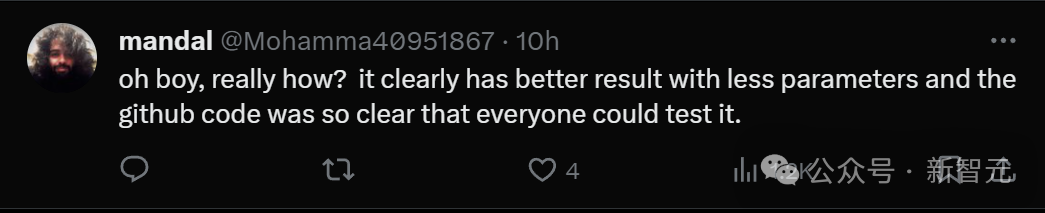
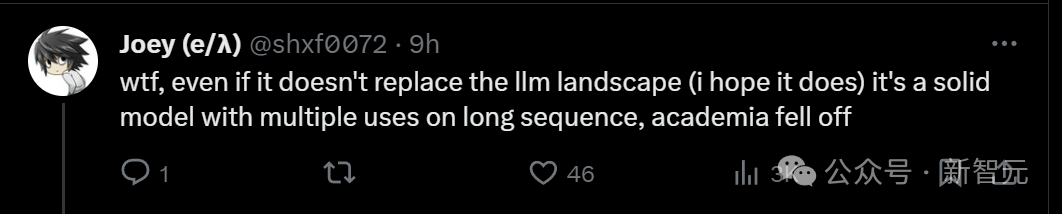
Some people simply shouted WTF. Even if the Mamba architecture cannot change the LLM landscape, it is a reliable model with multiple uses on long sequences. . To get this score, does it mean that today's academic world has declined?
Everyone sighed with emotion. Fortunately, this is just one of the four comments. The other reviewers gave high scores. At present, the final A decision has not yet been made.
Some people speculate that the reviewer may have been too tired and lost his judgment.
Another reason is that a new research direction such as the State Space model may threaten some reviewers and experts who have made great achievements in the Transformer field. The situation is very complicated.
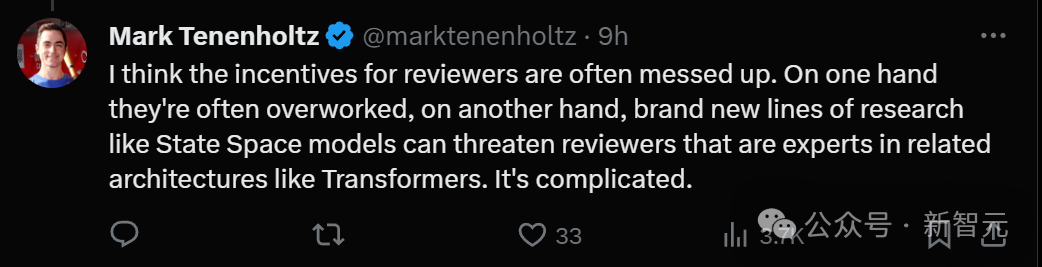
Some people say that Mamba’s paper getting 3 points is simply a joke in the industry.
They are so focused on comparing crazy fine-grained benchmarks, but the really interesting part of the paper is engineering and efficiency. Research is dying because we only care about SOTA, albeit on outdated benchmarks for an extremely narrow subset of the field.
"Not enough theory, too many projects."

Currently, this "mysterious case" has not yet come to light, and the entire AI community is waiting for a result.
The above is the detailed content of Transformer's groundbreaking work was opposed, ICLR review raised questions! The public accuses black-box operations, LeCun reveals similar experience. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
Suggestions for choosing a cryptocurrency exchange: 1. For liquidity requirements, priority is Binance, Gate.io or OKX, because of its order depth and strong volatility resistance. 2. Compliance and security, Coinbase, Kraken and Gemini have strict regulatory endorsement. 3. Innovative functions, KuCoin's soft staking and Bybit's derivative design are suitable for advanced users.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
